疫情,不少孩子封控在家,需要上网课,但是老是抑制不住地去打游戏或看视频。
朋友圈里面,某位技术大牛这么描述疫情封控期间,他与孩子的居家“战争”:
孩子上网课已经一个多月了,孩子因为爱玩游戏爱看B站,与我斗智斗勇好几回,目前战斗情况如下:
上课时间玩手机游戏 ~ 没收手机
在电脑上装手机模拟器 继续玩手机游戏 ~ 卸载模拟器
在电脑上看B站 ~ 设置host文件屏蔽B站域名
在电脑上看芒果TV ~ 继续设置屏蔽域名
继续安装手机模拟器、找到host文件删除屏蔽,看B站玩游戏 ~ 被打,被卸载各种软件,被警告再发现就换Linux操作系统
解封后,先买个企业级路由器管控起来… 或者再装个摄像头再加上AI人体姿态识别?😭
因本文是技术文章,在这里咱暂先不讨论教育之道,先提供一个技术方案,解决家长的燃眉之急,不用企业级路由器,也不用AI人体姿态识别。
我的方案是:packetbeat+kafka+ES套件,以大数据可视化方式监控孩子。
这个方案的特点:
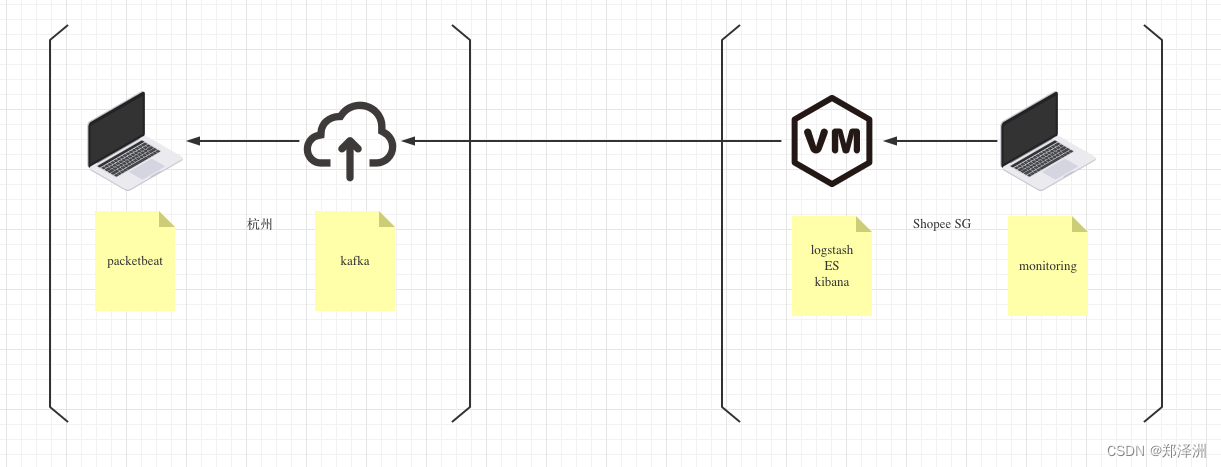
架构设计上有个难点,我的方案中考虑了异地监控的情况,比如孩子在杭州上课,我在新加坡工作,考虑跨国网络的不稳定性,我在常规的packetbeat和ES集群之间,加了一个准备放在阿里云上的kafka消息队列,这样就不用穿透内网,也不怕网络不稳丢消息了,远在新加坡Shopee云的监控主机可以用异步方式读取kafka。
监控实图1:
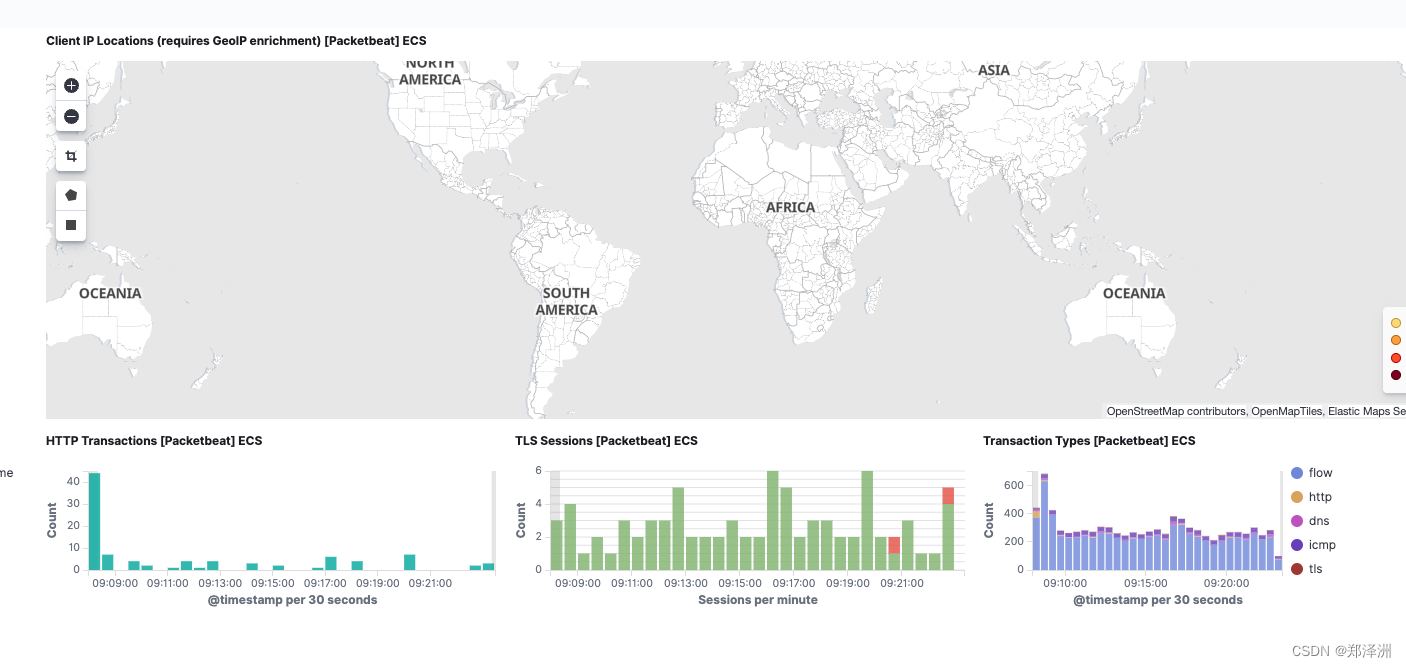
监控实图2:

孩子访问了啥网站,啥时候访问,网络地址、流量情况一应俱全:) 虽然和教育的目的相背,但是国内就好这一口不是😄 IT前辈大牛目前还在用物理手段,我已经升级到 云+大数据了,我要把这个项目开源,造福中国的父母,嘿嘿
注意版本问题!如下未特别说明的,都采用7.8.1版本,版本不匹配会有坑。
总体过程是:官网下载,unzip解压到本地目录,配置yml文件,后启动运行
10360* sudo ./packetbeat -e -c packetbeat.yml
10362 cd packetbeat-7.8.1-darwin-x86_64
10363* sudo ./packetbeat setup --dashboards
10364* sudo ./packetbeat -e -c packetbeat.yml
配置packetbeat.yml 输出到Kafka
# ---------------------------- Kafka -------------------------------------------
output.kafka:
hosts: ["localhost:9092"]
topic: packetbeat
required_acks: 1
采用docker-compose方式安装
version: '3'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- 9092:9092
environment:
KAFKA_ADVERTISED_HOST_NAME: 192.168.18.37
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock
kafka_manager:
image: sheepkiller/kafka-manager
container_name: kafka_manager
ports:
- 9000:9000
environment:
ZK_HOSTS: "zookeeper:2181"
APPLICATION_SECRET: "random-secret"
command: -Dpidfile.path=/dev/null
消费端代码如下供参考,也可以用logstash直接拉取
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
const TOPIC = "packetbeat"
func main() {
consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
partitionList, err := consumer.Partitions(TOPIC) // 根据topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println(partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := consumer.ConsumePartition(TOPIC, int32(partition), sarama.OffsetOldest)
fmt.Printf("---%+v\n", pc)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
i := 0
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%v Value:%v\n", msg.Partition, msg.Offset, string(msg.Key), string(msg.Value))
i++
if i > 5 {
return
}
}
}
}
安装过程参考官网说明,配置
input {
kafka {
bootstrap_servers => "localhost:59471"
topics => ["packetbeat"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "packetbeat-7.8.1-2022.05.01-000001"
document_type => "_doc"
}
stdout { codec => rubydebug }
}
也是docker-compose安装
services:
elasticsearch01:
build:
context: elasticsearch/
args:
ELK_VERSION: ${ELK_VERSION:-7.8.1}
volumes:
- type: bind
source: ./elasticsearch/elasticsearch.yml
target: /usr/share/elasticsearch/config/elasticsearch.yml
read_only: true
- ./data_elasticsearch01:/usr/share/elasticsearch/data
ports:
- "9200:9200"
environment:
- node.name=elasticsearch01
- discovery.seed_hosts=elasticsearch02
- cluster.initial_master_nodes=elasticsearch01,elasticsearch02
- bootstrap.memory_lock=true
#- "ES_JAVA_OPTS=-Xms${ES_HEAP_SIZE:-2g} -Xmx${ES_HEAP_SIZE:-2g}"
ulimits:
memlock:
soft: -1
hard: -1
elasticsearch02:
build:
context: elasticsearch/
args:
ELK_VERSION: ${ELK_VERSION:-7.8.1}
volumes:
- type: bind
source: ./elasticsearch/elasticsearch.yml
target: /usr/share/elasticsearch/config/elasticsearch.yml
read_only: true
- ./data_elasticsearch02:/usr/share/elasticsearch/data
environment:
- node.name=elasticsearch02
- discovery.seed_hosts=elasticsearch01
- cluster.initial_master_nodes=elasticsearch01,elasticsearch02
- bootstrap.memory_lock=true
#- "ES_JAVA_OPTS=-Xms${ES_HEAP_SIZE:-2g} -Xmx${ES_HEAP_SIZE:-2g}"
ulimits:
memlock:
soft: -1
hard: -1
kibana:
build:
context: kibana/
args:
ELK_VERSION: ${ELK_VERSION:-7.8.1}
volumes:
- type: bind
source: ./kibana/kibana.yml
target: /usr/share/kibana/config/kibana.yml
read_only: true
ports:
- "5601:5601"
environment:
- elasticsearch.hosts=["http://elasticsearch01:9200"]
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
使用ruby的watir测试网络应用程序时,浏览器最后会保持打开状态。网上的一些建议是,要进行真正的单元测试,您应该在每次测试时(在拆卸调用中)打开和关闭浏览器,但这很慢而且毫无意义。或者他们做这样的事情:defself.suites=superdefs.afterClass#Closebrowserenddefs.run(*args)superafterClassendsend但这会导致摘要输出不再显示(诸如“100次测试、100次断言、0次失败、0次错误”之类的内容仍应显示)。我怎样才能让ruby或watir在我的测试结束时关闭浏览器? 最佳答案
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
一、解决痛点使用spring-kafka客户端,每次新增topic主题,都需要硬编码客户端并重新发布服务,操作麻烦耗时长。kafkaListener虽可以支持通配符消费topic,缺点是并发数需要手动改并且重启服务。对于业务逻辑相似场景,创建新主题动态监听可以用kafka-batch-starter组件二、组件能力1、新增topic名称为:auto.topic1(由于配置spring.kafka.consumer.prefix为auto,因此只有auto前缀的topic,才会被组件动态监听。)2、应用输出日志,监听到新增auto.topic1,并初始化客户端(主题刷新间隔为10s)3、发新的消
我正在试验RSpec并考虑一个仅在测试套件通过时才更改随机种子的系统。我试图在after(:suite)block中实现它,该block在RSpec::Core::ExampleGroup对象的上下文中执行。虽然RSpec::Core::Example有一个方法“exception”,允许您检查是否有任何测试失败,但在上似乎没有类似的方法RSpec::Core::ExampleGroup或示例列表的任何访问器。那么,如何检查测试是通过还是失败?我知道这可以使用自定义格式化程序来跟踪是否有任何测试失败,但格式化过程影响测试的实际运行似乎不是一个好主意。 最佳答
十四届蓝桥青少组模拟赛Python-20221108T1.二进制位数十进制整数2在十进制中是1位数,在二进制中对应10,是2位数。十进制整数22在十进制中是2位数,在二进制中对应10110,是5位数。请问十进制整数2022在二进制中是几位数?print(len(bin(2022))-2)#运行结果:11T2.晨跑小蓝每周六、周日都晨跑,每月的1、11、21、31日也晨跑。其它时间不晨跑。已知2022年1月1日是周六,请问小蓝整个2022年晨跑多少天?#样例代码1ls=[0,31,28,31,30,31,30,31,31,30,31,30,31]ans=0k=6foriinrange(1,13)
看了thisquestion已经,这或多或少反射(reflect)了我目前如何运行我的整个套件。此外,我还设置了以下rake任务:Rake::TestTask.newdo|t|t.name="spec:models"t.libs但我注意到当我使用timerakespec:models运行它时,它在大约2.36秒内完成。如果我使用ruby/path/to/spec.rb运行该目录中的所有单独测试(目前所有测试都与ActiveRecord隔离——还没有持久性,所以速度非常快),它们的累计总用户时间是2.36秒,但我也注意到虽然每个文件从开始到结束需要0.4用户秒来执行,但MiniTest报
目录一、下载Elasticsearch1.选择你要下载的Elasticsearch版本二、采用通用搭建集群的方法三、配置三台es1.上传压缩包到任意一台虚拟机中2.解压并修改配置文件(配置单台es)3.配置三台es集群4.设置后台启动和开机自启(可选)一、下载Elasticsearch1.选择你要下载的Elasticsearch版本es下载地址这里我下载的是二、采用通用搭建集群的方法集群搭建方法三、配置三台es1.上传压缩包到任意一台虚拟机中上传方式有两种第一种:使用xftp上传直接拖动过去就可以了。第二种:使用lrzsz先安装yum-yinstalllrzsz切换到要上传的位置cd/opt/