导读:随着 5G 网络的普及以及疫情带来的影响,人们对实时音视频技术的应用场景会越来越多,包括会议、连麦、音视频通话、在线教育、远程医疗等,这些实时互动场景对 RTC 音频的质量提出了越来越高的要求。如何对 RTC 音频的效果开展测试,通过构建客观、标准、可重复的评价体系来保证好的音频传输质量,也成为目前比较紧急和重要的课题。

文|马建立 网易云信资深音视频测试工程师

理想的沟通模型

日常沟通中面对面的交流一般有比较好的效果,如果在一个安静的实验室内,减少环境的干扰和影响,会得到理想的沟通效果。我们再把这个模型抽象一下,大体可以看出有以下的特点:
环境安静:NR15 的底噪,相当于在极其安静的夜晚,人耳能不受到其他影响的干扰,集中注意力听目标人声。
适宜听音的混响环境:混响通常会影响听音者的理解程度,混响越大,语音的拖尾越长,可懂度也就越低。比如在混响较大的演唱厅,对于乐器和歌声来说,会有一定的美化效果,但是对于人的沟通交流是不利的。
语音清晰、自然:讲话者心理和生理都处在极佳的状态,发音清楚,频率均衡,语音流畅,语速适中。
声音大小适中:研究表明,音量对音质的影响是显著的,在其他条件一致的情况下,音量越大,主观听感越好。讲话者说话声音洪亮,在一定程度上能提升听音者的可懂度。
响应及时、沟通顺畅:在 RTC 的实时沟通中,延时也是一个非常重要的指标,一般来说,200ms 以内人的延时人的主观感觉无明显的障碍和迟滞感,200ms-400ms 能正常沟通,超过 400ms 就会有的迟滞感,更严重时会出现抢话的现象,直接影响通话的体验。在面对面的沟通场景下,时延只有 3ms 左右。

RTC 音量链路

上图是通过 RTC 实时沟通的两个人,从图上可以看出,讲话者 A 开始说话,声音经过空气传播、麦克风采集、A/D 转换、增强处理(降噪、回声消除、音量控制、去混响)、编码、打包传输、接收端解码、NetEQ、D/A 转换到下行播放,然后 B 听到声音。这是单工状态下的完整的声音传输的路径。
与理想的沟通模型相比,实际的 RTC 链路中存在多种类型的干扰和影响,比如环境影响、硬件影响、链路影响和网络影响,每个环节都有可能引入音频质量的下降。这些影响综合下来,会导致如下几个方面的声音的问题。

主观测试方法

最早的主观测试以两个人通话为主,A 和 B 建立起 RTC 的链接,通过分别或者同时讲话,还原真实场景的用户使用场景,主要关注的以下 3 个维度。
Listening Quality:听音者的音质,是单工的使用场景,比如 A 在讲话,B 听到的声音的质量,就是 Listening Quality,Listening Quality 描述了大部分情况下的语音质量,也是最基础的部分,目前业界已有的客观评价方法和手段基本上都是基于 Listening Quality。
Talking Quality:讲话者的音质,是讲话人自己听到的声音质量,与回声、侧音掩蔽、本地的环境都有一定的关系。
Conversation Quality:对话音质,除了包含 A/B 两个人的 Listening Quality 和 Talking Quality,还跟双工通话有关系,主要的影响因素有回声双讲和端到端延时。
主观测试关注的维度

主观测试要关注的点如上图所示,分为音质、音色、音量、延时、回声、降噪等几个大的方面。
音色
音色又称之为音品,是听觉感到的声音的特色,音色主要决定于声音的频谱。在 RTC 的链路中,影响声音的频率响应主要是麦克风的频率特性、中间处理如 EQ、高低通滤波、以及音量控制的算法(DRC/AGC)、扬声器/耳机得到频响等。不同人的发声频率分布也有差异,一般来说男性声音低频多,声音浑厚或者偏闷,女性或者小孩有更多的高频成分,声音明亮甚至有些尖锐。
音质:音质分为 3 个维度,清晰度、流畅度和自然度。
音量
对于 RTC 的 SDK 供应商来说,面临的最大挑战是设备多样性,不同的平台(Mac、Windows、Android、iOS、Web),以及不同机型和不同的外接设备,不同的机型或者设备采集、播放音量差异大。音量控制的策略在于能够保证不同平台设备之间的一致性,保证用户能够听到足够大小的声音,且不会显性的带来音质损伤和下降。
噪声
降噪算法的目的在于去除环境或者设备引入的噪声干扰,尽可能多的还原人声,提升信噪比。实际的降噪算法在处理噪声的过程中,都不可避免的、或多或少的损伤音质。因此评价降噪主要从两个方面考虑:
回声
回声消除是 RTC 链路中比较重要的一个模块,目的是消除设备的回声,保证顺畅的通话体验。评价回声也主要从两个点出发:
延时
网络传输中音频对抗丢包的算法如 FEC、RED、ARQ,以及对抗丢包的算法如 Jitter Buffer 等,都会产生额外的延时,导致端到端的延时增大,对于实时沟通交流带来负面的影响和体验下降。尤其是对于一些低时延的场景来说,端到端延时是一个衡量弱网对抗性能的重要指标。
主观测试的痛点
目前 RTC 音频的主流评价方式主要依靠主观测试和听音,这种方式对于人的专业能力要求比较高,而且效率比较低。主要有以下几个方面的痛点:
针对以上的痛点问题,网易云信目前在音频效果的评价和测试上,打造了一套从实验室构建、环境模拟、采集播放、评价方法端到端的客观评价方法。

标准实验室

上图是网易云信的声学实验室,主要的设备和硬件配置如下所示:

通过构建专业的音频测试实验室,满足音频自动化测试/竞品分析评测/版本间基线效果快速对比测试的需求,获得可重复的客观测试结果,同时能够满足研发音频算法仿真和原型验证的需求。还可以一人完成 3A 主观测试:降噪、音质、回声单双讲测试。目前 AI 算法越来越多,数据是 AI 类算法的关键,有了声学实验室和噪声模拟系统,通过编写自动化脚本的方式,可以实现 AI 数据自动采集和标注,大大降低数据购买和标记成本。目前云信的声学实验室组网如上图所示,实验室的引入提升了开发和测试的专业度,主要有以下方面的应用:

客观测试标准
实验室主要是提供了客观可重复的测试环境,硬件设备支持自定义的采集和播放,除此之外,目前网易云信的音频实验室还引入了客观的测试标准,作为最终数据的评价方法。音频测试标准按照不同维度有不同的划分。
主观/客观
主观是基于人类的主观评价,客观方法是用模型来计算和评估语音质量。典型的主观评测标准如P.800,客观的语音质量评测方法如 PESQ。
有参考/无参考
完全参考/无参考 (FR/NR) 描述所用测量算法的类型。FR 算法有两个信号:原始信号和失真信号。NR 算法只需要一个失真信号。典型的 FR 算法是例如 PESQ。典型的 NR 测量是 P.563,NR 方法也常被称为“单端”测试。
感知/非感知
通常,此类测量算法会尝试对人类感知进行建模。感知建模不仅用于质量的评估。其他著名的感知算法例如使用感知模型的 MP3 或 AAC 用于压缩音乐。非感知指标是一般的物理或技术指标,例如电平或信噪比。
基于感知模型的客观标准

基于感知模型的客观指标最经典也是应用最广泛的是有源客观语音质量测试标准 p.86x 系列,也是就常说的 PESQ/POLQA,是一种典型的有参考的语音评价标准, PESQ/POLQA 总的思路是:对原始信号(参考信号)和通过测试系统的信号进行电平调整到标准听觉电平,再用输入滤波器模拟标准电话听筒进行滤波。
对通过电平调整和滤波后的两个信号在时间上对准,并进行听觉变换,这个变换包括对系统中线性滤波和增益变化的补偿和均衡。两个听觉变换后的信号之间的不同作为扰动(即差值),分析扰动曲面提取出两个失真参数,在频率和时间上累积起来,映射到对主观平均意见分的预测值。POLQA 相对于 PESQ 做了大量精度的优化,使得客观测试结果与主观测试结果的一致性更高,在语音评测方面有个非常广泛的应用。

自动化测试
POLQA 自动化测试

网络测试中,为减少硬件采集播放和声学链路的影响采用电信号链路的测试。发送端和接受端的两台设备使用 3.5mm 的音频线与声卡连接。此外,有一套 TC 系统来提供网损环境,被测试的两台设备接入 TC 的 Router,通过脚本控制两端设备的丢包、延时、抖动和带宽。
如上图所示,测试主机通过声卡将信号发送给测试设备 A,测试设备经过本端的 RTC 音频处理后,经过网络传输发送到接收端设备 B,在这个过程中,通过弱网系统实时添加不同类型和程度的网损。声卡接收到测试设备 B 的信号,通过与原始信号的比对和分析,来衡量 RTC 对于弱网对抗模块的性能。
3A 客观自动化
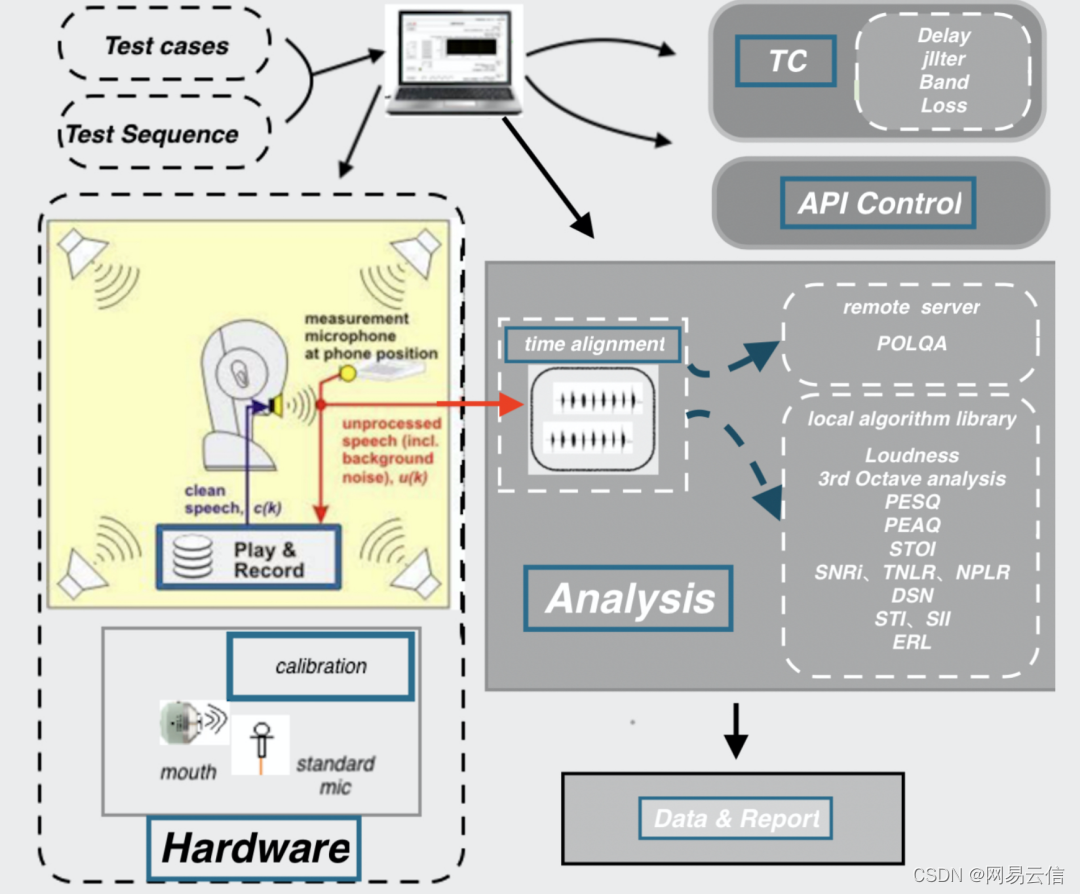
网易云信目前基于实验室搭建了端到端的 3A 自动化测试,架构框图如上图所示,主要分为用例管理层、API/UI 控制层、采集和播放、自动校准、分析与计算、数据和报告几个大的模块。主要用于回声、噪声和音量控制的综合评价,目前在版本基线测试、版本迭代对比、竞品对比等测试环节中应用。
作者介绍
马建立,网易云信资深音视频测试工程师,网易云信音视频媒体实验室核心成员,负责音频测试质量体系建设和音视频质量保障工作。
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
我正在运行RubyonRails3,我想使用Paperclip插件/gem降低上传图像的质量。我该怎么做?此时在我的模型文件中我有:has_attached_file:avatar,:styles=>{:thumb=>["50x50#",:jpg],:medium=>["250x250#",:jpg],:original=>["600x600#",:jpg]}这会将图像转换为.jpg格式并设置尺寸。 最佳答案 尝试使用convert_options。has_attached_file:avatar,:styles=>{:thumb=
开发者!我无法理解接下来的情况例如我有模型classPg::City我可以使用这样的代码:c=Pg::City.new({:population=>1000})putsc.population1000但是如果我取消注释上面的attr_accessible代码会抛出警告WARNING:Can'tmass-assignprotectedattributes:population如何将虚拟属性与模型属性一起用于质量分配?谢谢! 最佳答案 使用attr_accessor添加变量不会自动将其添加到attr_accessible。如果您要使用a
解决台式机麦克风不可用问题戴尔灵越3880最近因为需要开线上会议,发现戴尔台式机音频只有输出没有输入,也就是只能听见声音,无法输入声音。先后尝试了各种驱动安装更新之类的调试,无果。之后通过戴尔支持解决~这里多说一句,专业的就是专业,问题描述过去,直接给了解决方案,可能是他们遇到的相似问题比较多了,但也告诉我们,有些时候是可以通过这些官方服务解决问题的,比起自己折腾效率要高很多。那就记录一下吧~问题描述:电脑只能输出声音,不能输入声音。1、前提需要准备一只带麦克风的耳机,将耳机插入面板。2、先确定是否可以听到声音,可以通过播放歌曲或者视频。3、然后确认麦克风是否可用,可以通过调用win自带麦克风
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭4年前。Improvethisquestion我是Ruby的新手,时间有限,因此我尝试了一些简单的东西。最近我需要创建一个文件,因为我太懒了,所以我跑去谷歌。结果:File.open(local_filename,'w'){|f|f.write(doc)}真可惜,这很简单,我应该自己做的。然后我想检查File类的方法提供了什么ruby魔法,或者在调用这些方法时是否有任何“简化”,所以我前往文档here,并检查文件类。1.8.6文档在"fi
以VSTiTriforce为例,由Tweakbench提供。当加载到市场上的任何VST主机时,它允许主机向VSTi发送(大概是MIDI)信号。然后VSTi将处理该信号并输出由VSTi内的软件乐器创建的合成音频。例如,将A4(我相信是MIDI音符)发送到VSTi会导致它合成高于中央C的A。它将音频数据发送回VST主机,然后它可以在我的扬声器上播放或将其保存为.wav或其他一些音频文件格式。假设我有Triforce,我正在尝试用我选择的语言编写一个程序,它可以通过发送要合成的A4纸条与VSTi交互,并自动将其保存到系统上的文件?最终,我希望能够解析整个单轨MIDI文件(使用已经可用于此
特性工作电压范围:6V-14V输出功率:7W(CLASSD,7.4V/4Ω,THD=10%)10W(CLASSD,9V/4Ω,THD=10%)18W(CLASSD,12V/4Ω,THD=10%)最高可达92%效率(12V/8Ω)电平设置工作模式无需输出滤波器差分输入优异的“上电,掉电”噪声抑制过流保护、过热保护、欠压保护 eSOP-8封装典型应用电路很简单:如下是本人的设计。 输入电阻:输入电阻主要是确定增益,即输出功率,所以一定要确定输入信号的幅度,喇叭的幅度,前后使用有效值计算。此设计搭配的喇叭是8R3W,额定功率3W,额定电压4.89V(有效值),最大功率4W。我们先确定输入信号的赋值,
动手点关注干货不迷路1. 背景随着RTC使用场景的不断复杂化,新特性不断增多,同时用户对清晰度提升的诉求也越来越强烈,这些都对客户端机器性能提出了越来越高的要求(越来越高的分辨率,越来越复杂的编码器等)。但机器性能差异千差万别,同时用户的操作也不可预知,高级特性的使用和机器性能的矛盾客观存在。当用户机器负载过高时,我们需要适当降级视频特性来减轻系统复杂性,确保重要功能正常使用,提升用户体验。视频性能降级能做什么?一是解决因设备性能不足、突发的性能消耗冲击(如杀毒软件)带来的用户音视频体验问题(如视频卡顿、延时高、设备卡死)等问题;二是提升一些高级功能的渗透率,例如默认情况下开启视频超分,设备性
做音频处理(虽然它也可以是图像处理)我有一个一维数字数组。(它们恰好是代表音频样本的16位有符号整数,这个问题同样适用于float或不同大小的整数。)为了匹配不同频率的音频(例如,将44.1kHz样本与22kHz样本混合),我需要拉伸(stretch)或压缩值数组以满足特定长度。将数组减半很简单:每隔一个样本丢弃一次。[231,8143,16341,2000,-9352,...]=>[231,16341,-9352,...]将数组宽度加倍稍微不那么简单:将每个条目加倍(或可选地在相邻的“真实”样本之间执行一些插值)。[231,8143,16341,2000,-9352,...]=>[2
Java自学超全干货分享!学不学自己看着办吧!最近收到了很多知友私信我:”0基础有什么推荐的Java学习工具?”★作为ACM金牌选手,这些年在跟很多学员受教的过程中,积累了一些关于新手Java学习的经验和踩过的坑,今天来跟大家分享几点:1.找准学习路径和方法(选择不对,努力白费)2.合理规划学习时间,不在没必要的技术上浪费时间(找重点)3.找一些志同道合的朋友一起学习(相互鞭策)4.找一个前辈指点(方式方法)“还没开始就结束了”,作为java新手小白,最难自然是找对学习路径和方法……于是,本着一颗无私奉献的心,我连夜整理出了8个优质的Java免费学习网站,分享给大家。NO.1菜鸟教程国内小白入