本文以演进方向和目的为线索梳理了一些我常见到但不是很熟悉的预训练语言模型,首先来看看“完全版的BERT”:RoBERTa: A Robustly Optimized BERT Pretraining Approach(2019)可看成是完全体的BERT,主要3方面改进,首先采用了 Dynamic mask,即每个文本进入训练时动态 mask 掉部分 token,相比原来的 Bert,可以达到同一个文本在不同 epoch 被 mask 掉的 token 不同,相当于做了一个数据增强。其次,不使用 NSP 任务,效果会有一定提升。最后,RoBERTa 增大了训练时间和训练数据、 batch size 以及对 BPE(输入文本的分词方法)进行了升级。
接下来从不同思路的演进方向介绍一下各种改进的预训练语言模型。
想做大统一的模型可以从两方面着手,第一是任务混合,第二是结构混合。
任务混合指将NLU和NLG同时进行预训练,比如XLNet、MPNet采用的Permutaioon language modeling,兼顾上下文与自回归;或者是UniLM, GLM采用的Multi-task training,通过对注意力矩阵的设计使得这两种任务同时训练。
结构混合则更多使用Seq2seq去做理解和生成。比如MASS、T5和BART。但也面临如下挑战:
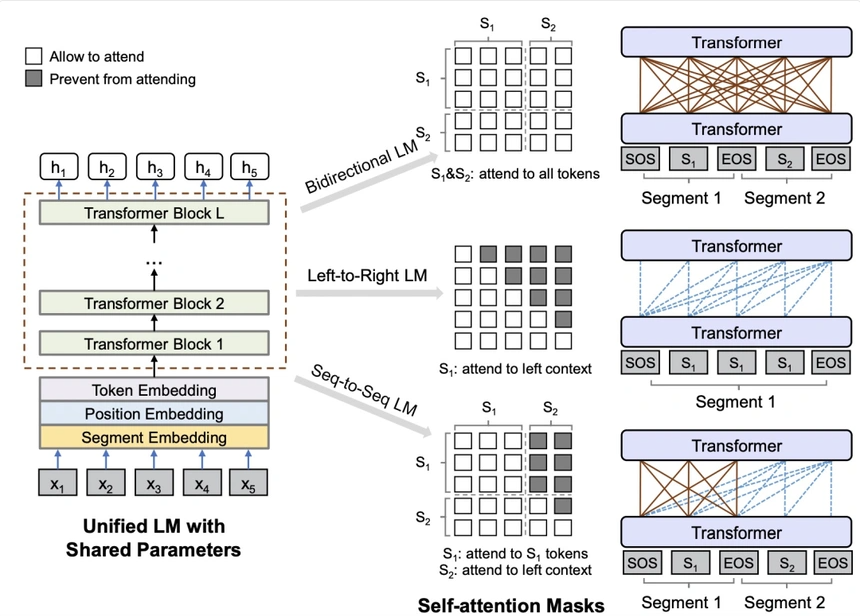
Unified Language Model Pre-training for Natural Language Understanding and Generation(NIPS 2019)提出了UniLM预训练语言模型。本文认为EMLo采用前向+后向LSTM、GPT采用从左至右的单向Transformer、BERT采用双向Attention都有优缺点。UniLM融合了3种语言模型优化目标,通过控制mask在一个模型中同时实现了3种语言模型优化任务,在pretrain过程交替使用3种优化目标。下图比较形象的描述了UniLM是如何利用mask机制来控制3种不同的优化任务,核心思路是利用mask控制生成每个token时考虑哪些上下文的信息。
XLNet: Generalized Autoregressive Pretraining for Language Understanding(NIPS 2019)提出了XLNet模型,融合了BERT和GPT这两类预训练语言模型的优点,并且解决了BERT中pretrain和finetune阶段存在不一致的问题(pretrain阶段添加mask标记,finetune过程并没有mask标记)。XLNet融合了AR模型(类GPT,ELMo)和AE模型各自的优点,既能建模概率密度,适用于文本生成类任务,又能充分使用双向上下文信息。XLNet实现AR和AE融合的主要思路为,对输入文本进行排列组合,然后对于每个排列组合使用AR的方式训练,不同排列组合使每个token都能和其他token进行信息交互,同时每次训练又都是AR的。
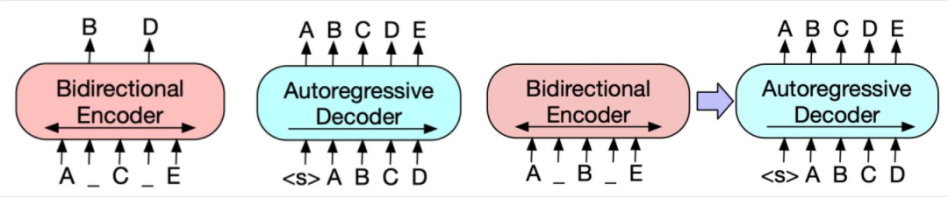
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension(2019)提出了一种新的预训练范式,包括两个阶段:首先原文本使用某种noise function进行破坏,然后使用sequence-to-sequence模型还原原始的输入文本。下图中左侧为Bert的训练方式,中间为GPT的训练方式,右侧为BART的训练方式。首先,将原始输入文本使用某些noise function,得到被破坏的文本。这个文本会输入到类似Bert的Encoder中。在得到被破坏文本的编码后,使用一个类似GPT的结构,采用自回归的方式还原出被破坏之前的文本。
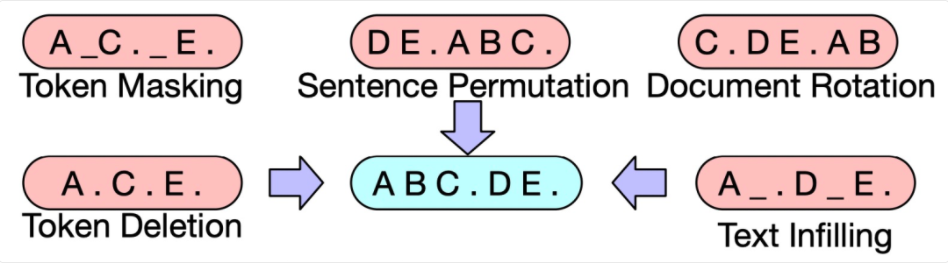
文中尝试了多种类型的noise function,如token masking、sentence permutation、text infilling等,其中sentence permutation+text infilling的方式取得了最好的效果。Text infilling指的是随机mask某些span。下图展示了文中提出的一些noise function方法。
为了模拟决策能力、逻辑推理能力、反实时推理能力(复盘)。需要模型有短时记忆与长期记忆,短时记忆用来决策和推理,长期记忆用来回忆事实和经验。
像Transformer-XL, CogQA, CogLTX这类模型,就是增加了Maintainable Working Memory,通过样本维度的记忆提升长距离理解能力,实现推理;REALM, RAG这类模型则是对语料、实体或者三元组进行记忆,具有Sustainable Long-Term Memory,将信息提前编码,在需要的时候检索出来。
BERT-Chinese-wwm利用中文分词,将组成一个完整词语的所有单字同时掩盖。ERNIE扩展了中文全词掩盖策略,扩展到对于中文分词、短语及命名实体的全词掩盖。SpanBERT采用了几何分布来随机采样被掩盖的短语片段,通过Span边界词向量来预测掩盖词
ERNIE: Enhanced Representation through Knowledge Integration(2019)ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding(2019)同名工作,主要关注用外部知识辅助设计预训练任务,v1设计了entity-level的MLM任务,mask掉的不是单个token,而是输入文本中某个entity对应的连续多个token;v2引入了更多task(如v1的entity-level mask、Capitalization Prediction Task、Token-Document Relation Prediction Task等),采用continual multitask learning的方式不断构造新的任务,并且以增量的方式进行多任务学习,每来一个任务都把历史所有任务放到一起进行多任务学习,避免忘记历史学到的知识。
ELECTRA引入替代词检测,来预测一个由语言模型生成的句子中哪些词是原本句子中的词,哪些词是语言模型生成的且不属于原句子中的词。
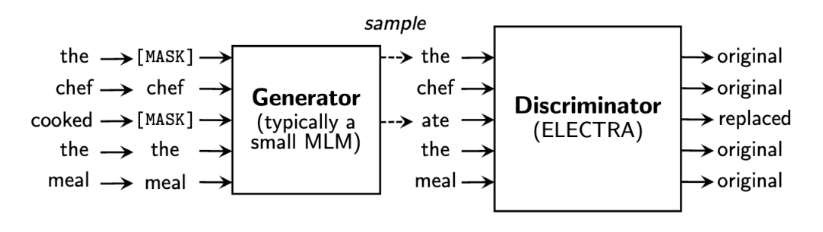
ELECTRA 使用一个小型的 MLM 模型作为生成器(Generator),来对包含[MASK]的句子进行预测。另外训练一个基于二分类的判别器(Discriminator)来对生成器生成的句子进行判断。
预训练模型可以从大量语料中进行学习,但知识图谱、领域知识不一定能学到。
对于这个问题可以有两种解决方案,一种是外挂型,把知识通过各种方法和文本一起输入进去,比如清华ERNIE、K-BERT,另一种是强迫型,在领域数据、结构化文本上精调,让模型记住这些知识,比如百度ERNIE、WWM。
K-BERT通过嵌入实体关系知识使用外部知识,实体关系三元组是知识图谱的最基本的结构,也是外部知识最直接和结构化的表达。K-BERT从BERT模型输入层入手,将实体关系的三元组显式地嵌入到输入层中。
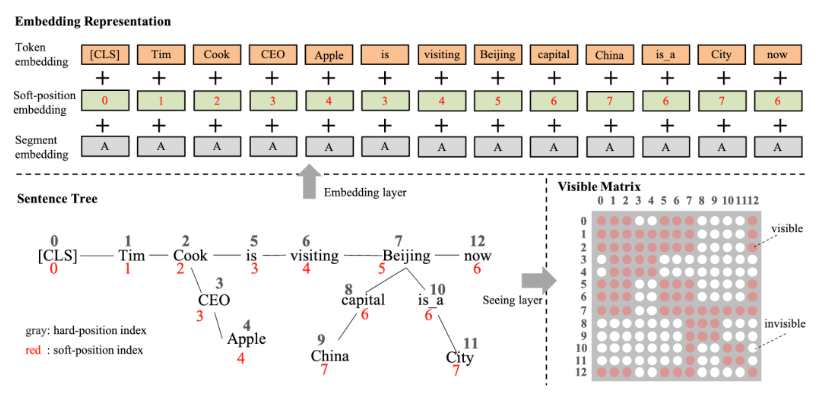
SemBERT则使用特征向量拼接的方式融合外部知识,SemBERT使用语义角色标注(Semantic Role Labeling)工具,获取文本中的语义角色向量表示,与原始BERT文本表示融合。
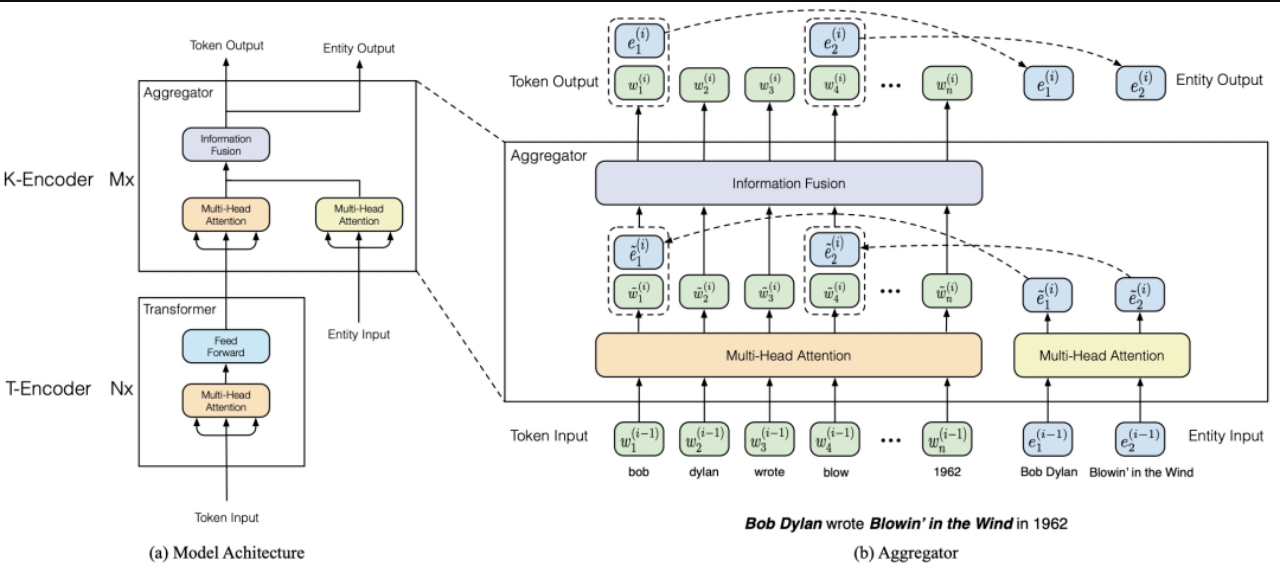
ERNIE: Enhanced Language Representation with Informative Entities(2019)则用训练目标融合知识,以DAE的方式在BERT中引入了实体对齐训练目标,WKLM通过随机替换维基百科文本中的实体,让模型预测正误,从而在预训练过程中嵌入知识。引入知识图谱对BERT进行优化,模型主要分为T-Encoder和K-Encoder两个部分。T-Encoder类似BERT,K-Encoder识别输入文本中的实体并获取这些实体的embedding,然后融合到输入文本的对应token位置。每层都会融合上一层的token embedding和entity embedding。此外,ERNIE在预训练阶段增加了token-entity relation mask任务,在20%的entity上,会mask掉token和entity的对齐关系,让模型来预测当前token对应的是哪个entity。
参数共享、模型剪枝(可以修剪head或者砍掉层)、知识蒸馏、模型量化(FP16等,低比特模型跟硬件强相关,很难泛化)
ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS(2020)提出了一个轻量级的Bert模型,以此降低Bert的运行开销,本文主要提出了两个优化:首先是Factorized embedding parameterization,即对输入的embedding进行分解,原始的Bert将token输入的embedding维度E和模型隐藏层维度H绑定了,即E=H,本文提出可以让E和H解绑,将E变成远小于H的维度,再用一层全连接将输入embedding映射到H维。这样模型embedding部分参数量从\(V*\)\(*H*\)下降到了\(*V*\)\(*E+E*H\)。Cross-layer parameter sharing。前者Cross-layer parameter sharing让Bert每层的参数是共享的,以此来减小模型参数量。除了上述两个降低Bert运行开销的优化外,ALBERT提出了inter-senetnce loss这一新的优化目标。原来Bert中的NSP任务可以理解为topic prediction和coherence prediction两个任务。其中topic prediction是一种特别简单的任务,由于其任务的简单性,导致coherence prediction学习程度不足。本文提出将coherence prediction单独分离出来,相比Bert,正样本仍然是一个document相邻的两个segment,负样本变成这两个segment的顺序交换。
DistilBERT在预训练阶段蒸馏,其学生模型具有与BERT结构,但层数减半。
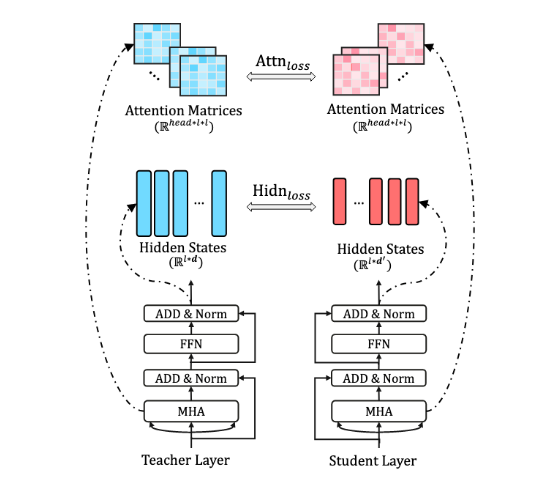
TinyBERT为BERT的嵌入层、输出层、Transformer中的隐藏层、注意力矩阵都设计了损失函数,来学习 BERT 中大量的语言知识。
BERT之前的跨语言学习主要有两种方法:
有了预训练方法之后,我们就可以在不同语言进行预训练了。mBERT在Wiki数据上进行多语言的MLM,之后XLM-R用了更好的语料后表现有所提升。但这两个模型都没有利用平行语料,于是XLM同时利用了平行语料,在平行语料做MLM,利用另一个语言的知识预测mask token。
后续研究还有Unicoder、ALM、InfoXLM、HICTL、ERNIE-M等,生成任务则有mBART、XNLG。
https://mp.weixin.qq.com/s/NA29niCVDq1WD1vlwqTd_g
https://zhuanlan.zhihu.com/p/381282229
https://arxiv.org/abs/2106.07139
https://mp.weixin.qq.com/s/HmuHx1TH3gkASROGjJxOmA
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/