模式识别与图像处理课程实验二:基于UNet的目标检测网络

实验采用Unet目标检测网络实现对目标的检测。例如检测舰船、车辆、人脸、道路等。其中的Unet网络结构如下所示
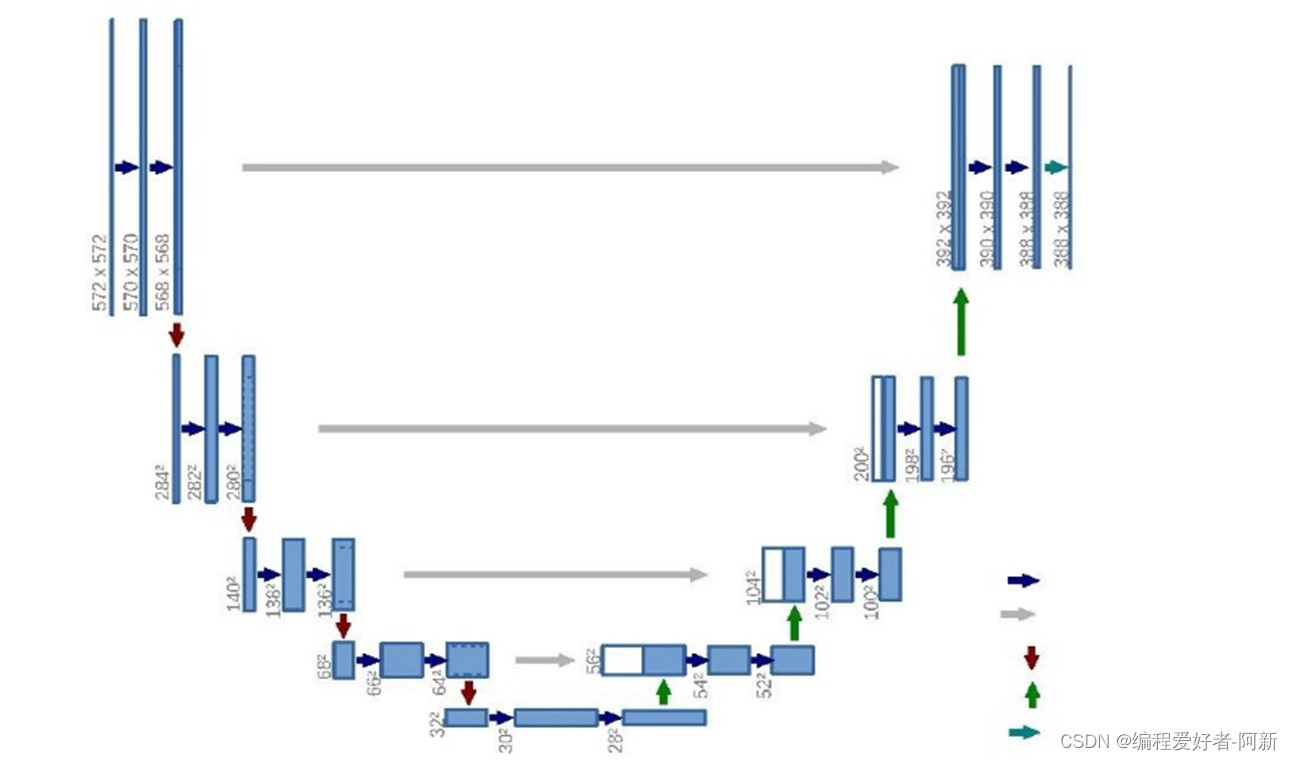
U-Net 是一个 encoder-decoder 结构,左边一半的 encoder 包括若干卷积,池化,把图像进行下采样,右边的 decoder 进行上采样,恢复到原图的形状,给出每个像素的预测。
编码器有四个子模块,每个子模块包含两个卷积层,每个子模块之后有一个通过 maxpool 实现的下采样层。
输入图像的分辨率是 572x572, 第 1-5 个模块的分辨率分别是 572x572, 284x284, 140x140, 68x68 和 32x32。
解码器包含四个子模块,分辨率通过上采样操作依次上升,直到与输入图像的分辨率一致。该网络还使用了跳跃连接,将上采样结果与编码器中具有相同分辨率的子模块的输出进行连接,作为解码器中下一个子模块的输入。
架构中的一个重要修改部分是在上采样中还有大量的特征通道,这些通道允许网络将上下文信息传播到具有更高分辨率的层。因此,拓展路径或多或少地与收缩路径对称,并产生一个 U 形结构。
在该网络中没有任何完全连接的层,并且仅使用每个卷积的有效部分,即分割映射仅包含在输入图像中可获得完整上下文的像素。该策略允许通过重叠平铺策略对任意大小的图像进行无缝分割,如图所示。为了预测图像边界区域中的像素,通过镜像输入图像来推断缺失的上下文。这种平铺策略对于将网络应用于大型的图像非常重要,否则分辨率将受到 GPU 内存的限制。
本实验通过Unet网络,实现对道路目标的检测,测试的数据集存放于文件夹中。使用Unet网络得到训练的数据集:道路目标检测的结果。
# 导入库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms, models, utils
from torch.utils.data import DataLoader, Dataset, random_split
from torch.utils.tensorboard import SummaryWriter
#from torchsummary import summary
import matplotlib.pyplot as plt
import numpy as np
import time
import os
import copy
import cv2
import argparse # argparse库: 解析命令行参数
from tqdm import tqdm # 进度条
# 创建一个解析对象
parser = argparse.ArgumentParser(description="Choose mode")
# 输入命令行和参数
parser.add_argument('-mode', required=True, choices=['train', 'test'], default='train')
parser.add_argument('-dim', type=int, default=16)
parser.add_argument('-num_epochs', type=int, default=3)
parser.add_argument('-image_scale_h', type=int, default=256)
parser.add_argument('-image_scale_w', type=int, default=256)
parser.add_argument('-batch', type=int, default=4)
parser.add_argument('-img_cut', type=int, default=4)
parser.add_argument('-lr', type=float, default=5e-5)
parser.add_argument('-lr_1', type=float, default=5e-5)
parser.add_argument('-alpha', type=float, default=0.05)
parser.add_argument('-sa_scale', type=float, default=8)
parser.add_argument('-latent_size', type=int, default=100)
parser.add_argument('-data_path', type=str, default='./munich/train/img')
parser.add_argument('-label_path', type=str, default='./munich/train/lab')
parser.add_argument('-gpu', type=str, default='0')
parser.add_argument('-load_model', required=True, choices=['True', 'False'], help='choose True or False', default='False')
# parse_args()方法进行解析
opt = parser.parse_args()
print(opt)
os.environ["CUDA_VISIBLE_DEVICES"] = opt.gpu
use_cuda = torch.cuda.is_available()
print("use_cuda:", use_cuda)
# 指定计算机的第一个设备是GPU
device = torch.device("cuda" if use_cuda else "cpu")
IMG_CUT = opt.img_cut
LATENT_SIZE = opt.latent_size
writer = SummaryWriter('./runs2/gx0102')
# 创建文件路径
def auto_create_path(FilePath):
if os.path.exists(FilePath):
print(FilePath + ' dir exists')
else:
print(FilePath + ' dir not exists')
os.makedirs(FilePath)
# 创建文件存放训练的结果
auto_create_path('./test/lab_dete_AVD')
auto_create_path('./model')
auto_create_path('./results')
# 向下采样,求剩余的区域
class ResidualBlockClass(nn.Module):
def __init__(self, name, input_dim, output_dim, resample=None, activate='relu'):
super(ResidualBlockClass, self).__init__()
self.name = name
self.input_dim = input_dim
self.output_dim = output_dim
self.resample = resample
self.batchnormlize_1 = nn.BatchNorm2d(input_dim)
self.activate = activate
if resample == 'down':
self.conv_0 = nn.Conv2d(in_channels=input_dim, out_channels=output_dim, kernel_size=3, stride=1, padding=1)
self.conv_shortcut = nn.AvgPool2d(3, stride=2, padding=1)
self.conv_1 = nn.Conv2d(in_channels=input_dim, out_channels=input_dim, kernel_size=3, stride=1, padding=1)
self.conv_2 = nn.Conv2d(in_channels=input_dim, out_channels=output_dim, kernel_size=3, stride=2, padding=1)
self.batchnormlize_2 = nn.BatchNorm2d(input_dim)
elif resample == 'up':
self.conv_0 = nn.Conv2d(in_channels=input_dim, out_channels=output_dim, kernel_size=3, stride=1, padding=1)
self.conv_shortcut = nn.Upsample(scale_factor=2)
self.conv_1 = nn.Conv2d(in_channels=input_dim, out_channels=output_dim, kernel_size=3, stride=1, padding=1)
self.conv_2 = nn.ConvTranspose2d(in_channels=output_dim, out_channels=output_dim, kernel_size=3, stride=2, padding=2,
output_padding=1, dilation=2)
self.batchnormlize_2 = nn.BatchNorm2d(output_dim)
elif resample == None:
self.conv_shortcut = nn.Conv2d(in_channels=input_dim, out_channels=output_dim, kernel_size=3, stride=1, padding=1)
self.conv_1 = nn.Conv2d(in_channels=input_dim, out_channels=input_dim, kernel_size=3, stride=1, padding=1)
self.conv_2 = nn.Conv2d(in_channels=input_dim, out_channels=output_dim, kernel_size=3, stride=1, padding=1)
self.batchnormlize_2 = nn.BatchNorm2d(input_dim)
else:
raise Exception('invalid resample value')
def forward(self, inputs):
if self.output_dim == self.input_dim and self.resample == None:
shortcut = inputs
elif self.resample == 'down':
x = self.conv_0(inputs)
shortcut = self.conv_shortcut(x)
elif self.resample == None:
x = inputs
shortcut = self.conv_shortcut(x)
else:
x = self.conv_0(inputs)
shortcut = self.conv_shortcut(x)
if self.activate == 'relu':
x = inputs
x = self.batchnormlize_1(x)
x = F.relu(x)
x = self.conv_1(x)
x = self.batchnormlize_2(x)
x = F.relu(x)
x = self.conv_2(x)
return shortcut + x
else:
x = inputs
x = self.batchnormlize_1(x)
x = F.leaky_relu(x)
x = self.conv_1(x)
x = self.batchnormlize_2(x)
x = F.leaky_relu(x)
x = self.conv_2(x)
return shortcut + x
class Self_Attn(nn.Module):
""" Self attention Layer"""
def __init__(self,in_dim,activation=None):
super(Self_Attn,self).__init__()
self.chanel_in = in_dim
# self.activation = activation
self.query_conv = nn.Conv2d(in_channels = in_dim, out_channels = in_dim//opt.sa_scale, kernel_size = 1)
self.key_conv = nn.Conv2d(in_channels = in_dim, out_channels = in_dim//opt.sa_scale, kernel_size = 1)
self.value_conv = nn.Conv2d(in_channels = in_dim, out_channels = in_dim, kernel_size = 1)
self.gamma = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X W X H)
returns :
out : self attention value + input feature
attention: B X N X N (N is Width*Height)
"""
m_batchsize, C, width, height = x.size()
proj_query = self.query_conv(x).view(m_batchsize,-1,width*height).permute(0,2,1) # B X (W*H) X C
proj_key = self.key_conv(x).view(m_batchsize,-1,width*height) # B X C x (*W*H)
energy = torch.bmm(proj_query,proj_key) # transpose check
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize,-1,width*height) # B X C X N
out = torch.bmm(proj_value,attention.permute(0,2,1))
out = out.view(m_batchsize, C, width, height)
out = self.gamma*out + x
return out
# 上采样,使用卷积恢复区域
class UpProject(nn.Module):
def __init__(self, in_channels, out_channels):
super(UpProject, self).__init__()
# self.batch_size = batch_size
self.conv1_1 = nn.Conv2d(in_channels, out_channels, 3)
self.conv1_2 = nn.Conv2d(in_channels, out_channels, (2, 3))
self.conv1_3 = nn.Conv2d(in_channels, out_channels, (3, 2))
self.conv1_4 = nn.Conv2d(in_channels, out_channels, 2)
self.conv2_1 = nn.Conv2d(in_channels, out_channels, 3)
self.conv2_2 = nn.Conv2d(in_channels, out_channels, (2, 3))
self.conv2_3 = nn.Conv2d(in_channels, out_channels, (3, 2))
self.conv2_4 = nn.Conv2d(in_channels, out_channels, 2)
self.bn1_1 = nn.BatchNorm2d(out_channels)
self.bn1_2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(out_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
# b, 10, 8, 1024
batch_size = x.shape[0]
out1_1 = self.conv1_1(nn.functional.pad(x, (1, 1, 1, 1)))
out1_2 = self.conv1_2(nn.functional.pad(x, (1, 1, 0, 1)))#right interleaving padding
#out1_2 = self.conv1_2(nn.functional.pad(x, (1, 1, 1, 0)))#author's interleaving pading in github
out1_3 = self.conv1_3(nn.functional.pad(x, (0, 1, 1, 1)))#right interleaving padding
#out1_3 = self.conv1_3(nn.functional.pad(x, (1, 0, 1, 1)))#author's interleaving pading in github
out1_4 = self.conv1_4(nn.functional.pad(x, (0, 1, 0, 1)))#right interleaving padding
#out1_4 = self.conv1_4(nn.functional.pad(x, (1, 0, 1, 0)))#author's interleaving pading in github
out2_1 = self.conv2_1(nn.functional.pad(x, (1, 1, 1, 1)))
out2_2 = self.conv2_2(nn.functional.pad(x, (1, 1, 0, 1)))#right interleaving padding
#out2_2 = self.conv2_2(nn.functional.pad(x, (1, 1, 1, 0)))#author's interleaving pading in github
out2_3 = self.conv2_3(nn.functional.pad(x, (0, 1, 1, 1)))#right interleaving padding
#out2_3 = self.conv2_3(nn.functional.pad(x, (1, 0, 1, 1)))#author's interleaving pading in github
out2_4 = self.conv2_4(nn.functional.pad(x, (0, 1, 0, 1)))#right interleaving padding
#out2_4 = self.conv2_4(nn.functional.pad(x, (1, 0, 1, 0)))#author's interleaving pading in github
height = out1_1.size()[2]
width = out1_1.size()[3]
out1_1_2 = torch.stack((out1_1, out1_2), dim=-3).permute(0, 1, 3, 4, 2).contiguous().view(
batch_size, -1, height, width * 2)
out1_3_4 = torch.stack((out1_3, out1_4), dim=-3).permute(0, 1, 3, 4, 2).contiguous().view(
batch_size, -1, height, width * 2)
out1_1234 = torch.stack((out1_1_2, out1_3_4), dim=-3).permute(0, 1, 3, 2, 4).contiguous().view(
batch_size, -1, height * 2, width * 2)
out2_1_2 = torch.stack((out2_1, out2_2), dim=-3).permute(0, 1, 3, 4, 2).contiguous().view(
batch_size, -1, height, width * 2)
out2_3_4 = torch.stack((out2_3, out2_4), dim=-3).permute(0, 1, 3, 4, 2).contiguous().view(
batch_size, -1, height, width * 2)
out2_1234 = torch.stack((out2_1_2, out2_3_4), dim=-3).permute(0, 1, 3, 2, 4).contiguous().view(
batch_size, -1, height * 2, width * 2)
out1 = self.bn1_1(out1_1234)
out1 = self.relu(out1)
out1 = self.conv3(out1)
out1 = self.bn2(out1)
out2 = self.bn1_2(out2_1234)
out = out1 + out2
out = self.relu(out)
return out
#编码,下采样
class Fcrn_encode(nn.Module):
def __init__(self, dim=opt.dim):
super(Fcrn_encode, self).__init__()
self.dim = dim
self.conv_1 = nn.Conv2d(in_channels=3, out_channels=dim, kernel_size=3, stride=1, padding=1)
self.residual_block_1_down_1 = ResidualBlockClass('Detector.Res1', 1*dim, 2*dim, resample='down', activate='leaky_relu')
# 128x128
self.residual_block_2_down_1 = ResidualBlockClass('Detector.Res2', 2*dim, 4*dim, resample='down', activate='leaky_relu')
#64x64
self.residual_block_3_down_1 = ResidualBlockClass('Detector.Res3', 4*dim, 4*dim, resample='down', activate='leaky_relu')
#32x32
self.residual_block_4_down_1 = ResidualBlockClass('Detector.Res4', 4*dim, 6*dim, resample='down', activate='leaky_relu')
#16x16
self.residual_block_5_none_1 = ResidualBlockClass('Detector.Res5', 6*dim, 6*dim, resample=None, activate='leaky_relu')
def forward(self, x, n1=0, n2=0, n3=0):
x1 = self.conv_1(x)#x1:dimx256x256
x2 = self.residual_block_1_down_1(x1)#x2:2dimx128x128
x3 = self.residual_block_2_down_1((1-opt.alpha)*x2+opt.alpha*n1)#x3:4dimx64x64
x4 = self.residual_block_3_down_1((1-opt.alpha)*x3+opt.alpha*n2)#x4:4dimx32x32
x = self.residual_block_4_down_1((1-opt.alpha)*x4+opt.alpha*n3)
feature = self.residual_block_5_none_1(x)
x = F.tanh(feature)
return x, x2, x3, x4
# 解码, 上采样
class Fcrn_decode(nn.Module):
def __init__(self, dim=opt.dim):
super(Fcrn_decode, self).__init__()
self.dim = dim
self.conv_2 = nn.Conv2d(in_channels=dim, out_channels=1, kernel_size=3, stride=1, padding=1)
self.residual_block_6_none_1 = ResidualBlockClass('Detector.Res6', 6*dim, 6*dim, resample=None, activate='leaky_relu')
# self.residual_block_7_up_1 = ResidualBlockClass('Detector.Res7', 6*dim, 6*dim, resample='up', activate='leaky_relu')
self.sa_0 = Self_Attn(6*dim)
#32x32
self.UpProject_1 = UpProject(6*dim, 4*dim)
self.residual_block_8_up_1 = ResidualBlockClass('Detector.Res8', 6*dim, 4*dim, resample='up', activate='leaky_relu')
self.sa_1 = Self_Attn(4*dim)
#64x64
self.UpProject_2 = UpProject(2*4*dim, 4*dim)
self.sa_2 = Self_Attn(4*dim)
self.residual_block_9_up_1 = ResidualBlockClass('Detector.Res9', 4*dim, 4*dim, resample='up', activate='leaky_relu')
#128x128
self.UpProject_3 = UpProject(2*4*dim, 2*dim)
self.sa_3 = Self_Attn(2*dim)
self.residual_block_10_up_1 = ResidualBlockClass('Detector.Res10', 4*dim, 2*dim, resample='up', activate='leaky_relu')
#256x256
self.UpProject_4 = UpProject(2*2*dim, 1*dim)
self.sa_4 = Self_Attn(1*dim)
self.residual_block_11_up_1 = ResidualBlockClass('Detector.Res11', 2*dim, 1*dim, resample='up', activate='leaky_relu')
def forward(self, x, x2, x3, x4):
x = self.residual_block_6_none_1(x)
x = self.UpProject_1(x)
x = self.sa_1(x)
x = self.UpProject_2(torch.cat((x, x4), dim=1))
x = self.sa_2(x)
x = self.UpProject_3(torch.cat((x, x3), dim=1))
# x = self.sa_3(x)
x = self.UpProject_4(torch.cat((x, x2), dim=1))
# x = self.sa_4(x)
x = F.normalize(x, dim=[0, 2, 3])
x = F.leaky_relu(x)
x = self.conv_2(x)
x = F.sigmoid(x)
return x
class Generator(nn.Module):
def __init__(self, dim=opt.dim):
super(Generator, self).__init__()
self.dim = dim
self.conv_1 = nn.Conv2d(in_channels=4, out_channels=1*dim, kernel_size=3, stride=1, padding=1)
self.conv_2 = nn.Conv2d(in_channels=dim, out_channels=3, kernel_size=3, stride=1, padding=1)
self.batchnormlize = nn.BatchNorm2d(1*dim)
self.residual_block_1 = ResidualBlockClass('G.Res1', 1*dim, 2*dim, resample='down')
#128x128
self.residual_block_2 = ResidualBlockClass('G.Res2', 2*dim, 4*dim, resample='down')
#64x64
# self.residual_block_2_1 = ResidualBlockClass('G.Res2_1', 4*dim, 4*dim, resample='down')
#64x64
#self.residual_block_2_2 = ResidualBlockClass('G.Res2_2', 4*dim, 4*dim, resample=None)
#64x64
self.residual_block_3 = ResidualBlockClass('G.Res3', 4*dim, 4*dim, resample='down')
#32x32
self.residual_block_4 = ResidualBlockClass('G.Res4', 4*dim, 6*dim, resample='down')
#16x16
self.residual_block_5 = ResidualBlockClass('G.Res5', 6*dim, 6*dim, resample=None)
#16x16
self.residual_block_6 = ResidualBlockClass('G.Res6', 6*dim, 6*dim, resample=None)
def forward(self, x):
x = self.conv_1(x)
x1 = self.residual_block_1(x)#x1:2*dimx128x128
x2 = self.residual_block_2(x1)#x2:4*dimx64x64
# x = self.residual_block_2_1(x)
#x = self.residual_block_2_2(x)
x3 = self.residual_block_3(x2)#x3:4*dimx32x32
x = self.residual_block_4(x3)#x4:6*dimx16x16
x = self.residual_block_5(x)
x = self.residual_block_6(x)
x = F.tanh(x)
return x, x1, x2, x3
class Discriminator(nn.Module):
def __init__(self, dim=opt.dim):
super(Discriminator, self).__init__()
self.dim = dim
self.conv_1 = nn.Conv2d(in_channels=6*dim, out_channels=6*dim, kernel_size=3, stride=1, padding=1)
#16x16
self.conv_2 = nn.Conv2d(in_channels=6*dim, out_channels=6*dim, kernel_size=3, stride=1, padding=1)
self.conv_3 = nn.Conv2d(in_channels=6*dim, out_channels=4*dim, kernel_size=3, stride=1, padding=1)
self.bn_1 = nn.BatchNorm2d(6*dim)
self.conv_4 = nn.Conv2d(in_channels=4*dim, out_channels=4*dim, kernel_size=3, stride=2, padding=1)
#8x8
self.conv_5 = nn.Conv2d(in_channels=4*dim, out_channels=4*dim, kernel_size=3, stride=1, padding=1)
#8x8
self.conv_6 = nn.Conv2d(in_channels=4*dim, out_channels=2*dim, kernel_size=3, stride=2, padding=1)
#4x4
self.bn_2 = nn.BatchNorm2d(2*dim)
self.conv_7 = nn.Conv2d(in_channels=2*dim, out_channels=2*dim, kernel_size=3, stride=1, padding=1)
#4x4
self.conv_8 = nn.Conv2d(in_channels=2*dim, out_channels=1*dim, kernel_size=3, stride=1, padding=1)
#4x4
#self.conv_9 = nn.Conv2d(in_channels=1*dim, out_channels=1, kernel_size=4, stride=1, padding=(0, 1), dilation=(1, 3))
#1x1
def forward(self, x):
x = F.leaky_relu(self.conv_1(x), negative_slope=0.02)
x = F.leaky_relu(self.conv_2(x), negative_slope=0.02)
x = F.leaky_relu(self.conv_3(x), negative_slope=0.02)
# x = F.leaky_relu(self.bn_1(x), negative_slope=0.02)
x = F.leaky_relu(self.conv_4(x), negative_slope=0.02)
x = F.leaky_relu(self.conv_5(x), negative_slope=0.02)
x = F.leaky_relu(self.conv_6(x), negative_slope=0.02)
# x = F.leaky_relu(self.bn_2(x), negative_slope=0.2)
x = F.leaky_relu(self.conv_7(x), negative_slope=0.02)
x = F.leaky_relu(self.conv_8(x), negative_slope=0.02)
#x = self.conv_9(x)
x = torch.mean(x, dim=[1, 2, 3])
x = F.sigmoid(x)
return x.view(-1, 1).squeeze()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# 获取训练的数据集
class GAN_Dataset(Dataset):
def __init__(self, transform=None):
self.transform = transform
def __len__(self):
return len(os.listdir(opt.data_path))
def __getitem__(self, idx):
img_name = os.listdir(opt.data_path)[idx]
imgA = cv2.imread(opt.data_path + '/' + img_name)
imgA = cv2.resize(imgA, (opt.image_scale_w, opt.image_scale_h))
imgB = cv2.imread(opt.label_path + '/' + img_name[:-4] + '.png', 0)
imgB = cv2.resize(imgB, (opt.image_scale_w, opt.image_scale_h))
# imgB[imgB>30] = 255
imgB = imgB/255
#imgB = imgB.astype('uint8')
imgB = torch.FloatTensor(imgB)
imgB = torch.unsqueeze(imgB, 0)
#print(imgB.shape)
if self.transform:
imgA = self.transform(imgA)
return imgA, imgB
img_road = GAN_Dataset(transform)
train_dataloader = DataLoader(img_road, batch_size=opt.batch, shuffle=True)
print(len(train_dataloader.dataset), train_dataloader.dataset[7][1].shape)
# 测试数据集
class test_Dataset(Dataset):
# DATA_PATH = './test/img'
# LABEL_PATH = './test/lab'
def __init__(self, transform=None):
self.transform = transform
def __len__(self):
return len(os.listdir('./munich/test/img'))
def __getitem__(self, idx):
img_name = os.listdir('./munich/test/img')
img_name.sort(key=lambda x:int(x[:-4]))
img_name = img_name[idx]
imgA = cv2.imread('./munich/test/img' + '/' + img_name)
imgA = cv2.resize(imgA, (opt.image_scale_w, opt.image_scale_h))
imgB = cv2.imread('./munich/test/lab' + '/' + img_name[:-4] + '.png', 0)
imgB = cv2.resize(imgB, (opt.image_scale_w, opt.image_scale_h))
#imgB = imgB/255
# imgB[imgB>30] = 255
imgB = imgB/255
#imgB = imgB.astype('uint8')
imgB = torch.FloatTensor(imgB)
imgB = torch.unsqueeze(imgB, 0)
#print(imgB.shape)
if self.transform:
#imgA = imgA/255
#imgA = np.transpose(imgA, (2, 0, 1))
#imgA = torch.FloatTensor(imgA)
imgA = self.transform(imgA)
return imgA, imgB, img_name[:-4]
img_road_test = test_Dataset(transform)
test_dataloader = DataLoader(img_road_test, batch_size=1, shuffle=False)
print(len(test_dataloader.dataset), test_dataloader.dataset[7][1].shape)
loss = nn.BCELoss()
fcrn_encode = Fcrn_encode()
fcrn_encode = nn.DataParallel(fcrn_encode)
fcrn_encode = fcrn_encode.to(device)
if opt.load_model == 'True':
fcrn_encode.load_state_dict(torch.load('./model/fcrn_encode_{}_link.pkl'.format(opt.alpha)))
fcrn_decode = Fcrn_decode()
fcrn_decode = nn.DataParallel(fcrn_decode)
fcrn_decode = fcrn_decode.to(device)
if opt.load_model == 'True':
fcrn_decode.load_state_dict(torch.load('./model/fcrn_decode_{}_link.pkl'.format(opt.alpha)))
Gen = Generator()
Gen = nn.DataParallel(Gen)
Gen = Gen.to(device)
if opt.load_model == 'True':
Gen.load_state_dict(torch.load('./model/Gen_{}_link.pkl'.format(opt.alpha)))
Dis = Discriminator()
Dis = nn.DataParallel(Dis)
Dis = Dis.to(device)
if opt.load_model == 'True':
Dis.load_state_dict(torch.load('./model/Dis_{}_link.pkl'.format(opt.alpha)))
Dis_optimizer = optim.Adam(Dis.parameters(), lr=opt.lr_1)
Dis_scheduler = optim.lr_scheduler.StepLR(Dis_optimizer,step_size=800,gamma = 0.5)
Fcrn_encode_optimizer = optim.Adam(fcrn_encode.parameters(), lr=opt.lr)
encode_scheduler = optim.lr_scheduler.StepLR(Fcrn_encode_optimizer,step_size=300,gamma = 0.5)
Fcrn_decode_optimizer = optim.Adam(fcrn_decode.parameters(), lr=opt.lr)
decode_scheduler = optim.lr_scheduler.StepLR(Fcrn_decode_optimizer,step_size=300,gamma = 0.5)
Gen_optimizer = optim.Adam(Gen.parameters(), lr=opt.lr_1)
Gen_scheduler = optim.lr_scheduler.StepLR(Gen_optimizer,step_size=800,gamma = 0.5)
# 训练函数
def train(device, train_dataloader, epoch):
fcrn_encode.train()
fcrn_decode.train()
# Gen.train()
for batch_idx, (road, road_label)in enumerate(train_dataloader):
road, road_label = road.to(device), road_label.to(device)
z = torch.randn(road.shape[0], 1, opt.image_scale_h, opt.image_scale_w, device=device)
img_noise = torch.cat((road, z), dim=1)
fake_feature, n1, n2, n3 = Gen(img_noise)
feature, x2, x3, x4 = fcrn_encode(road, n1, n2, n3)
Dis_optimizer.zero_grad()
d_real = Dis(feature.detach())
d_loss_real = loss(d_real, 0.9*torch.ones_like(d_real))
d_fake = Dis((1-opt.alpha)*feature.detach() + opt.alpha*fake_feature.detach())
d_loss_fake = loss(d_fake, 0.1 + torch.zeros_like(d_fake))
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
Dis_optimizer.step()
Gen_optimizer.zero_grad()
z = torch.randn(road.shape[0], 1, opt.image_scale_h, opt.image_scale_w, device=device)
img_noise = torch.cat((road, z), dim=1)
fake_feature, n1, n2, n3 = Gen(img_noise)
detect_noise = fcrn_decode((1-opt.alpha)*feature.detach() + opt.alpha*fake_feature, x2, x3, x4)
d_fake = Dis((1-opt.alpha)*feature.detach() + opt.alpha*fake_feature)
g_loss = loss(d_fake, 0.9*torch.ones_like(d_fake))
g_loss -= loss(detect_noise, road_label)
g_loss.backward()
Gen_optimizer.step()
z = torch.randn(road.shape[0], 1, opt.image_scale_h, opt.image_scale_w, device=device)
img_noise = torch.cat((road, z), dim=1)
fake_feature, n1, n2, n3 = Gen(img_noise)
# feature_img = fake_feature.detach().cpu()
# feature_img = np.transpose(np.array(utils.make_grid(feature_img, nrow=IMG_CUT)), (1, 2, 0))
feature, x2, x3, x4 = fcrn_encode(road, n1, n2, n3)
#detect = fcrn_decode(0.9*feature + 0.1*fake_feature)
detect = fcrn_decode(feature, x2, x3, x4 )
# detect_img = detect.detach().cpu()
# detect_img = np.transpose(np.array(utils.make_grid(detect_img, nrow=IMG_CUT)), (1, 2, 0))
# blur = cv2.GaussianBlur(detect_img*255, (3, 3), 0)
# _, thresh = cv2.threshold(blur,120,255,cv2.THRESH_BINARY)
fcrn_loss = loss(detect, road_label)
fcrn_loss += torch.mean(torch.abs(detect-road_label))/(torch.mean(torch.abs(detect+road_label))+0.001)
Fcrn_encode_optimizer.zero_grad()
Fcrn_decode_optimizer.zero_grad()
fcrn_loss.backward()
Fcrn_encode_optimizer.step()
Fcrn_decode_optimizer.step()
z = torch.randn(road.shape[0], 1, opt.image_scale_h, opt.image_scale_w, device=device)
img_noise = torch.cat((road, z), dim=1)
fake_feature, n1, n2, n3 = Gen(img_noise)
# ffp, _ = torch.split(fake_feature, [3, 6*opt.dim-3], dim=1)
# fake_feature_np = ffp.detach().cpu()
# fake_feature_np = np.transpose(np.array(utils.make_grid(fake_feature_np, nrow=IMG_CUT, padding=0)), (1, 2, 0))
feature, x2, x3, x4 = fcrn_encode(road, n1, n2, n3)
# fp, _ = torch.split(feature, [3, 6*opt.dim-3], dim=1)
# feature_np = fp.detach().cpu()
# feature_np = np.transpose(np.array(utils.make_grid(feature_np, nrow=IMG_CUT, padding=0)), (1, 2, 0))
road_np = road.detach().cpu()
road_np = np.transpose(np.array(utils.make_grid(road_np, nrow=IMG_CUT, padding=0)), (1, 2, 0))
road_label_np = road_label.detach().cpu()
road_label_np = np.transpose(np.array(utils.make_grid(road_label_np, nrow=IMG_CUT, padding=0)), (1, 2, 0))
detect_noise = fcrn_decode((1-opt.alpha)*feature + opt.alpha*fake_feature.detach(), x2, x3, x4 )
detect_noise_np = detect_noise.detach().cpu()
detect_noise_np = np.transpose(np.array(utils.make_grid(detect_noise_np, nrow=IMG_CUT, padding=0)), (1, 2, 0))
blur = cv2.GaussianBlur(detect_noise_np*255, (3, 3), 0)
_, thresh = cv2.threshold(blur,120,255,cv2.THRESH_BINARY)
fcrn_loss1 = loss(detect_noise, road_label)
fcrn_loss1 += torch.mean(torch.abs(detect_noise-road_label))/(torch.mean(torch.abs(detect_noise+road_label))+0.001)
Fcrn_decode_optimizer.zero_grad()
Fcrn_encode_optimizer.zero_grad()
fcrn_loss1.backward()
Fcrn_decode_optimizer.step()
Fcrn_encode_optimizer.step()
writer.add_scalar('g_loss', g_loss.data.item(), global_step = batch_idx)
writer.add_scalar('d_loss', d_loss.data.item(), global_step = batch_idx)
writer.add_scalar('Fcrn_loss', fcrn_loss1.data.item(), global_step = batch_idx)
if batch_idx % 20 == 0:
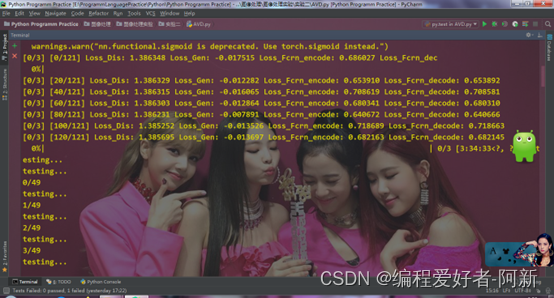
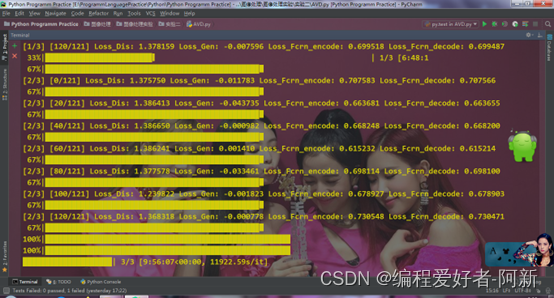
tqdm.write('[{}/{}] [{}/{}] Loss_Dis: {:.6f} Loss_Gen: {:.6f} Loss_Fcrn_encode: {:.6f} Loss_Fcrn_decode: {:.6f}'
.format(epoch, num_epochs, batch_idx, len(train_dataloader), d_loss.data.item(), g_loss.data.item(), (fcrn_loss.data.item())/2, (fcrn_loss1.data.item())/2))
if batch_idx % 300 == 0:
mix = np.concatenate(((road_np+1)*255/2, road_label_np*255, detect_noise_np*255), axis=0)
# feature_np = cv2.resize((feature_np + 1)*255/2, (opt.image_scale_w, opt.image_scale_h))
# fake_feature_np = cv2.resize((fake_feature_np + 1)*255/2, (opt.image_scale_w, opt.image_scale_h))
# mix1 = np.concatenate((feature_np, fake_feature_np), axis=0)
cv2.imwrite("./results/dete{}_{}.png".format(epoch, batch_idx), mix)
# cv2.imwrite('./results_fcrn_noise/feature{}_{}.png'.format(epoch, batch_idx), mix1)
# cv2.imwrite("./results/feature{}_{}.png".format(epoch, batch_idx), (feature_img + 1)*255/2)
# cv2.imwrite("./results9/label{}_{}.png".format(epoch, batch_idx), np.transpose(road_label.cpu().numpy(), (2, 0, 1))*255)
# 测试函数
def test(device, test_dataloader):
fcrn_encode.eval()
fcrn_decode.eval()
# Gen.eval()
for batch_idx, (road, road_label, img_name)in enumerate(test_dataloader):
road, _ = road.to(device), road_label.to(device)
# z = torch.randn(road.shape[0], 1, IMAGE_SCALE, IMAGE_SCALE, device=device)
# img_noise = torch.cat((road, z), dim=1)
# fake_feature = Gen(img_noise)
feature, x2, x3, x4 = fcrn_encode(road)
det_road = fcrn_decode(feature, x2, x3, x4)
label = det_road.detach().cpu()
label = np.transpose(np.array(utils.make_grid(label, padding=0, nrow=1)), (1, 2, 0))
# blur = cv2.GaussianBlur(label*255, (5, 5), 0)
_, thresh = cv2.threshold(label*255, 200, 255, cv2.THRESH_BINARY)
cv2.imwrite('./test/lab_dete_AVD/{}.png'.format(int(img_name[0])), thresh)
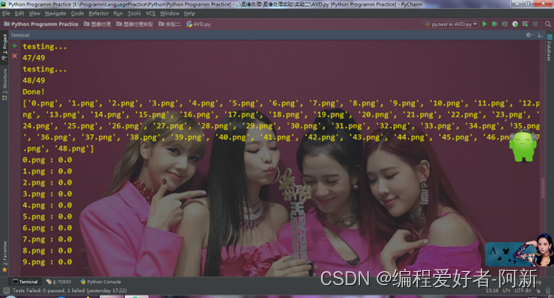
print('testing...')
print('{}/{}'.format(batch_idx, len(test_dataloader)))
print('Done!')
# 文件的读取与保存
def iou(path_img, path_lab, epoch):
img_name = os.listdir(path_img)
img_name.sort(key=lambda x:int(x[:-4]))
print(img_name)
iou_list = []
for i in range(len(img_name)):
det = img_name[i]
det = cv2.imread(path_img + '/' + det, 0)
lab = img_name[i]
lab = cv2.imread(path_lab + '/' + lab[:-4] + '.png', 0)
lab = cv2.resize(lab, (opt.image_scale_w, opt.image_scale_h))
count0, count1, a, count2 = 0, 0, 0, 0
for j in range(det.shape[0]):
for k in range(det.shape[1]):
if det[j][k] != 0 and lab[j][k] != 0:
count0 += 1
elif det[j][k] == 0 and lab[j][k] != 0:
count1 += 1
elif det[j][k] != 0 and lab[j][k] == 0:
count2 += 1
#iou = (count1 + count2)/(det.shape[0] * det.shape[1])
iou = count0/(count1 + count0 + count2 + 0.0001)
iou_list.append(iou)
print(img_name[i], ':', iou)
print('mean_iou:', sum(iou_list)/len(iou_list))
with open('./munich_iou.txt',"a") as f:
f.write("model_num" + " " + str(epoch) + " " + 'mean_iou:' + str(sum(iou_list)/len(iou_list)) + '\n')
# 主函数
if __name__ == '__main__':
if opt.mode == 'train':
num_epochs = opt.num_epochs
for epoch in tqdm(range(num_epochs)):
train(device, train_dataloader, epoch)
Dis_scheduler.step()
Gen_scheduler.step()
encode_scheduler.step()
decode_scheduler.step()
if epoch % 50 == 0:
now = time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime(time.time()))
torch.save(Dis.state_dict(), './model/Dis_{}'+ now +'munich.pkl'.format(opt.alpha))
torch.save(Gen.state_dict(), './model/Gen_{}'+ now +'munich.pkl'.format(opt.alpha))
torch.save(fcrn_decode.state_dict(), './model/fcrn_decode_{}'+ now +'munich.pkl'.format(opt.alpha))
torch.save(fcrn_encode.state_dict(), './model/fcrn_encode_{}'+ now +'munich.pkl'.format(opt.alpha))
print('testing...')
test(device, test_dataloader)
iou('./test/lab_dete_AVD', './munich/test/lab', epoch)
if opt.mode == 'test':
test(device, test_dataloader)
iou('./test/lab_dete_AVD', './munich/test/lab', 'test')
3
4

5
1
2
3

4
5
-6

8


我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶