目录
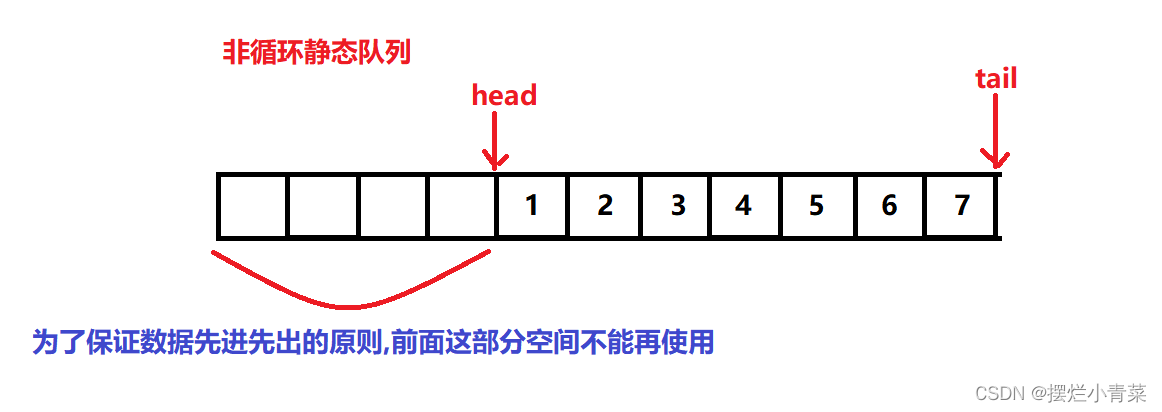
- 循环队列一般是一种静态的线性数据结构,其中的数据符合先进先出的原则.
- 循环队列的容器首地址和容器尾地址通过特定操作(比如指针链接,数组下标取余等方式)相连通,从而实现了容器空间的重复利用(在一个非循环静态队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间)

维护队列的结构体:
typedef struct { int * arry; //指向堆区数组的指针 int head; //队头指针 int tail; //队尾指针(指向队尾数据的下一个位置)(不指向有效数据) int capacity;//静态队列的容量 } MyCircularQueue;
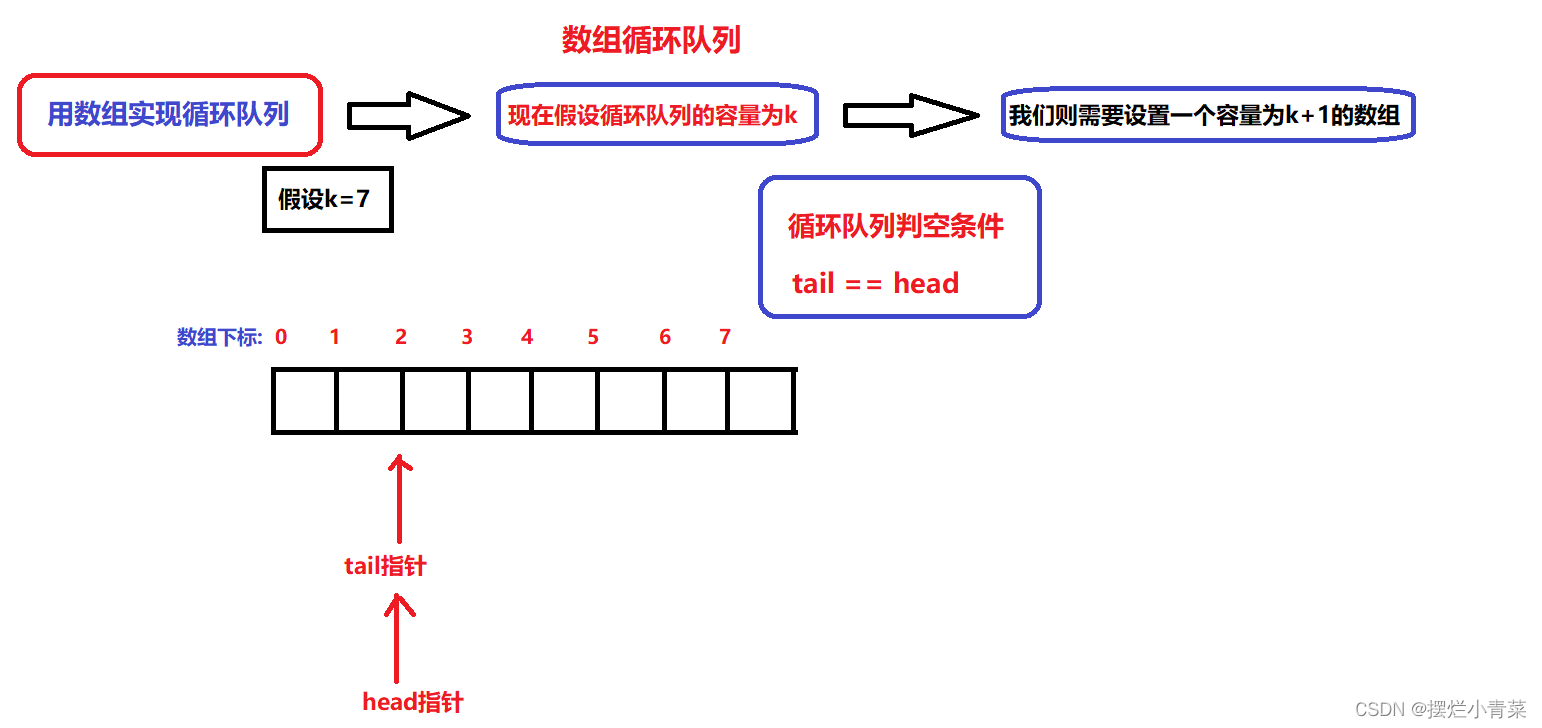
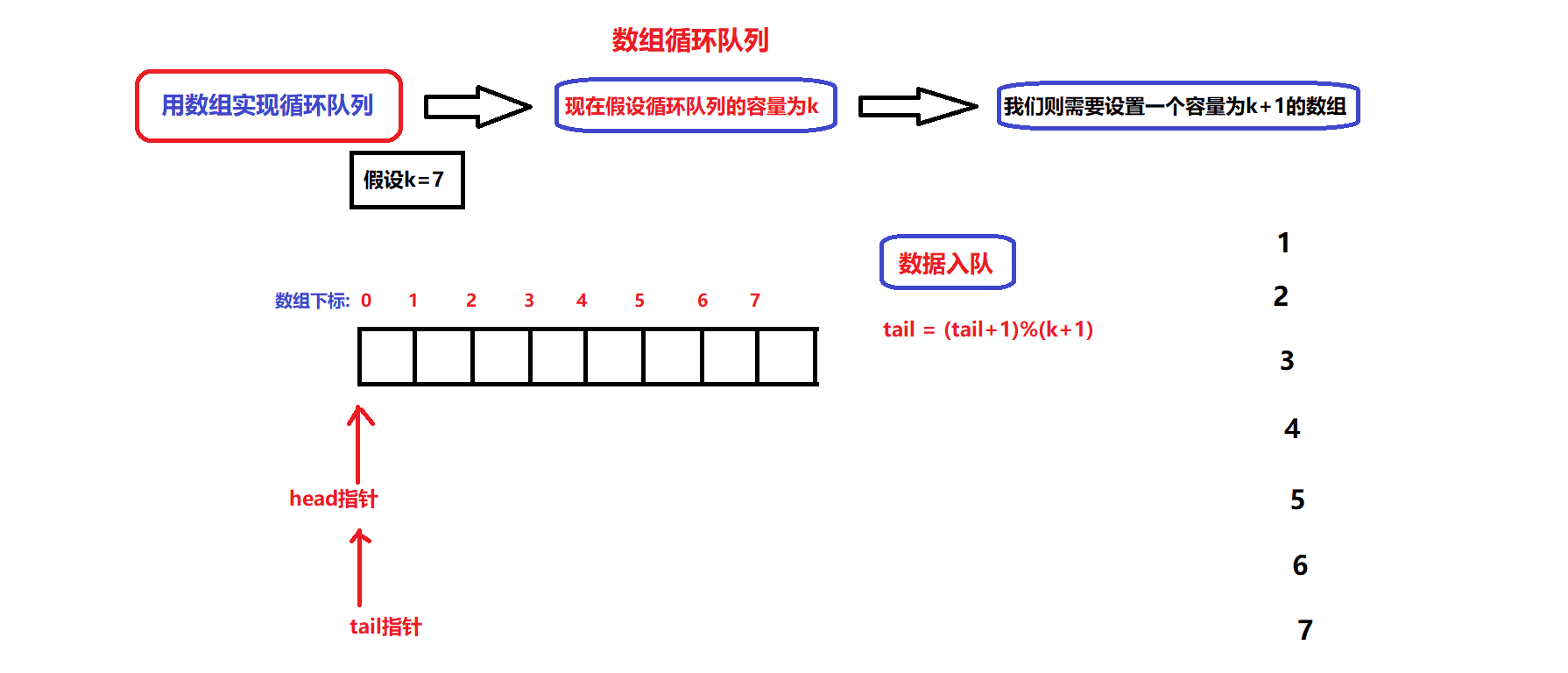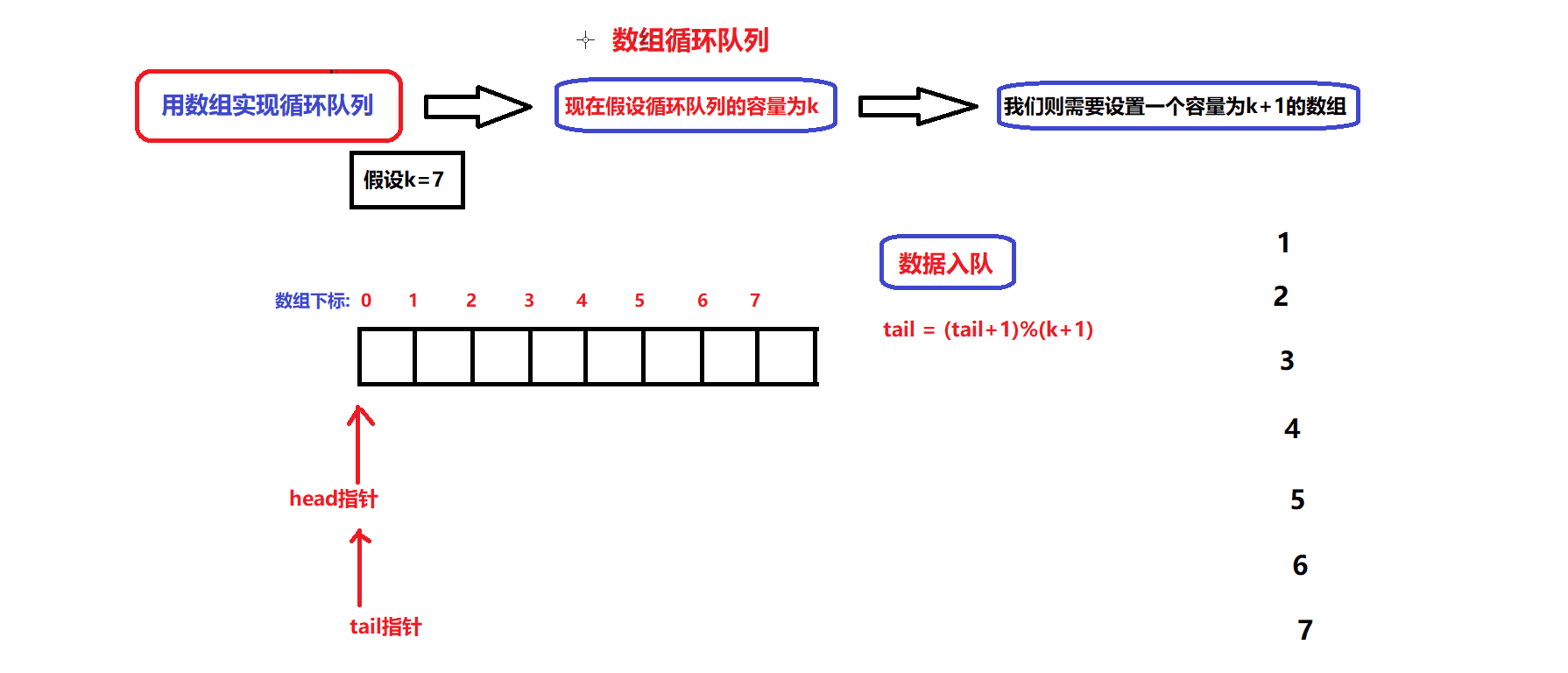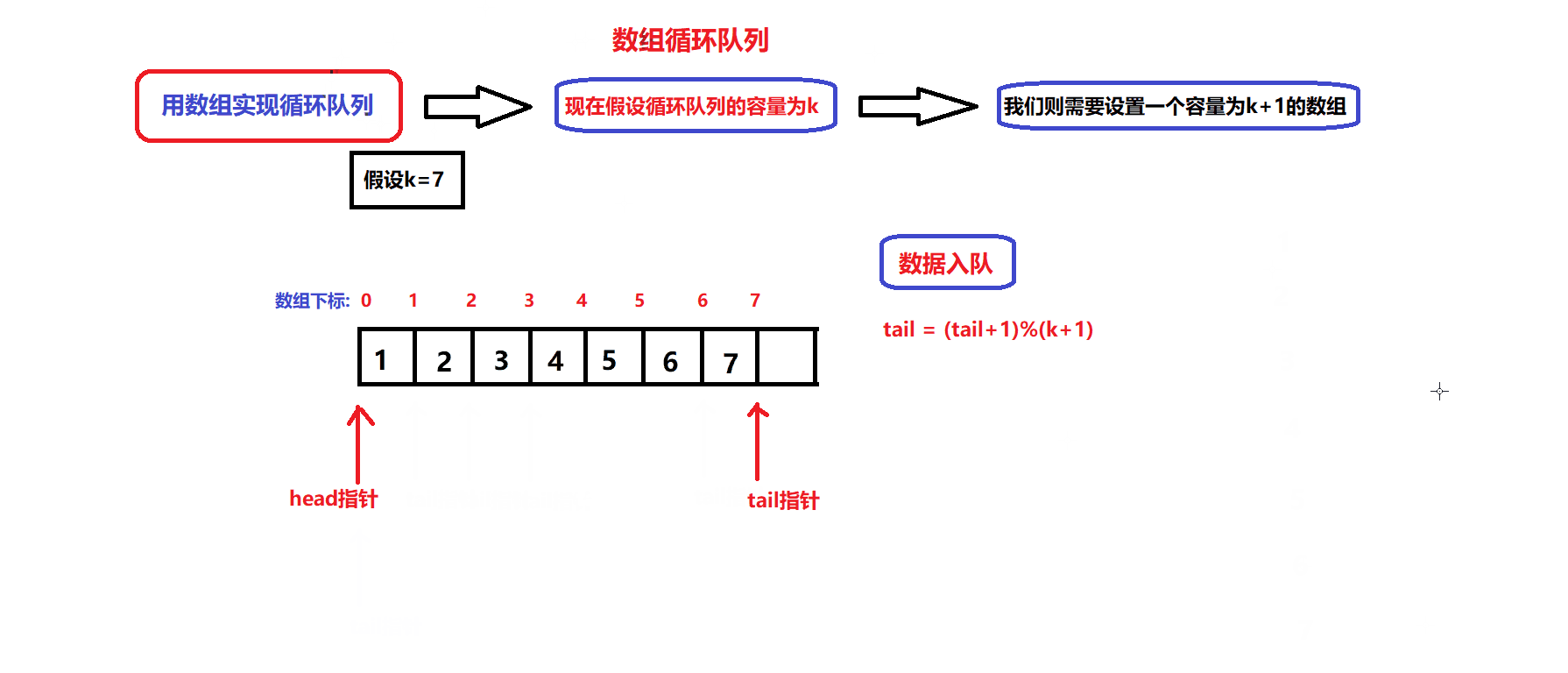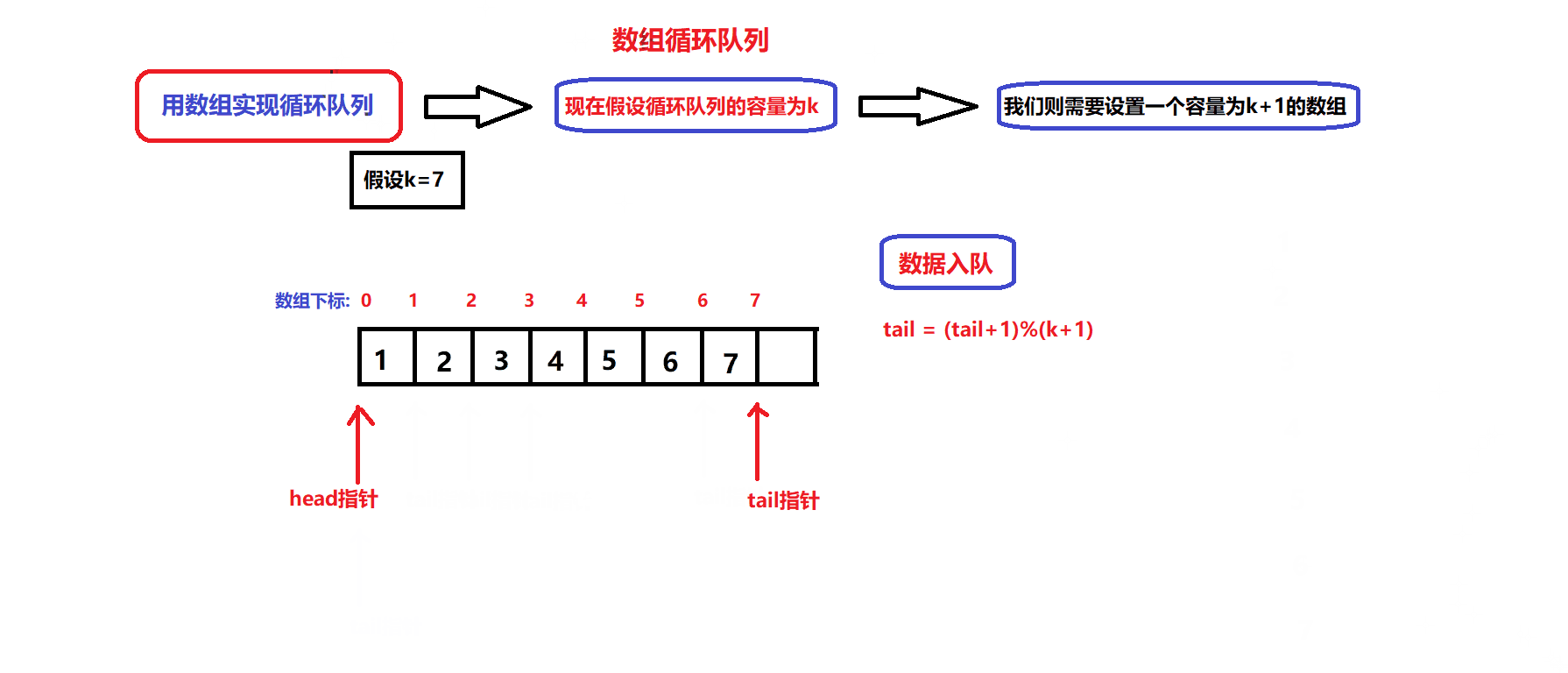
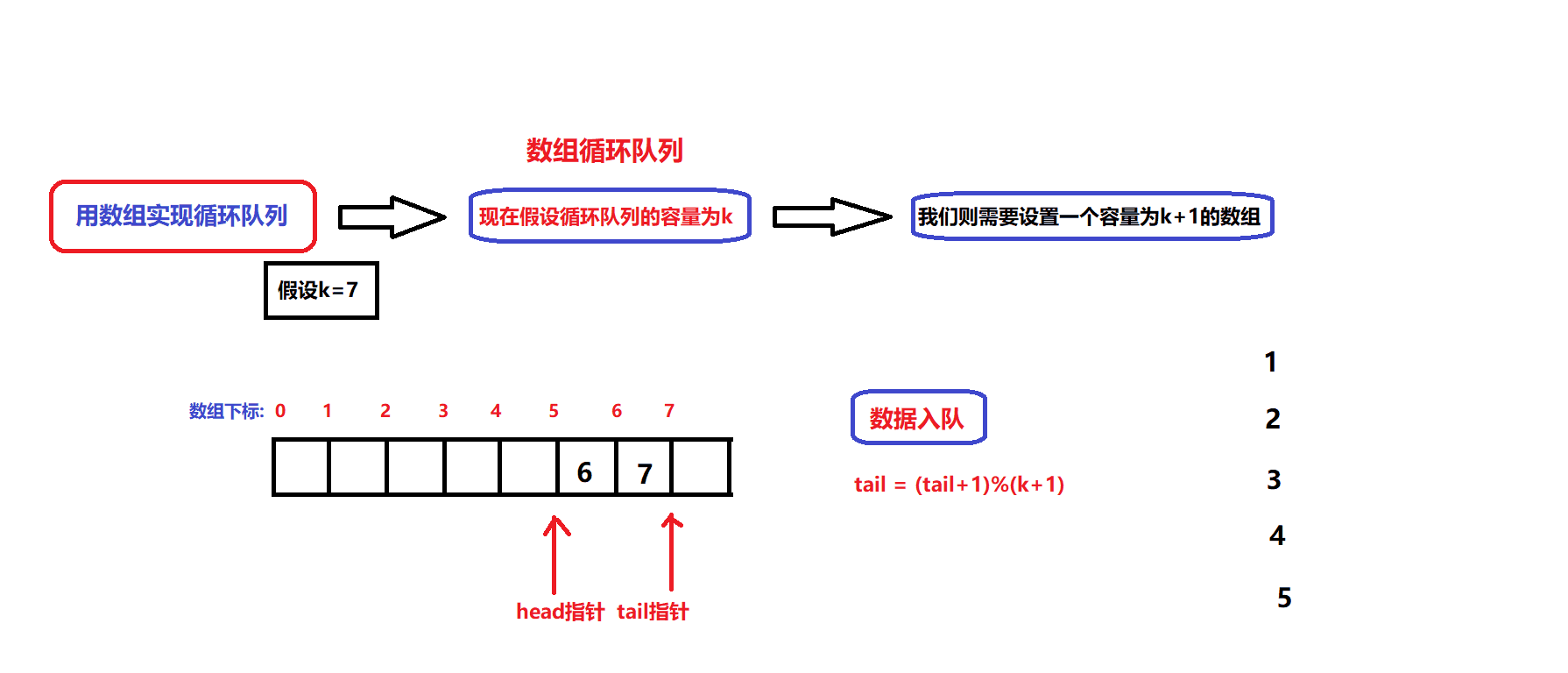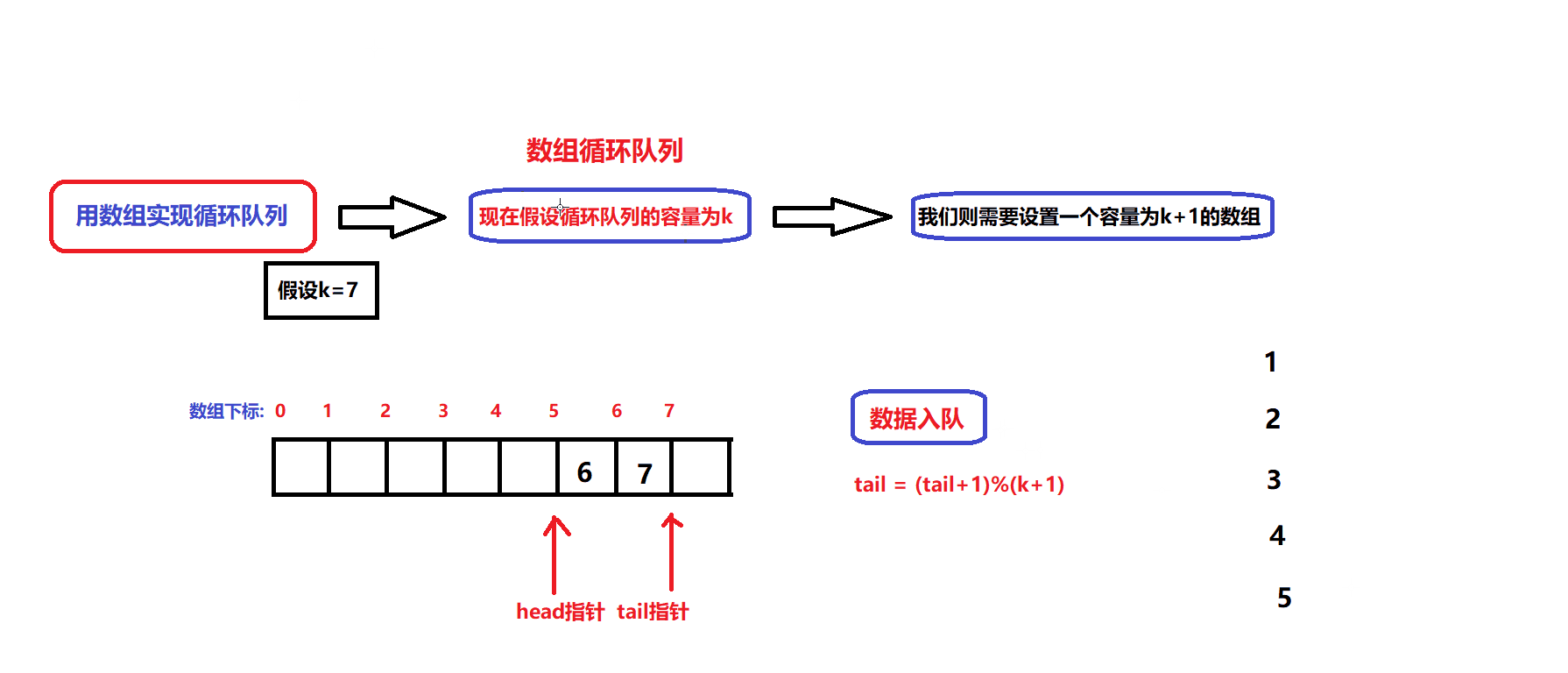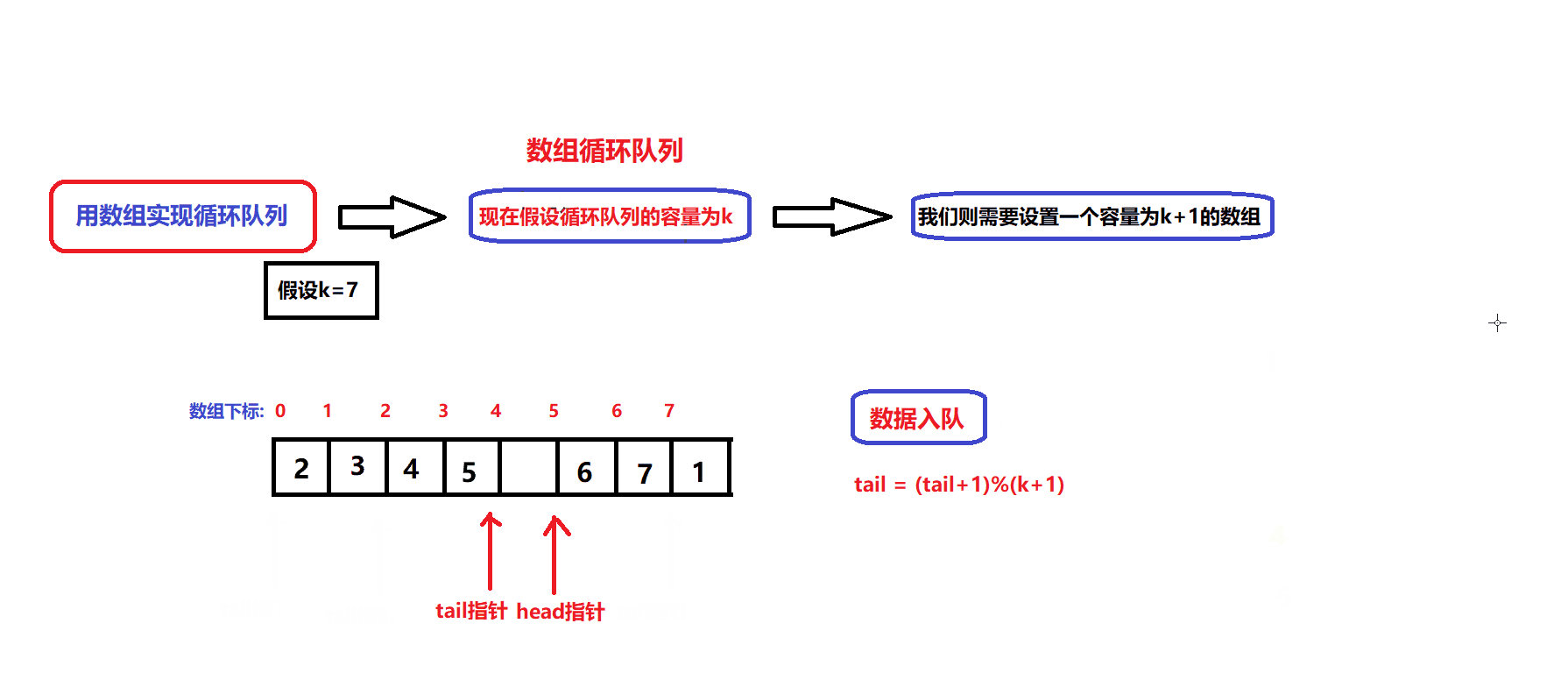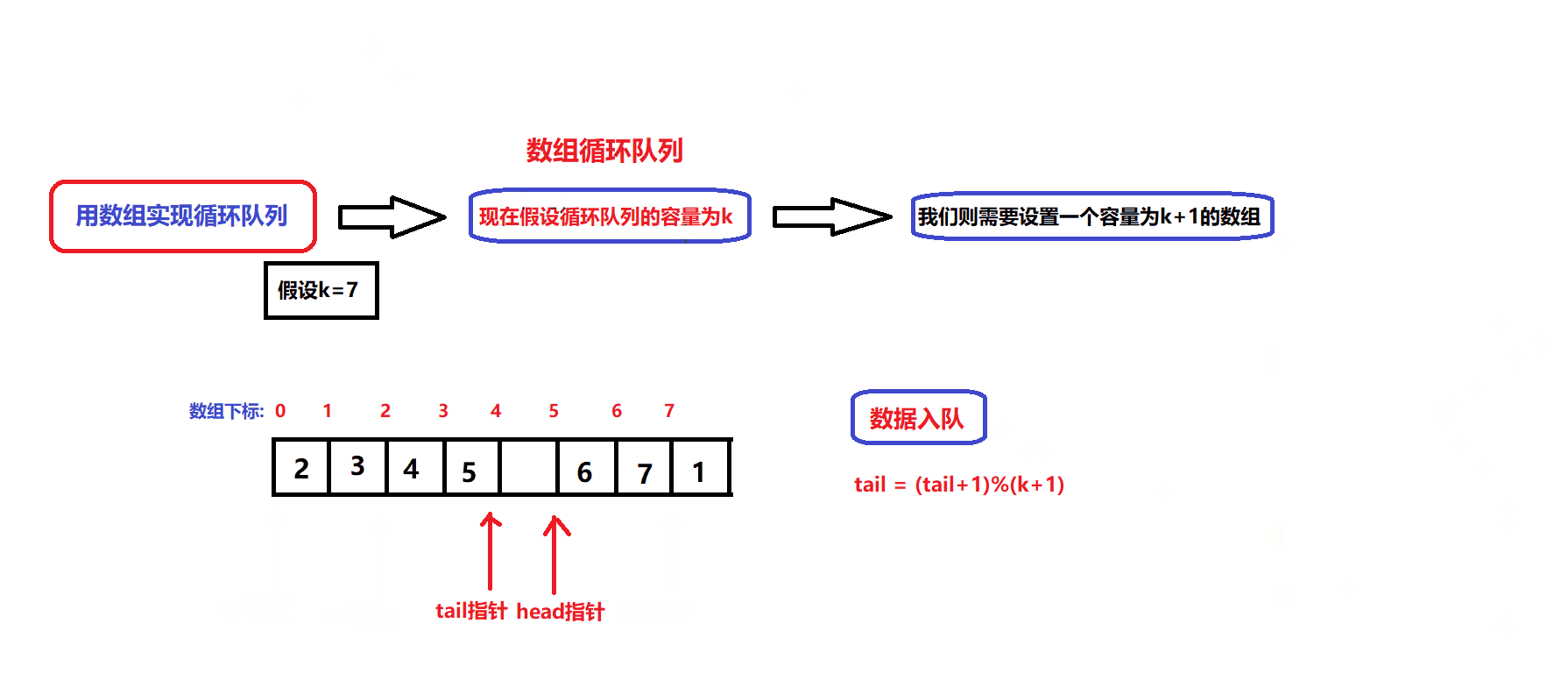
我们假定静态数组的容量为k(可存储k个数据):
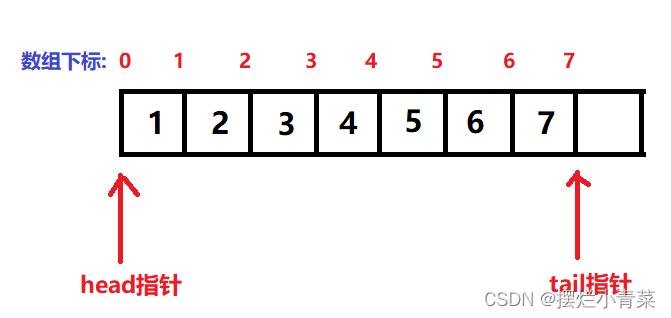
- 根据队列的基本数据结构:有两个指针用于维护数组中的有效数据空间,分别为head指针和tail指针,head指针用于指向队头数据,tail用于指向队尾数据的下一个位置(即tail指针不指向有效数据)
- 如图所示,head指针和tail指针之间就是有效数据的内存空间
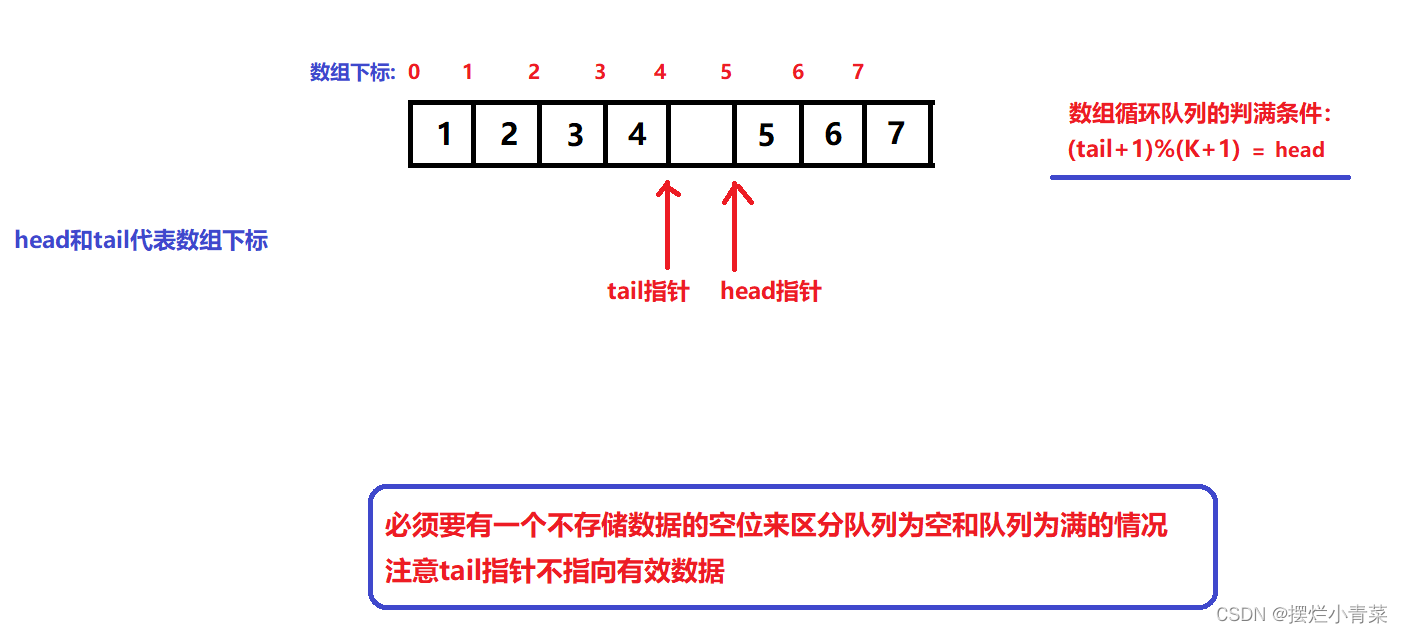
- 通过head指针和tail指针的关系来实现队列的判满(判断队列空间是否已被占满)与判空(判断队列是否为空队列);为了达到这个目的,我们需要将静态数组的容量大小设置为k+1(即多设置一个元素空间)
- 队列的判空条件: tail == head;
- 队列的判满条件: (tail+1)%(k+1) == head;
另外一种情形:
- 由此我们可以先设计出队列的判满和判空接口:
bool myCircularQueueIsEmpty(MyCircularQueue* obj) //判断队列是否为空 { assert(obj); return (obj->tail == obj->head); } bool myCircularQueueIsFull(MyCircularQueue* obj) //判断队列是否为满 { assert(obj); return ((obj->tail+1)%(obj->capacity +1) == obj->head); }
- 在堆区上创建MyCircularQueue结构体,同时为队列申请一个空间大小为(k+1)*sizeof(DataType)字节的数组:
MyCircularQueue* myCircularQueueCreate(int k) //k个容量大小的循环队列的初始化接口 { MyCircularQueue * tem = (MyCircularQueue *)malloc(sizeof(MyCircularQueue)); //开辟维护循环队列的结构体 if(NULL == tem) { perror("malloc failed"); exit(-1); } tem->arry = NULL; tem->capacity = k; //队列的数据容量为k tem->arry = (int*)malloc((k+1)*sizeof(int)); //开辟堆区数组 if(NULL == tem->arry) { perror("malloc failed"); exit(-1); } //将head,tail下标初始化为0 tem->head = 0; tem->tail = 0; return tem; }
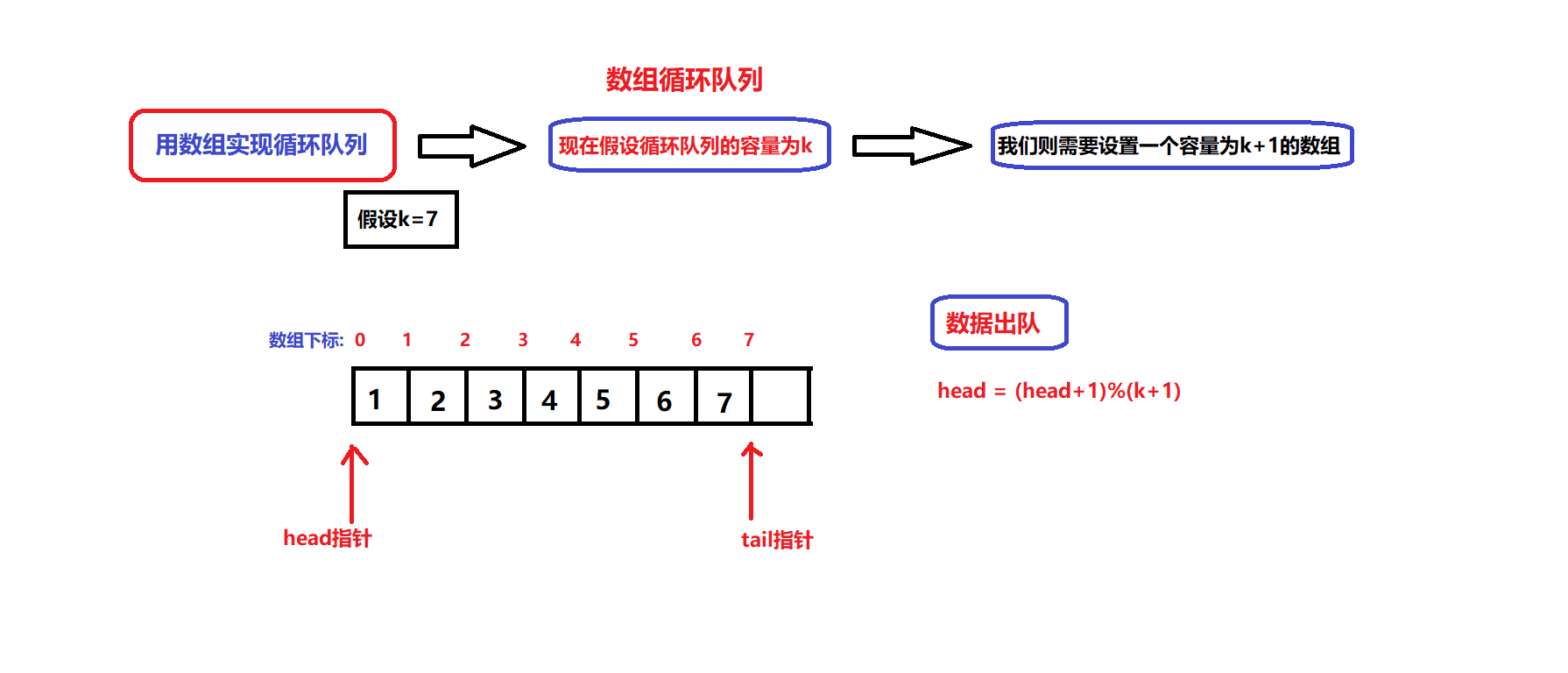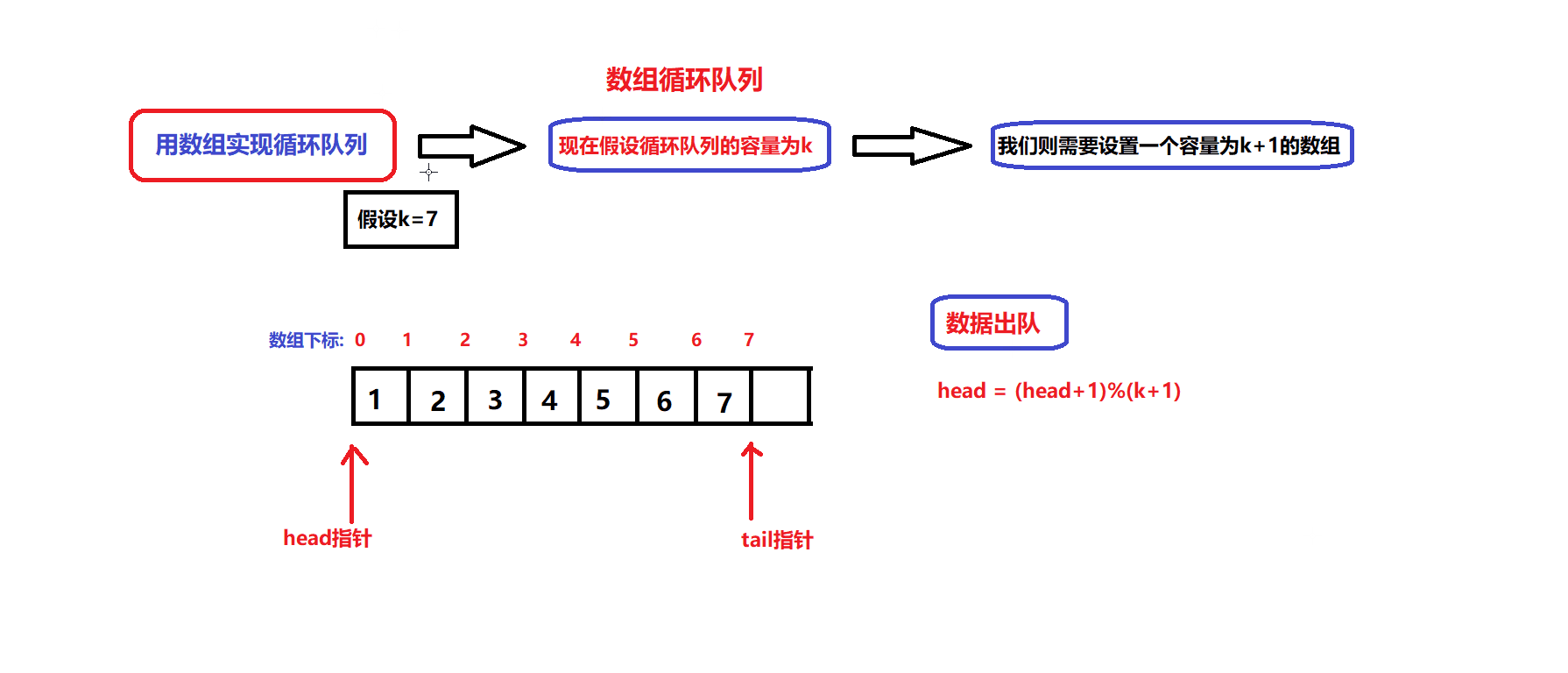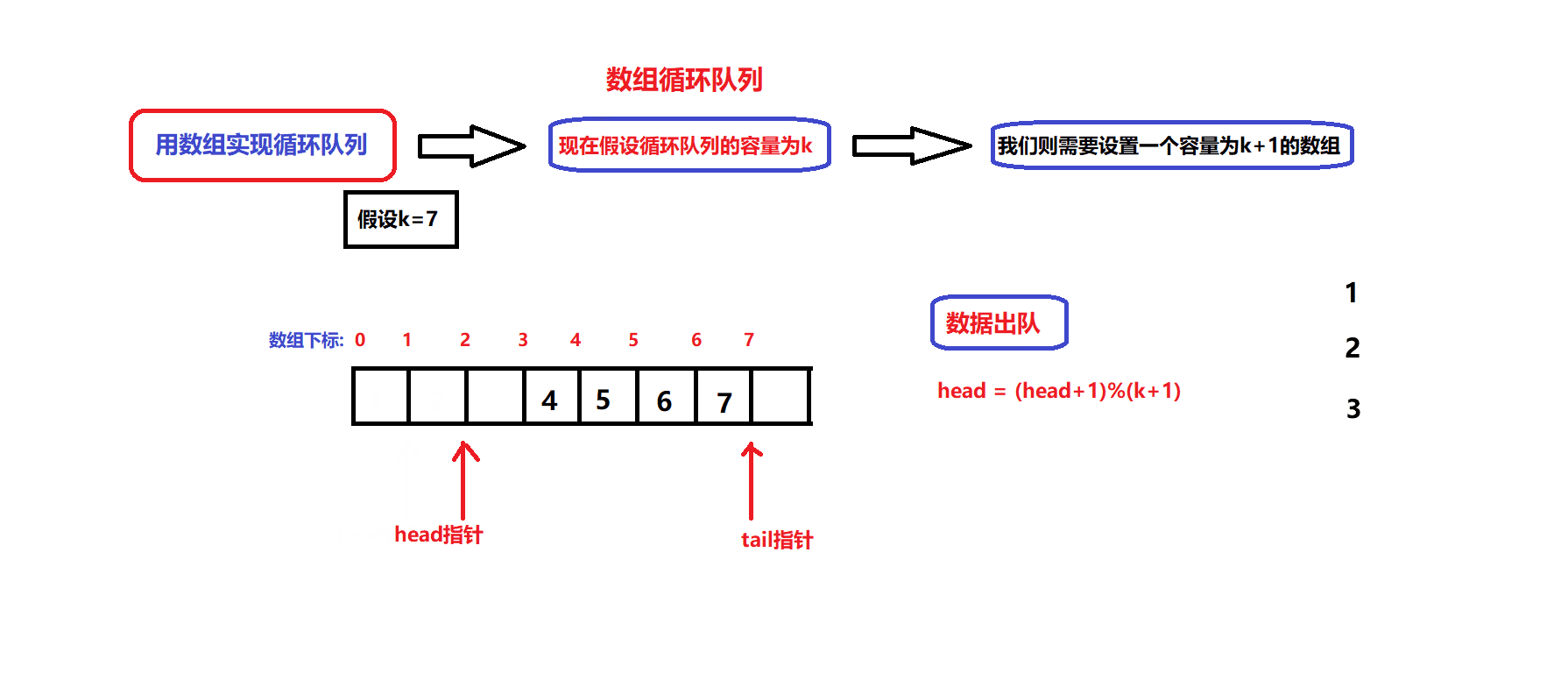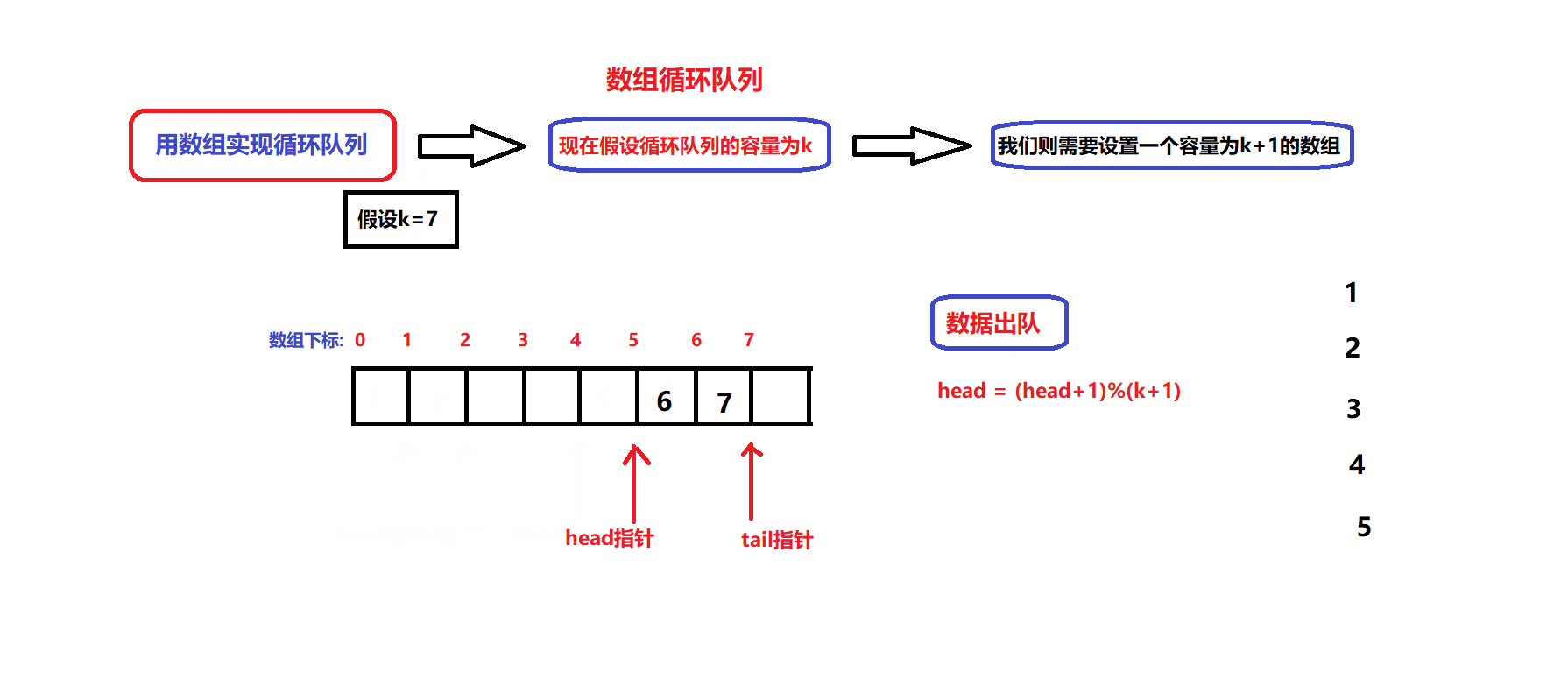
数据出队和入队的图解:
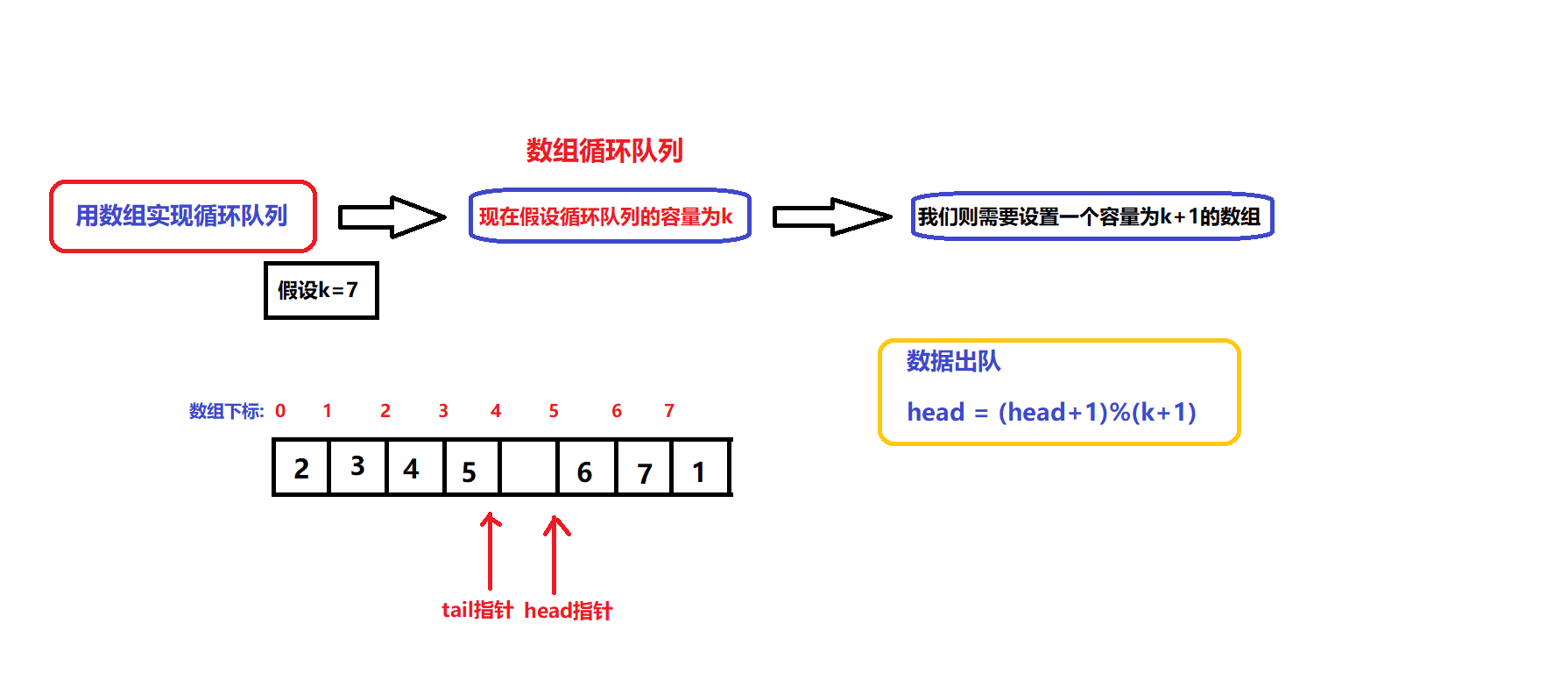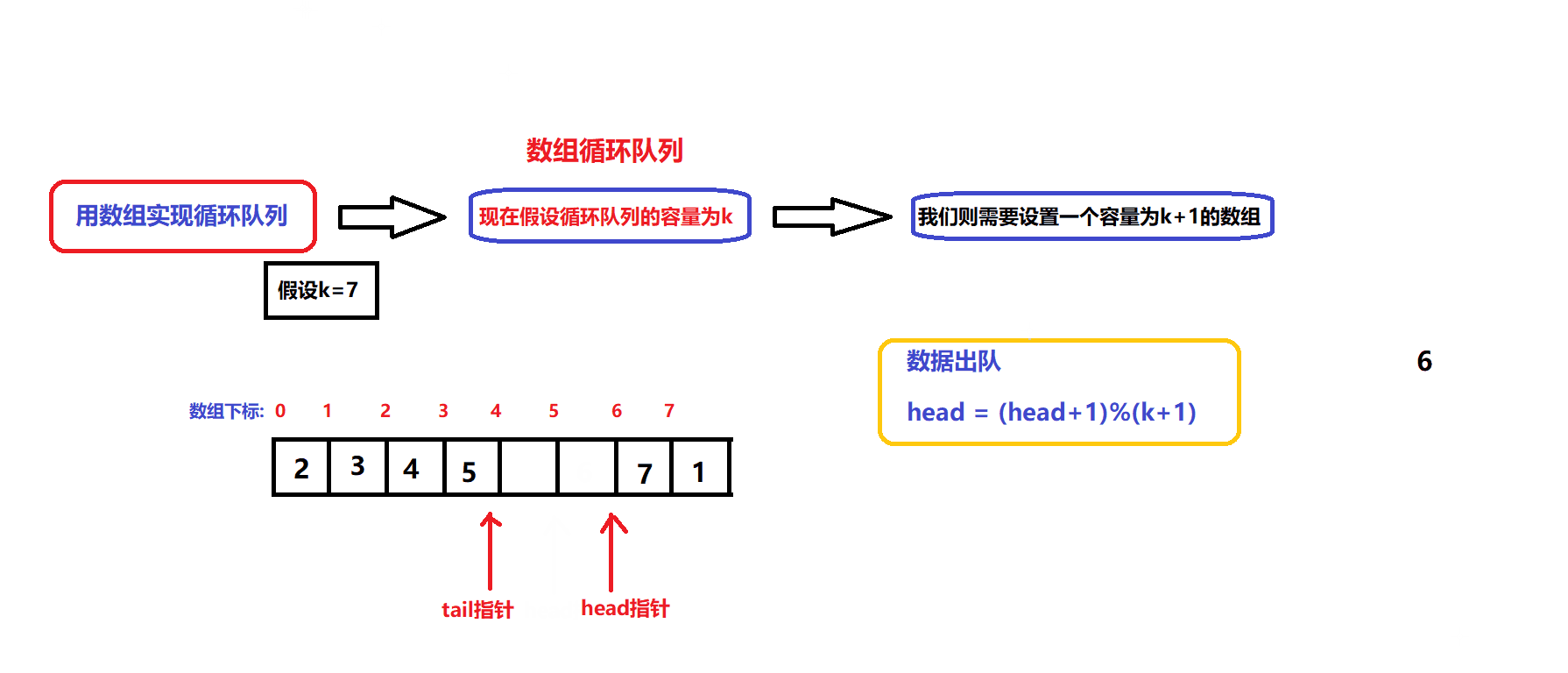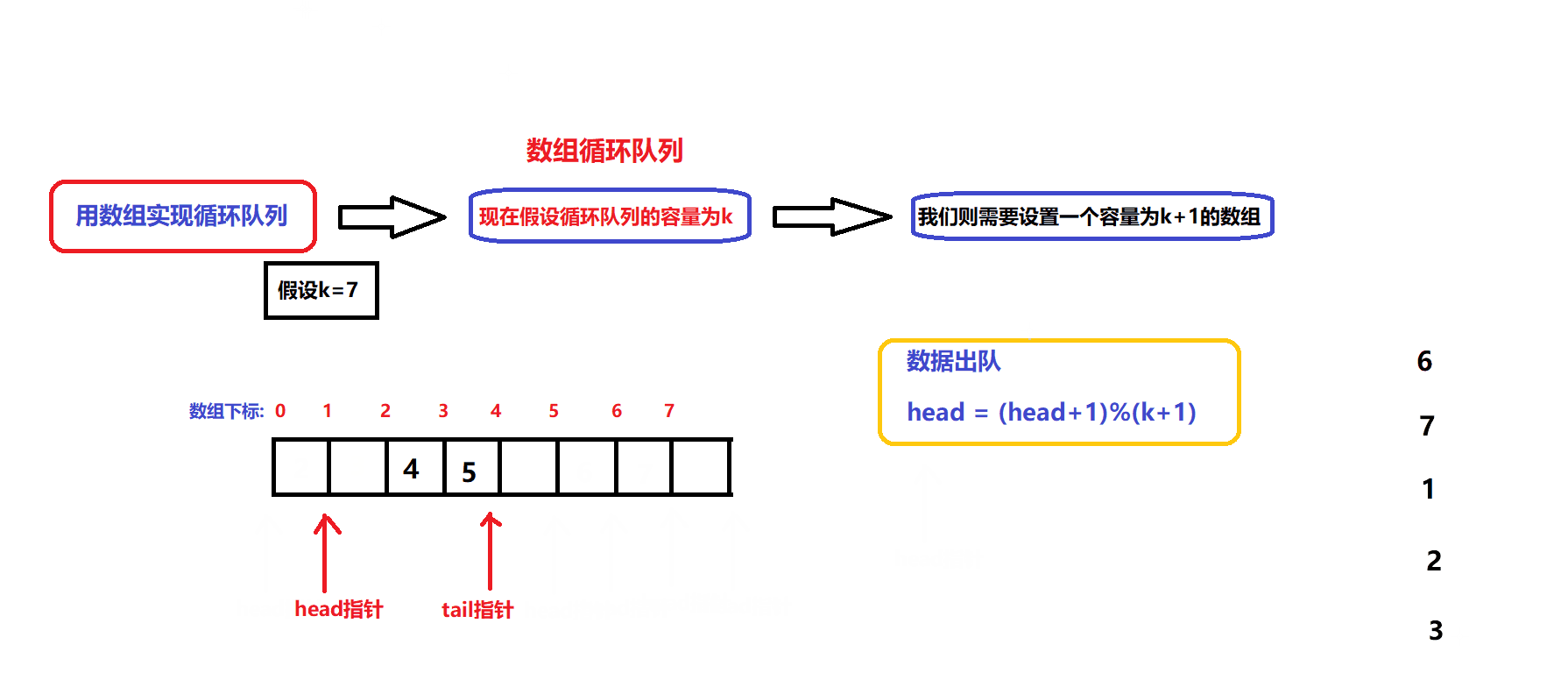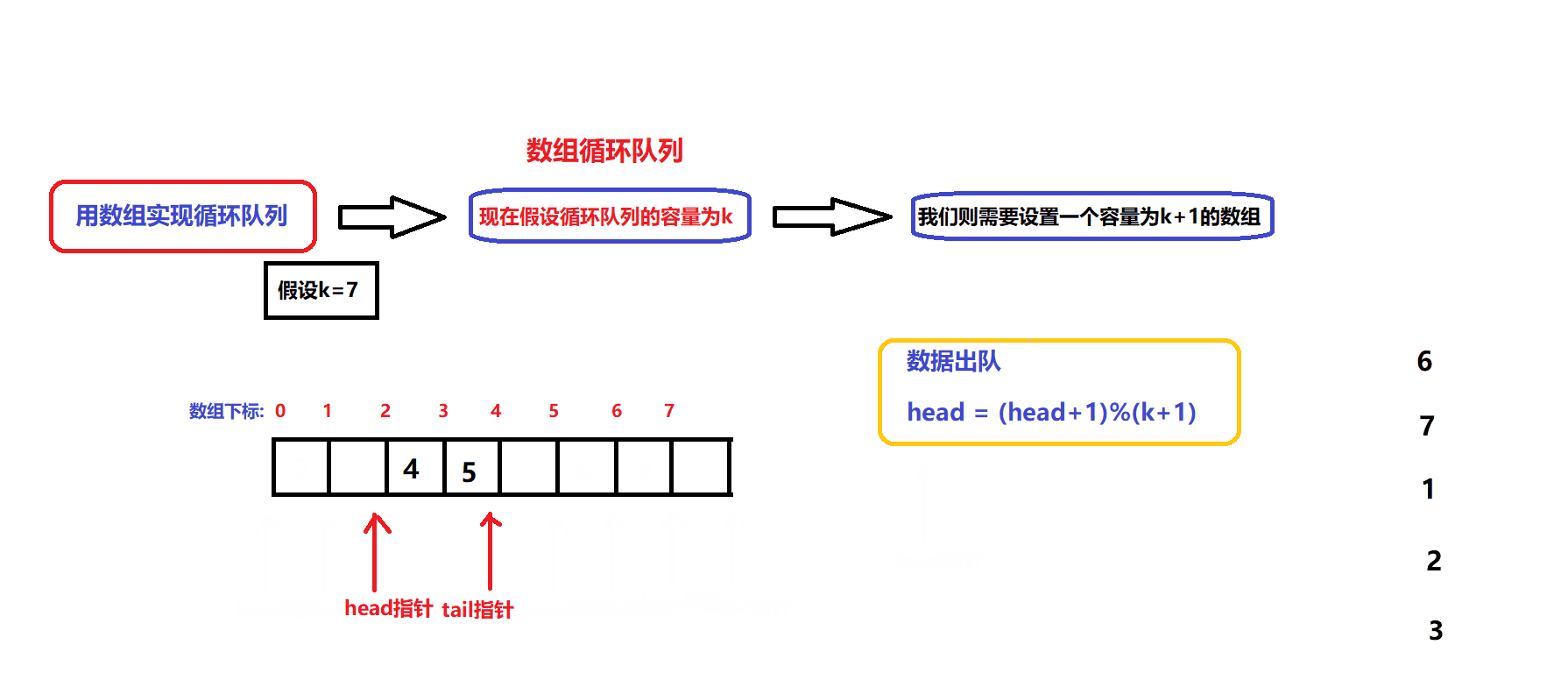
- 根据图解我们可以设计出数据入队和出队的接口:
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) //数据入队接口 { assert(obj); if(myCircularQueueIsFull(obj)) { return false; } //确保队列没满 obj->arry[obj->tail]=value; obj->tail = (obj->tail + 1)%(obj->capacity +1); return true; }bool myCircularQueueDeQueue(MyCircularQueue* obj) //数据出队接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return false; } //确保队列不为空 obj->head = (obj->head +1)%(obj->capacity +1); return true; }
返回队头数据的接口:
int myCircularQueueFront(MyCircularQueue* obj) //返回队头数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } return obj->arry[obj->head]; }返回队尾数据的接口:
int myCircularQueueRear(MyCircularQueue* obj) //返回队尾数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } int labelret = ((obj->tail-1)>=0)? obj->tail-1 : obj->capacity; //注意tail如果指向数组首地址,则尾数据位于数组最后一个位置 return obj->arry[labelret]; }队列的销毁接口:
void myCircularQueueFree(MyCircularQueue* obj) //销毁队列的接口 { assert(obj); free(obj->arry); obj->arry = NULL; free(obj); obj = NULL; }
数组循环队列总体代码:
typedef struct { int * arry; //指向堆区数组的指针 int head; //队头指针 int tail; //队尾指针(指向队尾数据的下一个位置)(不指向有效数据) int capacity;//静态队列容量 } MyCircularQueue; bool myCircularQueueIsEmpty(MyCircularQueue* obj); bool myCircularQueueIsFull(MyCircularQueue* obj); //顺序编译注意:先被使用而后被定义的函数要记得进行声明 MyCircularQueue* myCircularQueueCreate(int k) //循环队列初始化接口 { MyCircularQueue * tem = (MyCircularQueue *)malloc(sizeof(MyCircularQueue)); //开辟维护循环队列的结构体 if(NULL == tem) { perror("malloc failed"); exit(-1); } tem->arry = NULL; tem->capacity = k; //队列的数据容量为k tem->arry = (int*)malloc((k+1)*sizeof(int)); //开辟堆区数组 if(NULL == tem->arry) { perror("malloc failed"); exit(-1); } tem->head = 0; tem->tail = 0; return tem; } bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) //数据入队接口 { assert(obj); if(myCircularQueueIsFull(obj)) { return false; } //确保队列没满 obj->arry[obj->tail]=value; obj->tail = (obj->tail + 1)%(obj->capacity +1); return true; } bool myCircularQueueDeQueue(MyCircularQueue* obj) //数据出队接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return false; } //确保队列不为空 obj->head = (obj->head +1)%(obj->capacity +1); return true; } int myCircularQueueFront(MyCircularQueue* obj) //返回队头数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } return obj->arry[obj->head]; } int myCircularQueueRear(MyCircularQueue* obj) //返回队尾数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } int labelret = ((obj->tail-1)>=0)? obj->tail-1 : obj->capacity; //注意tail如果指向数组首地址,则尾数据位于数组最后一个位置 return obj->arry[labelret]; } bool myCircularQueueIsEmpty(MyCircularQueue* obj) //判断队列是否为空 { assert(obj); return (obj->tail == obj->head); } bool myCircularQueueIsFull(MyCircularQueue* obj) //判断队列是否为满 { assert(obj); return ((obj->tail+1)%(obj->capacity +1) == obj->head); } void myCircularQueueFree(MyCircularQueue* obj) //销毁队列的接口 { assert(obj); free(obj->arry); obj->arry = NULL; free(obj); obj = NULL; }力扣题解测试:
链表节点结构体定义:
typedef struct listnode { int data; struct listnode * next; }ListNode;维护链表循环队列的结构体:
typedef struct { int capacity; //记录队列容量大小 ListNode * head; //指向队头节点 ListNode * tail; //指向队尾节点 } MyCircularQueue;
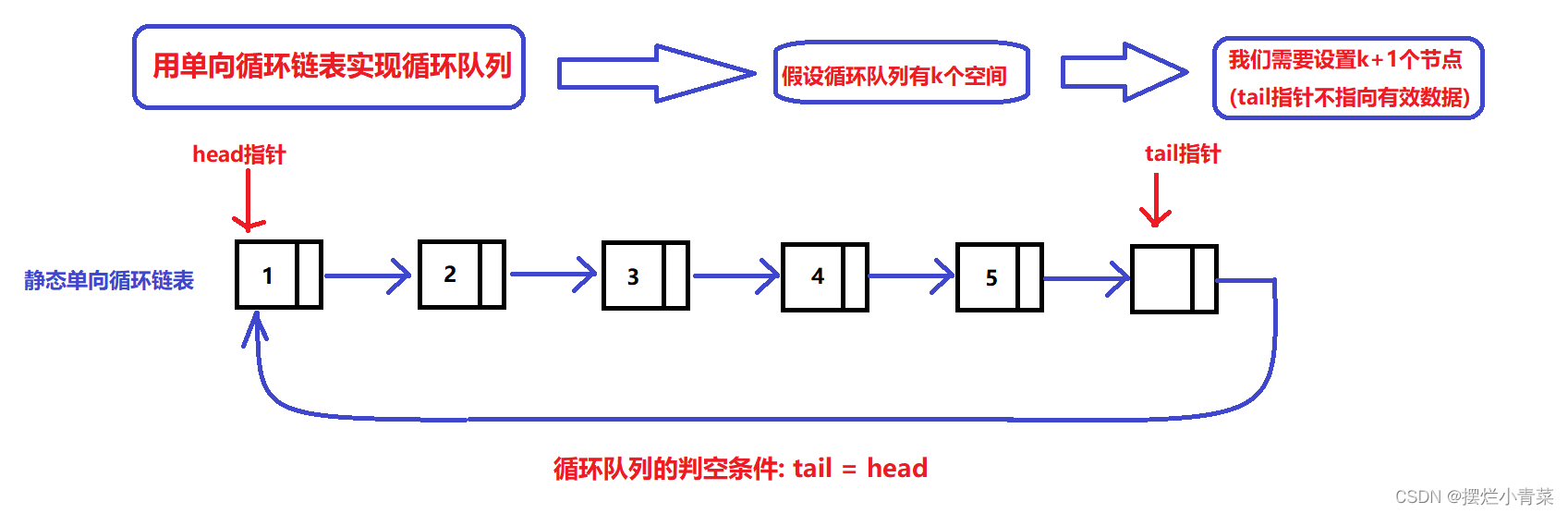
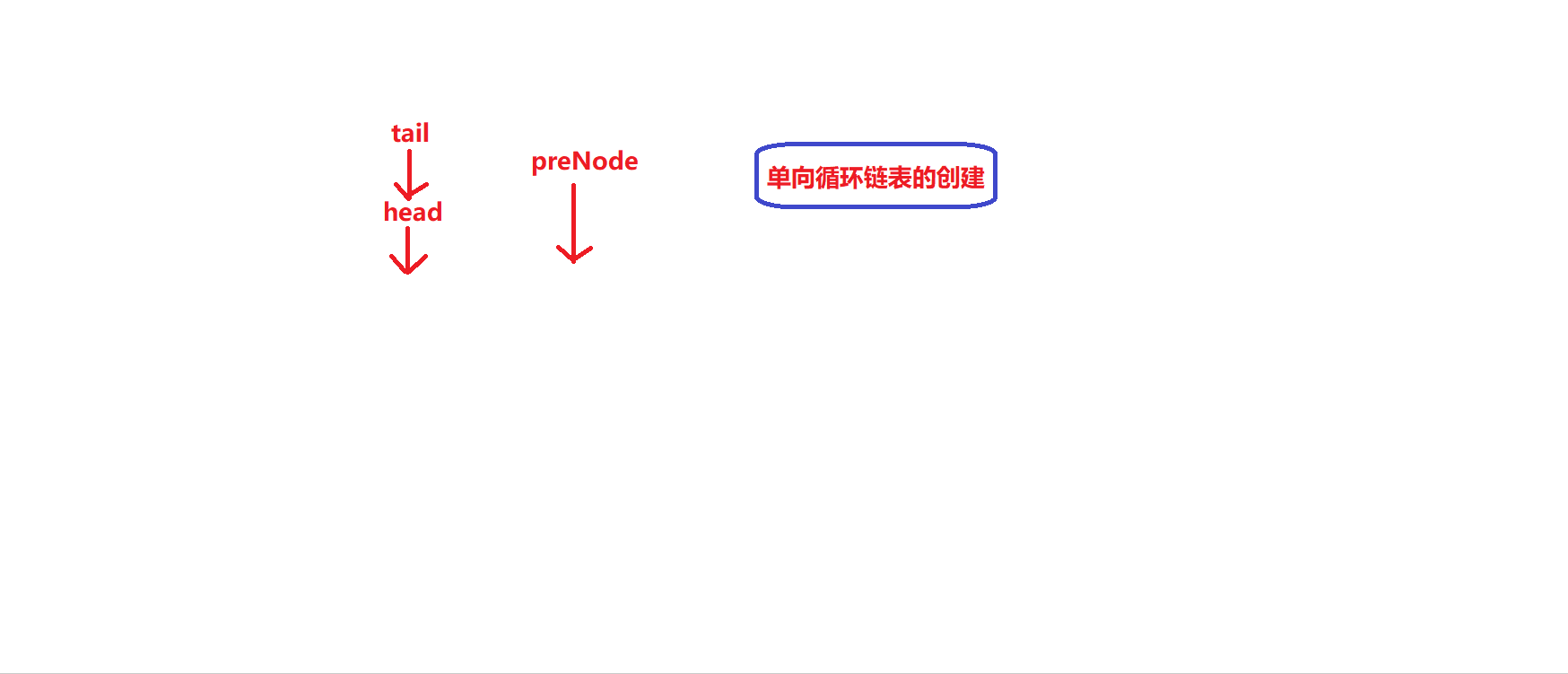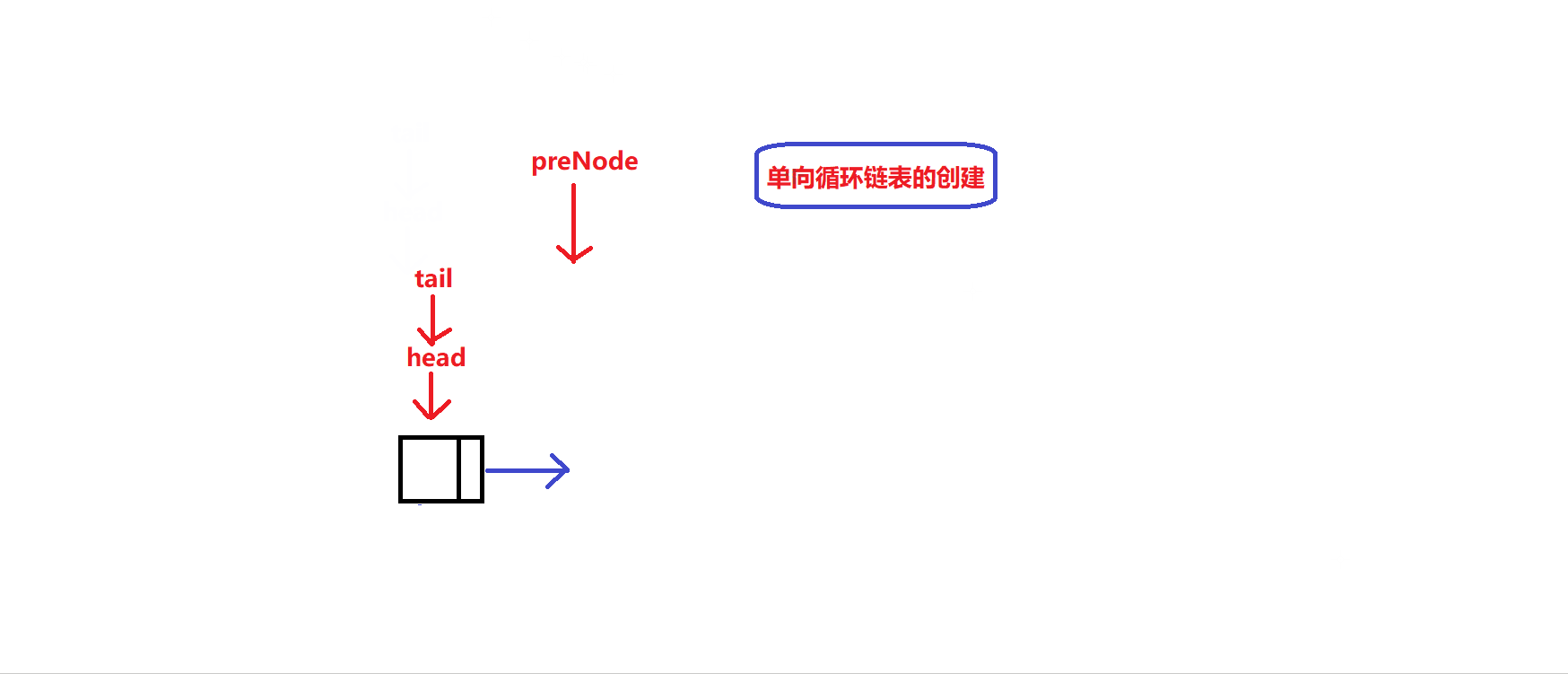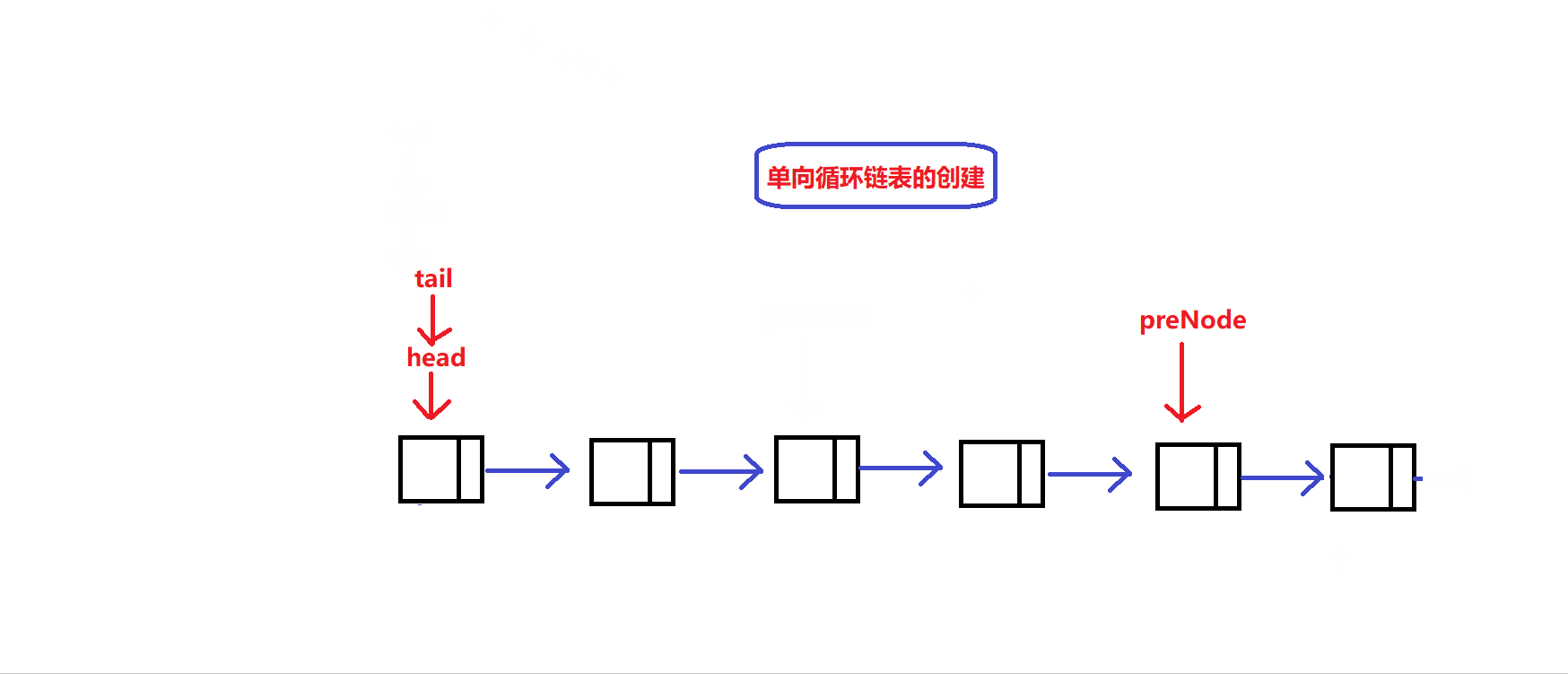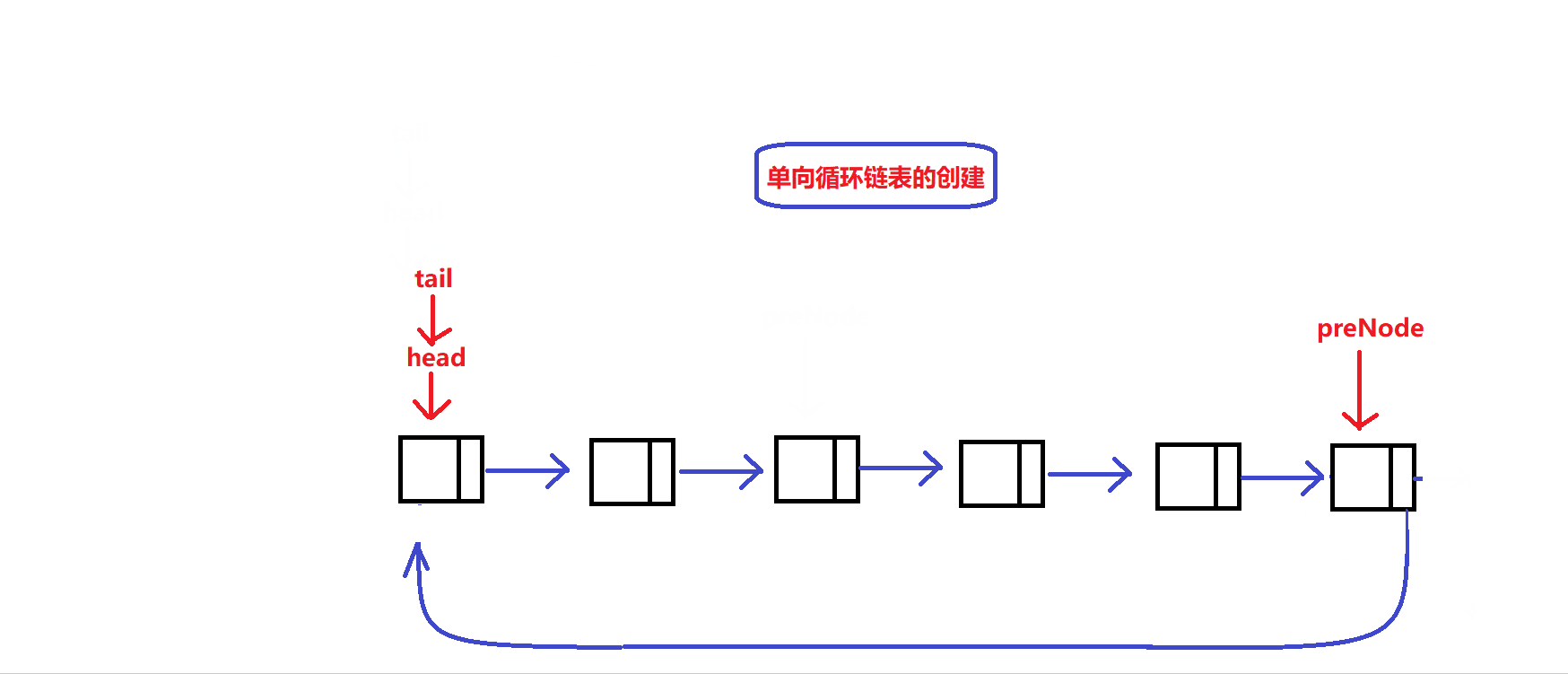
静态单向循环链表的容量大小为k:
- 与数组循环队列类似,我们同样需要开辟一个节点个数为k+1的静态循环链表
- 链表循环队列的总体结构图示:
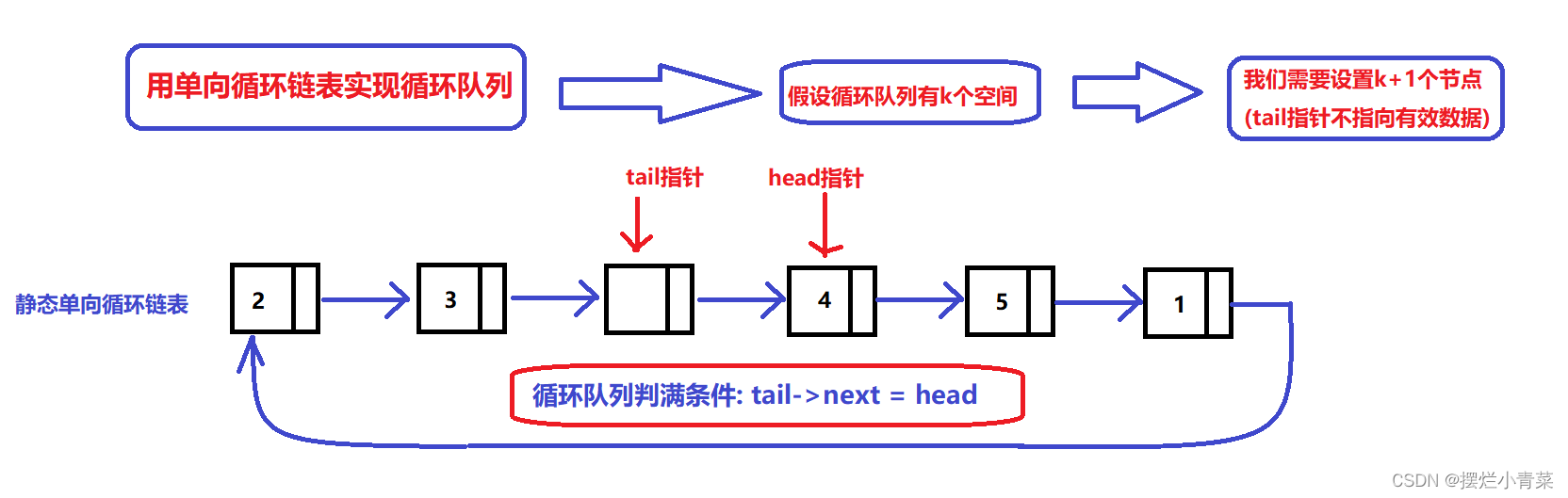
另外一种队列判满的情形:
- 链表循环队列的判满条件(判断队列空间是否被占满的关系式):tail->next == head;
- 链表循环队列的判空条件(判断队列是否为空队列的关系式): tail == head;
链表循环队列的判满和判空的接口:
bool myCircularQueueIsEmpty(MyCircularQueue* obj) //判断队列是否为空 { assert(obj); return(obj->head == obj->tail); } bool myCircularQueueIsFull(MyCircularQueue* obj) //判断队列是否为满 { assert(obj); return (obj->tail->next == obj->head); }
实现一个接口,创建一个维护链表循环队列的结构体同时创建容量大小为k+1的静态单向循环链表:
MyCircularQueue* myCircularQueueCreate(int k) //循环队列初始化接口 { int NodeNum =k+1; //创建k+1个链表节点 MyCircularQueue* object = (MyCircularQueue *)malloc(sizeof(MyCircularQueue)); assert(object); //申请维护循环队列的结构体 object->capacity = k; ListNode * preNode = NULL; //用于记录前一个链接节点的地址 while(NodeNum) { if(NodeNum == k+1) { ListNode * tem = (ListNode *)malloc(sizeof(ListNode)); assert(tem); preNode = tem; object->tail = object->head=tem; //让tail和head指向同一个初始节点 } else { ListNode * tem = (ListNode *)malloc(sizeof(ListNode)); assert(tem); preNode->next = tem; //链接链表节点 preNode = tem; } NodeNum--; } preNode->next = object->head; //将表尾与表头相接 return object; }
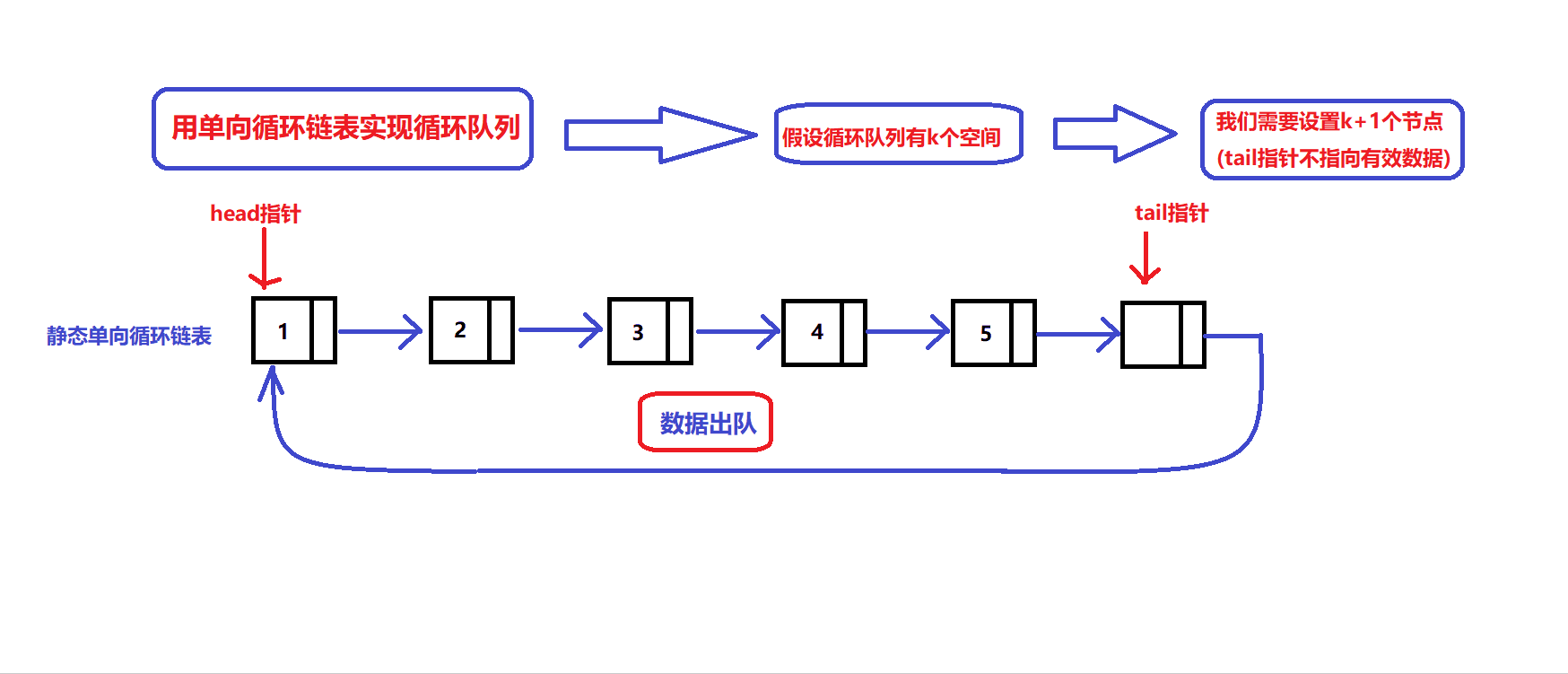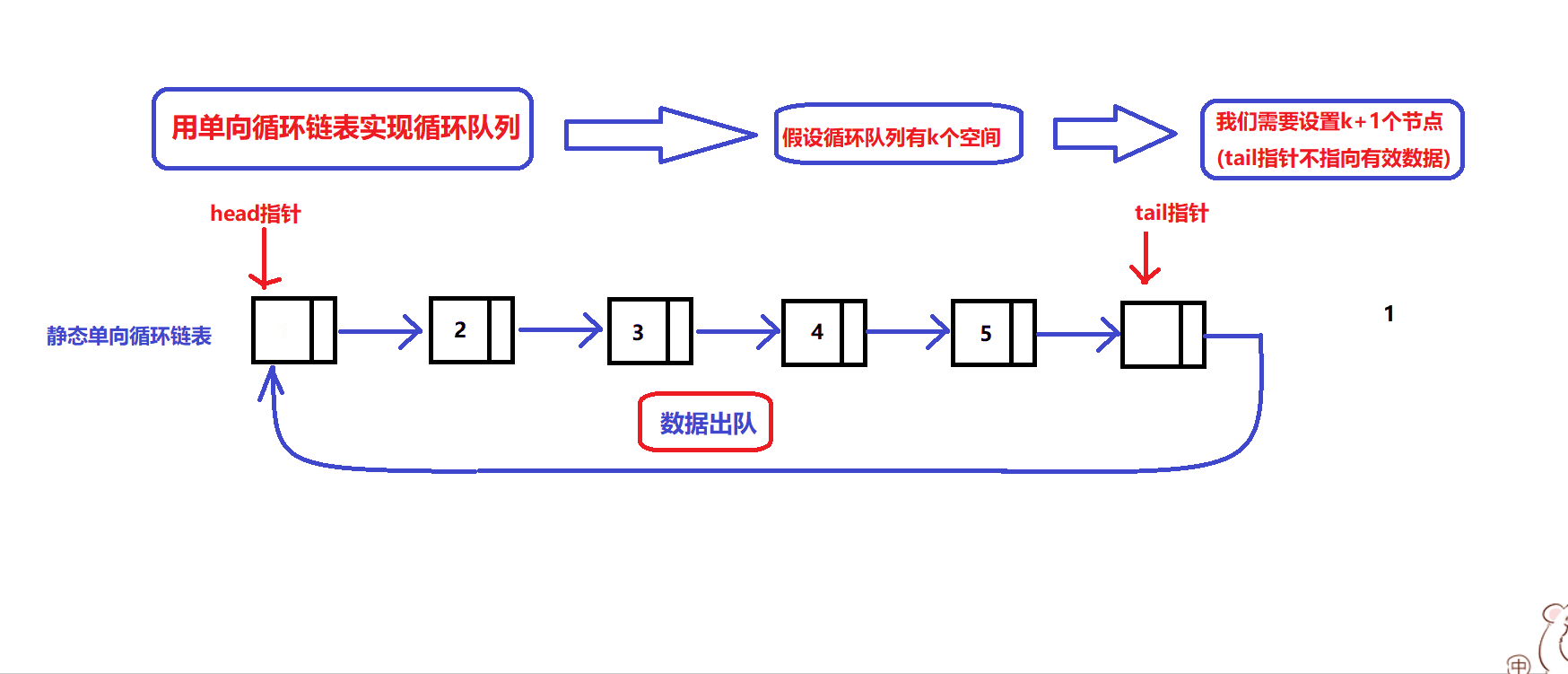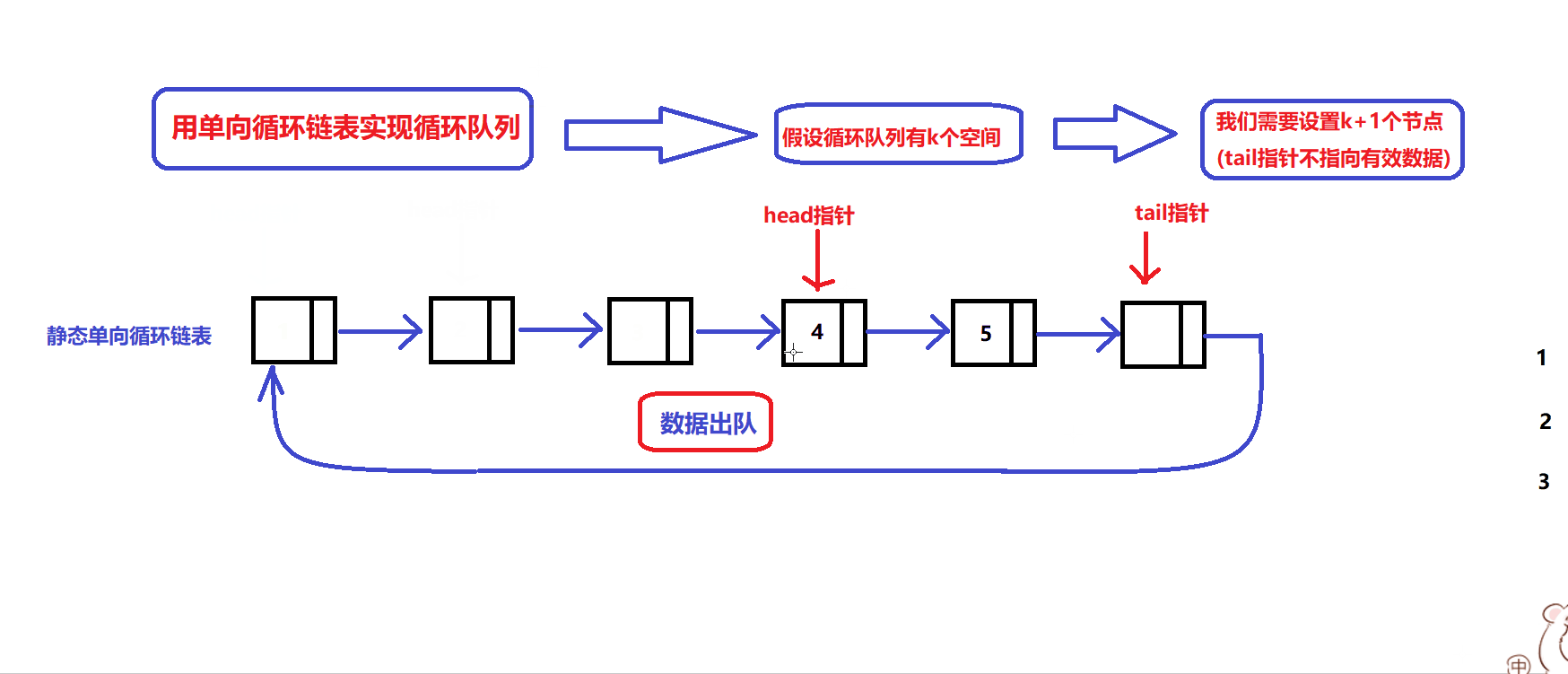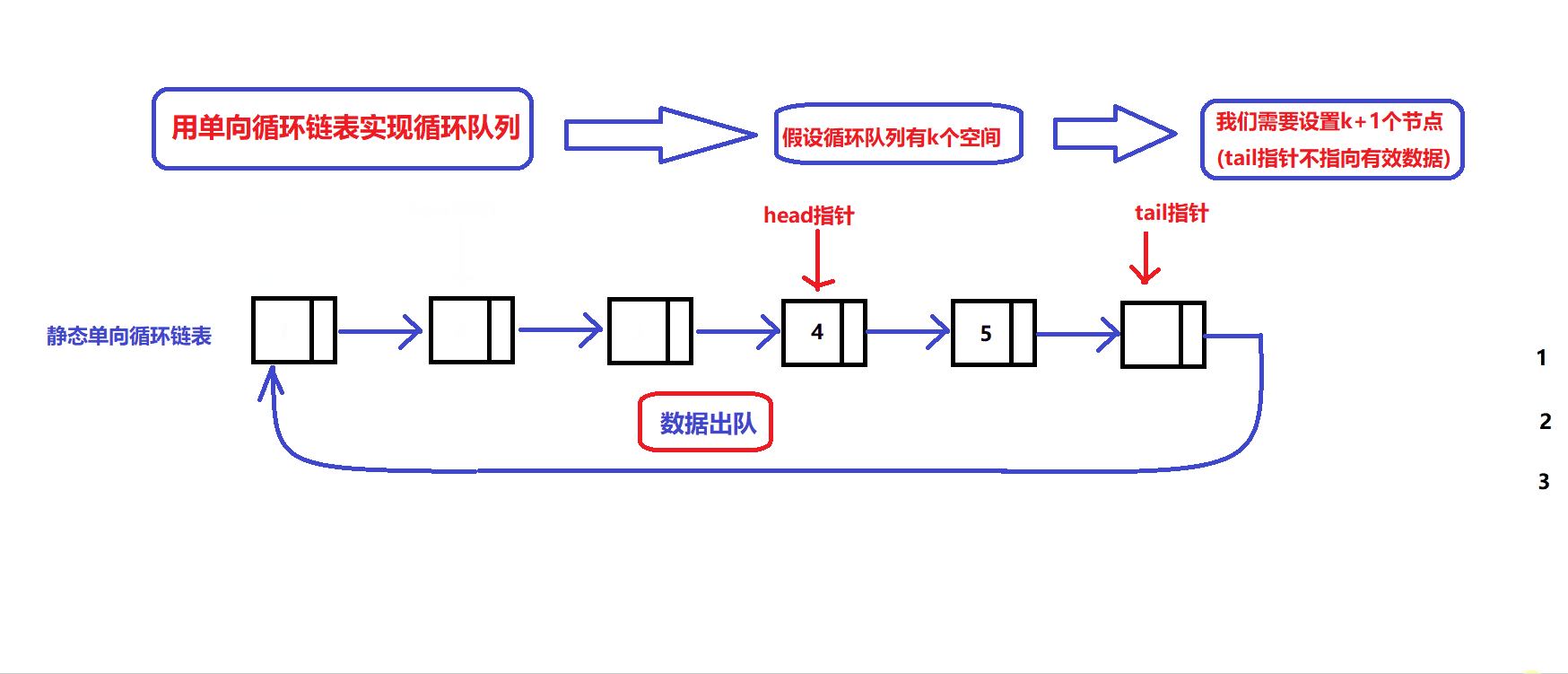
数据出入队图解:
根据图解实现数据出入队接口:
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)//数据入队接口(从队尾入队) { assert(obj); if(!obj || myCircularQueueIsFull(obj)) //确定队列没满 { return false; } obj->tail->data = value; //数据入队 obj->tail = obj->tail->next; return true; }bool myCircularQueueDeQueue(MyCircularQueue* obj) //数据出队接口 { assert(obj); if(!obj || myCircularQueueIsEmpty(obj)) { return false; } //数据出队 obj->head = obj->head->next; return true; }
返回队头数据的接口:
int myCircularQueueFront(MyCircularQueue* obj) //返回队头数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } return obj->head->data; //返回队头元素 }返回队尾数据的接口:
int myCircularQueueRear(MyCircularQueue* obj) //返回队尾数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } ListNode * tem = obj->head; while(tem->next != obj->tail) //寻找队尾元素 { tem=tem->next; } return tem->data; //返回队尾元素 }队列销毁接口:
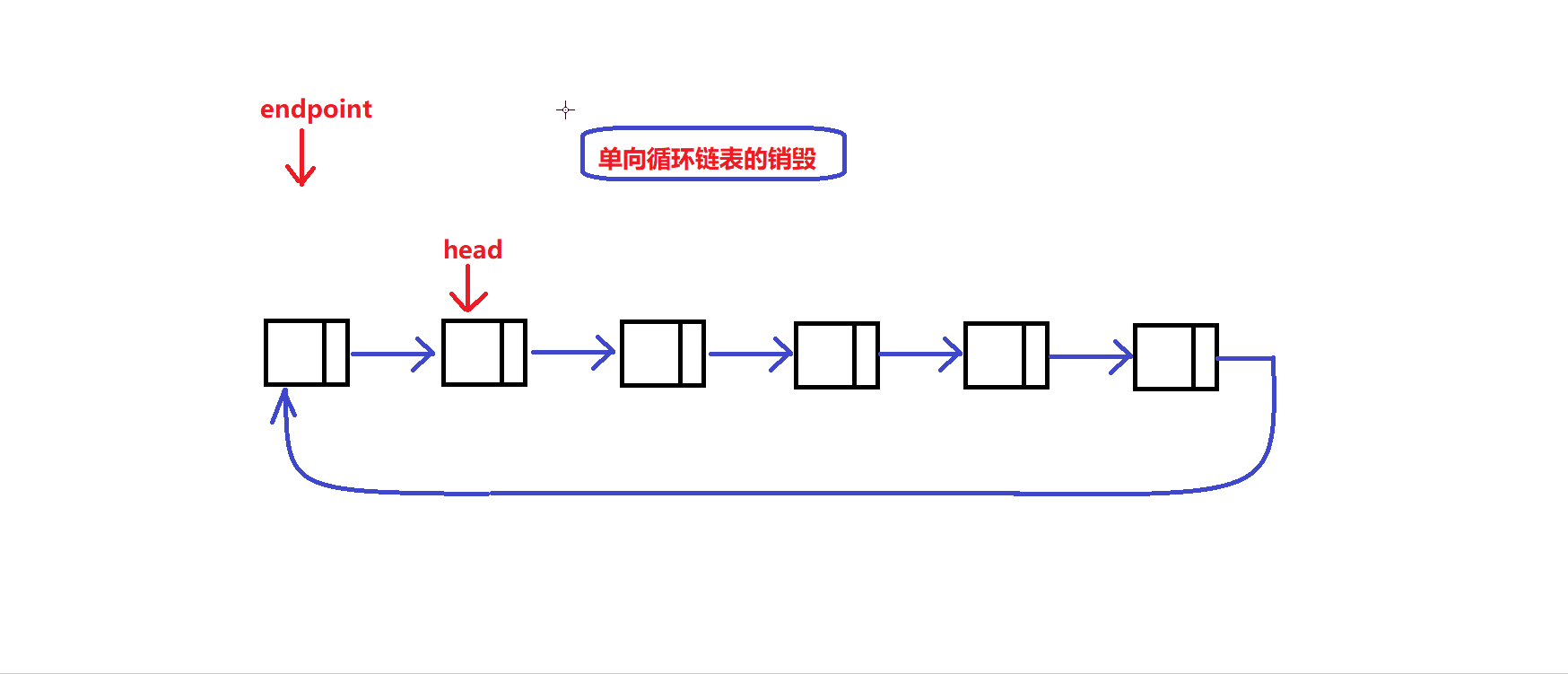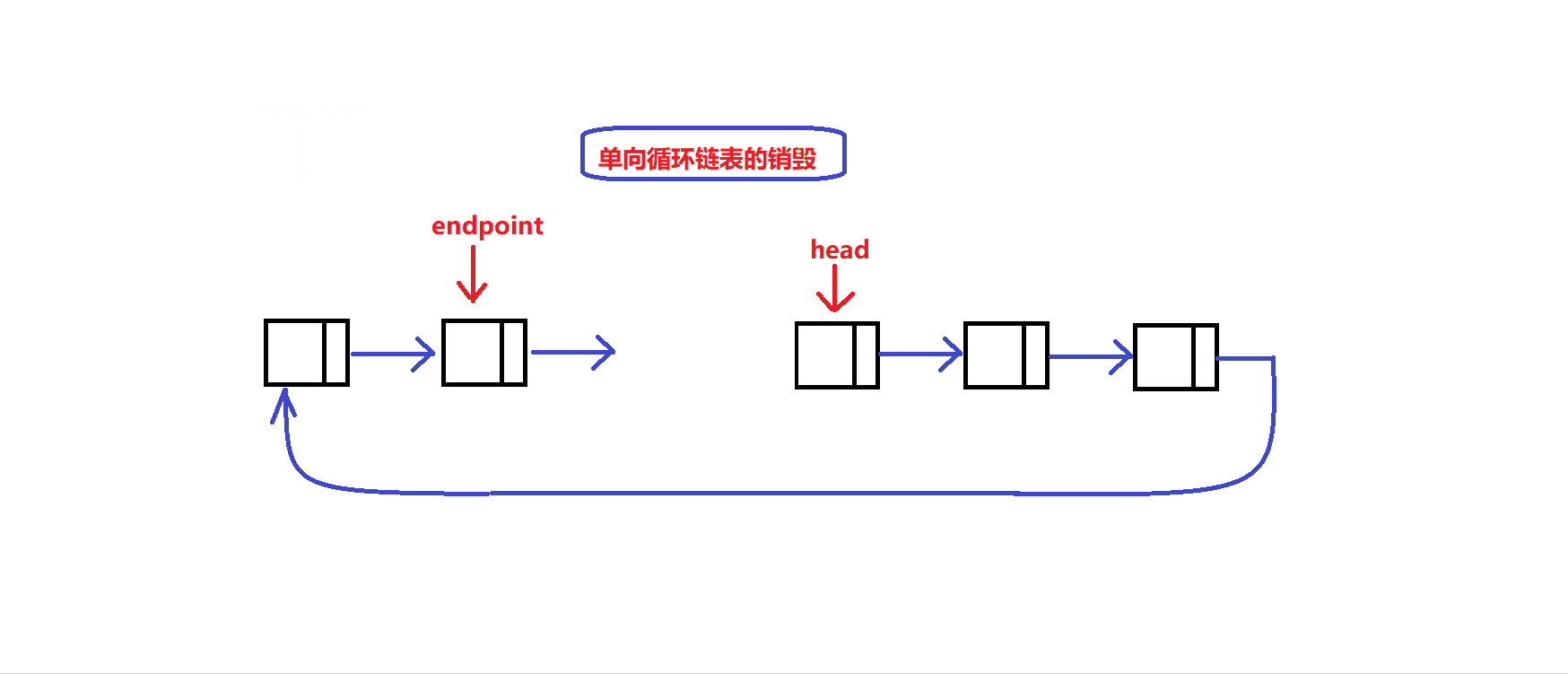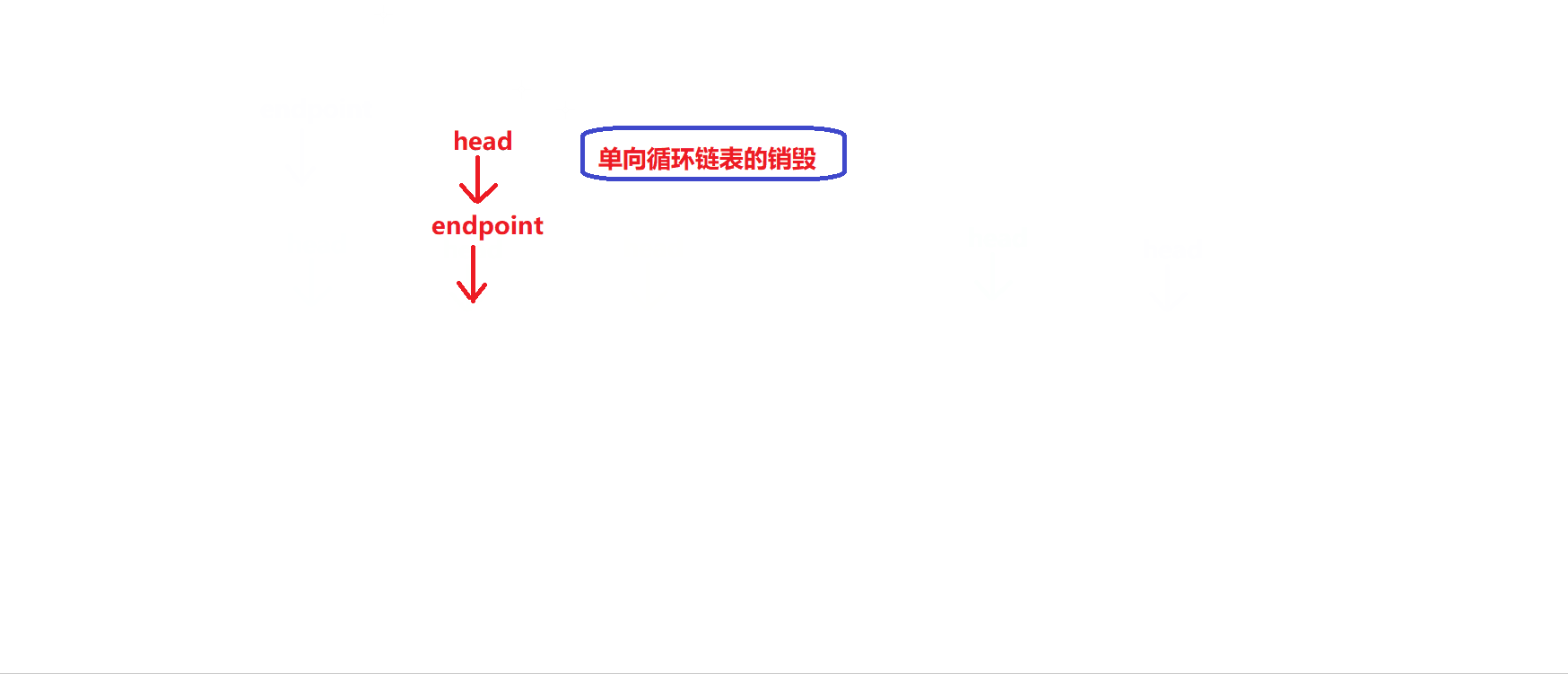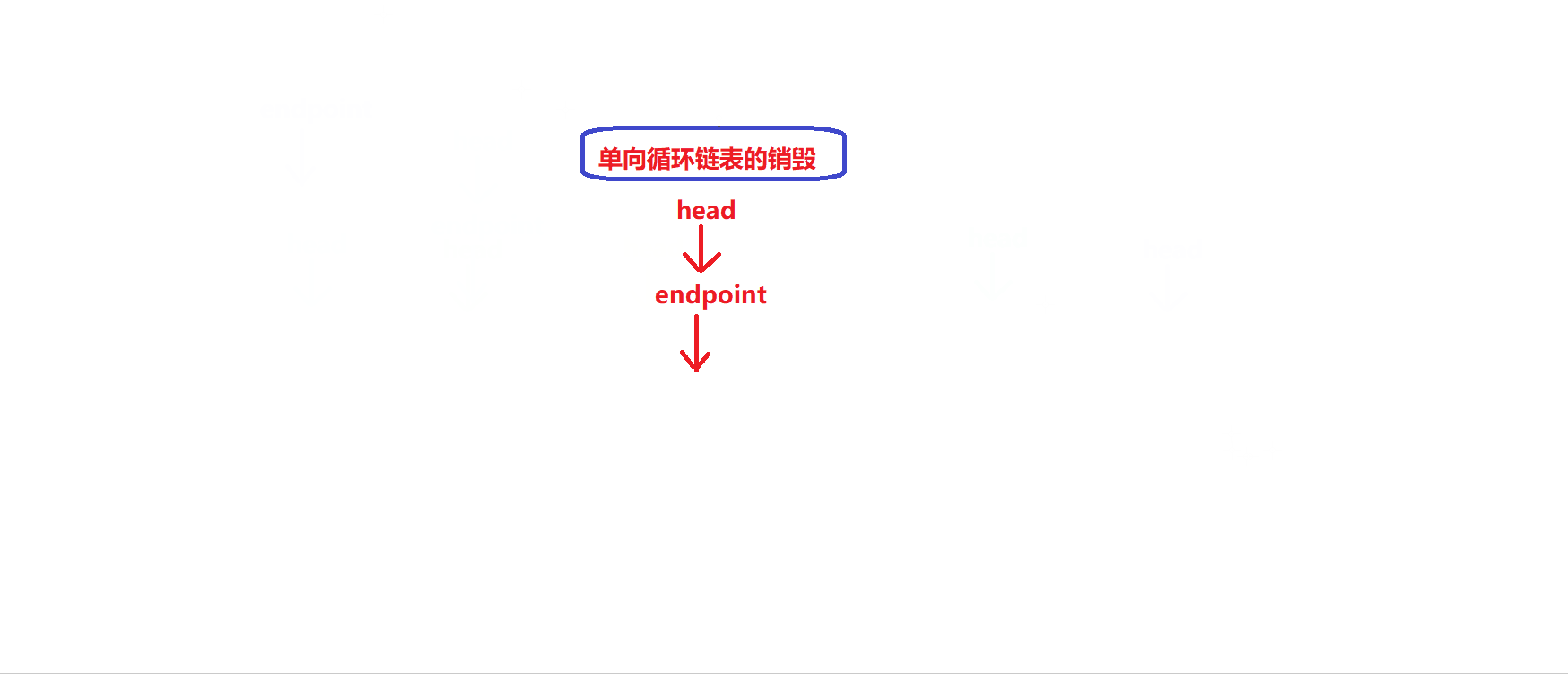
队列销毁过程图解:
void myCircularQueueFree(MyCircularQueue* obj) //销毁队列的接口 { assert(obj); //利用头指针来完成链表节点的释放 ListNode * endpoint = obj->head; //记录一个节点释放的终点 obj->head = obj->head->next; while(obj->head!=endpoint) { ListNode * tem = obj->head->next; free(obj->head); obj->head = tem; } free(endpoint); //释放掉终点节点 free(obj); //释放掉维护环形队列的结构体 }
总体代码:
typedef struct listnode { int data; struct listnode * next; }ListNode; typedef struct { int capacity; ListNode * head; ListNode * tail; int taildata; //单向链表找尾复杂度为O(N),因此我们用一个变量来记录队尾数据 } MyCircularQueue; bool myCircularQueueIsEmpty(MyCircularQueue* obj); bool myCircularQueueIsFull(MyCircularQueue* obj); //顺序编译注意:先被使用而后被定义的函数要记得进行声明 MyCircularQueue* myCircularQueueCreate(int k) //循环队列初始化接口 { int NodeNum =k+1; //创建k+1个链表节点 MyCircularQueue* object = (MyCircularQueue *)malloc(sizeof(MyCircularQueue)); assert(object); //申请维护循环队列的结构体 object->capacity = k; ListNode * preNode = NULL; //用于记录前一个链接节点的地址 while(NodeNum) { if(NodeNum == k+1) { ListNode * tem = (ListNode *)malloc(sizeof(ListNode)); assert(tem); preNode = tem; object->tail = object->head=tem; //让tail和head指向同一个初始节点 } else { ListNode * tem = (ListNode *)malloc(sizeof(ListNode)); assert(tem); preNode->next = tem; //链接链表节点 preNode = tem; } NodeNum--; } preNode->next = object->head; //将表尾与表头相接 return object; } bool myCircularQueueEnQueue(MyCircularQueue* obj, int value) //数据入队接口(从队尾入队) { assert(obj); if(!obj || myCircularQueueIsFull(obj)) //确定队列没满 { return false; } obj->tail->data = value; //数据入队 obj->tail = obj->tail->next; return true; } bool myCircularQueueDeQueue(MyCircularQueue* obj) //数据出队接口 { assert(obj); if(!obj || myCircularQueueIsEmpty(obj)) { return false; } obj->head = obj->head->next; return true; } int myCircularQueueFront(MyCircularQueue* obj) //返回队头数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } return obj->head->data; } int myCircularQueueRear(MyCircularQueue* obj) //返回队尾数据的接口 { assert(obj); if(myCircularQueueIsEmpty(obj)) { return -1; } ListNode * tem = obj->head; while(tem->next != obj->tail) //寻找队尾元素 { tem=tem->next; } return tem->data; } bool myCircularQueueIsEmpty(MyCircularQueue* obj) //判断队列是否为空 { assert(obj); return(obj->head == obj->tail); } bool myCircularQueueIsFull(MyCircularQueue* obj) //判断队列是否为满 { assert(obj); return (obj->tail->next == obj->head); } void myCircularQueueFree(MyCircularQueue* obj) //销毁队列的接口 { assert(obj); //利用头指针来完成链表节点的释放 ListNode * endpoint = obj->head; //记录一个节点释放的终点 obj->head = obj->head->next; while(obj->head!=endpoint) { ListNode * tem = obj->head->next; free(obj->head); obj->head = tem; } free(endpoint); //释放掉终点节点 free(obj); //释放掉维护环形队列的结构体 }leetcode题解测试:

我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最