文末附下载方式
| 组件 | 版本 |
|---|---|
| elasticseach | 7.13.0 |
| kibana | 7.13.0 |
| logstash | 7.13.0 |
| flink | 1.13.6 |
因为在正常的情况下,Flink的流数据是非常大的,有时候会使用print()打印数据自己查看,有时候为了查找问题会开启debug日志,就会导致日志文件非常大,通过Web UI查看对应的日志文件是会非常卡,所以首先将日志文件按照大小滚动生成文件,我们在查看时不会因为某个文件非常大导致Web UI界面卡,没法查看。
# Allows this configuration to be modified at runtime. The file will be checked every 30 seconds.
monitorInterval=30
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.file.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO
# Log all infos in the given file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 500MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
针对按照日志文件大小滚动生成文件的方式,可能因为某个错误的问题,需要看好多个日志文件,所以可以把日志文件通过KafkaAppender写入到kafka中,然后通过ELK等进行日志搜索甚至是分析告警。
# Allows this configuration to be modified at runtime. The file will be checked every 30 seconds.
monitorInterval=30
# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.kafka.ref = Kafka
rootLogger.appenderRef.file.ref = RollingFileAppender
# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO
# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO
logger.shaded_zookeeper.name = org.apache.flink.shaded.zookeeper3
logger.shaded_zookeeper.level = INFO
# Log all infos in the given file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = false
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size = 500MB
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = 10
# kafka
appender.kafka.type = Kafka
appender.kafka.name = Kafka
appender.kafka.syncSend = true
appender.kafka.ignoreExceptions = false
appender.kafka.topic = flink_logs
appender.kafka.property.type = Property
appender.kafka.property.name = bootstrap.servers
appender.kafka.property.value = localhost:9092
appender.kafka.layout.type = JSONLayout
apender.kafka.layout.value = net.logstash.log4j.JSONEventLayoutV1
appender.kafka.layout.compact = true
appender.kafka.layout.complete = false
#appender.kafka.layout.additionalField1.type = KeyValuePair
#appender.kafka.layout.additionalField1.key = logdir
#appender.kafka.layout.additionalField1.value = ${sys:log.file}
#appender.kafka.layout.additionalField2.type = KeyValuePair
#appender.kafka.layout.additionalField2.key = flink_job_name
#appender.kafka.layout.additionalField2.value = ${sys:flink_job_name}
#appender.kafka.layout.additionalField3.type = KeyValuePair
#appender.kafka.layout.additionalField3.key = yarnContainerId
#appender.kafka.layout.additionalField3.value = ${sys:yarnContainerId}
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
上面的appender.kafka.layout.type可以使用JSONLayout,也可以自定义。自定义需要将上面的appender.kafka.layout.type和appender.kafka.layout.value修改成如下:
appender.kafka.layout.type = PatternLayout
appender.kafka.layout.pattern = {"log_level":"%p","log_timestamp":"%d{ISO8601}","log_thread":"%t","log_file":"%F","log_line":"%L","log_message":"'%m'","log_path":"%X{log_path}","job_name":"${sys:flink_job_name}"}%n
针对于不同的Flink模式,需要在flink/lib目录下放入的jar包也有所不同:
# 根据kafka的版本放入kafka-clients
kafka-clients-3.1.0.jar
如果是通过flink on yarn模式还可以添加自定义字段:
# 日志路径
appender.kafka.layout.additionalField1.type = KeyValuePair
appender.kafka.layout.additionalField1.key = logdir
appender.kafka.layout.additionalField1.value = ${sys:log.file}
# flink-job-name
appender.kafka.layout.additionalField2.type = KeyValuePair
appender.kafka.layout.additionalField2.key = flinkJobName
appender.kafka.layout.additionalField2.value = ${sys:flinkJobName}
# 提交到yarn的containerId
appender.kafka.layout.additionalField3.type = KeyValuePair
appender.kafka.layout.additionalField3.key = yarnContainerId
appender.kafka.layout.additionalField3.value = ${sys:yarnContainerId}
添加以上的自定义字段,需要在flink-conf.yaml中配置如下:
env.java.opts.taskmanager: -DyarnContainerId=$CONTAINER_ID
env.java.opts.jobmanager: -DyarnContainerId=$CONTAINER_ID
之后进入flink目录提交任务到yarn:
./bin/flink run-application \
-d \
-t yarn-application \
-Dyarn.application.name=TopSpeed \
-Dmetrics.reporter.promgateway.groupingKey="TopSpeed" \
-Dmetrics.reporter.promgateway.jobName=TopSpeed \
-Denv.java.opts="-DflinkJobName=TopSpeed" \
./examples/streaming/TopSpeedWindowing.jar
消费kafka的消息可以看到如下:
{
"instant":{
"epochSecond":1655379271,
"nanoOfSecond":642000000
},
"thread":"main",
"level":"INFO",
"loggerName":"org.apache.flink.runtime.io.network.netty.NettyServer",
"message":"Transport type 'auto': using EPOLL.",
"endOfBatch":false,
"loggerFqcn":"org.apache.logging.slf4j.Log4jLogger",
"threadId":1,
"threadPriority":5,
"logdir":"/yarn/container-logs/application_1655373794581_0005/container_e46_1655373794581_0005_01_000002/taskmanager.log",
"flinkJobName":"TopSpeed",
"yarnContainerId":"container_e46_1655373794581_0005_01_000002"
}
# 根据kafka的版本放入kafka-clients
kafka-clients-3.1.0.jar
# jackson对应的jar包
jackson-annotations-2.13.3.jar
jackson-core-2.13.3.jar
jackson-databind-2.13.3.jar
日志写入Kafka之后可以通过Logstash接入elasticsearch,然后通过kibana进行查询或搜索,安装logstash的步骤可以参考官网。
将以下内容写入config/logstash-sample.conf文件中
input {
kafka {
bootstrap_servers => ["cdh2:9092,cdh3:9092,cdh4:9092"]
group_id => "logstash-group"
topics => ["flink_logs"]
consumer_threads => 3
type => "flink-logs"
codec => "json"
auto_offset_reset => "latest"
}
}
output {
elasticsearch {
hosts => ["cdh2:9200","cdh3:9200","cdh4:9200"]
index => "flink-log-%{+YYYY-MM-dd}"
}
}
上述配置按天生成新的flink日志索引,之后运行logstash,运行的日志没有报错即可在elasticsearch查看对应的索引日志。
bin/logstash -f ./config/logstash-sample.conf 2>&1 >./logs/logstash.log &
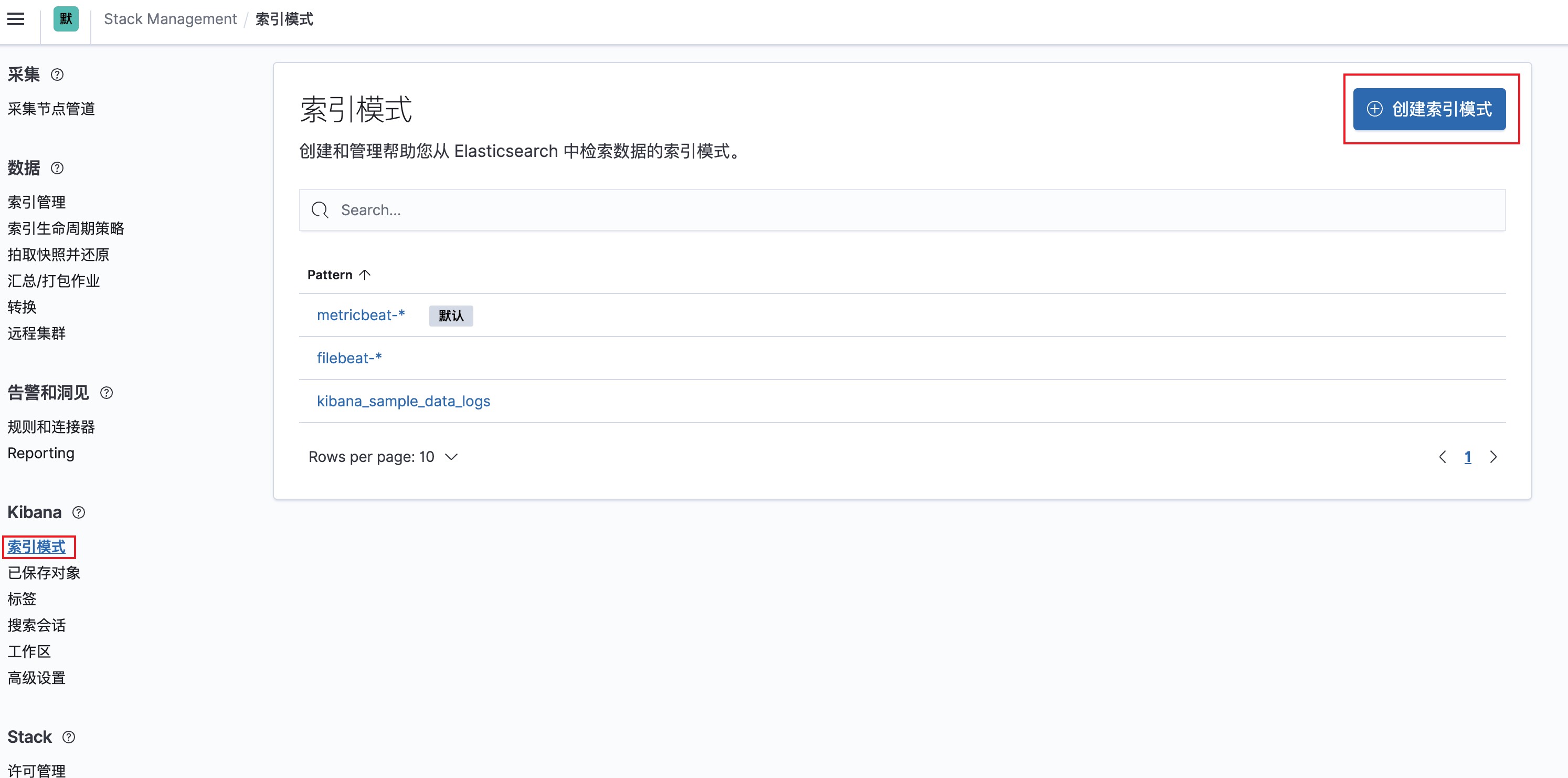
新建索引模式,因为我们上面的flink日志的索引名称为flin-log-%{+YYYY-MM-dd},所以我们创建一个匹配flink-log的索引模式即可。
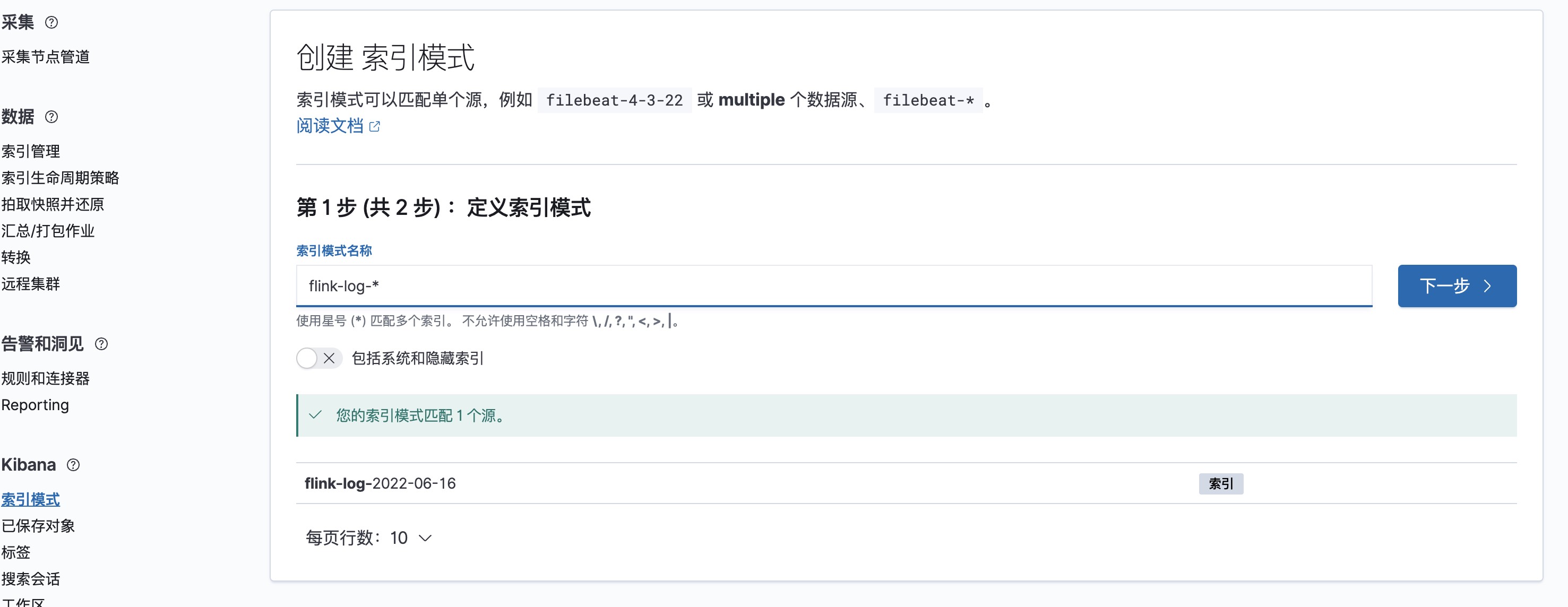
之后点击下一步,选择时间字段为@timestamp即可。
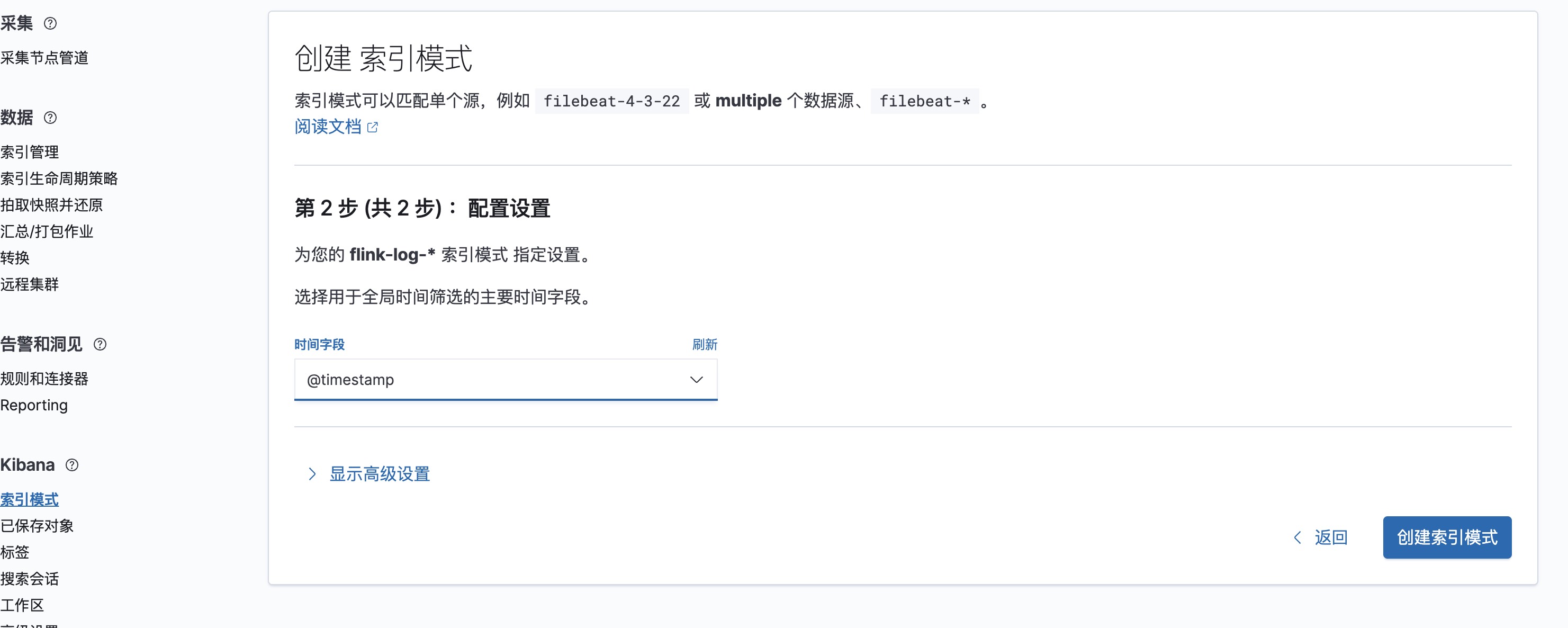
打开Discover选择刚刚创建的索引模式,在左上角可以添加筛选条件。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只