前期回顾:
目录
前面我们介绍了mysql表的基本查询,这里我们将会在基本查询的基础上进行一些扩展。
代码演示如下:
-- 查找1992.1.1 后入职的员工
-- 这里的hiredate时日期类型,日期类型可以直接比较,但要注意格式
SELECT * FROM emp
WHERE hiredate >'1992-01-01';
-- 查找首字母为S的员工的姓名与工资
-- 在近似查询中 % 代表0到多个字符
SELECT ename,sal FROM emp
WHERE ename LIKE 'S%';
-- 查找第三个字符为大写O的员工的姓名与工资
-- 在近似查询中 _ 表示一个字符
SELECT ename,sal FROM emp
WHERE ename LIKE '__O%'; -- 此处有两个 _
-- 显示没有上级雇员的情况
-- 没有上级即:该记录的mgr为NULL
SELECT * FROM emp
WHERE mgr IS NULL; -- 不可用 = NULL
-- 查询表结构
DESC emp;
-- 按照工资从低到高排序
SELECT * FROM emp
ORDER BY sal;-- 默认升序 ASC
-- 按照部门升序,工资降序排序
-- 多重排序,按照要求一次排序
SELECT * FROM emp
ORDER BY deptno ASC ,sal DESC ;
-- 显示每种岗位的雇员总数,平均工资
SELECT COUNT(*),FORMAT(AVG(sal),2),job
FROM emp
GROUP BY job;
-- 显示雇员总数,以及获得补助的雇员数
-- 未获得补助的员工 comm 值为NULL
-- 在使用 COUNT(列) 时正好不计算在内
SELECT COUNT(*),COUNT(comm)
FROM emp;
-- 统计没有获得补助的雇员数
-- 若为真,则1 ,进而count统计时会统计上
SELECT COUNT(IF(comm IS NULL,1,NULL)) FROM emp;
SELECT COUNT(*)-COUNT(comm) FROM emp;
-- 显示管理员的总人数
SELECT COUNT(job) FROM emp
WHERE job='MANAGER';
-- 统计各部门平均工资,且大于1000,
-- 并降序排列 前两条记录
SELECT FORMAT(AVG(sal),2) AS avg_sal ,deptno
FROM emp -- 从emp表中查询
GROUP BY deptno -- 按照部门分组
ORDER BY avg_sal DESC -- 降序排列
LIMIT 0,2; -- 分页查询前两条记录
-- 总结:如果select语句同时包含 group by,
-- having,limit,order by, 一般按照以下顺序
SELECT column1,column2 FROM `table`
GROUP BY `column`
HAVING `condition`
ORDER BY `column`
LIMIT `start`,`rows`;
除此之外,我们再介绍一下分页查询当我们的数据记录非常多时,我们可能需要分页查询。
分页查询基本语法:
SELECT .....FROM ......
LIMIT start ,rows;
代码演示如下:
-- 按照雇员id排序 每页显示三条记录
SELECT * FROM emp
ORDER BY empno
LIMIT 0,3; -- 从第0+1行开始,得到三条记录
-- 按照雇员id排序 每行显示5条记录
SELECT * FROM emp
ORDER BY empno
LIMIT 3,5; -- 从第3+1行开始,得到五条记录多表查询是基于两个或者两个以上的表的查询,在实际应用中,查询单个表可能不能满足你的需求,因此这里我们就引出了多表查询。
当我们同时查询多个表时,不同的表之间会形成笛卡尔集。我们需要在笛卡尔集的基础上加上筛选条件来满足我们的要求。
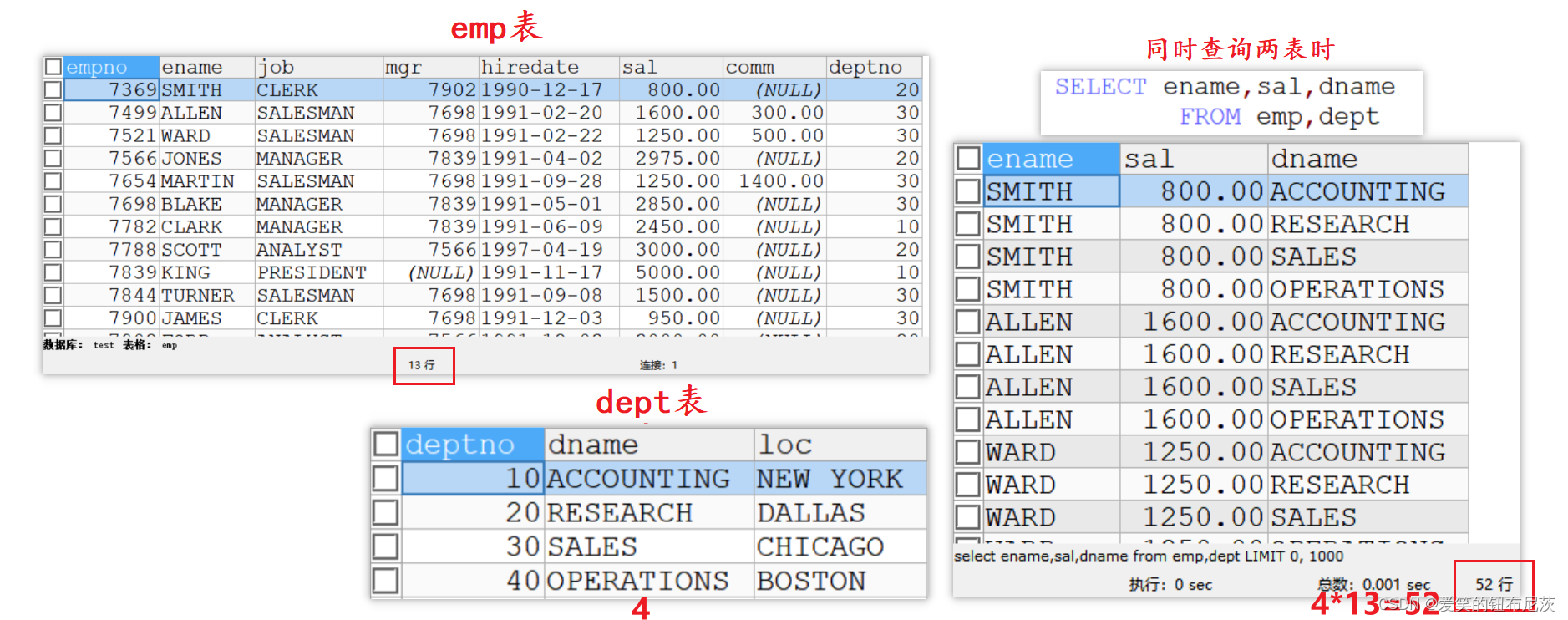
代码演示如下:
-- 多表查询
-- 笛卡尔集
-- 显示雇员名,雇员工资及所在部门的名字
SELECT ename,sal,dname
FROM emp,dept
WHERE emp.deptno=dept.deptno; -- 当满足此条件时,才是我们要的结果
-- 提示:多表查询的条件不能少于表数-1 否则会出现笛卡尔集
-- 显示部门号为10的部门名,员工名,工资
SELECT dname,ename,sal
FROM emp,dept
WHERE emp.deptno=dept.deptno&&emp.deptno=10;
-- 显示各个员工的姓名,工资,以及工资级别
SELECT ename,sal,grade
FROM emp,salgrade
WHERE sal BETWEEN salgrade.losal AND salgrade.hisal;
-- 自连接:在同一张表的连接查询
-- 显示公司员工和他的上级的名字
SELECT emp1.ename AS worker ,emp.ename AS `super`
FROM emp AS emp1,emp -- 由于列名不准确,我们要用AS指定列
WHERE emp1.mgr = emp.empno;子查询是指嵌入在其他SQL语句中的SELECT语句,也叫嵌套查询。按查询结果分为单行子查询,多行子查询,多列子查询。
多行子查询代码演示:
-- 多行子查询
-- 1.0如何显示与SMITH同一个部门的所有员工
-- 1.1 先找到SMITH所在部门
SELECT deptno FROM emp
WHERE ename ='SMITH';
-- 1.2 再找那个部门的员工
SELECT * FROM emp
WHERE deptno = (
SELECT deptno FROM emp
WHERE ename ='SMITH')
-- 2.0查询和部门10的工作相同的雇员的信息,
-- 但不包括部门10自己的雇员
-- 2.1 先找部门10有哪些工作
SELECT DISTINCT job FROM emp -- 由于可能多个员工的从事同一个工作,因此要去重。
WHERE deptno = 10;
-- 2.2 再找从事这些工作的所有雇员
SELECT * FROM emp
WHERE job IN( -- 因为部门10可能不止一种工作
SELECT DISTINCT job FROM emp
WHERE deptno = 10);
-- 2.3 在筛选掉部门号为10的雇员
SELECT * FROM emp
WHERE job IN(
SELECT DISTINCT job FROM emp
WHERE deptno = 10)AND deptno!=10;
子查询当作临时表使用代码演示:
-- 子查询当作临时表使用
-- 显示工资比部门30的所有员工的工资高的员工的姓名、工资、部门号
-- 用MAX
SELECT * FROM emp
WHERE sal>(SELECT MAX(sal) FROM emp WHERE deptno = 30);
-- ALL
SELECT * FROM emp
WHERE sal>ALL(SELECT sal FROM emp WHERE deptno = 30);
-- 显示至少比部门30其中一个高的员工
-- ANY
SELECT * FROM emp
WHERE sal>ANY(SELECT sal FROM emp WHERE deptno = 30);
-- 用MIN
SELECT * FROM emp
WHERE sal>(SELECT MIN(sal) FROM emp WHERE deptno = 30);
-- 将子查询当作临时表使用
SELECT cat_id,MAX(shop_price)
FROM ecs_goods
GROUP BY cat_id;
SELECT goods_id,ecs_goods.cat_id,goods_name,shop_price
FROM ( -- 将子查询结果看成一个临时表再进行相关操作
SELECT cat_id,MAX(shop_price) AS max_price
FROM ecs_goods
GROUP BY cat_id
)temp,ecs_goods
WHERE temp.cat_id = ecs_goods.cat_id
AND temp.max_price=ecs_goods.shop_price;
多列子查询代码演示:
-- 多列子查询
-- 查询与ALLEN同部门,同工作的人,不包括其本人
-- 1.1先找到ALLEN的部门和工作
SELECT deptno,job FROM emp
WHERE ename ='ALLEN';
-- 1.2
SELECT * FROM emp
WHERE(deptno,job) =(
SELECT deptno,job
FROM emp
WHERE ename ='ALLEN'
)AND ename!='ALLEN';
-- 查询与阳阳同学成绩完全一样的同学
SELECT * FROM student
WHERE(chinese,math,english)=(
SELECT chinese,math,english
FROM student
WHERE `name`='阳阳同学'
)AND `name`!='阳阳同学';
-- from子句中使用子查询
-- 查找部门工资高于本部门平均工资的雇员资料
-- 各部门平均工资
SELECT AVG(sal),deptno
FROM emp
GROUP BY deptno;
SELECT ename,sal,avg_sal,emp.deptno
FROM emp,(
SELECT FORMAT(AVG(sal),2) AS avg_sal,deptno
FROM emp
GROUP BY deptno
)temp
WHERE emp.deptno=temp.deptno
AND emp.sal>avg_sal;
-- 查找每个部门工资最高的人的资料
-- 各部门最高工资
SELECT MAX(sal) AS max_sal,deptno
FROM emp
GROUP BY deptno;
SELECT ename,sal,max_sal,emp.deptno
FROM emp,(
SELECT MAX(sal) AS max_sal,deptno
FROM emp
GROUP BY deptno
)temp
WHERE emp.deptno=temp.deptno
AND emp.sal=temp.max_sal
ORDER BY sal;有时再实际应用中,为了合并多个 SELECT 语句的结果,可以使用集合操作符号UNION, UNION ALL. 它们都是用于取得两个结果集的并集。
但 UNION ALL 不会对结果去重,UNION 会自动对结果去重。
代码演示如下:
-- 合并查询
CREATE TABLE test3(
id INT,
`name` VARCHAR(23),
age INT);
INSERT INTO test3
VALUES(1,'阳阳',19),(2,'小赵',19),(3,'山鱼',20),(4,'浩浩',19);
CREATE TABLE test4(
id INT,
`name` VARCHAR(23),
age INT);
INSERT INTO test4
VALUES(1,'杨枝',19),(2,'小驴',19),(3,'小乐',20),(4,'浩浩',19);
SELECT * FROM test3
UNION ALL -- 直接合并不去重
SELECT * FROM test4;
SELECT * FROM test3
UNION ALL -- 去重合并
SELECT * FROM test4;
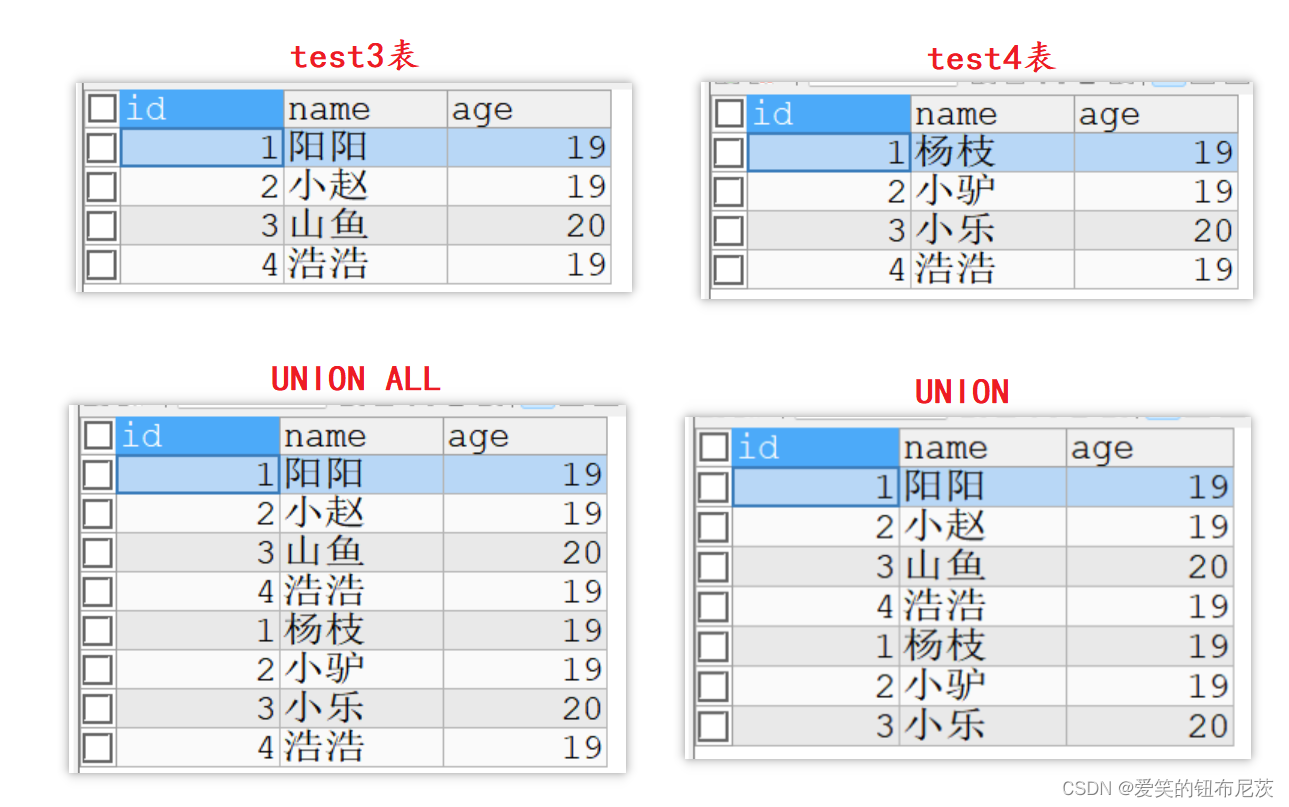
-- 表复制
-- 自我复制
CREATE TABLE test(
id INT,
`name` VARCHAR(23),
age INT);
INSERT INTO test
VALUES(1,'阳阳',19),(2,'小赵',19),(3,'山鱼',20),(4,'浩浩',19);
-- 把查询到的本表内容加入到本表完成自我复制
INSERT INTO test
SELECT * FROM test;
DELETE FROM test
-- 去除表中重复记录
-- 1.创建一个新表
CREATE TABLE test2(
id INT,
`name` VARCHAR(23),
age INT);
-- 2.把旧表的数据复制到新表上
INSERT INTO test2(id,`name`,age)
SELECT DISTINCT id,`name`,age FROM test; -- 此处在查找时去重
-- 3.删除旧表
DROP TABLE test;
-- 4.新表改名
RENAME TABLE test2 TO test;前面我们学习的查询,是利用where子句对两张或多张表,形成的笛卡尔集进行筛选,根据关联条件,显示所有匹配的记录,匹配不上的不显示。
不过这样就会造成一个问题,比如当要求:列出部门名称(dept表)和这些部门的员工名称和工作(emp表),同时要求显示那些没有员工的部门。由于我们是在多表形成的笛卡尔集中匹配关联条件进行筛选,因此我们无法显示出没有员工的部门,也无法显示出没有部门的员工。
由此我们引出了外连接。
如果左侧的表完全显示我们就说是左外连接。
用法:SELECT ... FROM 表1 LEFT JOIN 表2 ON 条件
代码演示如下:
-- 创建测试表
CREATE TABLE stu(
id INT,
`name` VARCHAR(23));
INSERT INTO stu
VALUES(1,'Newbniz'),(2,'Mike'),(3,'john');
CREATE TABLE grade2(
id INT,
score DOUBLE);
INSERT INTO grade2
VALUES(1,59.9),(2,33);
-- 左外连接
-- 一般情况下
SELECT * FROM stu,grade2
WHERE stu.id=grade2.id;
-- 使用左外连接
SELECT *
FROM stu LEFT JOIN grade2
ON stu.id = grade2.id;
SELECT * FROM stu;
SELECT * FROM grade2;
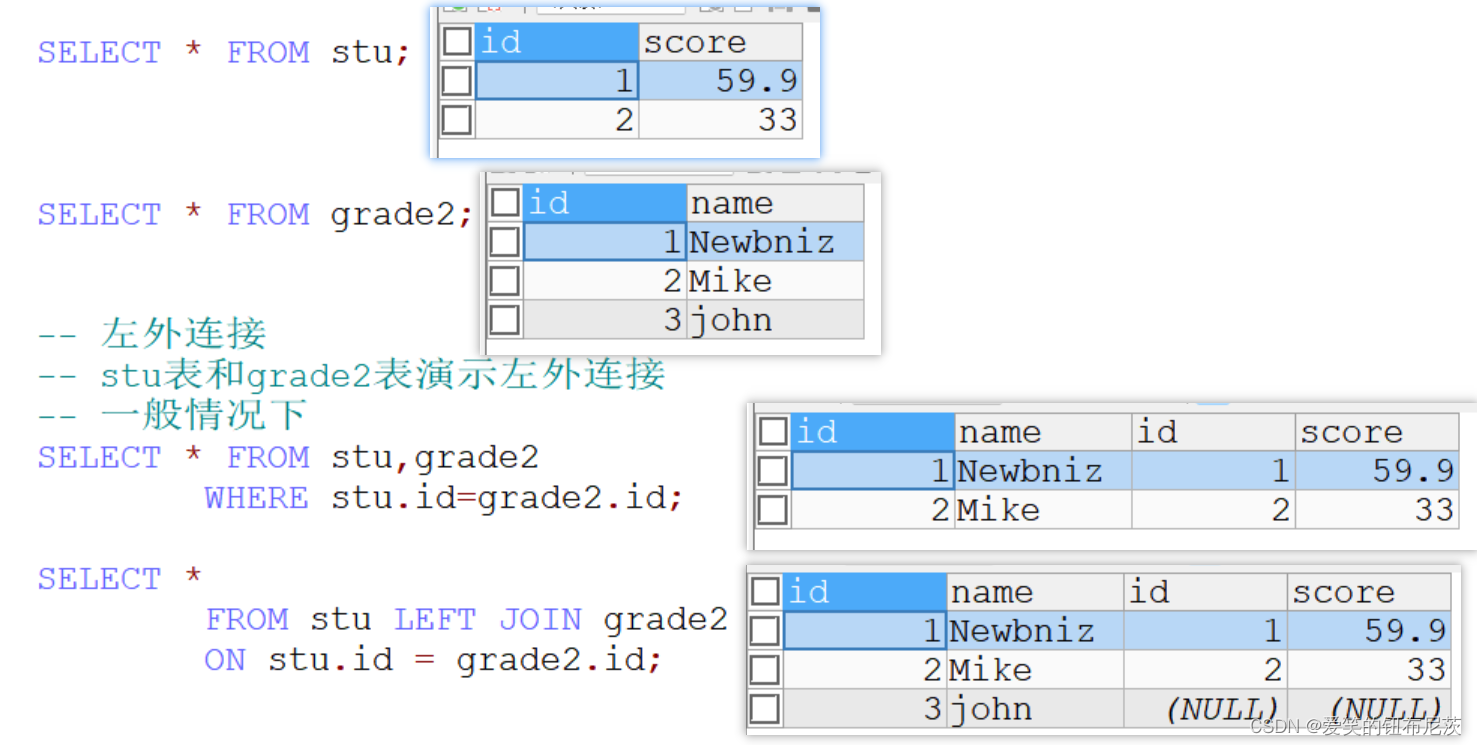
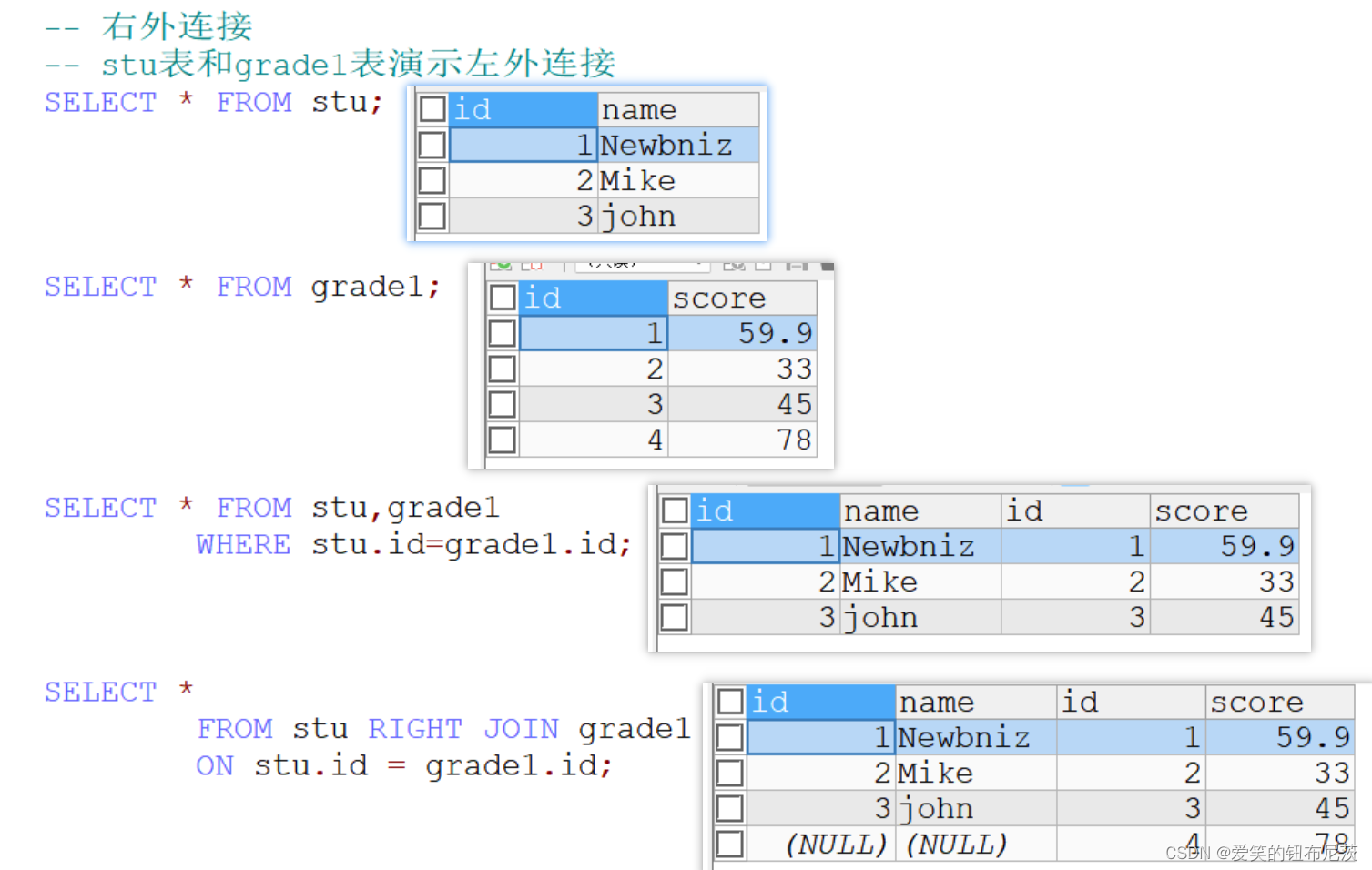
如果右侧的表完全显示我们就说是右外连接。
用法:SELECT ... FROM 表1 RIGHT JOIN 表2 ON 条件
代码演示如下:
-- 创建测试表
CREATE TABLE stu(
id INT,
`name` VARCHAR(23));
INSERT INTO stu
VALUES(1,'Newbniz'),(2,'Mike'),(3,'john');
CREATE TABLE grade1(
id INT,
score DOUBLE);
INSERT INTO grade1
VALUES(1,59.9),(2,33),(3,45),(4,78);
-- 右外连接
-- stu表和grade1表演示左外连接
SELECT * FROM stu;
SELECT * FROM grade1;
-- 一般情况下
SELECT * FROM stu,grade1
WHERE stu.id=grade1.id;
-- 使用右外连接
SELECT *
FROM stu RIGHT JOIN grade1
ON stu.id = grade1.id;
✨ 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富!
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时