大家好我是沐曦希💕
文章目录
我们在学习C/C++的动态内存空间,习惯把地址空间划分为几个区域:
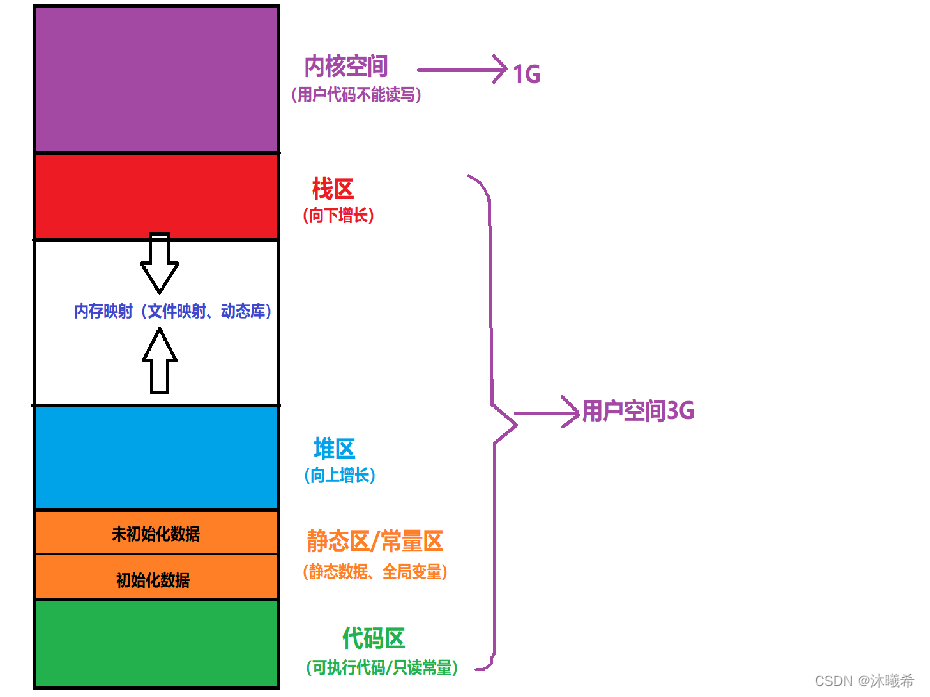
但是这并不是真的的地址空间:
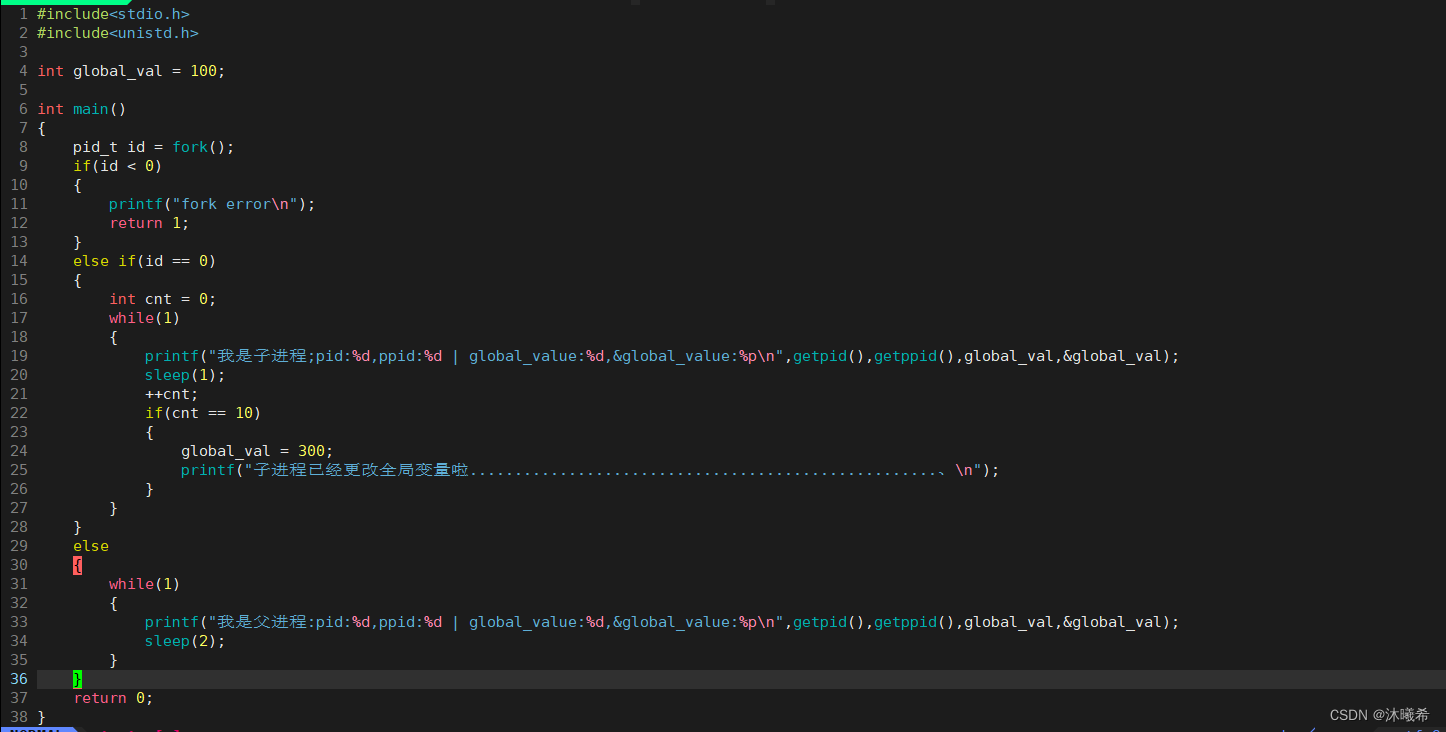
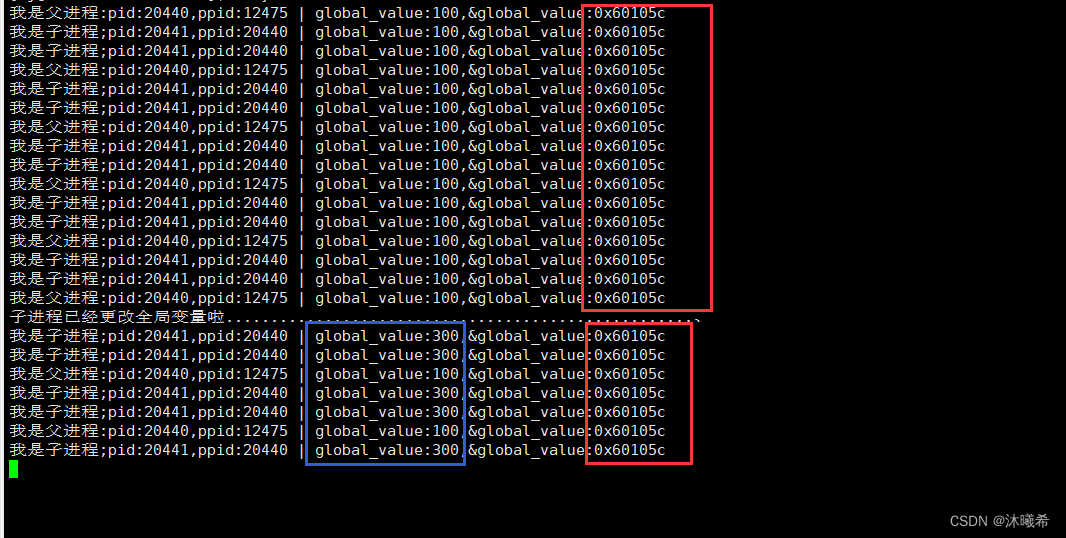
我们发现子进程把全局变global_value修改之后,子进程和父进程的值是不同的,这是合理的,因为进程之间具有独立性。但是这里global_value的地址居然是相同的!多进程在读取同一个地址的时候怎么可能出现不同的结果呢???地址相同说明这里的地址绝对不是对应物理地址,也就是说曾经我们学习的语言基本的地址(指针),不是对应的物理地址!!!
这里的地址是虚拟地址(线性地址),也可以成为逻辑地址。
能打印出来的地址空间排布,全部都是虚拟地址。物理地址,用户一概看不到,由OS统一管理;OS必须负责将 虚拟地址 转化成 物理地址 。
进程会认为自己是独占系统资源的,事实上并不是。
实际上操作系统会给每一个进程都创建一个独立的虚拟地址空间,然后通过页表将虚拟地址空间与物理内存一一对应 (映射),我们用户只能得到虚拟地址空间中的虚拟地址,当我们修改虚拟地址中的数据时,操作系统会先通过页表找到对应的物理内存,然后修改物理内存中的数据。
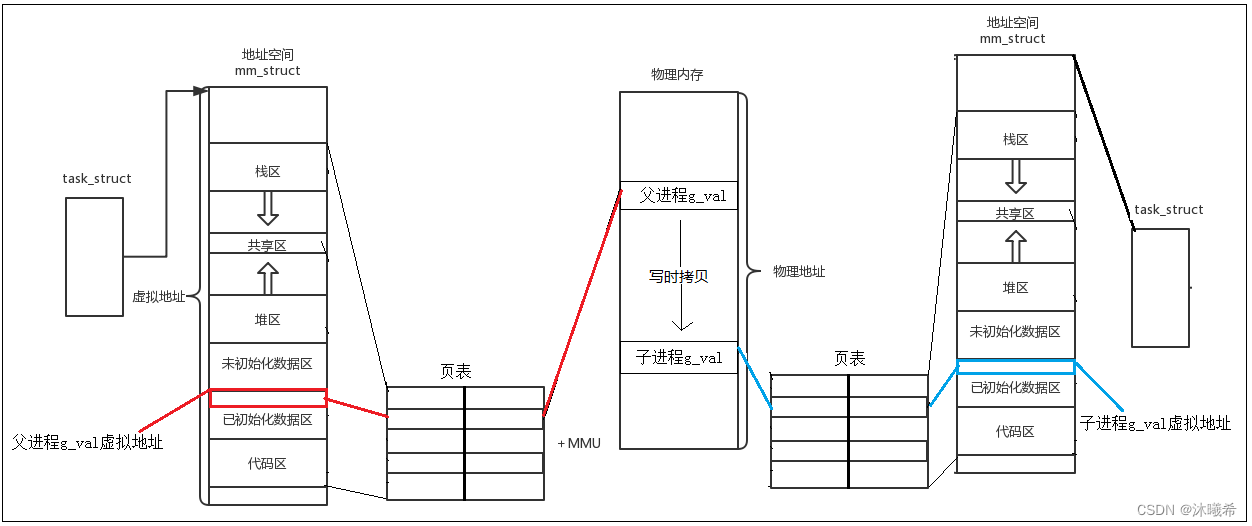
这就很好理解了:
父进程和子进程都有自己的独立的进程地址空间,且都有自己的页表结构,子进程由父进程创建,所以子进程的地址空间是从父进程拷贝而来,刚开始的g_val经过映射指向同一个物理内存,所以刚开始看到的都是100。
后来子进程修改了自己地址空间的g_val的值,当操作系统通过页表映射发现g_val的值是共享的,但是我们知道进程具有独立性,所以操作系统为了保证进程的独立性,当子进程或者父进程任何一方尝试对共享数据进行写入,那么操作系统会在物理内存上重新开辟一块新的内存空间,拷贝数据,然后在修改映射关系,不再指向老的变量,在整个修改的过程中,和父子进程的虚拟地址没有任何关系,只是底层经过页表映射到不同的区域,所以我们看到了地址是一样的,但是内容却是不一样的,这就是现象的由来!
写时拷贝:指父子进程在上述情况下任何一方尝试写入,操作系统先进行数据拷贝,更改页表映射,然后再让进程进行修改的过程称为写时拷贝。
进程地址空间上的地址从全0到全1按照正常的方式排列,所以是连续的地址,所以这个地址空间也被称为线性地址;对于磁盘程序内部的地址称为逻辑地址,在Linux下,虚拟地址到线性地址、逻辑地址是一样的,但在其他地方,区分比较明确。
OS会为系统中的每一个进程都创建一个地址空间,但是OS中同时存在很多个许多进程,那么就需要创建很多给地址空间,所以为了保证各个进程正常运行,OS 需要对每个进程的地址空间进行管理。
而管理的本质是先描述,在组织,所以和管理进程一样,操作系统会使用一种内核数据结构来对地址空间进行管理,Linux中用于 管理地址空间的内核数据结构叫做 mm_struct,操作系统会为每个进程创建一个 mm_struct 对象,然后通过管理结构体对象来间接管理进程地址空间。
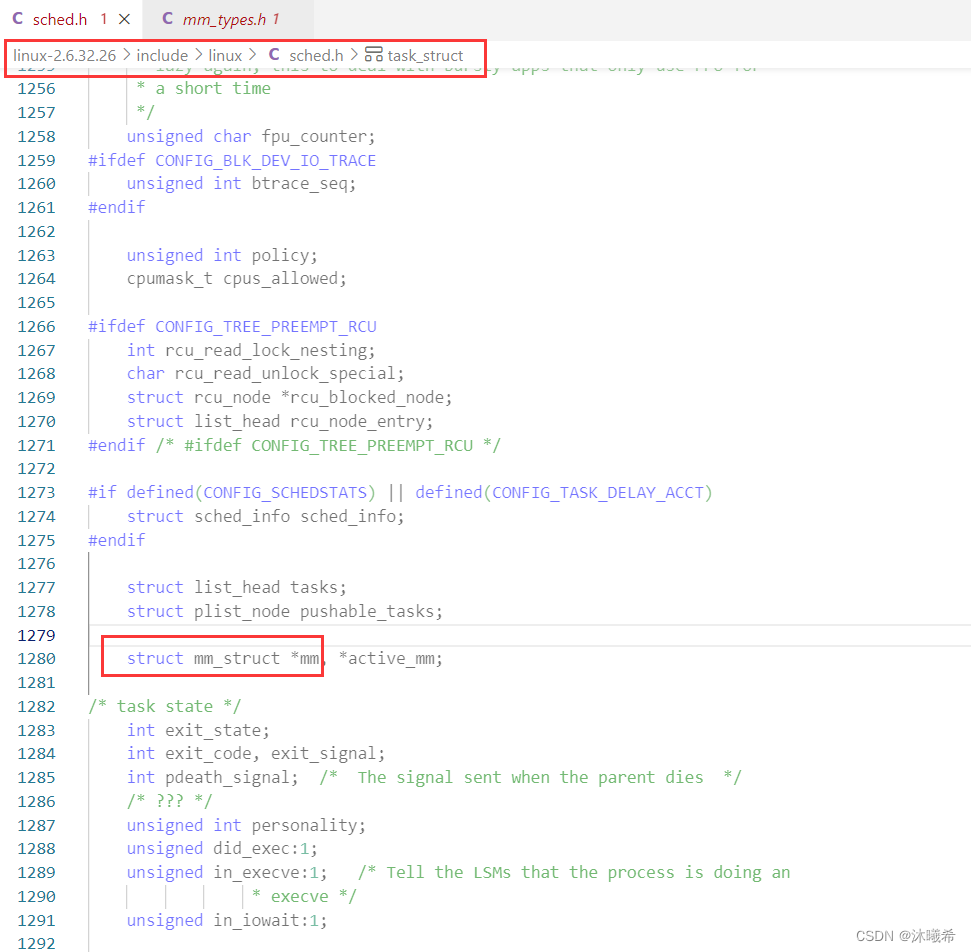
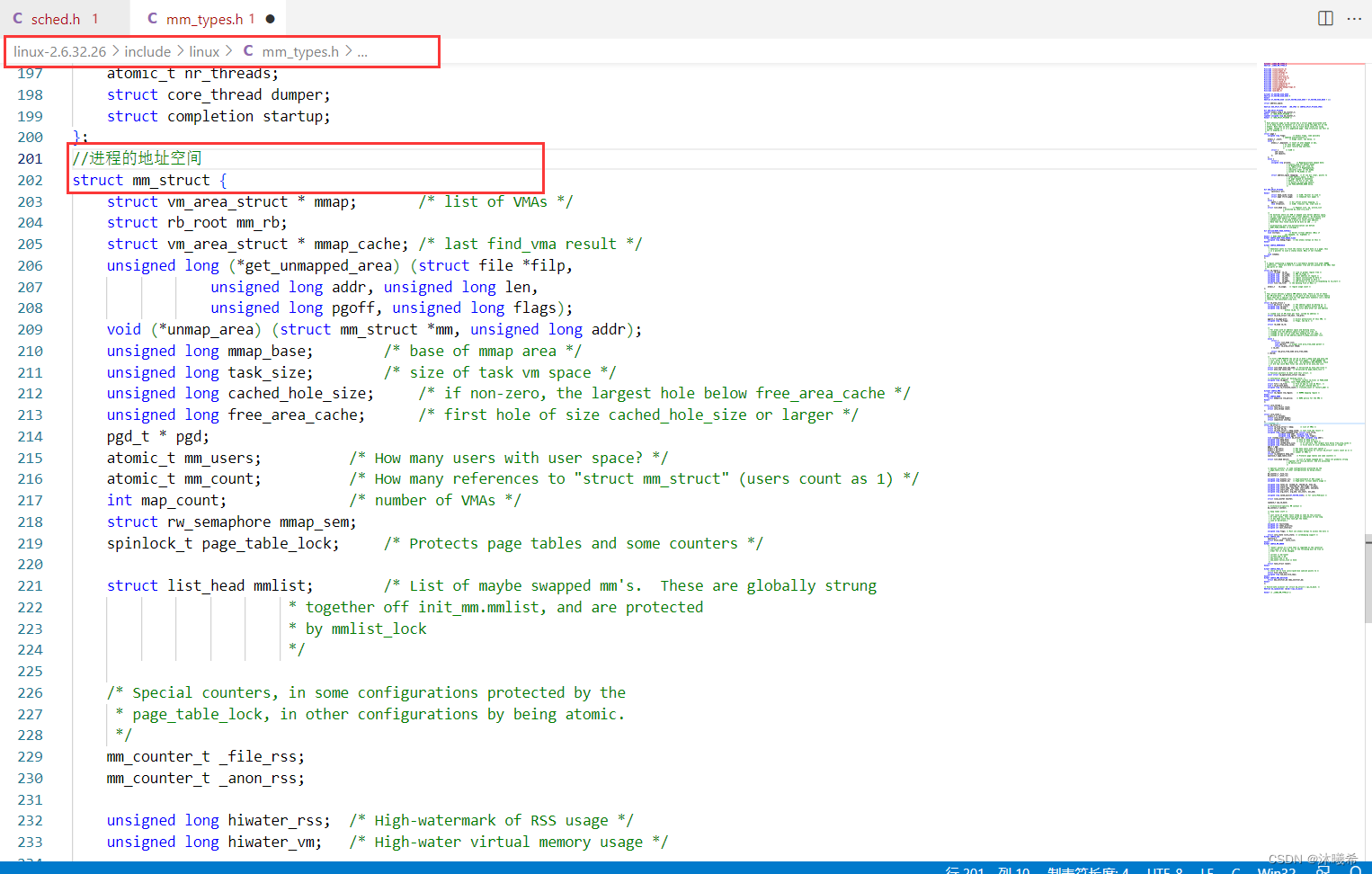
所以进程地址空间也是进程的属性,我们可以通过进程的 task_struct 来找到/管理进程对应的地址空间。
进程地址空间被划分为很多个区域,例如栈区、堆区、数据区、代码段。那进程地址空间是如何进行区域划分和区域调整的:把一个区域的end和start进行调整和维护内存区域
struct mm_struct{
//uint32_t:32位系统下的无符号整型
uint32_t code_start,code_end;
uint32_t data_start,data_end;
uint32_t heap_start,heap_end;
uint32_t stack_start,stack_end;
}
所谓的区域调整,本质就是修改各个区域的end或start.
每个进程都有进程地址空间,所有的进程都要通过页表映射到物理内存,如果进程直接访问物理内存,万一进程越界非法访问、非法读写时,页表就可以进行拦截,而且直接访问物理内存对于账号信息是非常不安全的,所以保证了内存数据的安全性。
对于进程而言,都有独立的地址空间及页表,通过页表映射到不同的物理内存上,所以一个进程数据的改变不会影响到另一个进程,保证了进程的独立性,而对于上面我们所说的父进程和子进程而言,子进程的地址空间从父进程拷贝,页表都指向同一块物理内存,但是即使此时的数据是共享的,在修改数据的时候也会发生我们所说的写时拷贝,保证了进程的独立性。
可执行程序被编译器编译的时候每个代码和数据在内存中已经有虚拟地址了(在磁盘上称为逻辑地址),也就是说,地址空间对于操作系统和编译器都是遵守的。所以当程序被加载到内存成为进程后,每个变量/函数都具备了物理地址。
所以我们现在有两套地址:
1.标识物理内存中代码和数据的地址
2.在程序内部互相跳转的时候的虚拟地址加载完成之后,代码的各个区域的地址已经知道。进程被调度时,CPU拿到虚拟地址,经过地址空间查页表通过映射,进行访问查到物理地址往后执行。也就是CPU通过了虚拟地址——页表映射——物理地址执行。也就是在整个CPU运行过程中,CPU并没有见到物理地址,用的都是虚拟地址。
每个进程都有自己独立的内核数据结构和其对应的代码已经数据。
进程=内核数据结构+进程对应的代码和数据
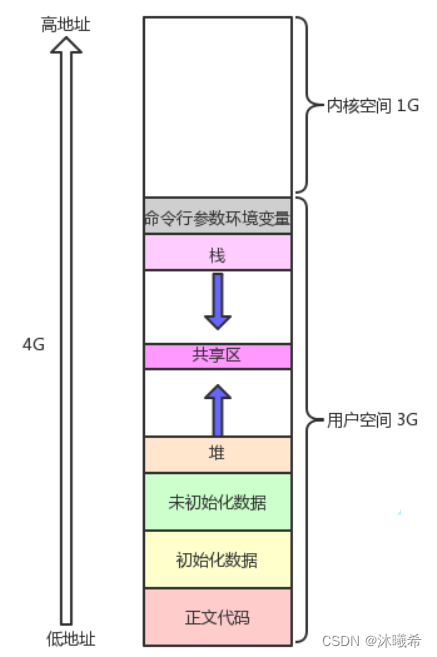
其中我们熟悉的全局数据区,代码段,栈区,堆区以及共享区,再加上一个命令行参数环境变量所占用的进程地址空间统称用户空间,在32位操作系统下,这部分空间占总空间的3/4,即3G;剩下的1G属于内核空间。
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
我想验证一个电子邮件地址是否是PayPal用户。是否有API调用来执行此操作?是否有执行此操作的ruby库?谢谢 最佳答案 GetVerifiedStatus来自PayPal'sAdaptiveAccounts平台会为您做这件事。PayPal没有任何codesamples或SDKs用于Ruby中的自适应帐户,但我确实找到了编写codeforGetVerifiedStatusinRuby的人.您需要更改该代码以检查他们拥有的帐户类型的唯一更改是更改if@xml['accountStatus']!=nilaccount_status