文章目录
随着亚马逊云、阿里云、华为云、腾讯云等云计算服务厂商越来越安全、稳定,以及价格越来越便宜,越来越多的企业或个人开始尝试或正在使用云计算服务厂商提供的IaaS服务替代自建IDC机房中的基础设施资源。面对各个云计算厂商的营销套路,不少企业不知道选哪家云商的服务比较合适,一怕被绑架,上车容易下车难,第一年免费用,第二年没折扣;二怕今年上阿里,明年华为更便宜,后年腾讯更优惠,服务迁移难。如何让业务在不同云商之间随意切换呢?这样就能实现想用哪家的云就选哪家的资源。
下边通过实验的方式尝试一种实现上述诉求的方法,即搭建一套k8s容器集群平台,不同云商上云主机部署工作负载节点,并注册到k8s集群。实现一套容器集群管理多个云商的工作负载节点,于是根据云商的优惠政策,动态的将容器化部署的服务有侧重点的分布到性价比更高的云商上。
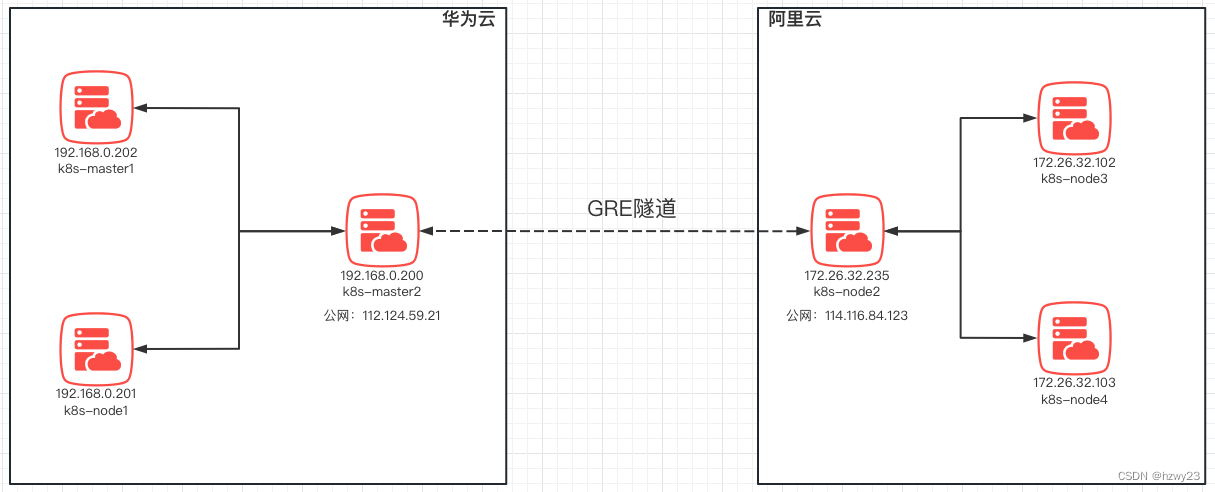
如上图所示,华为云上部署3个节点,阿里云上部署3个节点,其中华为云上 k8s-master1 与 k8s-master2 为 k8s 集群的管理服务,k8s-node1 为 k8s 集群的工作负载节点,阿里云上的 k8s-node2、k8s-node3、k8s-node4 为 k8s 集群的工作负载节点。
通过建立GRE隧道,在华为云 k8s-master2 与阿里云 k8s-node2 节点之间建立 GRE 隧道,打通华为云与阿里云内网通信。同时使用 iptables 设置流量转发规则,例如 k8s-master2 通过设置 iptables 规则将阿里云上的主机对 k8s-master1 与 k8s-node1 的流量进行转发,同理,k8s-node2 通过设置 iptables 规则将华为云上的主机对 k8s-node3 与 k8s-node4 的流量进行转发,从而实现华为云与阿里云上所有主机之间的内网互通。
建立 GRE 隧道的方法请参考 构建GRE隧道打通不同云商的云主机内网 。这篇文章主要介绍了在两个云商之间搭建 GRE 隧道实现两个内网互通的方法。由于使用 route 工具添加的路由并不会持久话的保存(服务器重启将会丢失),所以,本章将会介绍如何搭建 GRE 隧道,并持久话保存。
在阿里云 k8s-node2 节点上执行下边命令
cat > /etc/sysctl.d/gre.conf <<EOF
net.ipv4.ip_forward=1
EOF
在阿里云 k8s-node2 节点上执行下边命令
cat > /etc/init.d/gre.sh <<EOF
#!/bin/bash
ip tunnel del tunnel999
ip tunnel add tunnel999 mode gre remote 112.124.59.21 local 172.26.32.235
ip link set tunnel999 up mtu 1476
ip addr add 192.168.100.2 peer 192.168.100.1/32 dev tunnel999
ip route add 192.168.0.0/24 dev tunnel999
EOF
chmod +x /etc/init.d/gre.sh
cat > /usr/lib/systemd/system/gre.service <<EOF
[Unit]
Description=GRE Service
After=network.target
[Service]
Type=oneshot
User=root
ExecStart=/etc/init.d/gre.sh
[Install]
WantedBy=multi-user.target
EOF
systemctl enable gre
systemctl start gre
在阿里云 k8s-node2 节点上执行下边命令
iptables -t nat -A POSTROUTING -o eth0 -s 192.168.100.1 -j MASQUERADE
iptables -A FORWARD -s 192.168.100.1 -o eth0 -j ACCEPT
iptables -t nat -A POSTROUTING -o tunnel999 -s 192.168.0.0/24 -j MASQUERADE
iptables -A FORWARD -s 192.168.0.0/24 -o tunnel999 -j ACCEPT
在阿里云 k8s-node3 和 k8s-node4 节点上执行下边的命令,添加华为云内网CIDR路由到 k8s-node2 节点内网IP上。
route add -net 192.168.0.0/24 gw 172.26.32.235
添加完成后 k8s-node3 和 k8s-node4 暂时无法访问华为云主机内网IP,等待华为云上安装部署完成后,才可以访问华为云上主机内网IP。
在华为云 k8s-master2 节点上执行下边命令
cat > /etc/sysctl.d/gre.conf <<EOF
net.ipv4.ip_forward=1
EOF
在华为云 k8s-master2 节点上执行下边命令
cat > /etc/init.d/gre.sh <<EOF
#!/bin/bash
ip tunnel del tunnel999
ip tunnel add tunnel999 mode gre remote 114.116.84.123 local 192.168.0.200
ip link set tunnel999 up mtu 1476
ip addr add 192.168.100.1 peer 192.168.100.2/32 dev tunnel999
ip route add 172.26.32.0/24 dev tunnel999
EOF
chmod +x /etc/init.d/gre.sh
cat > /usr/lib/systemd/system/gre.service <<EOF
[Unit]
Description=GRE Service
After=network.target
[Service]
Type=oneshot
User=root
ExecStart=/etc/init.d/gre.sh
[Install]
WantedBy=multi-user.target
EOF
systemctl enable gre
systemctl start gre
在华为云 k8s-master2 节点上执行下边命令
iptables -t nat -A POSTROUTING -o eth0 -s 192.168.100.2 -j MASQUERADE
iptables -A FORWARD -s 192.168.100.2 -o eth0 -j ACCEPT
iptables -t nat -A POSTROUTING -o tunnel999 -s 172.26.32.0/24 -j MASQUERADE
iptables -A FORWARD -s 172.26.32.0/24 -o tunnel999 -j ACCEPT
在华为云 k8s-master1 和 k8s-node1 节点上执行下边命令,添加阿里云内网CIDR路由到 k8s-master2 节点内网IP上。
route add -net 172.26.32.0/24 gw 192.168.0.200
添加完成后就可以在 k8s-node1 和 k8s-master1 节点上访问阿里云上所有云主机的内网IP,并且阿里云上的所有云主机可以访问华为云上所有云主机的内网IP。
首先在华为云上安装部署 kubernetes 集群主节点,具体操作步骤请参考:部署安装kubernetes集群。
在阿里云主机上安装 kubernetes worker 节点配置。主要涉及到:Linux 内核升级,Containerd 容器安装,Linux 参数优化,Kubelet与Kube-Proxy 组件部署。下边操作以阿里云 172.26.32.235 主机为例。
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install containerd
containerd config default > /etc/containerd/config.toml
sandbox_image = "registry.k8s.io/pause:3.6"
替换成
sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = false
替换成
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
添加国内镜像仓库,这个非常关键,否则将会导致镜像下载失败,Pod中服务无法启动。
[plugins."io.containerd.grpc.v1.cri".registry]
......
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
在containerd 配置文件中找到上边内容,并在此处添加下边两行, 注意缩进,下边两行内容与上边一行有2个空格的缩进,下边两行内容之间也存在2个空格的缩进。
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["http://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn","https://registry.docker-cn.com"]
systemctl enable containerd
systemctl restart containerd
Linux 参数优化请参考 K8S安装过程七:Kubernetes 节点配置调整
从华为云已经安装部署好的节点上获取 kubernetes 的安装包。详细过程请参考:K8S安装过程九:Kubernetes Worker 节点安装
scp root@192.168.0.200:/opt/kubernetes.tar.gz /opt/
mkdir -p /etc/kubernetes/ssl
scp root@192.168.0.200:/etc/kubernetes/ssl/* /etc/kubernetes/ssl/
cd /opt
tar -xvf kubernetes.tar.gz
mkdir /opt/kubernetes/manifests
cat > /usr/lib/systemd/system/kubelet.service <<EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf
ExecStart=/opt/kubernetes/server/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
systemctl enable kubelet
systemctl start kubelet
systemctl status kubelet

cat > /usr/lib/systemd/system/kube-proxy.service <<EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf
ExecStart=/opt/kubernetes/server/bin/kube-proxy \$KUBE_PROXY_OPTS
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
systemctl enable kube-proxy
systemctl start kube-proxy
systemctl status kube-proxy

到此,跨越不同云商搭建容器集群完成,此时的容器集群中工作负载节点涵盖了华为云与阿里云。后续添加其他云商的云主机,流程与上述类似。

Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
是否有可能:before_filter:authenticate_user!||:authenticate_admin! 最佳答案 before_filter:do_authenticationdefdo_authenticationauthenticate_user!||authenticate_admin!end 关于ruby-on-rails-before_filter运行多个方法,我们在StackOverflow上找到一个类似的问题: https://
我正在使用Rails3.1并在一个论坛上工作。我有一个名为Topic的模型,每个模型都有许多Post。当用户创建新主题时,他们也应该创建第一个Post。但是,我不确定如何以相同的形式执行此操作。这是我的代码:classTopic:destroyaccepts_nested_attributes_for:postsvalidates_presence_of:titleendclassPost...但这似乎不起作用。有什么想法吗?谢谢! 最佳答案 @Pablo的回答似乎有你需要的一切。但更具体地说...首先改变你View中的这一行对此#
我收到格式为的回复#我需要将其转换为哈希值(针对活跃商家)。目前我正在遍历变量并执行此操作:response.instance_variables.eachdo|r|my_hash.merge!(r.to_s.delete("@").intern=>response.instance_eval(r.to_s.delete("@")))end这有效,它将生成{:first="charlie",:last=>"kelly"},但它似乎有点hacky和不稳定。有更好的方法吗?编辑:我刚刚意识到我可以使用instance_variable_get作为该等式的第二部分,但这仍然是主要问题。