Java栈和队列·上
大家好,我是晓星航。今天为大家带来的是 Java栈和队列·上 的讲解!😀
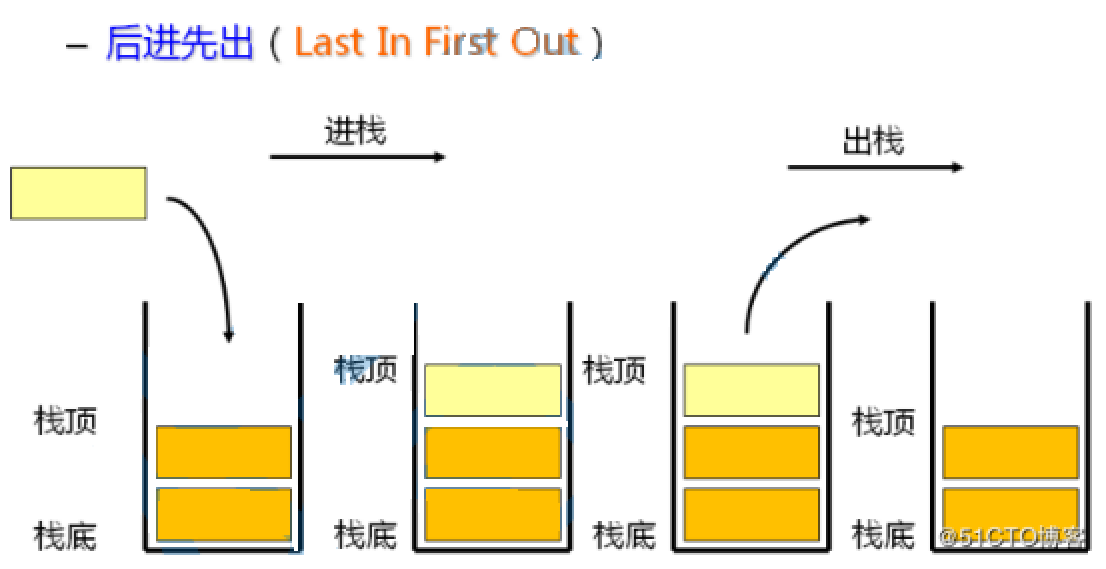
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
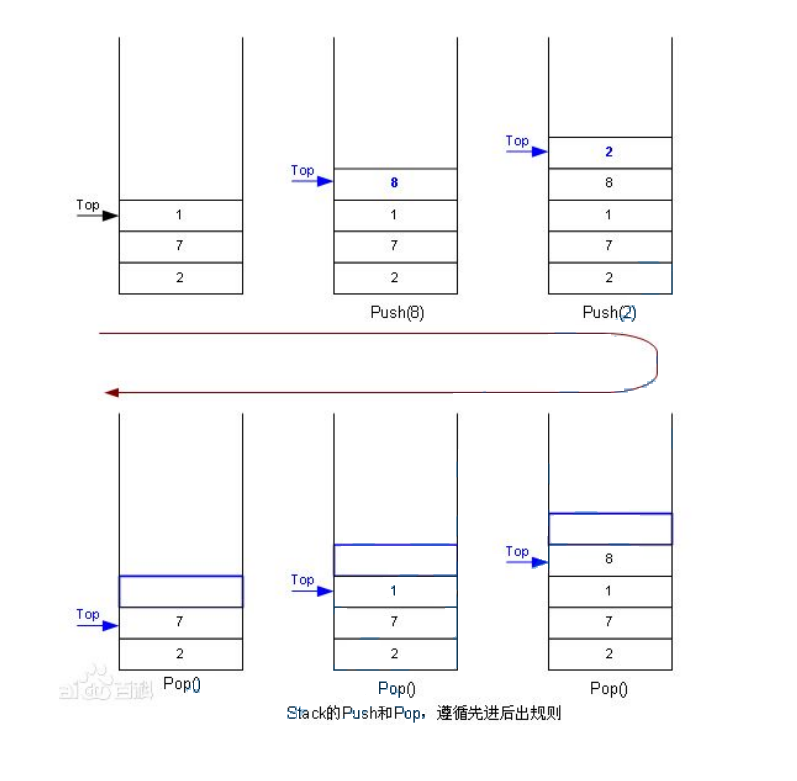
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据在栈顶。(先进去的后出)
那么什么是栈帧呢?
答:我们调用函数时,计算机会为这个函数开辟一块内存,即为栈帧。在JVA stack上开辟。
提问:能不能用单链表实现栈?

相对来说,顺序表的实现上要更为简单一些,所以我们优先用顺序表实现栈。
public class TestDemo {
// 简单起见,我们就不考虑扩容问题了
private int[] array = new int[100];
private int size = 0;
public void push(int v) {
array[size++] = v;
}
public int pop() {
return array[--size];
}
public int peek() {
return array[size - 1];
}
public boolean isEmpty() {
return size == 0;
}
public int size() {
return size;
}
}
push:增加栈中元素(压栈-在栈顶插入)
pop:弹出栈顶元素,并且删除
peek:获取栈顶元素,但是不删除
empty:判断栈中元素是否为空,为空返回true,不为空返回flase。
size:获取栈中元素个数,并返回数值
isEmpty:判断栈中元素是否为空,为空返回true,不为空返回flase。(继承于Vector父类)
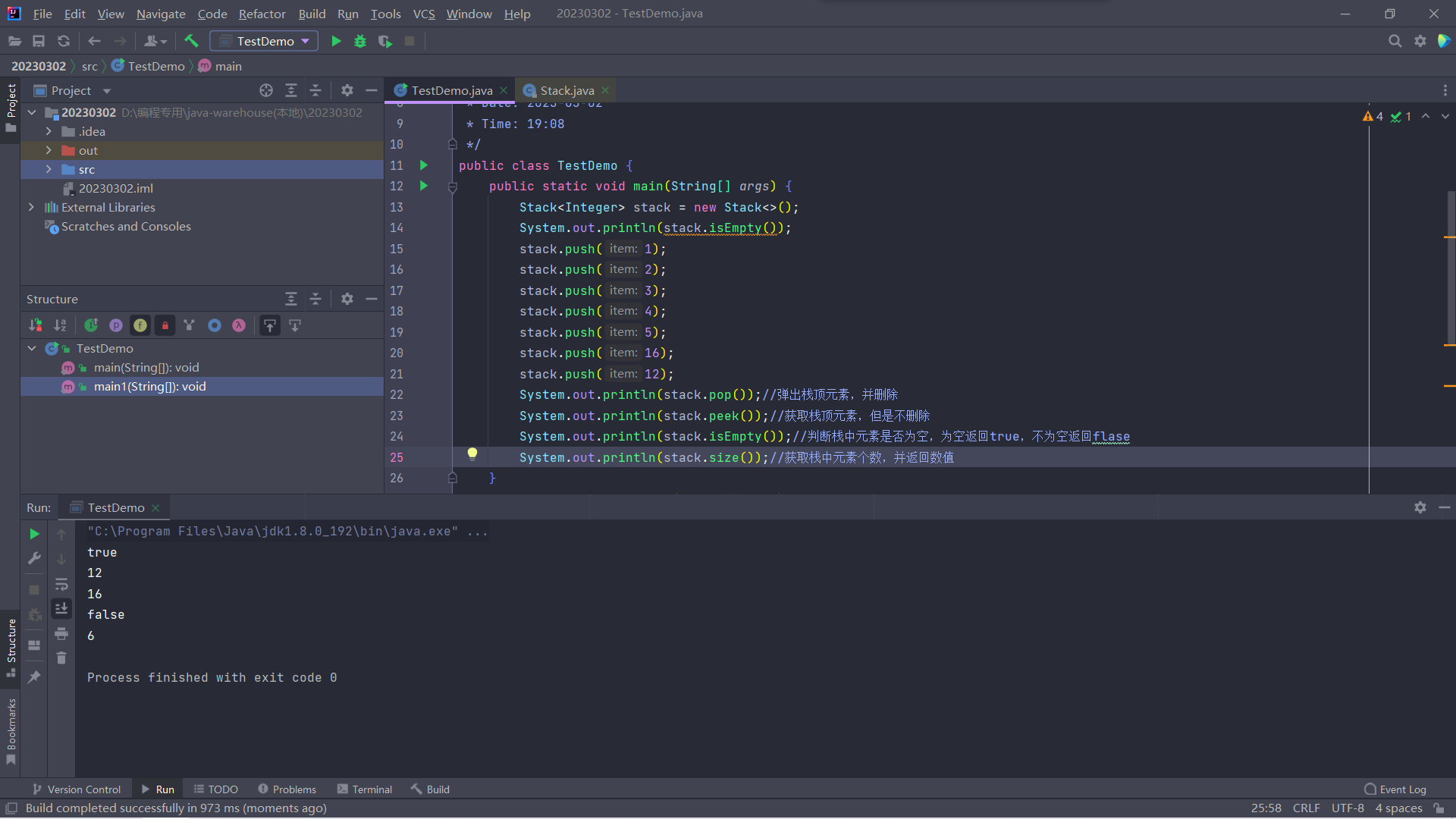
代码示意图如上
自己实现栈:
import java.util.Arrays;
public class MyStack {
public int[] elem;
public int useSize;
public MyStack() {
this.elem = new int[5];
}
public void push(int val) {
if(isFull()) {
//扩容
this.elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
this.elem[this.useSize] = val;
useSize++;
}
public boolean isFull() {
return this.useSize == this.elem.length;
}
public int peek() {
if (isEmpty()) {
throw new RuntimeException("栈为空");
}
return this.elem[useSize - 1];
}
public int pop() {
if (isEmpty()) {
throw new RuntimeException("栈为空");
}
int oldVal = this.elem[useSize-1];
this.useSize--;
return oldVal;
}
public boolean isEmpty() {
return this.useSize == 0;
}
}

1、入栈和出栈的顺序?
例如:一个栈的入栈序列是a、b、c、d、e则栈不可能的输出序列是:()
A.edcba B.decba C.dceab D.abcde
答:选C。
解析:这里我们后入的先出,但不一定要全部入进去才能出,所以例如选项D可以入一个出一个。
2、已知一个栈的入栈序列是mnxyz,则不可能出现的出栈顺序是?
A.mnxyz B.xnyzm C.nymxz D.nmyzx
答:选C
解析:这里和上面第一题解法相同也是后入的先出,随进随出,而C不符合这个规律,因此C错误。
3、中缀表达式 转 后缀表达式:
(5+4)*3-2
(((5+4)*3)-2)
(((54)+3)*2)-
54+3*2-
如何通过 这个后缀 表达式 来计算一个值呢?
具体图解过程如下:
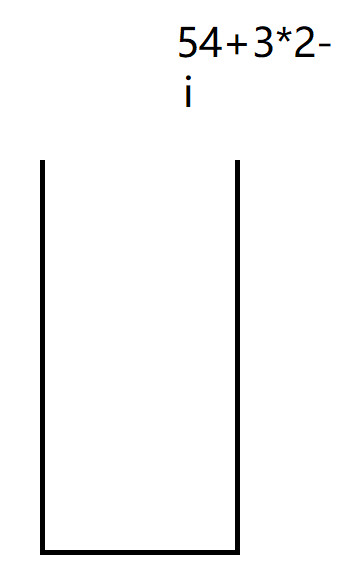
i开始遍历我们的表达式:
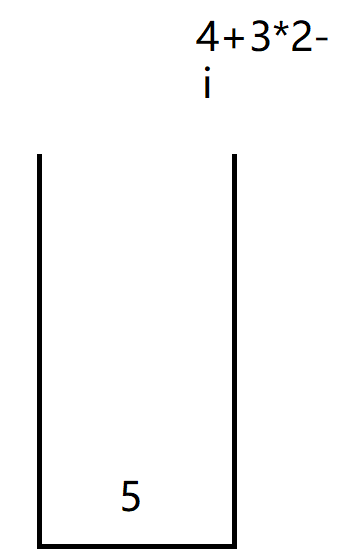
i遍历到4,并将5放入栈中
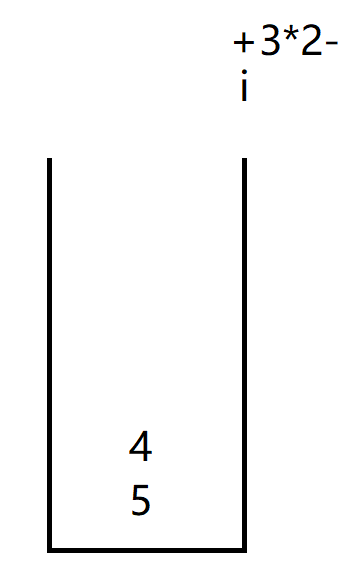
i遍历到+,并将4放入栈中

此时因为i访问到了+号,因此开始计算前面两个元素的值,先入栈的放左边后入栈的放右边。

将计算好的结果9放入栈中,i继续向后走遇到3
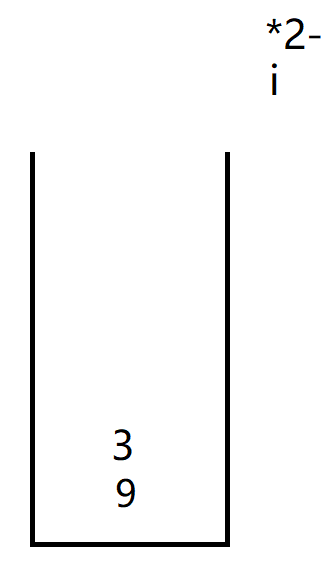
i遍历到*,并将3放入栈中

此时因为i访问到了*号,因此开始计算前面两个元素的值,先入栈的放左边后入栈的放右边。

将计算好的结果27放入栈中,i继续向后走遇到2

i遍历到-,并将2放入栈中
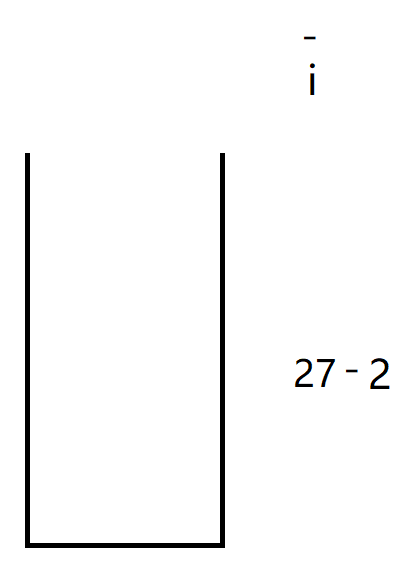
此时因为i访问到了-号,因此开始计算前面两个元素的值,先入栈的放左边后入栈的放右边。
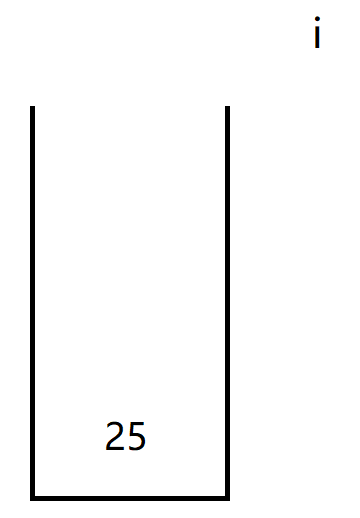
i往后走没有值停下,此时将计算好的结果25放入栈中
上述便是计算机计算后缀表达式的详细图解过程
转化方法为先按照计算顺序分别加上括号,然后再按照符号的顺序将他们分别放在各自的括号后面(后缀表达式)
如果此时是将中缀表达式 转 前缀表达式 则为:-*+54 3 2 (过程如下)
(5+4)*3-2
(((5+4)*3)-2)
-(*(+(54)3)2)
-*+54 3 2
如何用代码来实现中缀表达式转化为后缀表达式呢?
1.定义很多的常量,来标识每个运算符的优先级( ) + - * /
2.借助栈
下面为大家带来一个使用栈来计算后缀表达式的编程题目:
class Solution {
public int evalRPN(String[] tokens) {
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < tokens.length; i++) {
String val = tokens[i];
if (!isOperation(val)) {
//如果不是运算符
stack.push(Integer.parseInt(val));
} else {
//如果是运算符
int num2 = stack.pop();
int num1 = stack.pop();
switch (val) {
case "+":
stack.push(num1+num2);
break;
case "-":
stack.push(num1-num2);
break;
case "*":
stack.push(num1*num2);
break;
case "/":
stack.push(num1/num2);
break;
}
}
}
return stack.pop();
}
private boolean isOperation(String x) {
if (x.equals("+") || x.equals("-") || x.equals("*") || x.equals("/")) {
return true;
}
return false;
}
}
下面题目是通过计算机来计算出栈与入栈的可能性:


1、遍历pushA数组,存放元素到栈中。
2、获取栈顶元素和当前j下标元素是否一样?
3、如果一样哪么就弹出,j++ ……
注意事项:
1、栈是否为空?
import java.util.ArrayList;
public class TestDemo {
public boolean IsPopOrder (int [] pushA,int [] popA) {
Stack<Integer> stack = new Stack<>();
int j = 0;
for (int i = 0; i < pushA.length; i++) {
stack.push(pushA[i]);
while (j < popA.length && stack.empty() && stack.peek() == popA[j]) {
stack.pop();
j++;
}
}
return stack.empty();
}
}
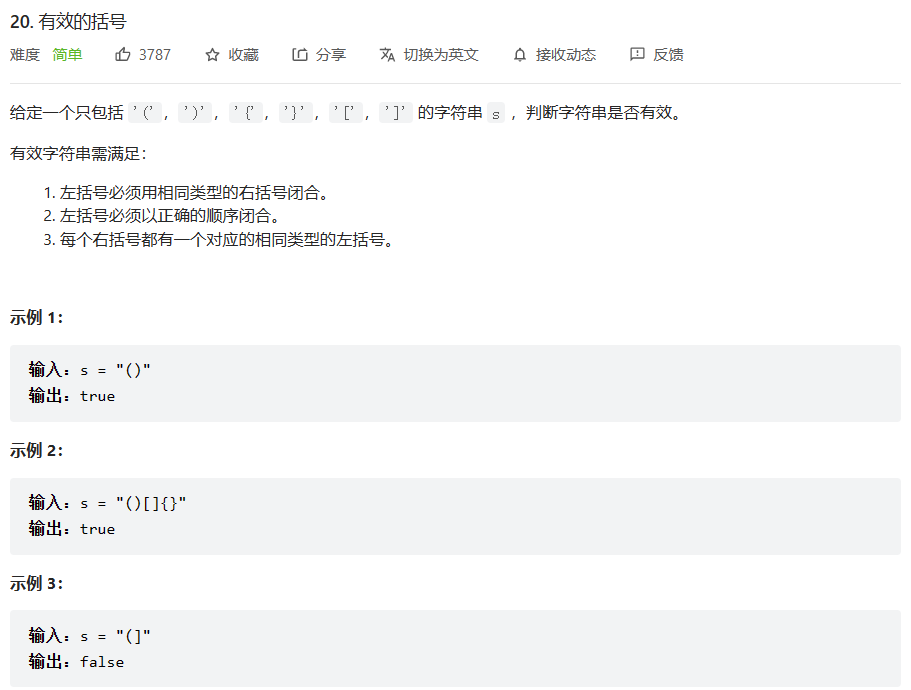
import java.util.Stack;
class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
if (ch == '(' || ch == '[' || ch == '{' ) {
//如果是左括号直接入栈
stack.push(ch);
} else {
//如果是右括号
if (stack.empty()) {
//右括号多
System.out.println("右括号多!");
return false;
}
char top = stack.peek();
if (top == '(' && ch == ')' || top == '[' && ch == ']' || top == '{' && ch == '}') {
//如果左括号和右括号匹配 则弹出这个左括号
stack.pop();
} else {
//左右括号不匹配
System.out.println("左右括号不匹配");
return false;
}
}
}
if (!stack.empty()) {
//左括号多
System.out.println("左括号多!");
return false;
}
return true;
}
}
题目描述的很清楚,左右括号如果不匹配,无非是以下几种情况:
1、左括号多余右括号
2、右括号多余左括号
3、左右括号顺序不想匹配
在使用代码将这几种情况考虑完全后,便可轻易通过测试。
思路如下:
如果是左括号我们直接使其进栈,如果是右括号我们先判断右括号是否比左括号多,再看其是否相匹配,匹配则弹出相对应的左括号继续下一个括号的判断,如果不匹配则返回不匹配错误,在右括号全部判断完毕后,我们判断一下栈此时是否为空,如果为空则我们所有的括号都匹配成功即正确,如果不为空则是左括号比右括号要多,我们就返回false。


class MinStack {
private Stack<Integer> stack;
private Stack<Integer> minStack;
public MinStack() {
stack = new Stack<>();
minStack = new Stack<>();
}
public void push(int val) {
stack.push(val);
if (!minStack.empty()) {
int top = minStack.peek();
//比较 小于等于的话 也要放进来
if (val <= top) {
minStack.push(val);
}
} else {
minStack.push(val);
}
}
public void pop() {
int popVal = stack.pop();
if (!minStack.empty()) {
int top = minStack.peek();
if (top == popVal) {
minStack.pop();
}
}
}
public int top() {
return stack.peek();
}
public int getMin() {
return minStack.peek();
}
}
思路:这里我们采取了使用两个栈(一个普通栈 一个最小栈)来比较的方法,例如我们在push元素时,普通栈我们是直接放进去的,而最小栈我们则是通过比较,如果要放的元素比我们最小栈栈顶的元素小或等于我们便在最小栈也放入一份。
在pop弹出栈顶元素时我们同样是直接弹出普通栈的栈顶元素,然后比较这个弹出的元素和最小栈栈顶元素的大小是否相等,如果相等我们则还需要再pop一次最小栈的栈顶元素。
top方法和我们stack栈中的peek方法一样,我们直接返回stack的peek方法即可。
getMin方法是返回栈中最小元素,我们这里有两个栈,而最小栈的原理就是将最小的元素通过压栈(头插)的方式进入最小栈,因此我们最小栈的最小值永远是栈顶的元素,我们直接返回最小栈的栈顶元素即可。

感谢各位读者的阅读,本文章有任何错误都可以在评论区发表你们的意见,我会对文章进行改正的。如果本文章对你有帮助请动一动你们敏捷的小手点一点赞,你的每一次鼓励都是作者创作的动力哦!😘
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
Java的Collections.unmodifiableList和Collections.unmodifiableMap在Ruby标准API中是否有等价物? 最佳答案 使用freeze应用程序接口(interface):Preventsfurthermodificationstoobj.ARuntimeErrorwillberaisedifmodificationisattempted.Thereisnowaytounfreezeafrozenobject.SeealsoObject#frozen?.Thismethodretur