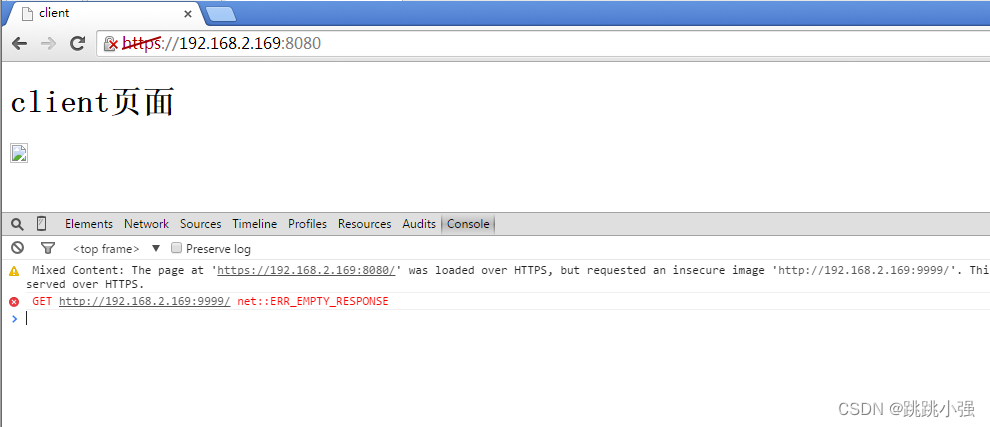
<点击以获取跳转信息 >跳转过去记得按一下f12点击网络请求详情,再刷新一下,就可以看见referer字段:
当我们尝试在浏览器内部直接输入这熟悉的网址时,此时刷新后则是这样一番景象:
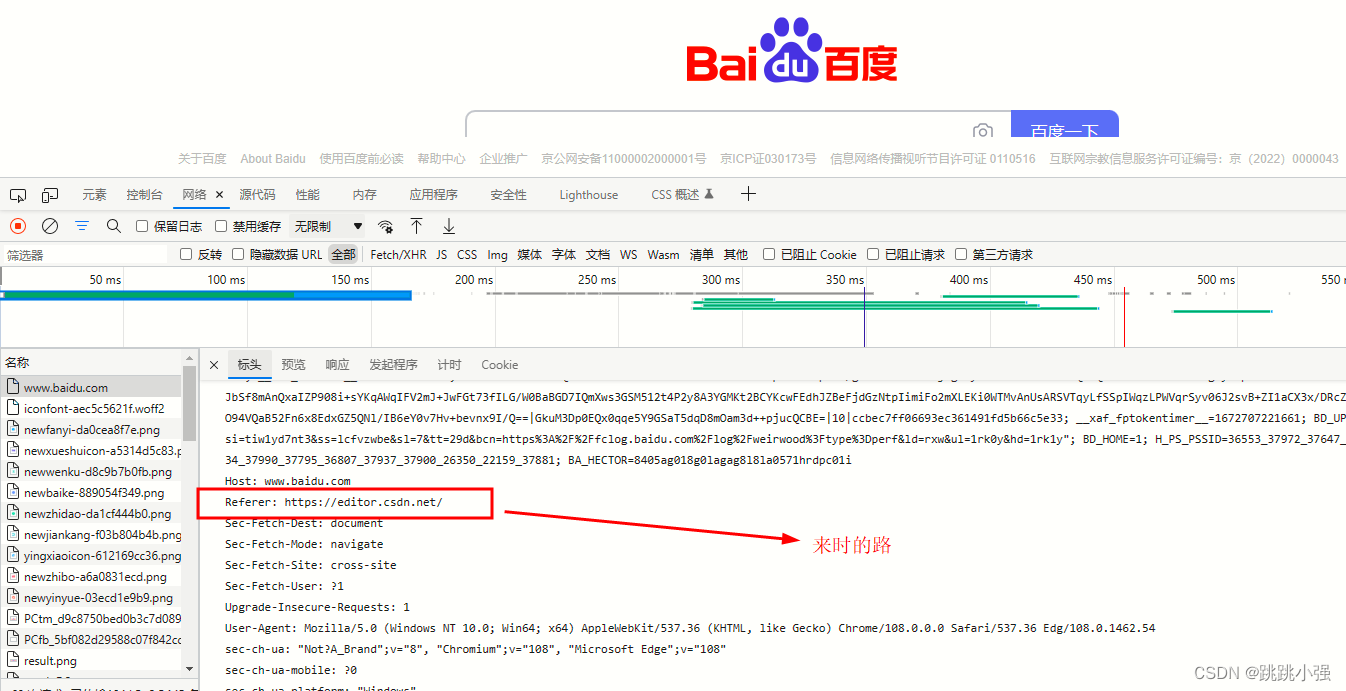
于是你就明白了referer的基本用途,它是存在于http请求头内部的用于标识访问者来源网页的标识字段。通常在普通用户的访问下是不会出现的,常常出现于各个网页之间的相互跳转。
说到这里你想到了什么,各个网页?嗯…记得这块在网页里面引用别人的东西好像还挺多的。直接把人家的图片地址写下来,就能显示,可方便了。对,这种行为就是盗图,当然只要是可以在网页上访问的网络资源,基本上都会面临这样一种情况:被盗取资源。盗取链接与防止盗取链接形成了一个经久不衰的话题。那么今天我们就通过几个小例子来体会一下盗图与防盗图的斗争吧。好好的理解一下关于referer字段的故事。
Referer请求头包含了当前请求页面的来源页面的地址,即表示当前页面是通过此来源页面里的链接进入的。服务端一般使用Referer(注:
正确英语拼写应该是referrer,由于早期HTTP规范的拼写错误,为了保持向后兼容就一直延续下来)请求头识别访问来源,可能会以此统计分析、日志记录以及缓存优化等。
真有人为了这事情发博客吐槽…哈哈 详细历史见吐槽内容
言归正传,学习!显然,注意刚刚访问百度的同学可以细心的发现referrer-policy这个引用者策略,其规定了referer的具体使用规则。不同的设置如下给出:
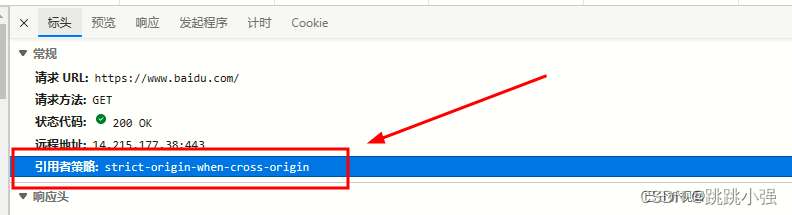
no-referrer : 整个referee首部会被移除,访问来源信息不随着请求一起发送。no-referrer-when-downgrade : 在没有指定任何策略的情况下用户代理的默认行为。在同等安全级别的情况下,引用页面的地址会被发送(HTTPS->HTTPS),但是在降级的情况下不会被发送 (HTTPS->HTTP).origin: 在任何情况下,仅发送文件的源作为引用地址。例如 https://example.com/page.html 会将 https://example.com/ 作为引用地址。origin-when-cross-origin: 对于同源的请求,会发送完整的URL作为引用地址,但是对于非同源请求仅发送文件的源。strict-origin: 在同等安全级别的情况下,发送文件的源作为引用地址(HTTPS->HTTPS),但是在降级的情况下不会发送 (HTTPS->HTTP)。 strict-origin-when-cross-origin: 对于同源的请求,会发送完整的URL作为引用地址;在同等安全级别的情况下,发送文件的源作为引用地址(HTTPS->HTTPS);在降级的情况下不发送此首部 (HTTPS->HTTP)。unsafe-url: 无论是同源请求还是非同源请求,都发送完整的 URL(移除参数信息之后)作为引用地址。(最不安全了)可以在HTML里面设置meta标签
<meta name="referrer" content="origin">
也可以用<a>、<area>、<img>、<iframe>、<script> 或者<link> 元素上的 referrerpolicy 属性为其设置独立的请求策略。
比如:
<script src='/javascripts/test.js' referrerpolicy="no-referrer"></script>
注意,如果不对页面进行处理的话,默认的referer-policy的数值是 strict-origin-when-cross-origin
前面我们说过防盗链的工作原理,其就是通过Referer或者签名,网站可以检测目标网页访问的来源网页,如果是资源文件,则可以追踪到显示它的网页地址 一旦检测到来源不是本站,即进行阻止或者返回指定的页面。
那么要绕过它就至少的满足下面的三个条件之一:
- 本网站。
- 无referer信息的情况。(服务器认为是从浏览器直接访问的图片URL,所以这种情况下能正常访问)
- 授权的网址。
显然,方法1、3均无法实现。留给我们的方法就只有想办法去除自己在访问时的referer字段了。
当我们的目标被盗网站的策略采用默认策略时,我们可以利用访问主动降级的方式将目标图片盗链下来。也就是说我们可以在https的网页中用http请求另一个https网站的资源。此时可以不发送我们的referer字段,达到绕过防盗链的效果。(由于浏览器的升级,现在这种操作已经被禁止了。)虽然如此,我们还是尝试这复现一下这一操作。
示例环境:centos7 安装nodejs环境
用nodejs同时模拟出”盗图人“和“拥图人”。我们使用古老的浏览器尝试访问网页见证这一古老的偷图方法。
如何在本地为本地的web服务创建自签名成了我们要解决的第一个问题。按照以下步骤创建对应的证书以及签名。在此之前应当创建对应的文件夹:
[root@blackstone ceshi]# mkdir demo01
[root@blackstone ceshi]# mkdir -p ./demo01/server/keys
[root@blackstone ceshi]# mkdir -p ./demo01/server/src
[root@blackstone ceshi]# mkdir -p ./demo01/client/src
[root@blackstone ceshi]# mkdir -p ./demo01/client/keys
[root@blackstone ceshi]# mkdir -p ./demo01/ca
[root@blackstone ceshi]# tree demo01
demo01
├── ca
├── client
│ ├── keys
│ └── src
└── server
├── keys
└── src
好,接下来到这个demo01目录下,进行证书的构造
#1.生成私钥
// 生成服务器端私钥
openssl genrsa -out server/keys/server.key 1024
// 生成客户端私钥
openssl genrsa -out client/keys/client.key 1024
#2.生成公钥
openssl rsa -in server/keys/server.key -pubout -out server/keys/server.pem
openssl rsa -in client/keys/client.key -pubout -out client/keys/client.pem
#3.CA证书自签名
#3.1 创建CA私钥
openssl genrsa -out ca/ca.key 1024
#3.2 生成CA的CSR文件与crt
#生成csr
openssl req -new -key ca/ca.key -out ca/ca.csr
#生成crt
openssl x509 -req -in ca/ca.csr -signkey ca/ca.key -out ca/ca.crt
#3.3 为server发放证书
#生成csr文件
openssl req -new -key server/keys/server.key -out server/keys/server.csr
#签名过程需要CA的证书和私钥参与, 最终颁发一个带有CA签名的证书
openssl x509 -req -CA ca/ca.crt -CAkey ca/ca.key -CAcreateserial -in server/keys/server.csr -out server/keys/server.crt
#3.4 为client发放证书
#生成CSR文件
openssl req -new -key client/keys/client.key -out client/keys/client.csr
#签名过程需要CA的证书和私钥参与, 最终颁发一个带有CA签名的证书
openssl x509 -req -CA ca/ca.crt -CAkey ca/ca.key -CAcreateserial -in client/keys/client.csr -out client/keys/client.crt
关于CA证书:为了得到签名证书,服务器端需要通过自己的私钥生成CSR(Certificate Signing Request,证书签名请求)文件。CA机构通过这个文件颁发属于该服务器端的签名证书,只要通过CA机构就能验证证书是否合法。
上面用是自签名证书来构建安全网络的。所谓自签名证书,就是自己扮演CA机构,给自己得服务器端颁发签名证书。其过程包括了生成CA私钥、生成CSR文件、通过私钥自签名生成证书
经过上面一通创建之后,我们使用tree确认生成无误
server目录下创建server.js用于建立服务
let https = require("https");
let fs = require("fs");
let url = require("url");
let path = require("path");
// 白名单
const whiteList = ["192.168.2.169:80"];
const options = {
key: fs.readFileSync("./keys/server.key"),
cert: fs.readFileSync("./keys/server.crt"),
};
https
.createServer(options, function (req, res) {
let refer = req.headers["referer"] || req.headers["refer"];
console.log('refer----', refer, req.url);
res.setHeader("Access-Control-Allow-Origin", "*");
if (refer) {
let referHostName = url.parse(refer, true).host;
let currentHostName = url.parse(req.url, true).host;
console.log(referHostName, currentHostName, '--==')
// 当referer不为空, 但host未能命中目标网站且不在白名单内时, 返回错误的图
if (
referHostName != currentHostName &&
whiteList.indexOf(referHostName) == -1
) {
res.setHeader("Content-Type", "image/jpeg");
fs.createReadStream(path.join(__dirname, "/src/img/403.jpg")).pipe(res);
return;
}
}
// 当referer为空时, 返回正确的图
res.setHeader("Content-Type", "image/jpeg");
fs.createReadStream(path.join(__dirname, "/src/img/1.jpg")).pipe(res);
}).listen(9999);
监听的是9999端口,用于模拟被偷服务器,在其对应的src目录下放上相应的资源
服务端的nodejs文件client.js
let https = require("https");
let fs = require("fs");
let url = require("url");
let path = require("path");
var options = {
hostname: "localhost",
port: 8000,
path: "/",
method: "GET",
rejectUnauthorized: false,
key: fs.readFileSync("./keys/client.key"),
cert: fs.readFileSync("./keys/client.crt"),
ca: [fs.readFileSync("../ca/ca.crt")],
};
// 创建服务器
https.createServer(options, function (req, res) {
let staticPath = path.join(__dirname, "src");
let pathObj = url.parse(req.url, true);
if (pathObj.pathname === "/") {
pathObj.pathname += "index.html";
}
// 读取静态目录里面的文件,然后发送出去
let filePath = path.join(staticPath, pathObj.pathname);
fs.readFile(filePath, "binary", function (err, content) {
if (err) {
res.writeHead(404, "Not Found");
res.end("<h1>404 Not Found</h1>");
} else {
res.writeHead(200, "OK");
res.write(content, "binary");
res.end();
}
});
}).listen(8080);
配置client首页文件
[root@blackstone client]# cat ./src/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>client</title>
</head>
<body>
<h1>client页面</h1>
<div id="container">
<!-- <img src="https://192.168.2.169:9999/" referrerpolicy="no-referrer"> -->
<img src="http://192.168.2.169:9999">
</div>
<!-- <script src="js/fetchImg.js"></script> -->
</body>
</html>
依次分别运行server和client
[root@blackstone server]# node server.js
[root@blackstone client]# node client.js
使用火狐浏览器测试访问:
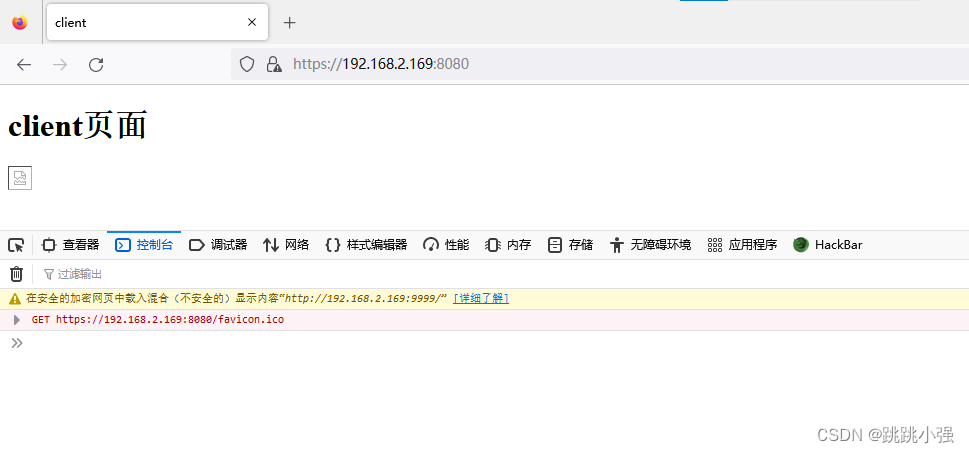
可以看到,尽管我们尝试进行盗链,但是因为浏览器的安全限定,无法显示偷出来的图片,我们掏出超低版本的浏览器试试。。。经测试暂时无果,这个古老的方案大抵是被禁用掉了。
点击此处获取老版本浏览器
<meta name="referrer" content="no-referrer" />
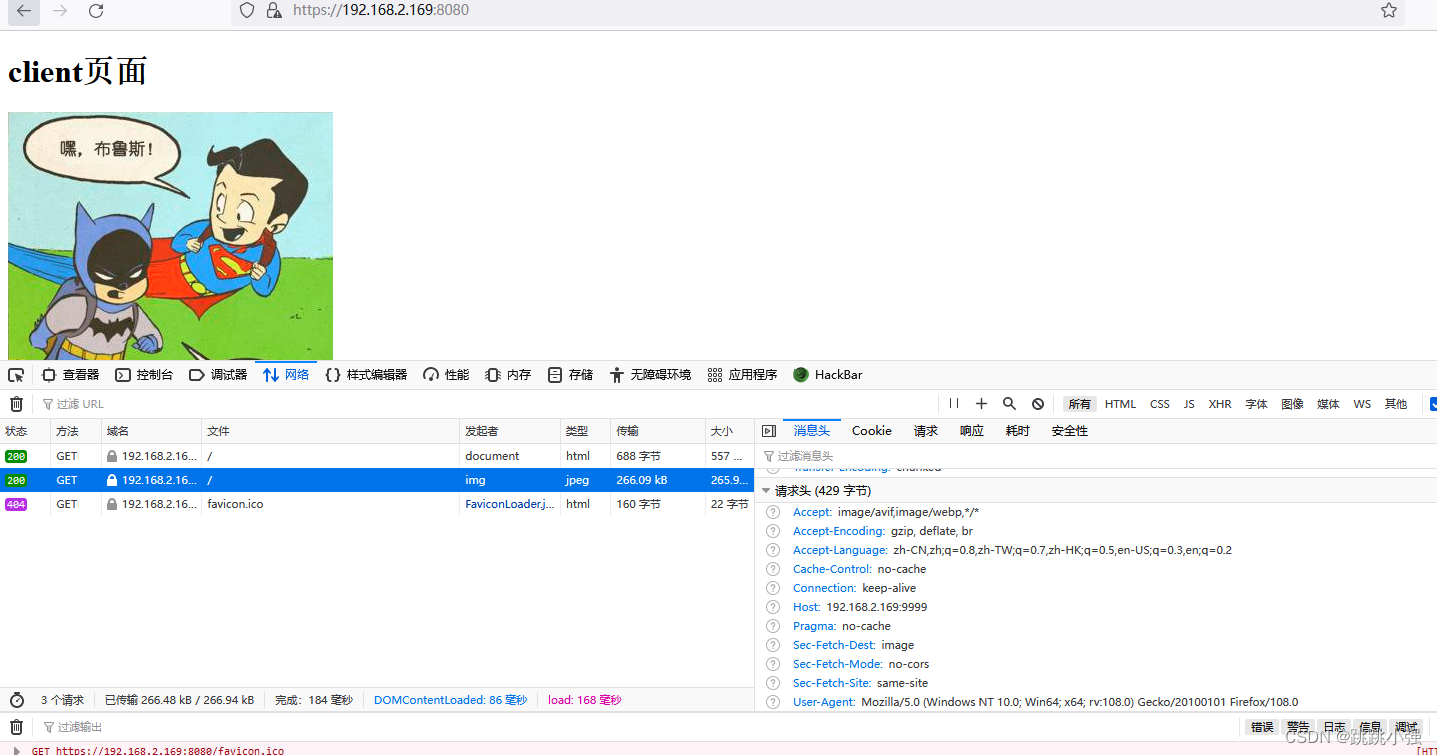
可以清晰的看到,设置后发出的https请求已经没了referer字段,正常请求到了图片
在标签旁设置上这个属性就行
<img src="https://192.168.2.169:9999/" referrerpolicy="no-referrer">
function showImg(src, wrapper ) {
let url = new URL(src);
let frameid = 'frameimg' + Math.random();
window.img = `<img id="tmpImg" width=400 src="${url}" alt="图片加载失败,请稍后再试"/> `;
// 构造一个iframe
iframe = document.createElement('iframe')
iframe.id = frameid
iframe.src = "javascript:parent.img;" // 通过内联的javascript,设置iframe的src
// 校正iframe的尺寸,完整展示图片
iframe.onload = function () {
var img = iframe.contentDocument.getElementById("tmpImg")
if (img) {
iframe.height = img.height + 'px'
iframe.width = img.width + 'px'
}
}
iframe.width = 10
iframe.height = 10
iframe.scrolling = "no"
iframe.frameBorder = "0"
wrapper.appendChild(iframe)
}
showImg('https://192.168.2.169:9999', document.querySelector('#container'))
XMLHttpRequest中setRequestHeader方法,用于向请求头添加或修改字段。我们能不能手动将修改 referer字段呢?
演示代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>client</title>
</head>
<body>
<h1>client页面</h1>
<div id="container">
</div>
</body>
<script src="./03.js"></script>
</html>
// 通过ajax下载图片
function loadImage(uri) {
return new Promise(resolve => {
let xhr = new XMLHttpRequest();
xhr.responseType = "blob";
xhr.onload = function() {
resolve(xhr.response);
};
xhr.open("GET", uri, true);
// 通过setRequestHeader设置header不会生效
// 会提示 Refused to set unsafe header "Referer"
xhr.setRequestHeader("Referer", "");
xhr.send();
});
}
// 将下载下来的二进制大对象数据转换成base64,然后展示在页面上
function handleBlob(blob) {
let reader = new FileReader();
reader.onload = function(evt) {
let img = document.createElement('img');
img.src = evt.target.result;
document.getElementById('container').appendChild(img)
};
reader.readAsDataURL(blob);
}
const imgSrc = "https://tiebapic.baidu.com/forum/w%3D580%3B/sign=f88eb0f2cf82b9013dadc33b43b6ab77/562c11dfa9ec8a135455cc35b203918fa1ecc09c.jpg";
loadImage(imgSrc).then(blob => {
handleBlob(blob);
});
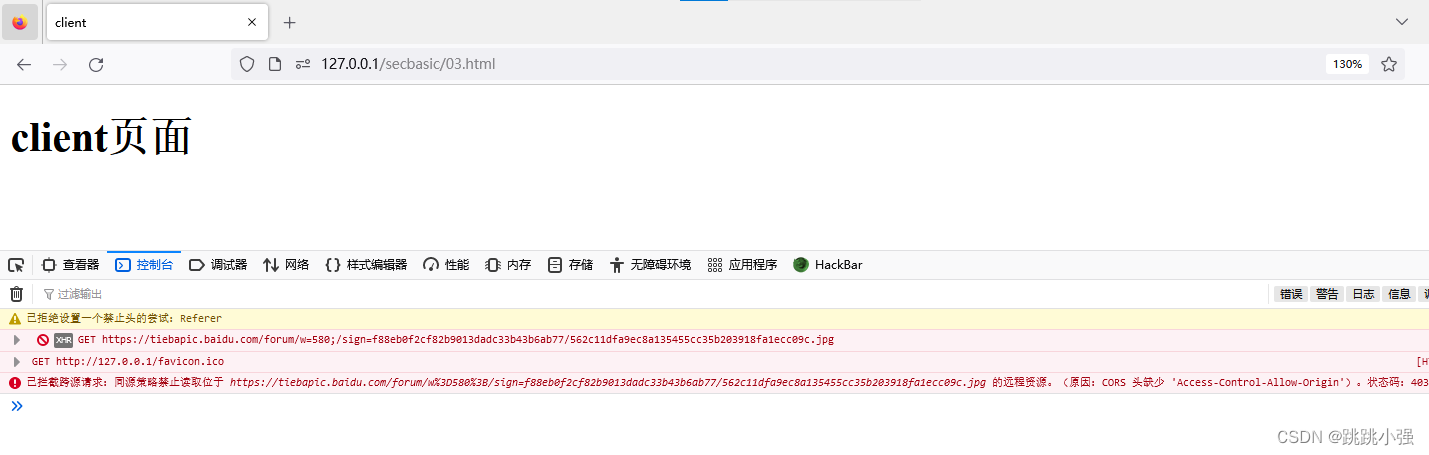
可以看见setRequestHeader设置referer响应头是无效的,这是由于浏览器为了安全起见,无法手动设置部分保留字段,不幸的是Referer恰好就是保留字段之一,详情列表参考Forbidden header name。
可见使用xmlhttprequest提供的方法用AJAX同源请求无法完成这一操作。使用fetch可以解决这一问题。
// 将下载下来的二进制大对象数据转换成base64,然后展示在页面上
function handleBlob(blob) {
let reader = new FileReader();
reader.onload = function(evt) {
let img = document.createElement('img');
img.src = evt.target.result;
document.getElementById('container').appendChild(img)
};
reader.readAsDataURL(blob);
}
const imgSrc = "https://192.168.2.169:9999";
function fetchImage(url) {
return fetch(url, {
headers: {
// "Referer": "", // 这里设置无效
},
method: "GET",
referrer: "", // 将referer置空
// referrerPolicy: 'no-referrer',
}).then(response => response.blob());
}
fetchImage(imgSrc).then(blob => {
handleBlob(blob);
});
可以看到这里的请求明显没了referer字段
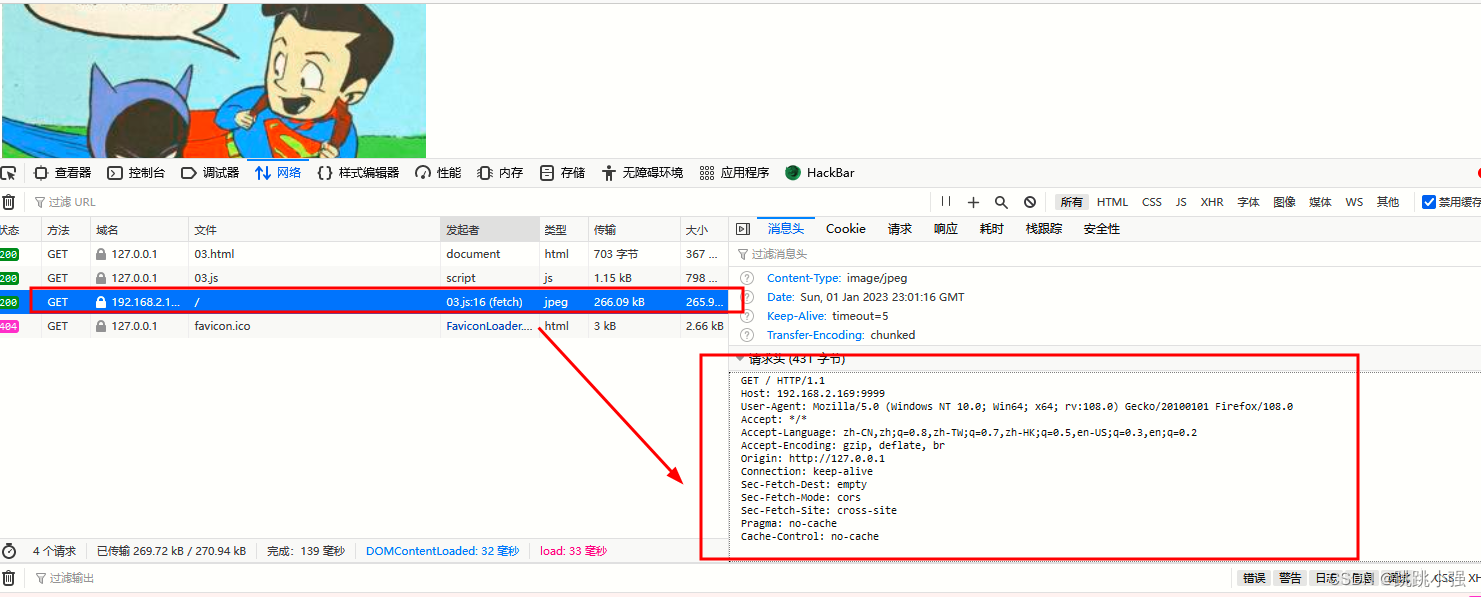
更加"刑"的方法就是直接搭建一个中转服务器,代理盗链者对目标资源进行正常请求,并将获取到的资源进行转发。
当然,在上面罗列了那么多的绕过防盗链手法中,大部分的方法就是人为或者自动的取消掉自己的referer头部伪装成普通用户的正常访问去获取资源。要解决这个问题可以从以下几个方面去开展:
1.动态文件名,定期更换文件名称或者路径
2.判定引用地址,一般是判断浏览器请求时HTTP头的Referer字段的值
3.使用登录验证,cookie
4.图片加水印
5.可以购买一些安全服务对服务器的请求进行过滤
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
rails中是否有任何规定允许站点的所有AJAXPOST请求在没有authenticity_token的情况下通过?我有一个调用Controller方法的JqueryPOSTajax调用,但我没有在其中放置任何真实性代码,但调用成功。我的ApplicationController确实有'request_forgery_protection'并且我已经改变了config.action_controller.consider_all_requests_local在我的environments/development.rb中为false我还搜索了我的代码以确保我没有重载ajaxSend来发送
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我正在使用Heroku(heroku.com)来部署我的Rails应用程序,并且正在构建一个iPhone客户端来与之交互。我的目的是将手机的唯一设备标识符作为HTTPheader传递给应用程序以进行身份验证。当我在本地测试时,我的header通过得很好,但在Heroku上它似乎去掉了我的自定义header。我用ruby脚本验证:url=URI.parse('http://#{myapp}.heroku.com/')#url=URI.parse('http://localhost:3000/')req=Net::HTTP::Post.new(url.path)#boguspara
我想找到在某些文本中找到一些(让它是两个)句子的好方法。什么会更好-使用正则表达式或拆分方法?你的想法?应JeremyStein的要求-有一些例子示例:输入:ThefirstthingtodoistocreatetheCommentmodel.We’llcreatethisinthenormalway,butwithonesmalldifference.IfwewerejustcreatingcommentsforanArticlewe’dhaveanintegerfieldcalledarticle_idinthemodeltostoretheforeignkey,butinthis
我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token