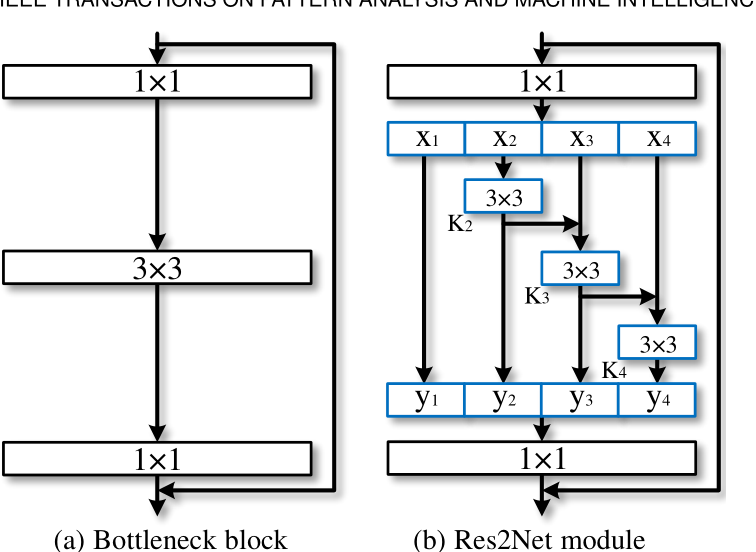
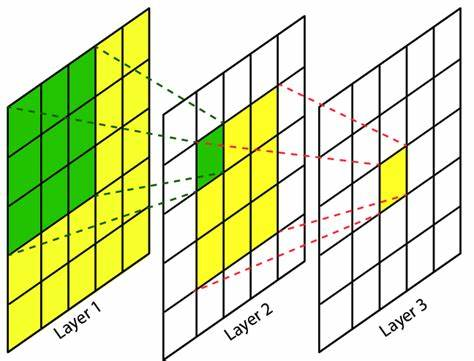
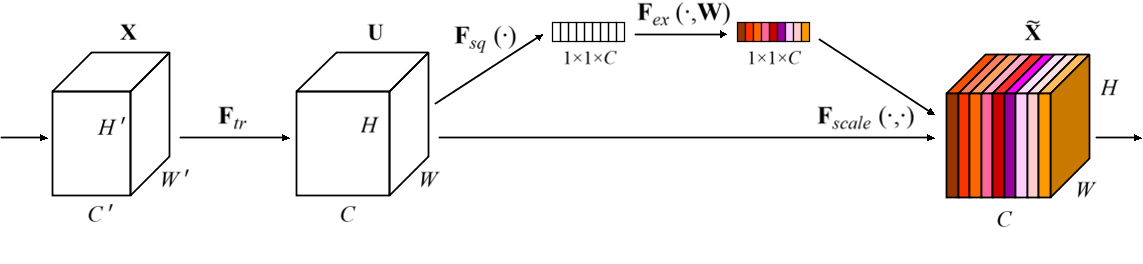
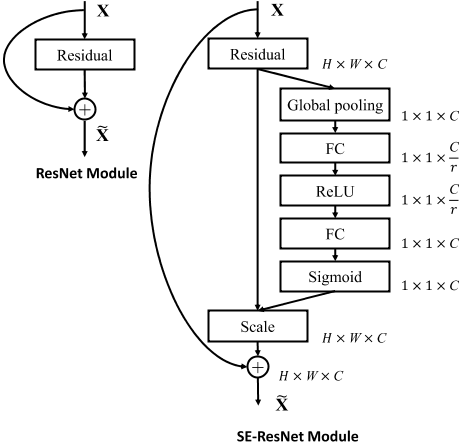
require'mechanize'agent=Mechanize.newlogin=agent.get('http://www.schoolnet.ch/DE/HomeDE.htm')agent.clicklogin.link_withtext:/Login/然后我得到Mechanize::UnsupportedSchemeError。 最佳答案 Mechanize不支持javascript但您可以将搜索字段添加到表单并为其分配搜索词并使用mechanize提交表单form=page.forms.firstform.add_fie
解开谜团:深入探索ChatGPT的技术奇迹。ChatGpt无处不在,无论是在播客、博客、YouTube还是社交媒体上。当我注意到这项新技术如此受欢迎时,我决定试一试,我被震惊了!有很多关于ChatGpt及其魔力的博客,但在这篇博客中,我将深入探讨其内部技术及其工作原理!ChatGpt简介根据OpenAI,ChatGpt被描述为:“我们训练了一个名为ChatGpt的模型,它以对话方式进行交互。对话格式使ChatGpt可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。ChatGPT是InstructGPT的兄弟模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。”OpenA
我有一个大型用户数据库(约200,000个),我正在将其从ASP.NET应用程序转移到RubyonRails应用程序。我真的不想要求每个用户重置他们的密码,所以我试图在Ruby中重新实现C#密码哈希函数。旧函数是这样的:publicstringEncodePassword(stringpass,stringsaltBase64){byte[]bytes=Encoding.Unicode.GetBytes(pass);byte[]src=Convert.FromBase64String(saltBase64);byte[]dst=newbyte[src.Length+bytes.Leng
近期,以“生成式人工智能”(GenerativeAI)为核心技术的聊天机器人ChatGPT火爆全球。百度、阿里巴巴、科大讯飞、360等国内企业纷纷抛出ChatGPT相关进展,打造中国版的ChatGPT。科大讯飞此前在投资者互动平台表示,ChatGPT主要涉及到自然语言处理相关技术,属于认知智能领域的应用之一,公司在该方向技术和应用具备长期深厚的积累。并称2022年12月已进一步启动生成式预训练大模型任务攻关,类ChatGPT技术将在今年5月率先落地科大讯飞AI学习机产品。近日,科大讯飞副总裁、研究院执行院长刘聪围绕什么是ChatGPT,它强在哪里?会对未来世界带来哪些颠覆性影响?进一步阐述Ch
导语 | 在C++11标准之前,C++中默认的传值类型均为Copy语义,即:不论是指针类型还是值类型,都将会在进行函数调用时被完整的复制一份!对于非指针而言,开销及其巨大!因此在C++11以后,引入了右值和Move语义,极大地提高了效率。本文介绍了在此场景下两个常用的标准库函数:move和forward。一、特性背景(一)Copy语义简述C++中默认为Copy语义,因此存在大量开销。以下面的代码为例:0_copy_semantics.cc#include#includeclassObject{public:Object(){std::coutv;v.push_back(obj);}最终的输出
我是.Net程序员,希望扩展并可能在我当前和future的Web应用程序中使用一些Ruby。看着IronRubyWebsite最后一次发布是将近一年前:2011年3月13日。否announcements从那时起就已经在他们的网站上制作了。考虑到所有这些,我想到了几个问题:IronRuby死了吗?如果该项目已终止,是否有任何替代方案集成到.Net中?如果它还活着,它仍然是一个积极维护的项目吗?我在哪里可以找到最新版本?我是不是找错了树?我是否应该将ruby保留为ruby,将.Net保留为.Net,这两个独立的实体永远不会在同一个项目中相遇?我在stackoverflow上看到过有
目录引言:一、inode和block1、inode和block概述2、inode的内容1.inode包含文件的元信息(文件属性)2.用stat命令可以查看某个文件的inode信息3.Linux系统文件三个主要的时间属性 4.目录文件的结构3、inode的号码5、硬盘分区后的结构6、inode的大小7、inode的特殊作用 二、链接文件三、案例:恢复EXT类型的文件四、案例:恢复XFS类型的文件五、日志文件1.日志的功能2.日志文件的分类3.日志保存位置1.常见的一些日志文件:2.扩展:日志检查3.小结:4.日志消息的级别5.用户日志分析六、总结引言:inode是一个重要概念,是理解Uni
我正在从基于Web表单的遗留应用程序引导Aurelia。我的身份验证相关信息在自定义基页类的Web表单应用程序中维护。我如何将此身份验证信息传递和维护到Aurelia的全局范围?这样我就可以在使用路由构建菜单时使用它来根据用户/Angular色显示/隐藏某些菜单项? 最佳答案 您可以将逻辑添加到您的自定义基页中以添加标记到文档的头部,使所有信息都可用于javascript应用程序:...window.appInfo={user:'foo',bar:'baz'};...然后在您的aurelia应用中,您可以根据需要访问此信息:expo
我已经阅读了很多博客文章,其中提供了IE中“操作中止”错误的原因和解决方案。我最近构建了一个应用程序,有时会为某些用户出现此错误。让我详细解释一下。该应用程序是在VS2008中构建的.NET2.0、ASP.NET和C#Web应用程序。它使用ComponentOneWeb控件以及标准的VisualStudio控件。在其中一个网页中,我让用户在一组ComponentOneWeb输入控件中键入输入,然后将其添加到集合中。集合绑定(bind)到中继器,每次在集合中创建新条目时,中继器都会反弹。如果用户从转发器中删除条目(使用命令按钮),集合将更新并重新回到转发器。当应用程序提交给最终用户进行测
将基于ASP.NETSOAP的Web服务转换为基于JSON的响应的正确方法是什么?...然后从jQuery中调用它们?集成基于jQuery的AJAX和ASP.NET时的“最佳实践”是什么?文章?书? 最佳答案 可以使用System.Runtime.Serialization和System.Runtime.Serialization.JSON将JSON转换为.NET类。我怀疑您对设置从客户端到服务器的函数调用更感兴趣。我觉得值得一试thistutorial.在本教程中,您需要添加一个网络服务“.asmx”文件。在asmx文件中,您将能