
个人简介:
> 📦个人主页:赵四司机
> 🏆学习方向:JAVA后端开发
> ⏰往期文章:SpringBoot项目整合微信支付
> 🔔博主推荐网站:牛客网 刷题|面试|找工作神器
> 📣种一棵树最好的时间是十年前,其次是现在!
> 💖喜欢的话麻烦点点关注喔,你们的支持是我的最大动力。
前言:
前面介绍了项目的搭建过程并且实现了部分功能,你会发现无论什么时候都离不开Nginx和Gateway的支持,我们用Nginx实现了反向代理及静态资源映射,在服务器(代码块层面)我们使用了Gateway作为第二层网关实现统一授权、信息认证及路由,那么这时候问题来了,两者都叫网关,它们之间的区别是什么呢?我们能不能只用一个而不用另外一个呢?带着这个疑惑,我查阅了大量文章资料,最后我决定写一篇文章梳理一下两者的作用及区别,并且举了大量通俗易懂的例子来解释,相信你看完这篇文章也能知道项目中的请求处理是怎样的一个过程。
如果你想要一个可以系统学习的网站,那么我推荐的是牛客网,个人感觉用着还是不错的,页面很整洁,而且内容也很全面,语法练习,算法题练习,面试知识汇总等等都有,论坛也很活跃,传送门链接:牛客刷题神器
目录
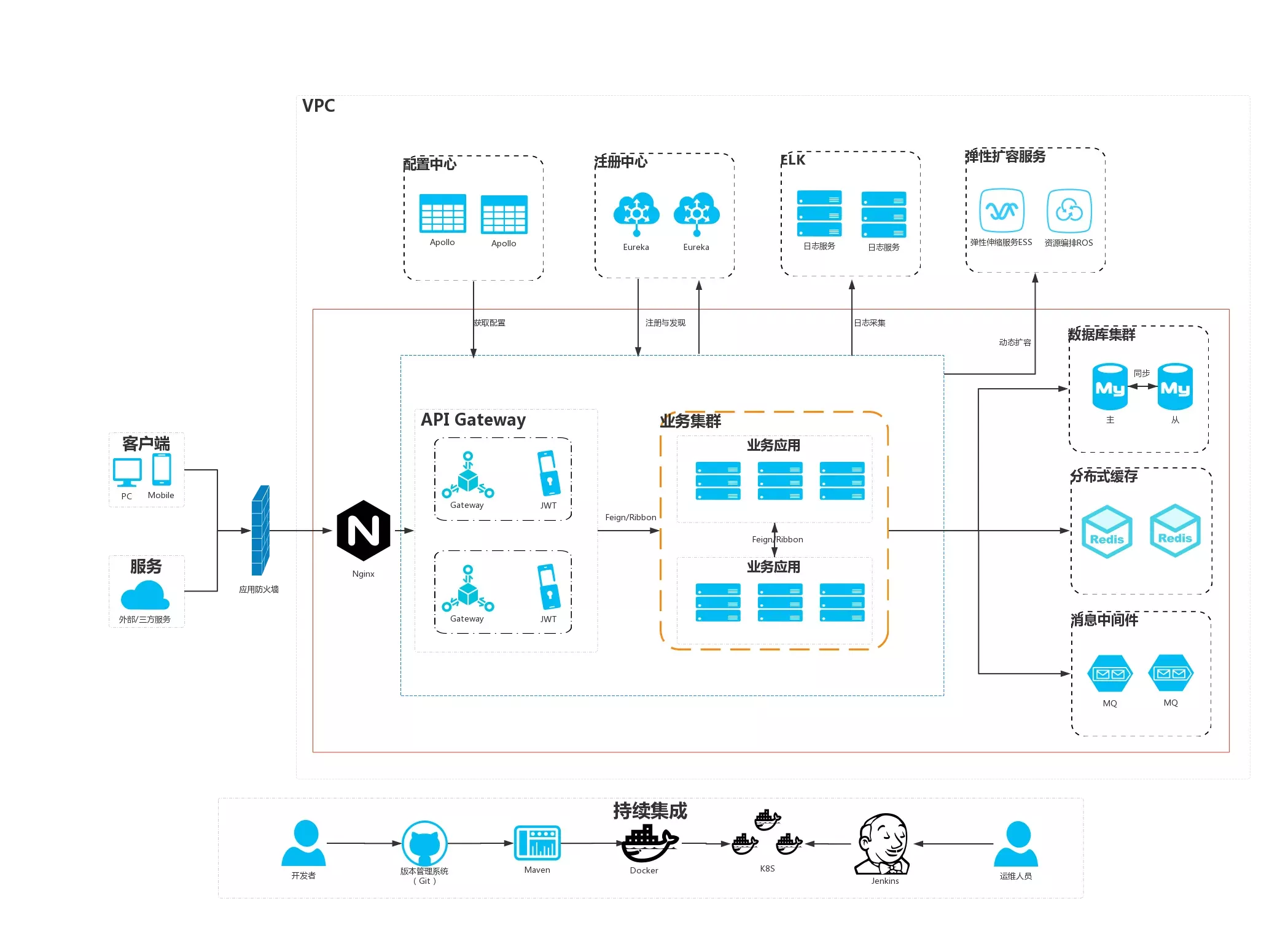
网关是系统的唯一对外的入口,介于客户端和服务器端之间的中间层,处理非业务功能,提供路由请求、鉴权、监控、缓存、限流等功能。无论你查看任何一个微服务项目架构,你都会发现在客户端和服务器端之间有一个网关,移动端的任何请求都必须经过网关才能到达服务端,见下图:
试想这样的情景,小崩同学要在一个网站上面购买东西,首先他输入了网址A访问了网站首页,然后小崩需要登录进行购买,但是这时候网站并不会自动跳转登录页面,因为这时候小崩需要访问的是登录微服务,需要另外输入新的网址B来进入登录界面。这时候小崩说,我只知道www.jd.com啊,我哪里知道京东的登录网址是什么。这时候小崩进行了一番搜索,终于获得了京东的登录界面网址,然后小崩成功登录了京东账号,点击结算,这时候需要访问的是订单微服务,而系统又提示小崩需要输入网址C进入订单微服务,这时候小崩实在蚌埠住了,一怒之下放弃了剁手,直接省下999。
假如没有网关,你就可能会遇到像小崩那样的情景,相信这样你也会绷不住的,因为每一个微服务都有自己的访问地址,我们完成一个业务需求可能需要调用多个微服务,没有网关的场景是这样的:
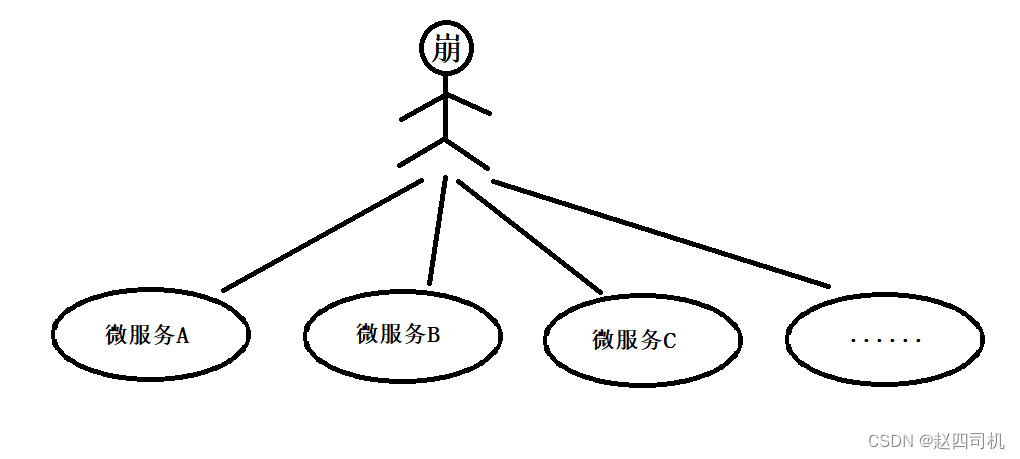
这样的结构存在如下问题:
这时候引入网关,场景发生了变化:

这时候我们有业务需求我们只需要直接访问网关即可,然后网关会根据实际请求再去访问不同的微服务,这样我们只需要与网关进行交互,只需要记住网关的地址,这样就解决了用户交互复杂问题;同时所有的认证请求都统一在网关进行认证,这时候就解决了认证困难问题;最后,我们还能通过网关对所有微服务进行监控,实时掌握各个微服务的运行状况,便于管理。
Nginx 是高性能的 HTTP 和反向代理的web服务器,处理高并发能力是十分强大的,能经受高负 载的考验,有报告表明能支持高达 50,000 个并发连接数。
其特点是占有内存少,并发能力强,事实上nginx的并发能力确实在同类型的网页服务器中表现较好,中国大陆使用nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
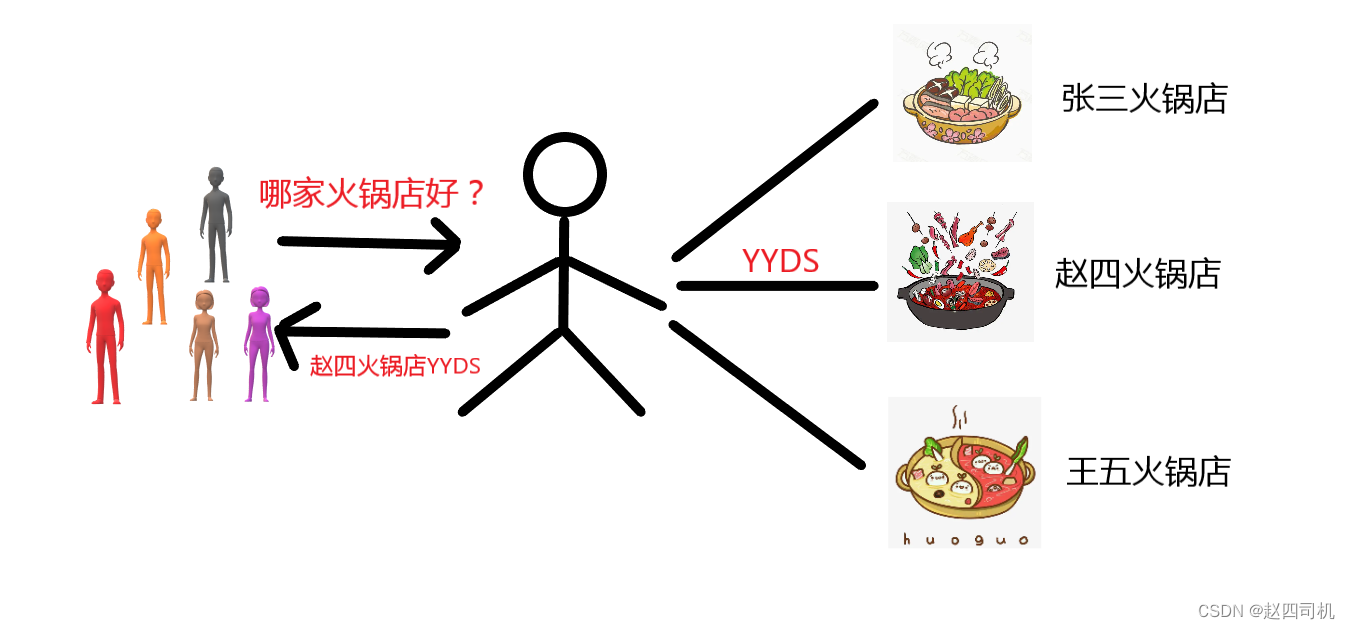
通过Nginx我们可以实现反向代理,这也是我在项目中使用到的一个功能,那么什么是反向代理呢?我们用户对代理是无感知的,因为我们不需要进行任何配置就可以进行访问。我们只需要将请求发送至反向代理服务器,由反向代理服务器帮我们决定需要访问哪个资源并且将资源返回给我们。此时反向代理服务器和目标服务器对外就是服务器,但是只对外暴露了代理服务器的地址,目标服务器的地址是隐藏的。
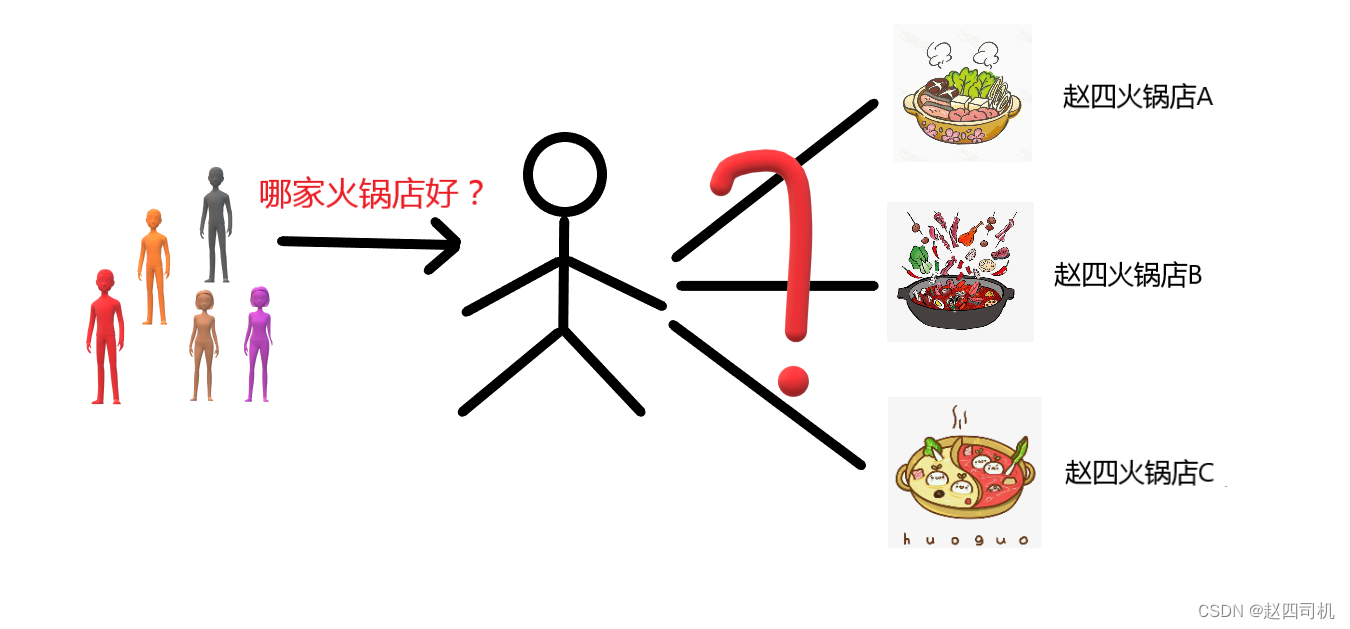
可能上面的文字你没理解,没关系,下面我举一个简单的例子加以说明。就比如你和你的一堆朋友刚到一个地方,你想知道附近有什么推荐的火锅店,这时候你并不知道附近有什么好的火锅店。你只认识当地的一个朋友,这时候你问他附近有什么火锅店推荐的,这时候你朋友就会告诉你“赵四火锅店YYDS”。这时候你朋友就充当了一个反向代理服务器,你一开始并不知道真实的火锅店名称,当然代理服务器返回资源给你后你也还是不知道你访问的是哪个目标,就好像你并不知道赵四火锅店的背景,你只知道你只是实现了吃火锅这一需求。
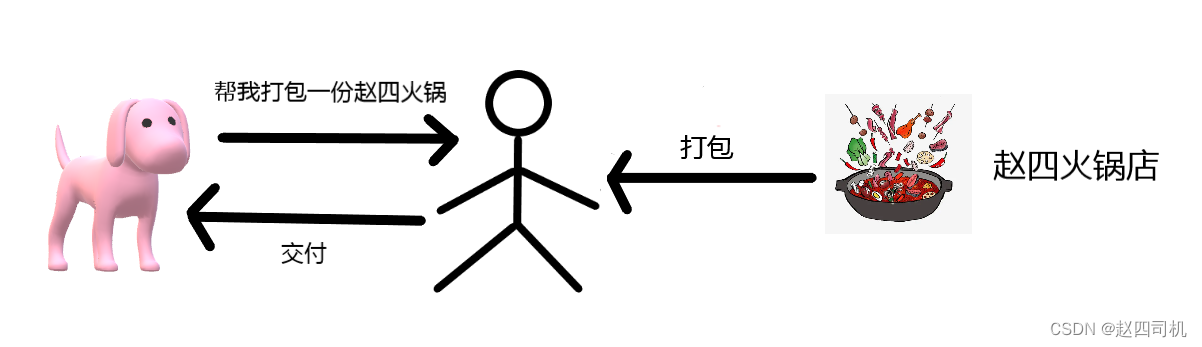
Nginx不仅可以实现反向代理,还能实现正向代理,那么什么是正向代理呢?前面说到反向代理我们是无感知的,我们并不知道我们需要访问的目标,我们只是知道代理的地址。而正向代理则不同,我们是很清楚我们需要访问的目标的,但是访问过程中出现了一个代理去帮我们完成这个请求并将结果返回。 此时服务器只知道请求来自哪个代理服务器,而不知道是哪个客户端发起的请求,正向代理模式屏蔽或者隐藏了真实客户端的信息。
可能上面的文字理解起来有点干涩,没关系,我还是举火锅的例子。这时候你的需求并不是问火锅店了,而是你想要打包赵四火锅店的火锅,这时候就出现了一个人去帮你打包并带回来,这时候赵四只知道是谁来买的,并不知道买的人是谁,隐藏了客户端的信息,这就是正向代理。
理解代理模式之后,我们了解到反向代理就是将用户请求分发给不同的服务器进行处理,那么分发规则是什么呢?我们能不能改变这个规则呢?这里提到的用户发送的请求量,反向代理服务器接收到的处理量就是负载量,而反向代理服务器需要根据一定的规则来将请求分发给不同的目标服务器,依据一定的规则将请求分发给不同的服务器进行处理的过程就是在进行负载均衡。Nginx提供了六种不同的负载均衡策略,分别为:
为了能更简单地理解这些知识,我们继续用赵四火锅的例子。这时候场景变成了很多人点了赵四的火锅外卖,这时候外卖小哥(更准确点应该是点餐系统)就是一个反向代理服务器,而赵四开了很多家火锅分店,这时候外卖小哥就需要根据不同的策略来选择去哪家分店取餐,这就是负载均衡策略,因为总不能全部订单都安排给一个分店做,这样资源利用率很低,而且客户的体验会很差。这时候有六种分发规则:
Spring Cloud Gateway是Spring官方基于Spring 5.0,Spring Boot 2.0和Project Reactor等技术开发的网关,Spring Cloud Gateway旨在为微服务架构提供一种简单而有效的统一的API路由管理方式。Spring Cloud Gateway作为Spring Cloud生态系中的网关,目标是替代Zuul,其不仅提供统一的路由方式,并且基于Filter链的方式提供了网关基本的功能,例如:安全,监控/埋点,和限流等。
Zuul网关属于netfix公司开源的产品,属于第一代微服务网关。
Gateway属于SpringCloud自研发的第二代微服务网关。
Zuul基于Servlet实现的,阻塞式的Api,不支持长连接。
Spring Cloud Gateway基于Spring5构建,能够实现响应式非阻塞式的Api,支持长连接,能够更好整合Spring体系的产品。
Spring Cloud Gateway可以看做是一个Zuul 1.x的升级版和替代品,比Zuul 2更早使用Netty实现异步IO,从而实现了一个简单、比Zuul 1.x更高效的、与Spring Cloud紧密配合的API网关。
Spring Cloud Gateway 里明确的区分了 Router 和 Filter,并且一个很大的特点是内置了非常多的开箱即用功能,并且都可以通过 SpringBoot 配置或者手工编码链式调用来使用。
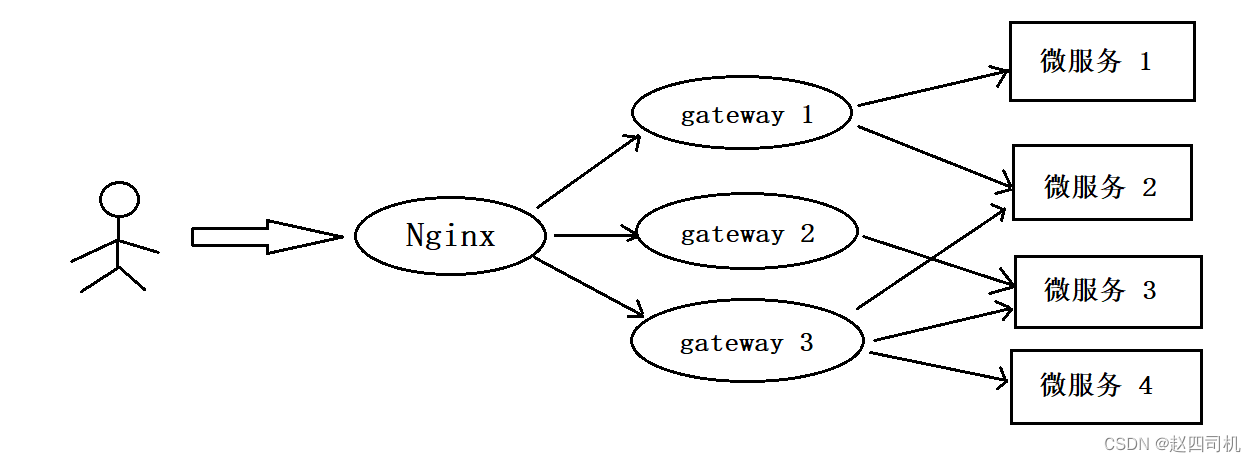
首先Nginx会抵御第一波的并发流量,是用户最前端的访问,可以把它当做第一层网关。可以看到项目中我都是通过Nginx来实现静态资源映射的,这时候输入的url是Nginx中配置的url。经过Nginx之后,Nginx通过反向代理再将请求转发到不同的网关系统,这是第二层网关,网关系统是根据不同的微服务来整合的,比如移动端网关,自媒体端网关,管理员端网关等。
前面我已经介绍过了怎么搭建网关,不熟悉的可以查看环境搭建那篇文章,这里我会讲解一下Spring Cloud GateWay 内置几种 Predicate 的使用。
在讲解之前我们先了解一下网关路由可以配置的内容有哪些:
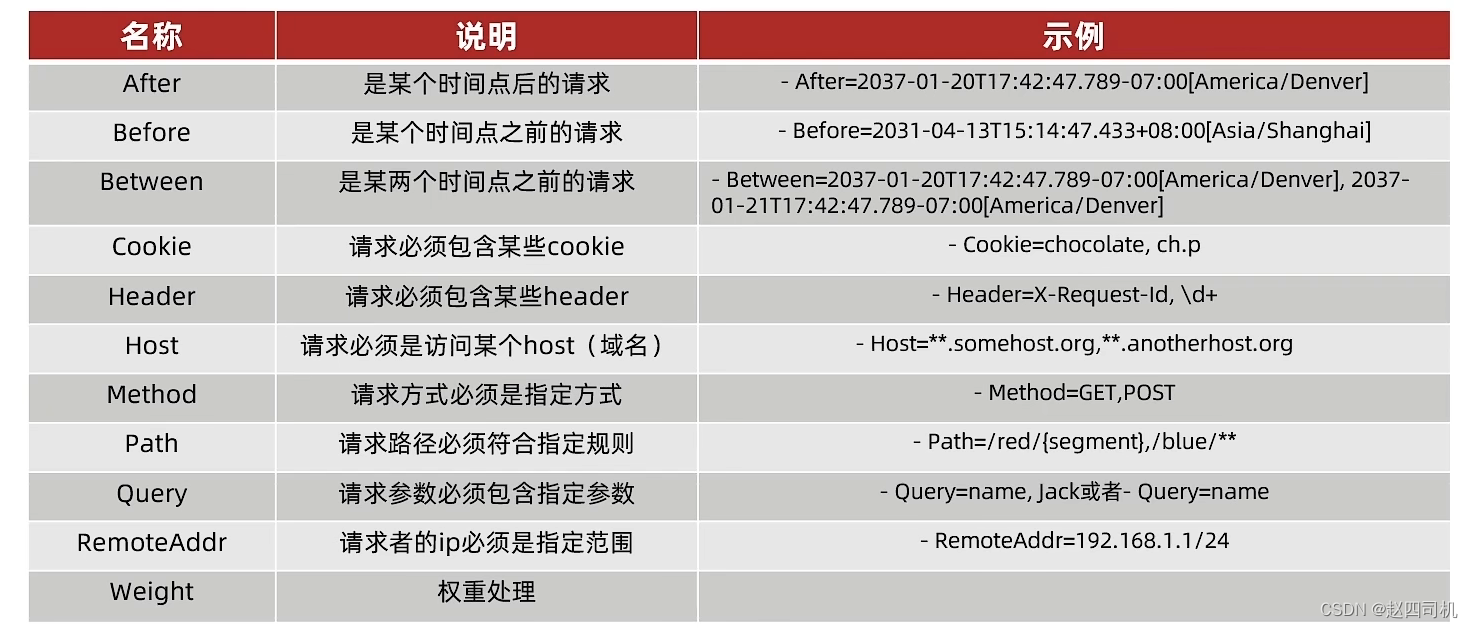
Spring提供了11种基本的Predicate工厂,见下表(图片来源于黑马教程):
所谓跨域,就是指域名不一致,而域名不一致有包括域名不同和域名相同但是端口不同,跨域问题是指浏览器禁止请求的发起者与服务端发生跨ajax请求,请求被浏览器拦截的问题,解决方案就是CORS,在网关中只需要做如下配置即可:
spring:
cloud:
gateway:
globalcors: #全局的跨域处理
add-to-simple-url-handler-mapping: true #解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedHeaders: "*" # 允许在请求头中携带的头信息
allowedOrigins: "*"
maxAge: 360000 # 这次跨域检测有效期
allowedMethods:
- GET
- POST
- DELETE
- PUT
- OPTION这里需要说明两点,一是解决options请求被拦截那项配置,我们的ajax是采用CORS的请求方案,CORS是浏览器去询问服务器你让不让这个请求跨域,这个询问是会被网关拦截的,而添加了这项配置表示不拦截这个询问。二是maxAge配置,假如没有这项配置,将来发送Ajax请求时候每次都要询问一次,这样服务器压力呈双倍增加,而添加这一项配置之后可以给跨域设置有效信息,有效期内可以让浏览器不发送跨域请求即可完成跨域,减轻了服务器压力。
至此关于Nginx和Gateway的介绍就完成了,下篇预告:自媒体前后端搭建&素材管理
友情链接: 牛客网 刷题|面试|找工作神器
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我是Ruby的新手。我试过查看在线文档,但没有找到任何有效的方法。我想在以下HTTP请求botget_response()和get()中包含一个用户代理。有人可以指出我正确的方向吗?#PreliminarycheckthatProggitisupcheck=Net::HTTP.get_response(URI.parse(proggit_url))ifcheck.code!="200"puts"ErrorcontactingProggit"returnend#Attempttogetthejsonresponse=Net::HTTP.get(URI.parse(proggit_url)
有人知道如何将capybarapoltergeist的用户代理覆盖到移动用户代理以进行测试吗?我发现了一些有关为seleniumwebdriver配置它的信息:http://blog.plataformatec.com.br/2011/03/configuring-user-agents-with-capybara-selenium-webdriver/这在capybara闹鬼中怎么可能? 最佳答案 请参阅poltergeistgithub页面上的链接:https://github.com/teampoltergeist/polte
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
我需要使用ActiveMerchant库在我们的一个Rails应用程序中设置支付解决方案。尽管这个问题非常主观,但人们对主要网关(BrainTree、Authorize.net等)的体验如何?它必须:处理定期付款。有能力记入个人帐户。能够取消付款。有办法存储用户的付款详细信息(例如Authotize.netsCIM)。干杯 最佳答案 ActiveMerchant很棒,但在过去一年左右的时间里,我在使用它时发现了一些问题。首先,虽然某些网关可能会得到“支持”——但并非所有功能都包含在内。查看功能矩阵以确保完全支持您选择的网关-http
我希望访问我机器上的所有HTTP流量(我的Windows机器-不是服务器)。据我了解,拥有一个本地代理是所有流量路线的必经之路。我一直在谷歌搜索但未能找到任何资源(关于Ruby)来帮助我。非常感谢任何提示或链接。 最佳答案 WEBrick中有一个HTTP代理(Rubystdlib的一部分)和here's一个实现示例。如果你喜欢生活在边缘,还有em-proxy伊利亚·格里戈里克。这postIlya暗示它似乎确实需要一些调整来解决您的问题。 关于ruby-如何捕获所有HTTP流量(本地代理)
我正在使用Net::FTPruby库连接到FTP服务器并下载文件。一切正常,但现在我需要使用出站代理,因为他们的防火墙将IP地址列入白名单,并且我正在使用Heroku来托管该站点。我正在试用新的Proximo附加组件,它看起来很有前途,但我无法让Net::FTP使用它。我在Net::FTPdocs中看到以下内容:connect(host,port=FTP_PORT)EstablishesanFTPconnectiontohost,optionallyoverridingthedefaultport.IftheenvironmentvariableSOCKS_SERVERisset,
我想使用nokogiri和mechanize自动化一个计时网络客户端。我需要通过代理服务器连接,但问题是,我不知道所述代理服务器的用户名和密码。我想获取存储在计算机上的此代理的缓存凭据..例如,在c#中你可以使用:stringproxyUri=proxy.GetProxy(requests.RequestUri).ToString();requests.UseDefaultCredentials=true;requests.Proxy=newWebProxy(proxyUri,false);requests.Proxy.Credentials=System.Net.Credential