文章目录
定时器是一种实际开发中非常常用的组件, 类似于一个 “闹钟”, 达到一个设定的时间之后, 就执行某个指定好的代码.
类似于这样的场景就需要用到定时器.
标准库中提供了一个 Timer 类, Timer 类的核心方法为schedule.
Timer类构造时内部会创建线程, 有下面的四个构造方法, 可以指定线程名和是否将定时器内部的线程指定为后台线程(即守护线程), 如果不指定, 定时器对象内部的线程默认为前台线程.
| 序号 | 构造方法 | 解释 |
|---|---|---|
| 1 | public Timer() | 无参, 定时器关联的线程为前台线程, 线程名为默认值. |
| 2 | public Timer(boolean isDaemon) | 指定定时器中关联的线程类型, true(后台线程), false(前台线程). |
| 3 | public Timer(String name) | 指定定时器关联的线程名, 线程类型为前台线程 |
| 4 | public Timer(String name, boolean isDaemon) | 指定定时器关联的线程名和线程类型 |
schedule 方法是给Timer注册一个任务, 这个任务在指定时间后进行执行, TimerTask类就是专门描述定时器任务的一个抽象类, 它实现了Runnable接口.
public abstract class TimerTask implements Runnable // jdk源码
| 序号 | 方法 | 解释 |
|---|---|---|
| 1 | public void schedule(TimerTask task, long delay) | 指定任务, 延迟多久执行该任务 |
| 2 | public void schedule(TimerTask task, Date time) | 指定任务, 指定任务的执行时间 |
| 3 | public void schedule(TimerTask task, long delay, long period) | 连续执行指定任务, 延迟时间, 连续执行任务的时间间隔, 毫秒为单位 |
| 4 | public void schedule(TimerTask task, Date firstTime, long period) | 连续执行指定任务, 第一次任务的执行时间, 连续执行任务的时间间隔 |
| 5 | public void scheduleAtFixedRate(TimerTask task, Date firstTime, long period) | 与方法4作用相同 |
| 6 | public void scheduleAtFixedRate(TimerTask task, long delay, long period) | 与方法3作用相同 |
| 7 | public void cancel() | 清空任务队列中的全部任务, 正在执行的任务不受影响. |
代码示例:
import java.util.Timer;
import java.util.TimerTask;
public class TestProgram {
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("执行延后3s的任务!");
}
}, 3000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("执行延后2s后的任务!");
}
}, 2000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("执行延后1s的任务!");
}
}, 1000);
}
}
执行结果:
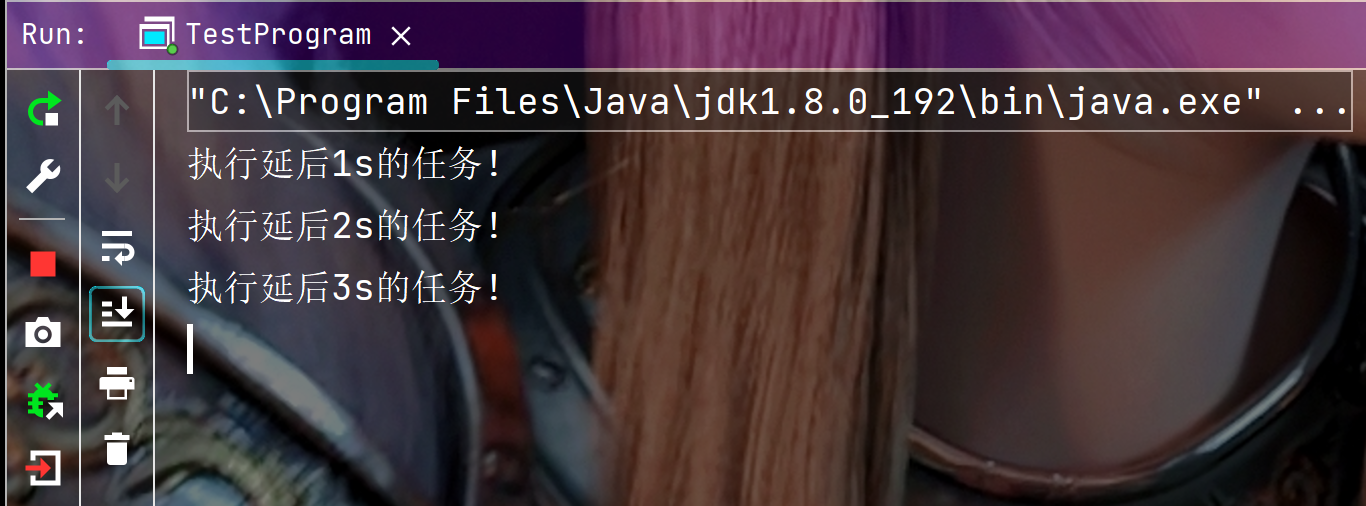
观察执行结果, 任务执行结束后程序并没有结束, 即进程并没有结束, 这是因为上面的代码定时器内部是开启了一个线程去执行任务的, 虽然任务执行完成了, 但是该线程并没有销毁; 这和自己定义一个线程执行完成 run 方法后就自动销毁是不一样的, Timer 本质上是相当于线程池, 它缓存了一个工作线程, 一旦任务执行完成, 该工作线程就处于空闲状态, 等待下一轮任务.
首先, 我们需要定义一个类, 用来描述一个定时器当中的任务, 类要成员要有一个Runnable, 再加上一个任务执行的时间戳, 具体还包含如下内容:
class MyTask implements Comparable<MyTask>{
//要执行的任务
private Runnable runnable;
//任务的执行时间
private long time;
public MyTask(Runnable runnable, long time) {
this.runnable = runnable;
this.time = time;
}
//获取当前任务的执行时间
public long getTime() {
return this.time;
}
//执行任务
public void run() {
runnable.run();
}
@Override
public int compareTo(MyTask o) {
return (int) (this.time - o.time);
}
}
然后就需要实现定时器类了, 我们需要使用一个数据结构来组织定时器中的任务, 需要每次都能将时间最早的任务找到并执行, 这个情况我们可以考虑用优先级队列(即小根堆)来实现, 当然我们还需要考虑线程安全的问题, 所以我们选用优先级阻塞队列 PriorityBlockingQueue 是最合适的, 特别要注意在自定义的任务类当中要实现比较方式, 或者实现一下比较器也行.
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
我们自己实现的定时器类中要有一个注册任务的方法, 用来将任务插入到优先级阻塞队列中;
还需要有一个线程用来执行任务, 这个线程是从优先级阻塞队列中取出队首任务去执行, 如果这个任务还没有到执行时间, 那么线程就需要把这个任务再放会队列当中, 然后线程就进入等待状态, 线程等待可以使用sleep和wait, 但这里有一个情况需要考虑, 当有新任务插入到队列中时, 我们需要唤醒线程重新去优先级阻塞队列拿队首任务, 毕竟新注册的任务的执行时间可能是要比前一阵拿到的队首任务时间是要早的, 所以这里使用wait进行进行阻塞更合适, 那么唤醒操作就需要使用notify来实现了.
实现代码如下:
//自己实现的定时器类
class MyTimer {
//扫描线程
private Thread t = null;
//阻塞队列,存放任务
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
public MyTimer() {
//构造扫描线程
t = new Thread(() -> {
while (true) {
//取出队首元素,检查队首元素执行任务的时间
//时间没到,再把任务放回去
//时间到了,就执行任务
try {
synchronized (this) {
MyTask task = queue.take();
long curTime = System.currentTimeMillis();
if (curTime < task.getTime()) {
//时间没到,放回去
queue.put(task);
//放回任务后,不应该立即就再次取出该任务
//所以wait设置一个阻塞等待,以便新任务到时间或者新任务来时后再取出来
this.wait(task.getTime() - curTime);
} else {
//时间到了,执行任务
task.run();
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t.start();
}
/**
* 注册任务的方法
* @param runnable 任务内容
* @param after 表示在多少毫秒之后执行. 形如 1000
*/
public void schedule (Runnable runnable, long after) {
//获取当前时间的时间戳再加上任务时间
MyTask task = new MyTask(runnable, System.currentTimeMillis() + after);
queue.put(task);
//每次当新任务加载到阻塞队列时,需要中途唤醒线程,因为新进来的任务可能是最早需要执行的
synchronized (this) {
this.notify();
}
}
}
要注意上面扫描线程中的synchronized并不能只要针对wait方法加锁, 如果只针对wait加锁的话, 考虑一个极端的情况, 假设的扫描线程刚执行完put方法, 这个线程就被cpu调度走了, 此时另有一个线程在队列中插入了新任务, 然后notify唤醒了线程, 而刚刚并没有执行wait阻塞, notify就没有起到什么作用, 当cpu再调度到这个线程, 这样的话如果新插入的任务要比原来队首的任务时间更早, 那么这个新任务就被错过了执行时间, 这些线程安全问题真是防不胜防啊, 所以我们需要保证这些操作的原子性, 也就是上面的代码, 扩大锁的范围, 保证每次notify都是有效的.
那么最后基于上面的代码, 我们来测试一下这个定时器:
public class TestDemo23 {
public static void main(String[] args) {
MyTimer timer = new MyTimer();
timer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("2s后执行的任务1");
}
}, 2000);
timer.schedule(new Runnable() {
@Override
public void run() {
System.out.println("2s后执行的任务1");
}
}, 1000);
}
}
执行结果:
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?