前言
之前我们有用到top、free、iostat等等命令,去监控服务器的性能,但是这些命令,我们只针对单台服务器进行监控,通常我们线上都是一个集群的项目,难道我们需要每一台服务器都去敲命令监控吗?这样显然不是符合逻辑的,Linux中就提供了一个集群监控工具 – prometheus。
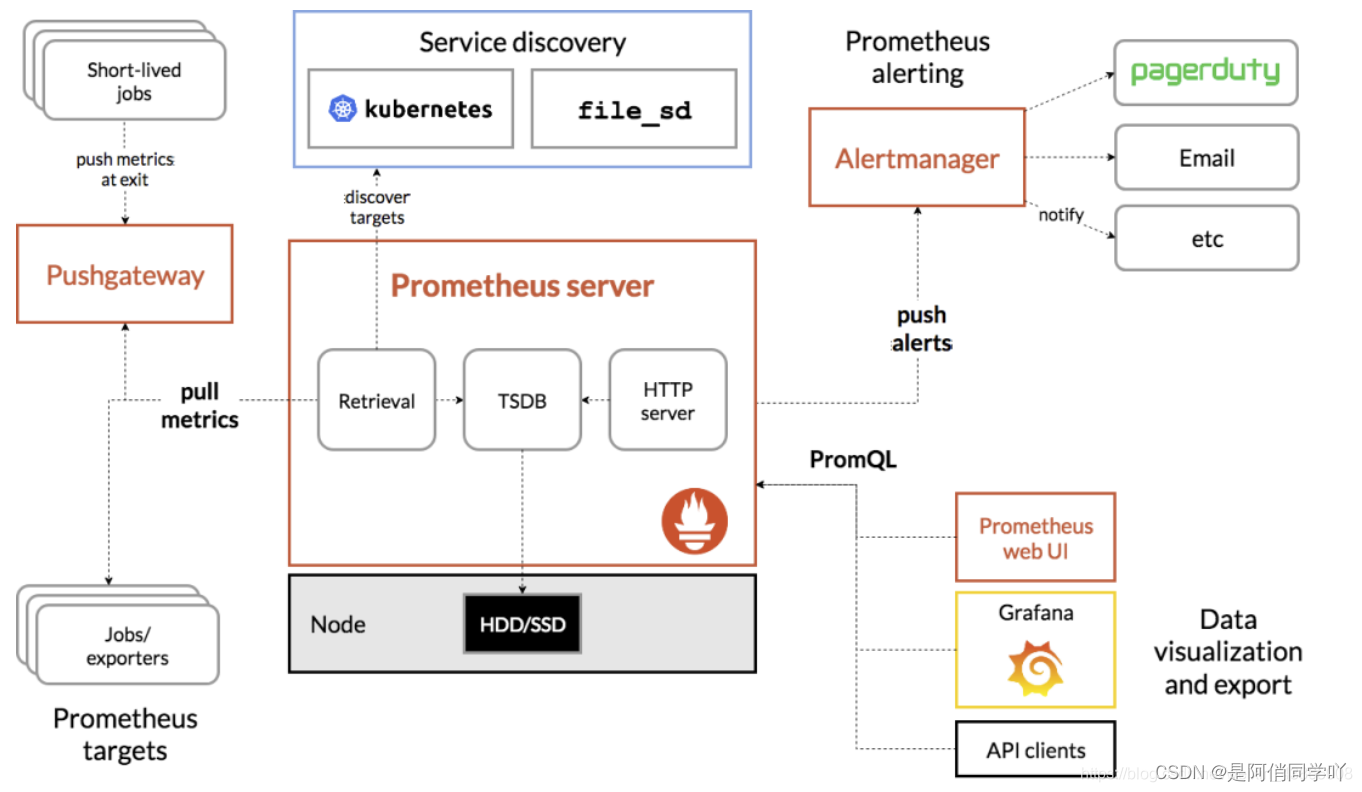
prometheus 监控原理
1、prometheus :虽然说是监控平台,但是实际上是一套数据库
2、mysql_exporter: 可以理解成程序或者软件,他是工作在我们要监控的目标服务器上,主要是用于监控mysql的数据。
3、node_exporter: 他的作用主要是收集性能测试的数据,如cpu、内存磁盘网络等信息,然后将数据保存到prometheus,相当于将数据存入到数据库中。
4、prometheus 只能用于做数据存储,不能做展示,因此我们需要用到grafana组件。
5、grafana 主要是用于数据展示,并且可以做到定时读取数据
 下载docker镜像
下载docker镜像
docker pull prom/node-exporter
docker pull prom/prometheus
docker pull grafana/grafana
启动监控Linux的exporter
docker run -d -p 9100:9100 \
-v "/proc:/host/proc:ro" \
-v "/sys:/host/sys:ro" \
-v "/:/rootfs:ro" \
prom/node-exporter
exporter测试访问地址
http://localhost:9100/metrics
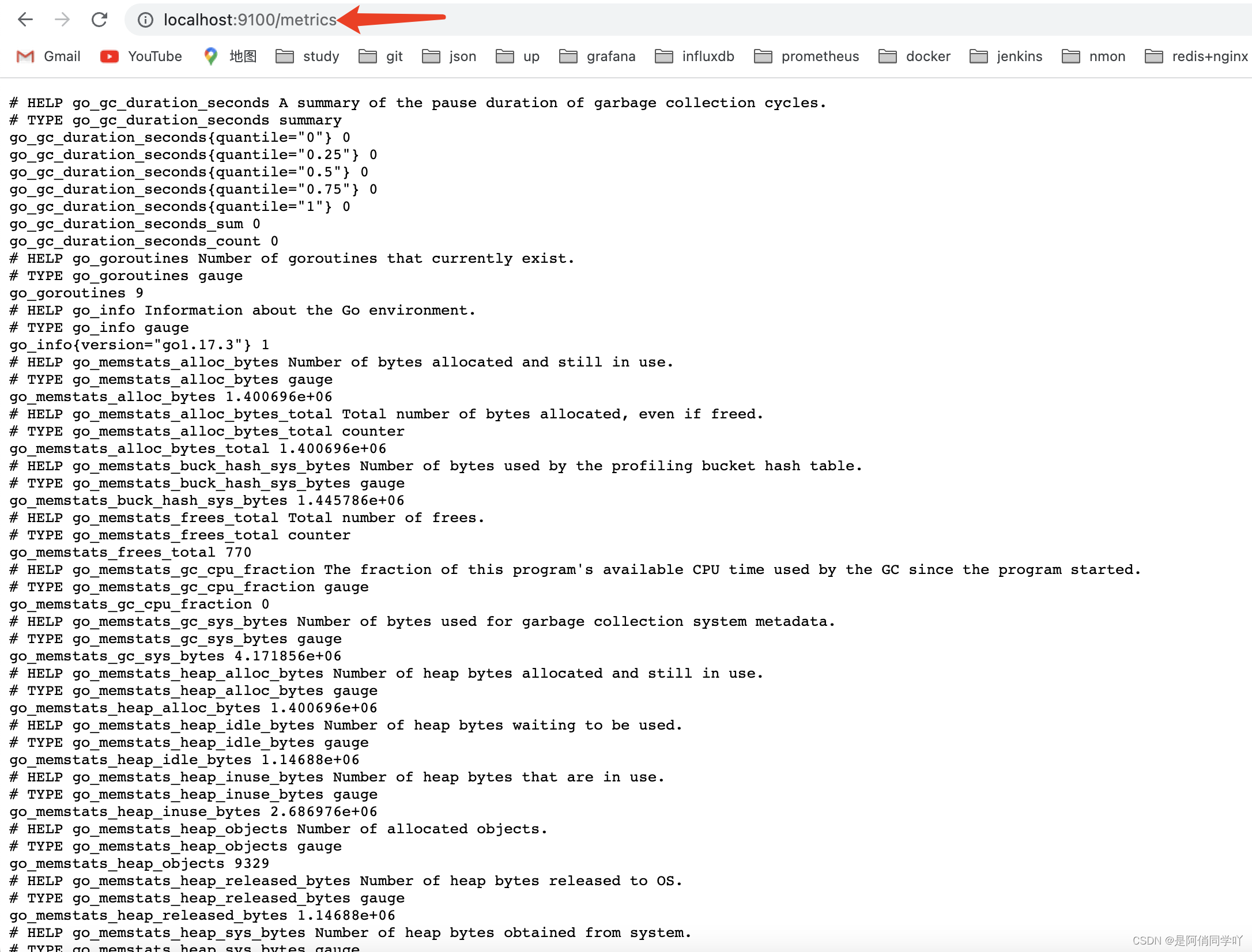
我们可以看到启动exporter已经成功啦
部署prometheus
首先我们需要创建存放prometheus的文件目录
mkdir /opt/prometheus
cd /opt/prometheus/
vim prometheus.yml
配置peometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: ['192.168.31.44':9100']
labels:
instance: linux
这里要特别说明下,这里涉及一个坑点,小编我就猜坑了,特此记录下。
`在scrape_configs配置项下添加Linux监控的job,其中node_expore的IP千万不要使用localhost,因为使用localhost或者127.0.0.1都是去访问普罗米修斯容器的本身;就会报node_exporter 提示错误 Get “http://localhost:9100/metrics 20”: dial tcp 127.0.0.1:9100: connect: connection refused的错误
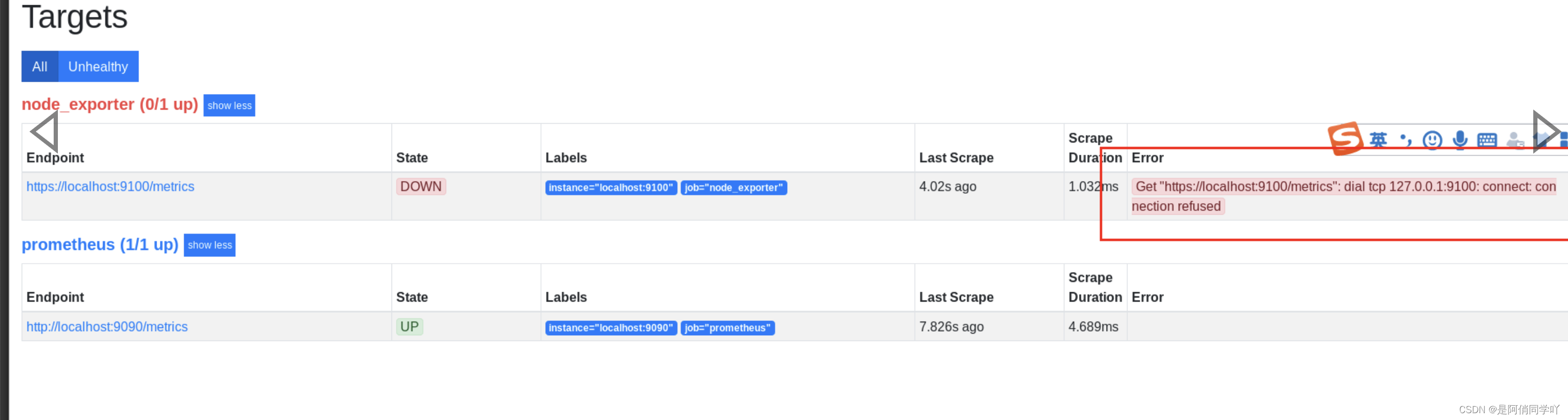
点击上图的url ,跳转的地址也是不正确的
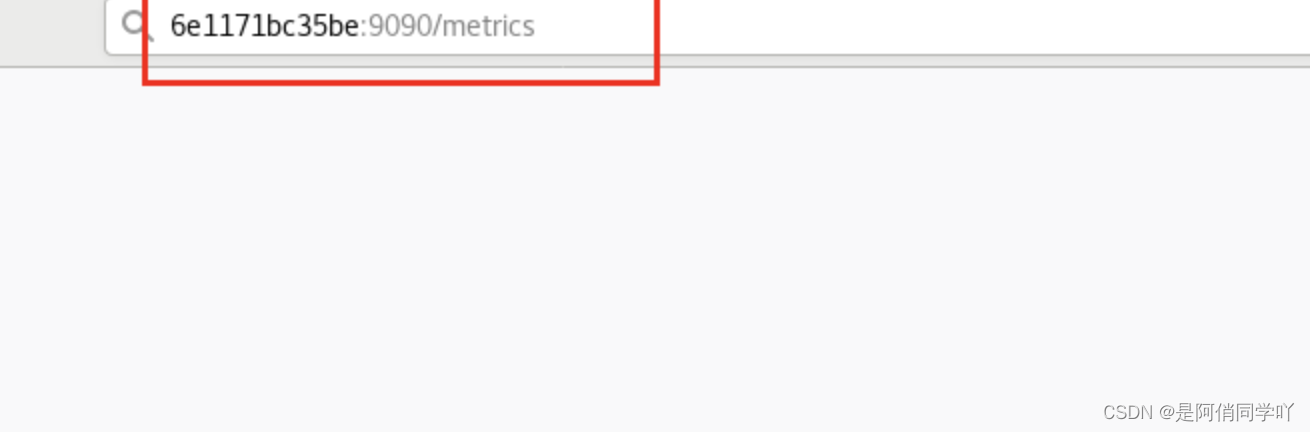
要使用宿主机的IP+端口,就成功解决报错问题啦
- job_name: linux
static_configs:
- targets: ['192.168.31.44':9100']
labels:
instance: linux
启动prometheus(将docker的配置文件映射到部署服务器)
docker run -d \
-p 9090:9090 \
-v /Users/qiao/opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
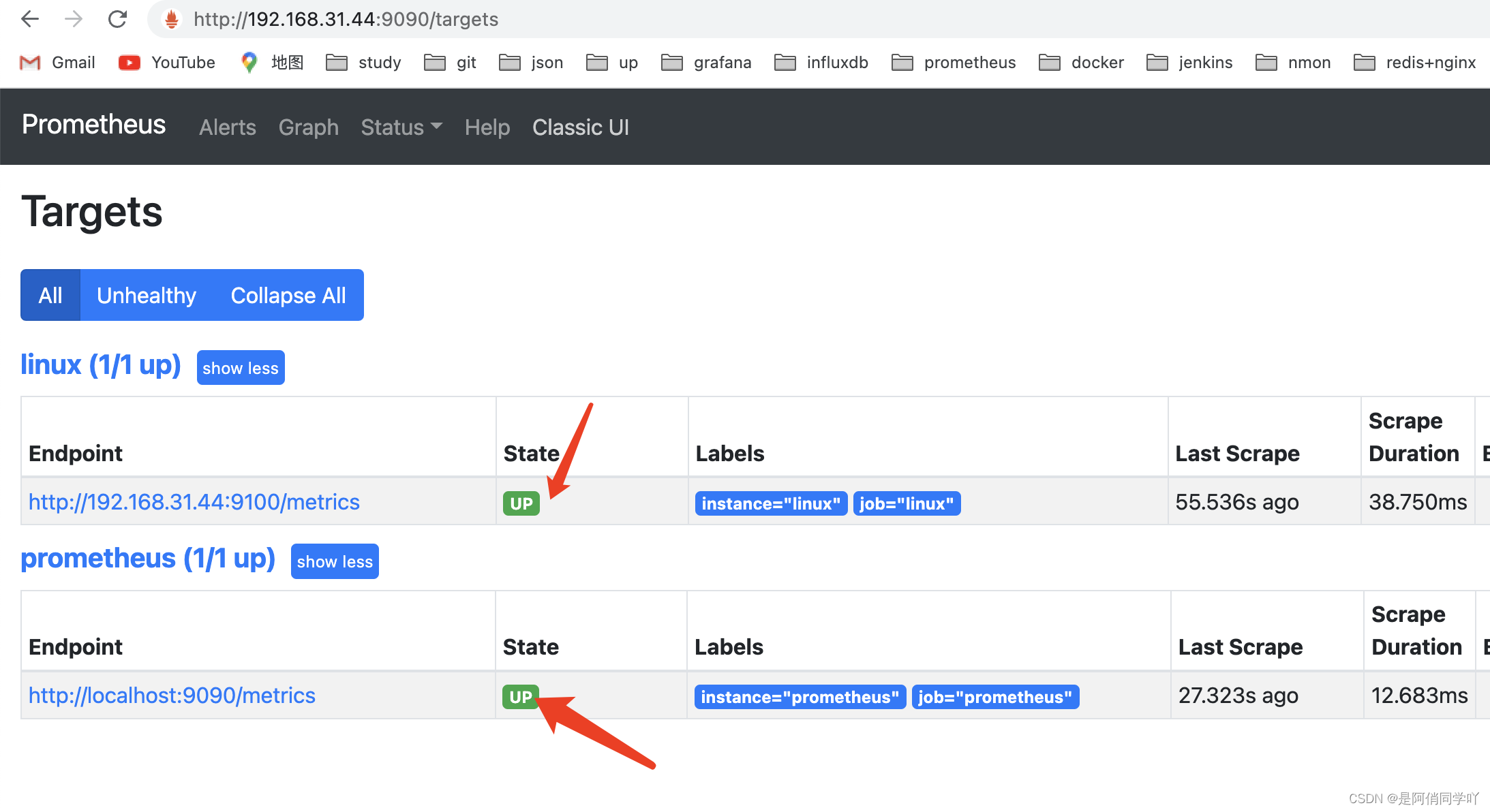
prometheus测试访问地址
http://192.168.31.44:9090/graph
配置 grafana 仪表盘
1.在浏览器访问:http://{ip}:3000/
2.输入用户名/密码:admin/admin登录 ,首次会让你设置密码。如果不设置的话,可以直接点击skip

3.登录之后,会显示下面的页面,点击添加数据源
选择prometheus
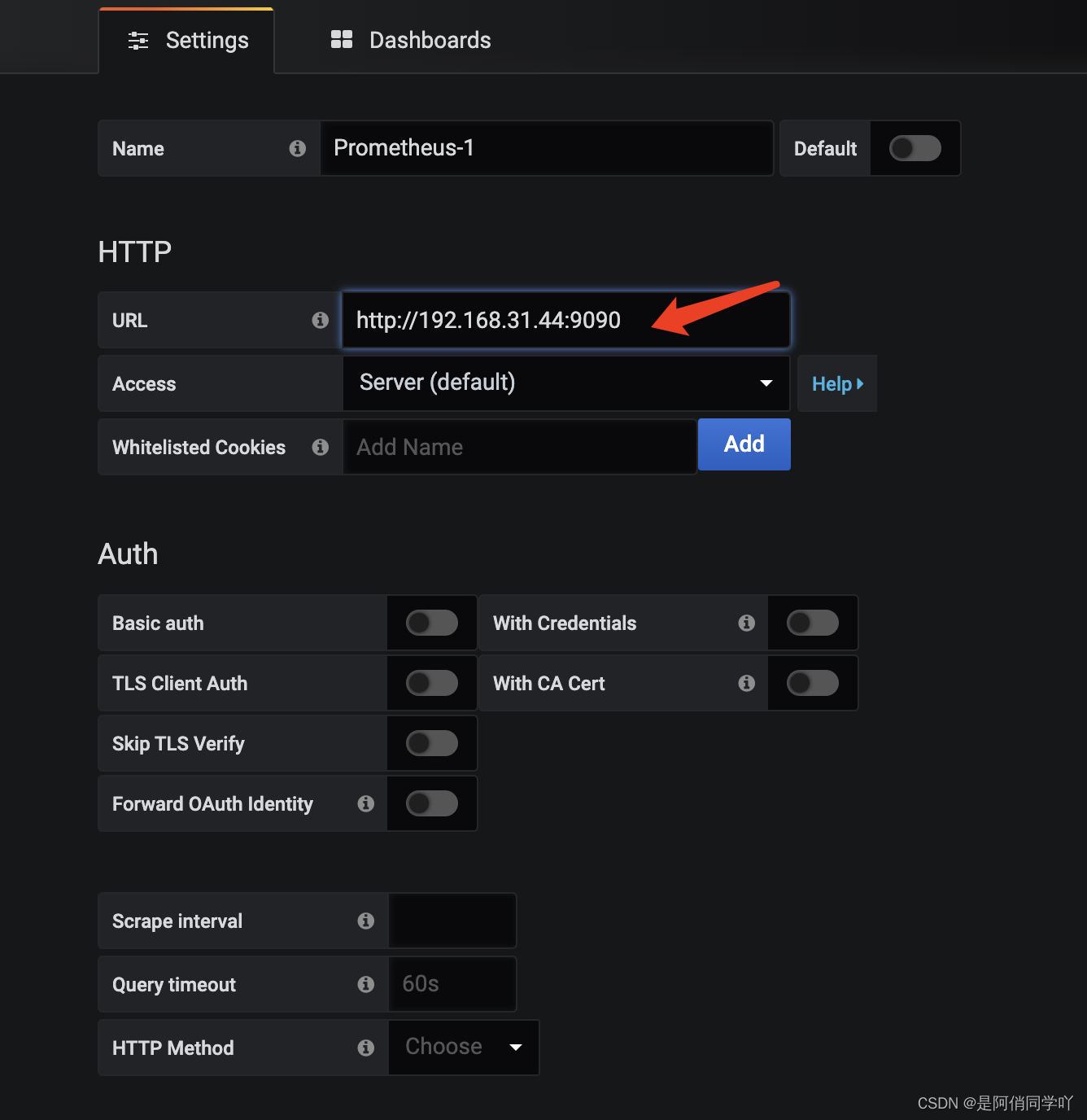
直接添加监控的服务器ip+端口号,我们之前配置的是默认端口9090,添加点击保存即可,其他的都可以不填。
点击左边那个 + ,选择 import,
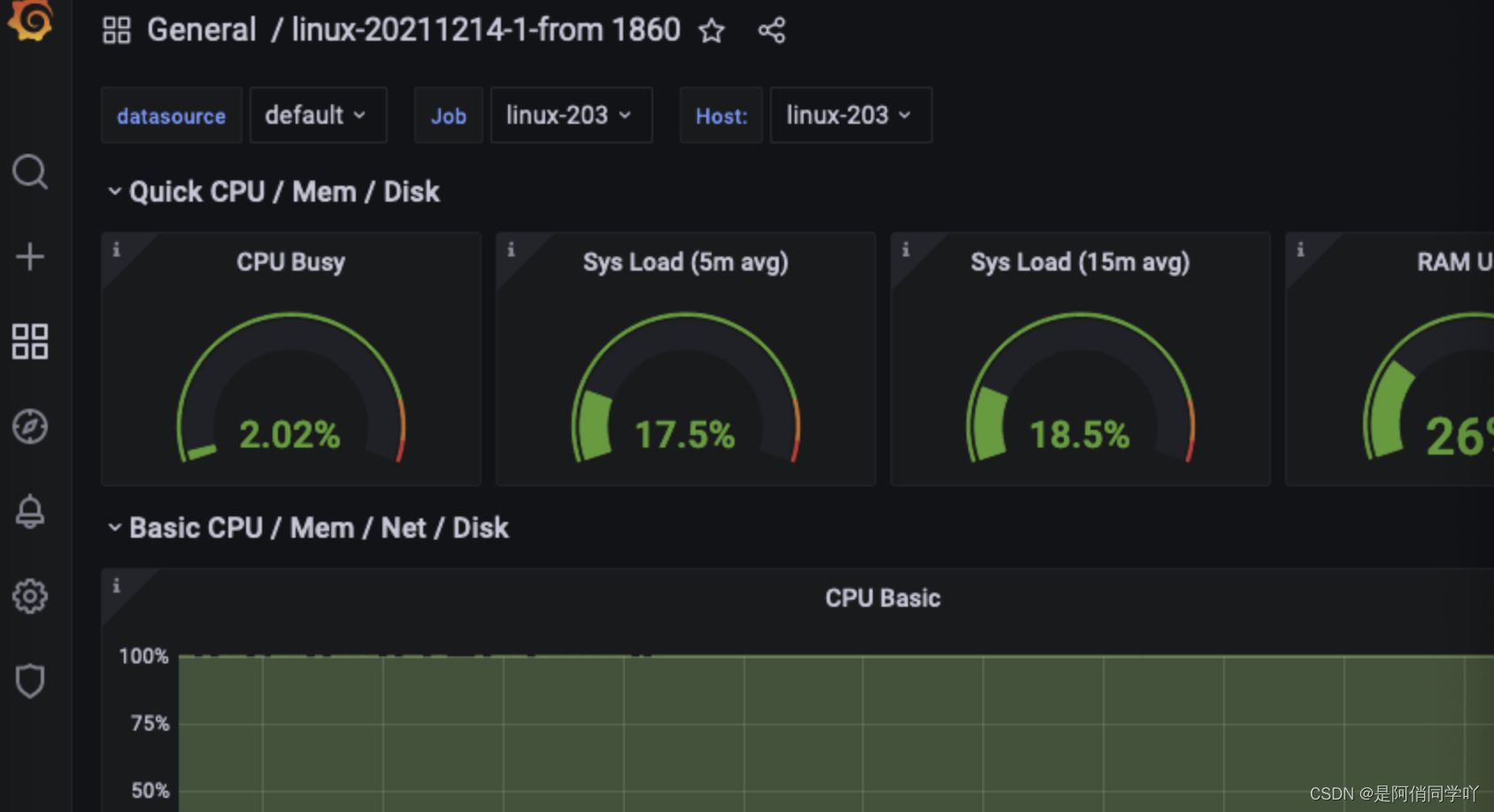
输入一个大家推荐的 dashboard ID : 1860 ,直接 locad ,就可以看到效果了!
 我们也可以导入监控模板
我们也可以导入监控模板
打开 grafana 官网,查找官网提供的 prometheus 监控模板
链接: https://grafana.com/grafana/dashboards.
点击 Linux 服务器监控的中文模板,记录该模板的 id:8919
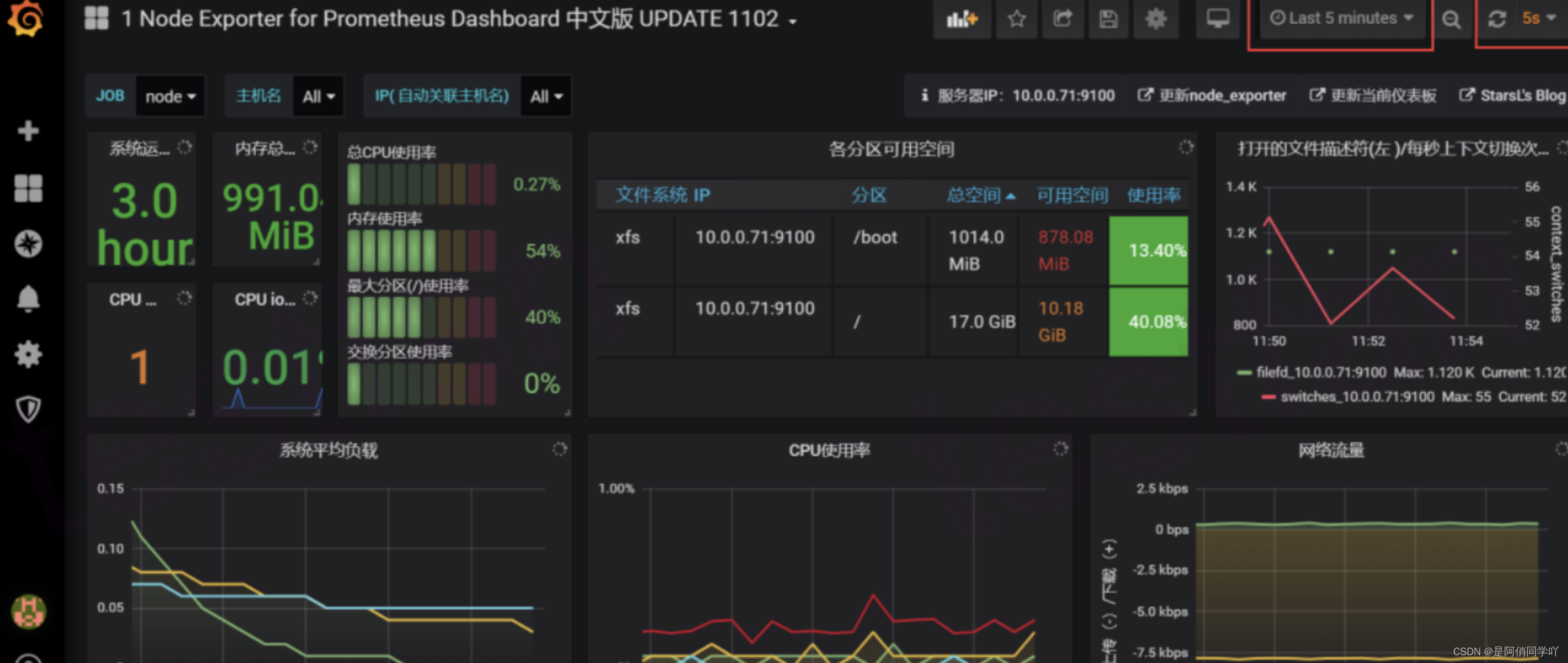
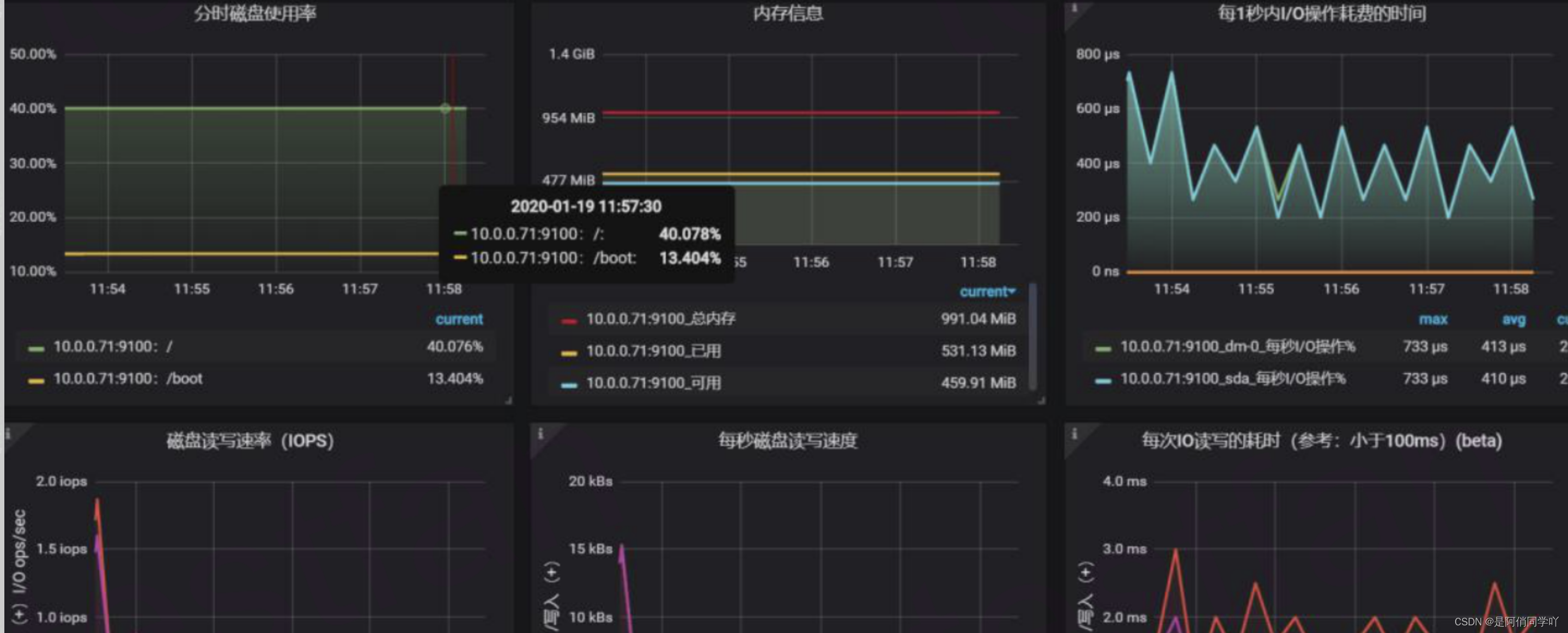
将数据更新频率设置为 5s,展示最近 5 分钟的数据,就可以看到实时的、最近 5 分钟的各项性能指标。包含了 CPU、Load、内存、网络、磁盘、IO 耗时等指标。监控数据永久保存,可以随时查看任意时间点内的历史统计数据,非常方便。
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t