
计算节点作为整个计算系统之中重要的组成部分,也是区别于云计算的一点,目的是避免计算瓶颈和减少计算延迟。
这样的层级通信,如下图所示,下面的层次组成了上面的层次的功能,每个计算节点之间形成树状拓扑结构。往往最高级的计算节点仍然在云上,主要负责的是协调整个系统。
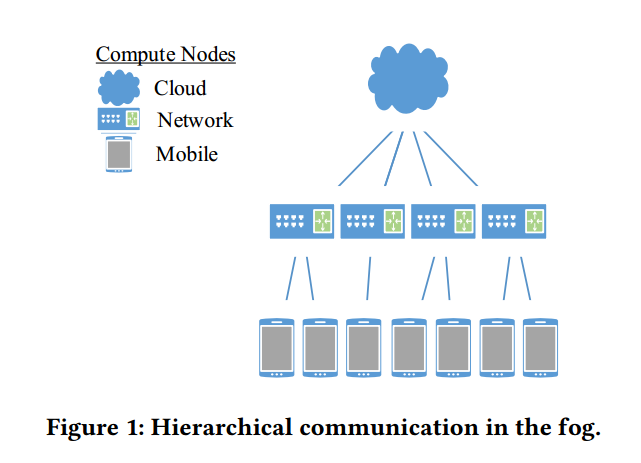
将网络的计算节点组织成实现雾计算的树状层级结构,使用雾计算来最小化延迟。将低层级处理不了的工作负载到高层级上,一层一层向上请求,这样在网络高峰的时候,大量的IOT设备都可以正常运行。而且作者还开发了一种负载分配的算法,使得平均延迟最小化。
Djabir Abdeldjalil Chekired and Lyes Khoukhi. 2018. Multi-Tier Fog Architecture: A New Delay-Tolerant Network for IoT Data Processing. In 2018 IEEE International Conference on Communications (ICC). IEEE, 1–6
利用雾计算的计算节点,减少计算延迟。顶层置于云上,层数取决于计算节点的数量。作者设计了一个数据存储的机制,最底层节点收集数据,如果运行中的应用程序需要这些数据,由于彼此的距离很近,基本可以保证数据的实时获取,但是考虑到边缘设备的存储容量有限,数据会周期性的向上层传输保存。
Amir Sinaeepourfard, Jordi Garcia, Xavier Masip-Bruin, and Eva Marin-Tordera.2018.Data Preservation through Fog-to-Cloud (F2C) Data Management in Smart Cities. In 2nd IEEE International Conference on Fog and Edge Computing (ICFEC).IEEE, 1–9.
Olena Skarlat, Vasileios Karagiannis, Thomas Rausch, Kevin Bachmann, and Stefan Schulte. 2018. A Framework for Optimization, Service Placement, and Runtime Operation in the Fog. In 11th IEEE/ACM International Conference on Utility and Cloud Computing (UCC). IEEE, 164–173.
本框架将参与的资源整合到计算节点的层次结构中,层次结构的顶部,是一个云计算的节点。云计算节点的下层结构按照树形结构来构建,将IOT设备看成树的叶子,在云设备和雾设备之间,设置一个雾控制器的组件,这个组件给计算节点提供虚拟资源。这样的体系结构可以将雾计算的工作负载被分到边缘设备的多个计算节点。当工作负载仍然太大或者无法完成时,将任务提交到云上。
这样的分层类型的分层依据往往是按照资源大小来进行排布的,对于雾计算平台尤其有益,特别是那些计算资源极其有限的IOT设备,这些设备没有那种特别复杂的算法和资源用来处理和转发工作负载内容。它们就在层级树状结构的最底层,仅仅梳理简单的、资源占用低的计算工作。
这样的点对点通信方式就是利用P2P的方式来组织雾计算的节点,如下图所示
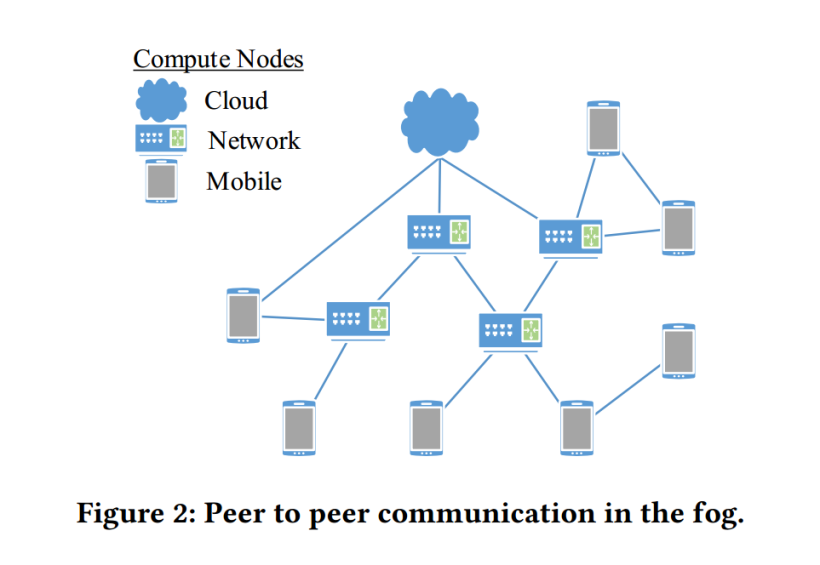
José Santos, Tim Wauters, Bruno Volckaert, and Filip De Turck. 2018. Towards Dynamic Fog Resource Provisioning for Smart City Applications. In 14th International Conference on Network and Service Management (CNSM). IEEE, 290–294.
用于雾计算中的动态资源配置,分布式哈希表(DHT)提供一种按照环形的结构来组织计算节点的机制。通过使用DHT,计算节点就可以交换彼此可用的计算资源信息和工作负载的各种信息。文献【40】也提出了一种接近感知和容错机制。虽然提供了消息传递系统,但是没有提及具体的供应机制,作者选择了三种基于DHT的P2P协议:Chord, Kademlia and Pastry.
Genc Tato, Marin Bertier, and Cedric Tedeschi. 2018. Koala: Towards Lazy and Locality-Aware Overlays for Decentralized Clouds. In 2nd IEEE International Conference on Fog and Edge Computing (ICFEC). IEEE, 1–10.
用于组织所有的计算节点,通过假设在地理维度上的很多小型数据中心,来让云分散化。Koala通过简化掉检测节点故障的周期性消息来降低通信协议上的开销,检测故障的方式变成了检测不响应程序流量的节点。发现这样的节点之后,更新相应节点的路由信息,从而汇报故障。这样的机制为重叠网提供了容错,而且这样的覆盖也提供了接近感知的路由方式。基于此,所有的计算节点都被组织在了环形结构之中,每个节点都仅仅维护系统的一部分视图,用于权衡路由跳数和延迟之间的均衡后选择下一跳。
Juan A. Cabrera G, Daniel E. Lucani R., and Frank H. P Fitzek. 2016. On network coded distributed storage: How to repair in a fog of unreliable peers. In 2016 International Symposium on Wireless Communication Systems (ISWCS). IEEE, 188–193.
通过管理雾计算中不同设备的数据来应对IOT设备不断生成的数据。雾计算的节点也被组织到了P2P网络之中,方便提供低延迟和高吞吐的量的数据存储。每个节点与邻近的节点进行无线通信。作者提出了一种用于解决计算节点意外断联的问题:数据按照分布式存储在雾计算的计算节点之中,当有某个节点无法响应的时候,其他的可以响应的节点自动选择出一个领导者,这样的一个领导者要从其他节点中收集数据块,然后通过向前纠错码重新组装数据并重新分发给其他节点。这样可以提升存储的容错并且计算节点出现故障仍然可用。
不可否认P2P对于网络边缘设备通信已经很成熟,在雾计算中集成P2P通信可以确保节点故障的容忍度。不足之处在于P2P假设所有节点都是平等的,然而节点之间可用资源的异质性仍然需要讨论。
混合通信就是将分层和P2P一起使用来组织雾计算节点,计算节点按层组织,每层之间的设备按照P2P进行通信。针对于雾计算不同部分有这不同要求的情况是有用的。(雾计算的边缘设备和云计算的稳定设备的容错性是有区别的),如下图所示
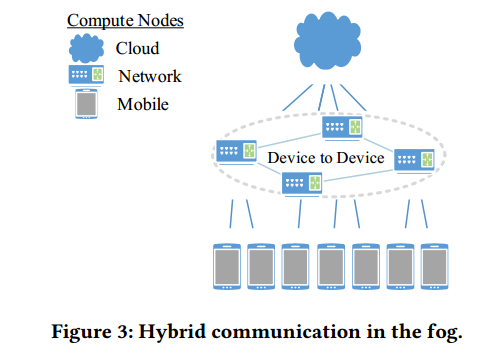
Gilsoo Lee, Walid Saad, and Mehdi Bennis. 2017. An online secretary framework for fog network formation with minimal latency. In 2017 IEEE International Conference on Communications (ICC). IEEE, 1–6.
这个框架是为了将工作负载从IOT设备中外包出去。作者提出了一个优化模型,动态选择每个计算节点的邻居节点,然后将工作负载外包给邻居节点,使得计算延迟最小。雾节点彼此连接以P2P进行通信。系统整体架构使用三层分层组织,底层是资源受限IOT设备,将处理不了工作负载给层次结构更高的雾层,雾层的每个计算节点都可以与邻近的邻居节点共享负载,也可以将工作负载外包给顶层的云层。
Xu Chen and Junshan Zhang. 2017. When D2D meets cloud: Hybrid mobile task offloadings in fog computing. In 2017 IEEE International Conference on Communications (ICC). IEEE, 1–6.
该框架给了工作负载三种选择
也是按照移动设备-雾设备-云设备三层架构来设计的。工作负载的任务是优化问题的一部分,优化问题可以最大程度的降低计算成本,这样来讲工作负载就可以在云层中或者在雾层中以P2P为通信方式进行外包。作者开发了两种启发式方法(随机/贪婪)来进行工作负载的有效外包。
Junsong Fu, Yun Liu, Han-Chieh Chao, Bharat Bhargava, and Zhenjiang Zhang.
\2018. Secure data storage and searching for industrial IoT by integrating fog computing and cloud computing. IEEE Transactions on Industrial Informatics 14, 10 (2018), 4519–4528.
主要为了应对IOT数据的大幅增加。这个框架将计算节点的体系结构重新设定为“边缘服务器-代理服务器-云服务器”。边缘服务器将数据转换为统一的格式,在功能区对其进行组合。数据被发送到代理服务器,代理服务器对数据加密方便存储在云上。用户将查询的陷门(trapdoor)发送到云服务器上,云服务器通过陷门来查找加密数据。实现了数据的加密存储,但是对于小型数据来讲,边缘服务器之间仍然会相互通信共享负载。
混合通信尝试将P2P和分层通信结合起来。那么,这种通信方式由于固有的层次结构,支持资源异构的节点。但是其使用的是简单的P2P连接,往往会丧失容错机制。
为了比较雾计算中的通信类型,根据雾计算的性质要求,特出一套标准
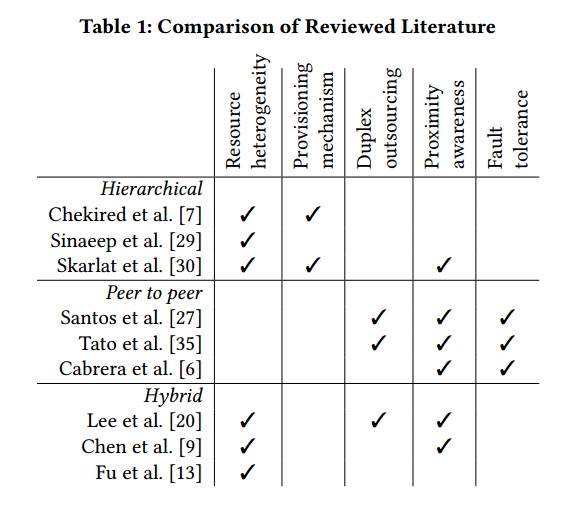
根据上表所示,分层通信对于资源异质性的处理很好,不同设备使用不同的层,之间的关系很简单,要开发供应机制是好的选择,计算节点在predecessors/successors提供虚拟资源就可以了。但是接近措施和容错机制没有被重视。
对于典型的P2P通信,其对于容错机制很好,但是其往往将每个节点都视为平等的,所以对于节点的资源异质性支持不是很好,反而是混合通信更好一点,而且混合类型可以实现靠近感知,因为层内的设备以p2p方式来通信。
基于上表,明显可以看出,每种通信类型都符合了不同的标准,所以往往通信标准决定了应用程序的最终功能。但是为了完成通用雾计算的需求,确定以下的研究挑战:
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只