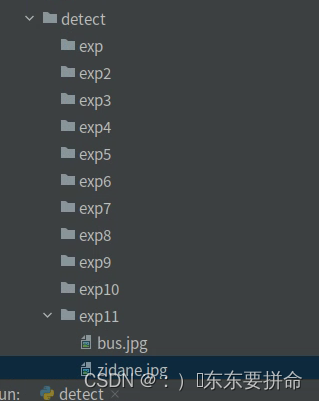
看我出现那么多例子,最后才能正常预测的,是有点小心酸
第一个报错 没有sppf类的
Can't get attribute 'SPPF' on <module 'models.common' from 'D:\\Pycharm\\Code\\yolov5-5.0\\models\\common.py'>
Can't get attribute 'SPPF' on <module 'models.common' from 'D:\\Pycharm\\Code\\yolov5-5.0\\models\\common.py'>
紧接着第二个报错
RuntimeError: The size of tensor a (80) must match the size of tensor b (56) at non-singleton
RuntimeError: The size of tensor a (80) must match the size of tensor b (56) at non-singleton
下面给出解决方案
针对第一个问题
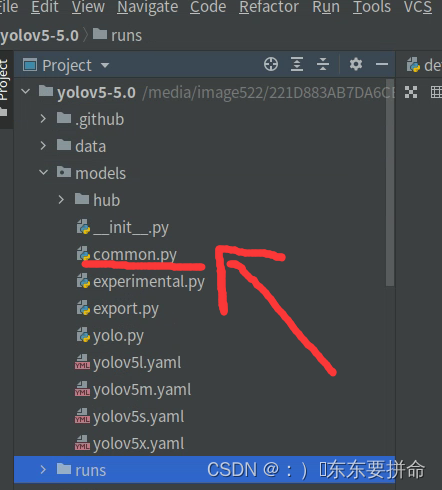
打开它,找到spp那个类149行左右
在spp类的下面添加sppf类
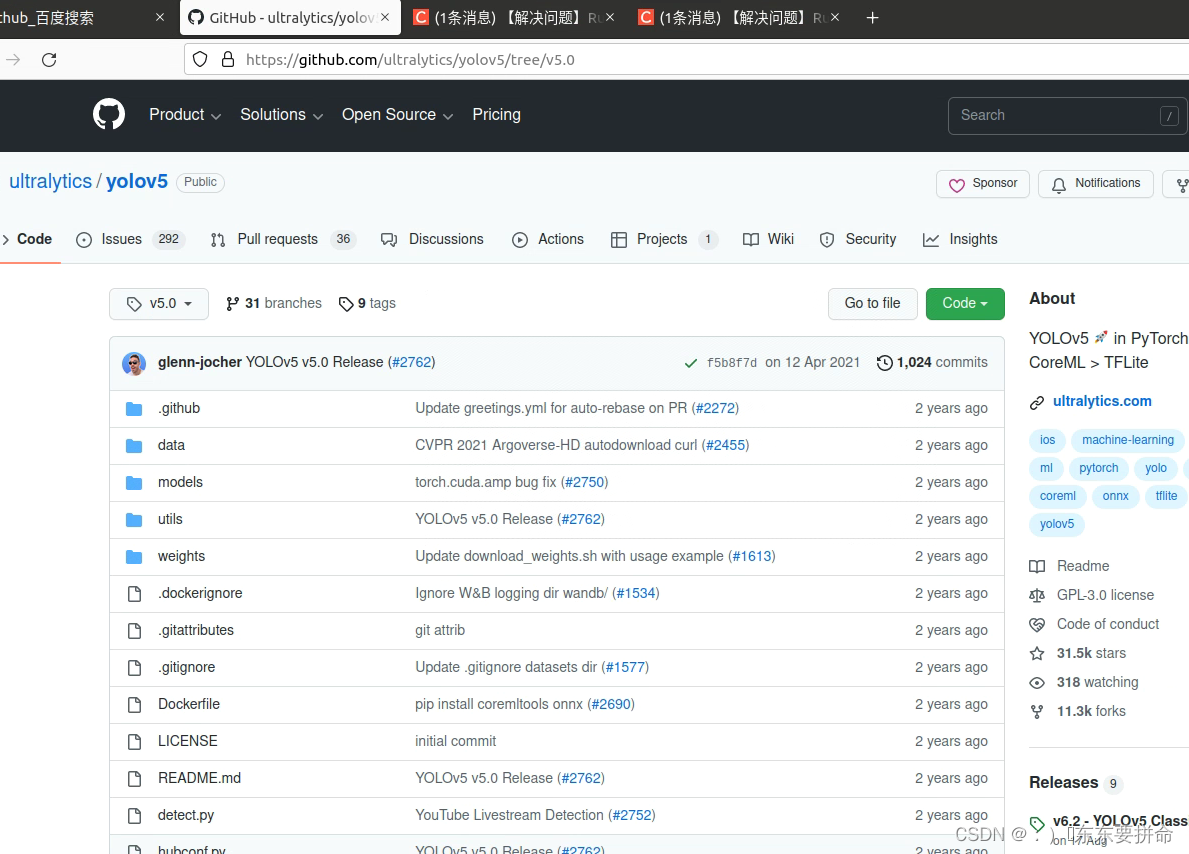
先回溯一下本源,这个model里面的common文件确实没有SPPF类别
那么就得去别的版本把这个sppf在逃公主拿下
这里找到6.0

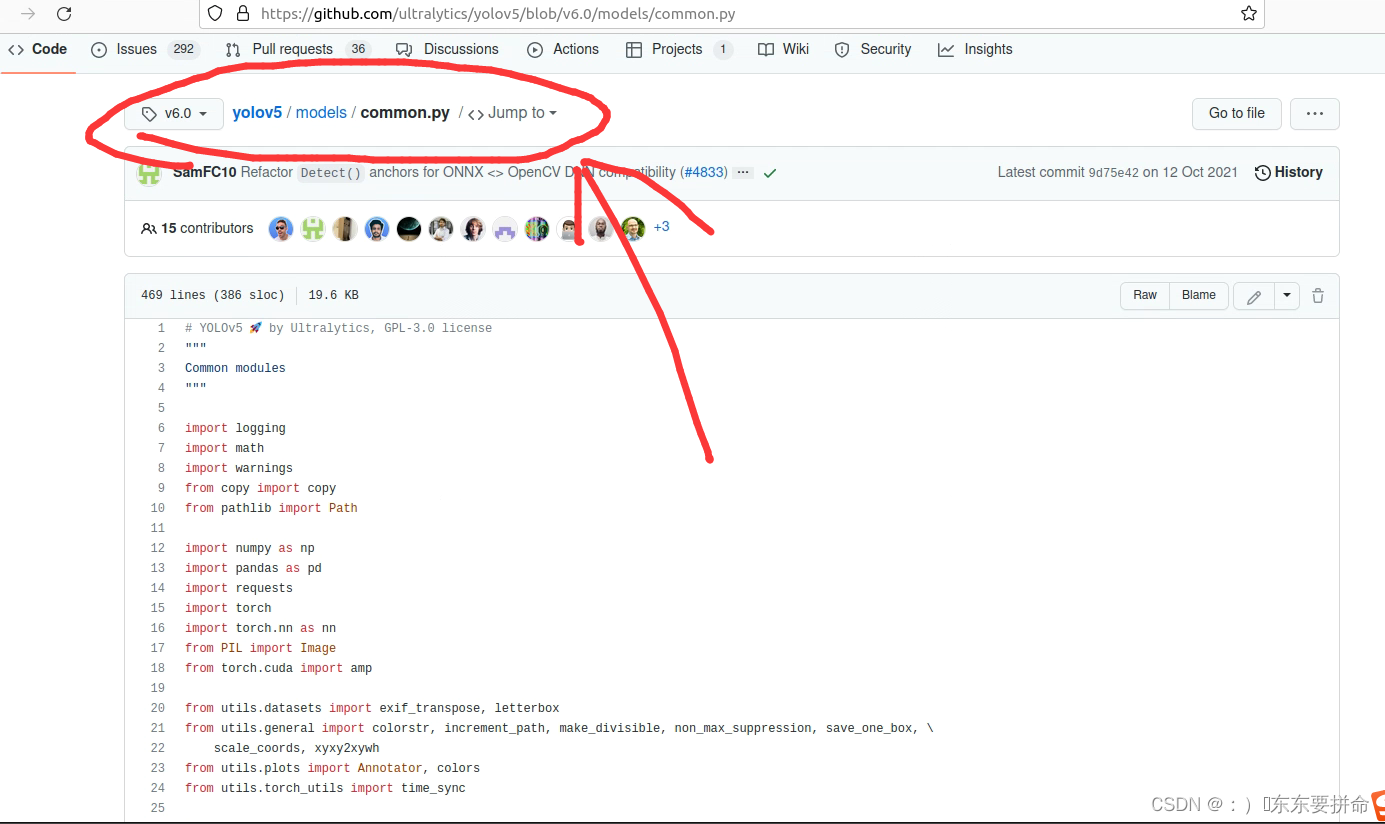
根据我这个路径找到6.0的common
找到sppf
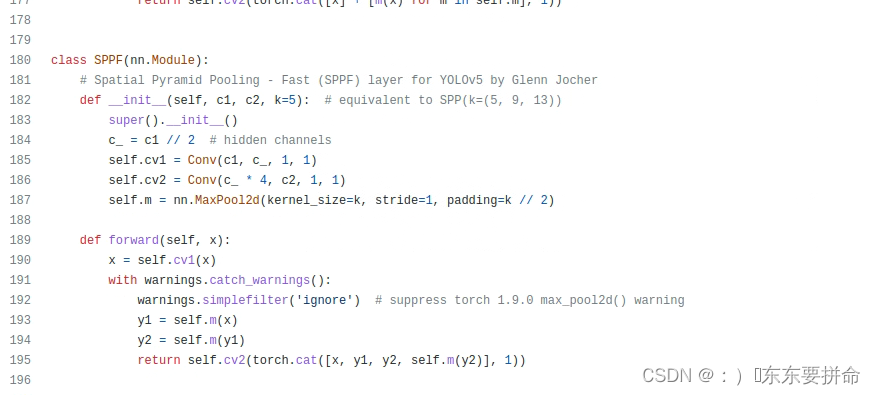 复制过来,拷贝到我们的common文件里面
复制过来,拷贝到我们的common文件里面
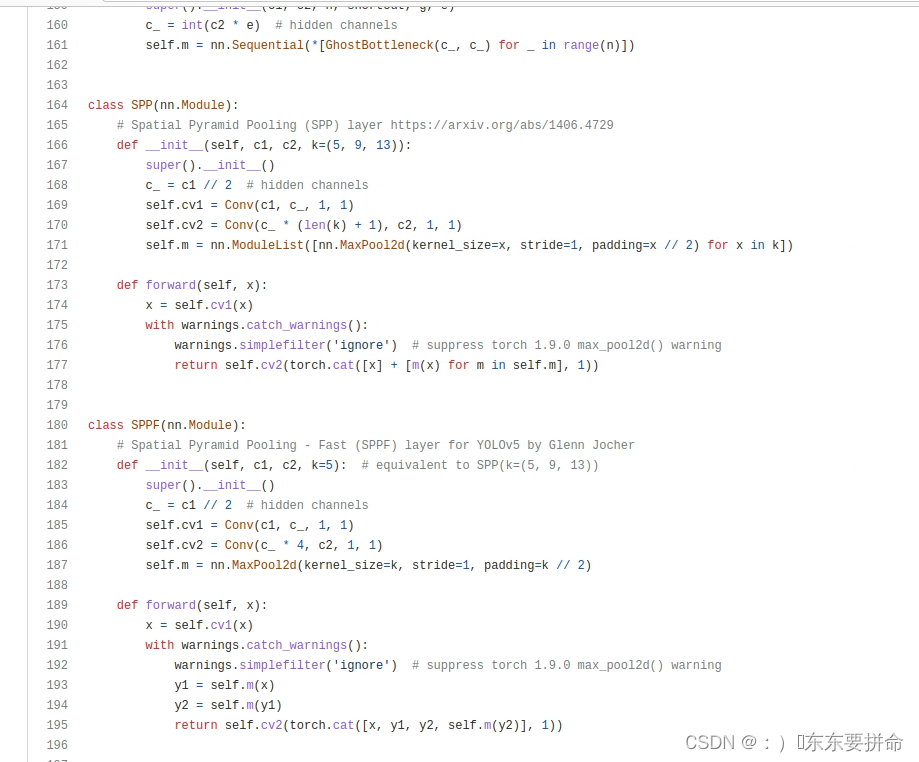
这是原来的相对位置
其实在我们的common中放spp的上面和下面都没有关系的
第一个问题呢算是解决了,但是不出意外还是要报错
就跟我上面的那个应该一模一样
出现那个原因是因为权重文件不匹配,你只需要知道自己装的是哪个yolov5版本 1.0 2.0
我的是5.0 就要去找5.0的权重,本来是之前它自动就会下好的,所以不应该出现意外的
但是没有办法 直接给出去哪下吧
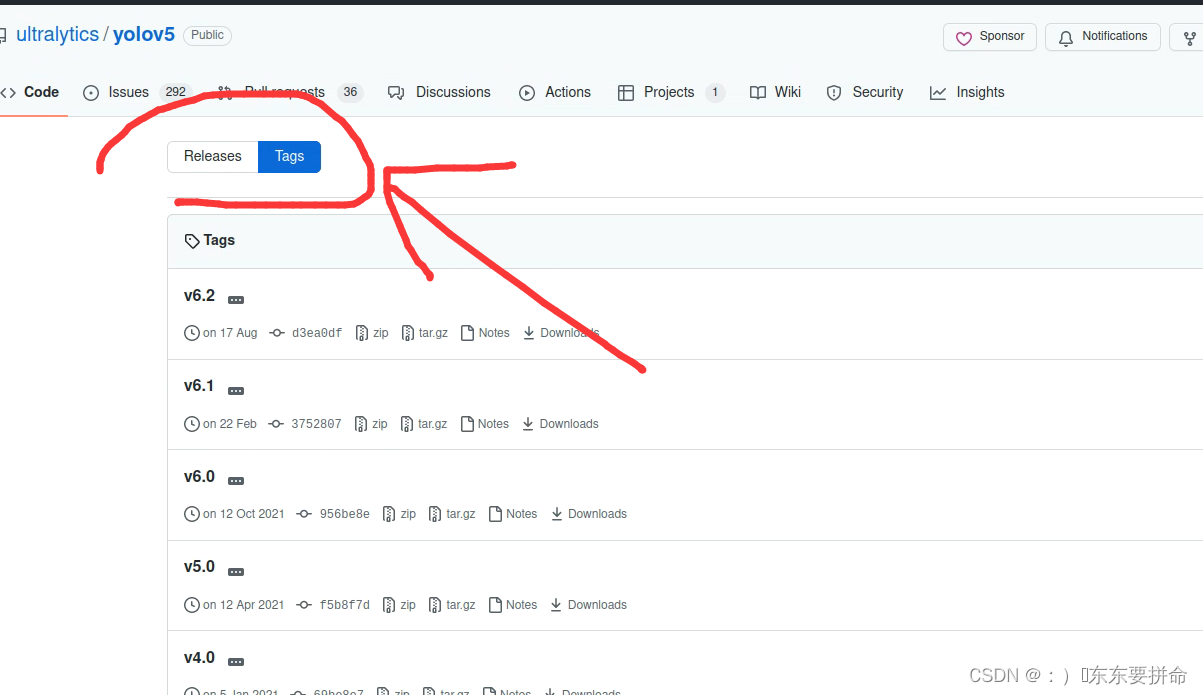
打开之后往下翻
找到我划线的
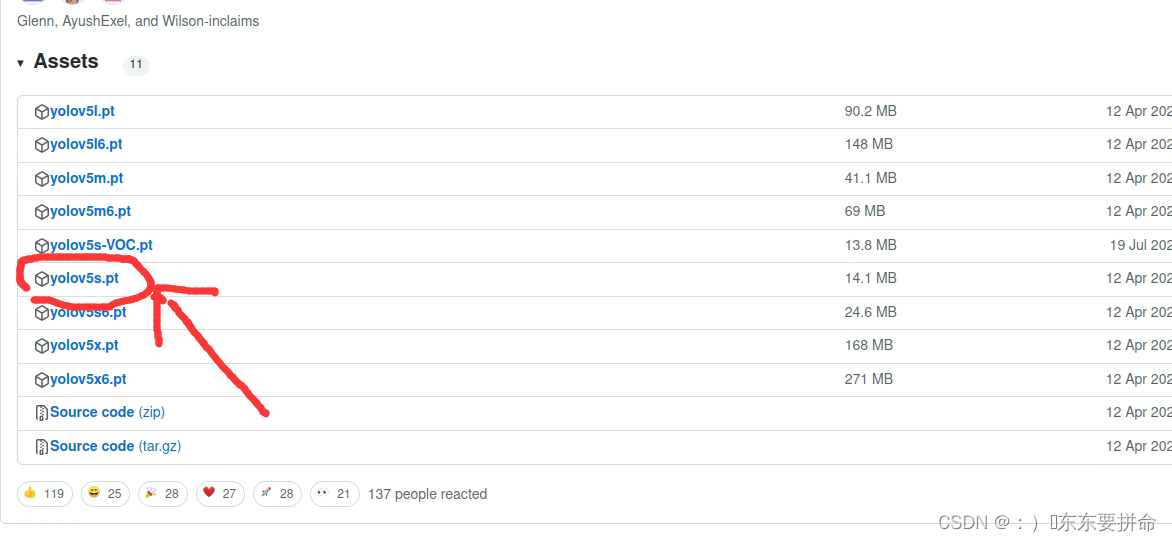
把它下下来
注意哦 小细节一样要在

右击复制paste
不然复制到权重文件还是会报错的
复制到这里还是失败的哦
最后
出现在这里就行了
接着去愉快的跑detect吧
这就是YOLOv5 的hello world哦


恭喜你们,也恭喜我自己,开始了object detection 的一小步
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
这似乎应该有一个直截了当的答案,但在Google上花了很多时间,所以我找不到它。这可能是缺少正确关键字的情况。在我的RoR应用程序中,我有几个模型共享一种特定类型的字符串属性,该属性具有特殊验证和其他功能。我能想到的最接近的类似示例是表示URL的字符串。这会导致模型中出现大量重复(甚至单元测试中会出现更多重复),但我不确定如何让它更DRY。我能想到几个可能的方向...按照“validates_url_format_of”插件,但这只会让验证干给这个特殊的字符串它自己的模型,但这看起来很像重溶液为这个特殊的字符串创建一个ruby类,但是我如何得到ActiveRecord关联这个类模型
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
如何正确创建Rails迁移,以便将表更改为MySQL中的MyISAM?目前是InnoDB。运行原始执行语句会更改表,但它不会更新db/schema.rb,因此当在测试环境中重新创建表时,它会返回到InnoDB并且我的全文搜索失败。我如何着手更改/添加迁移,以便将现有表修改为MyISAM并更新schema.rb,以便我的数据库和相应的测试数据库得到相应更新? 最佳答案 我没有找到执行此操作的好方法。您可以像有人建议的那样更改您的schema.rb,然后运行:rakedb:schema:load,但是,这将覆盖您的数据。我的做法是(假设
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题