PCL作为目前最为强大的点云库,内部存在有大量集成好的算法。而对于数据量大、非同源、含大量噪声且部分重叠的激光点云与影像重建点云,其稀疏程度、噪声程度等不同,非重叠区域的面积很大。真实场景的点云尤其是影像重建点云噪声较多,提取的法向量误差也很大,有的时候NDT和ICP并不能形成良好的匹配,这个时候我们该怎么样评估通过IPC或NDT算出的变换矩阵来估算出算法的精度呢?这个时候就需要通过均方根误差以及重合度来综合评判结果了。
Cloudcompare是一个开源的免费点云处理软件,可以实现常用的点云处理功能,使用也是简单方便。官网网址为http://www.cloudcompare.org/,由于其良好的可视化,这里我们来从这个软件开始,向读者来介绍配准的一些基础概念。
首先,我们打开安装好的cloudcompare,打开要配准的点云文件。这里使用斯坦福的兔子点云。
选中45°点云,改变颜色(edit–>colors–>set unique,或者快捷键alt+c)

选中两个点云,点击配准按钮,参考点云(reference)选择0°,重叠度改成70%(不同数据视情况而定,这里目测70%重叠差不多),精度(RMS difference)没改变。
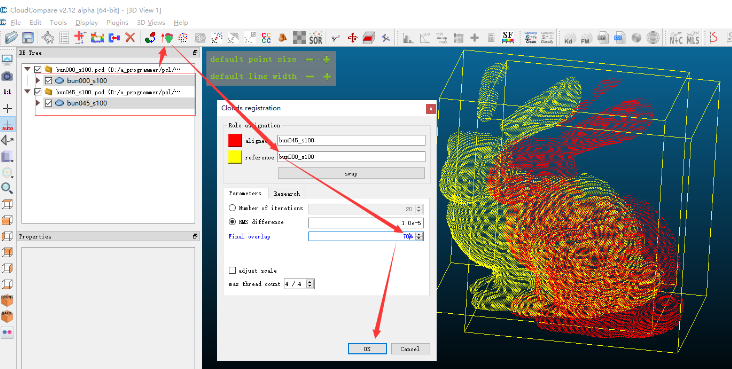
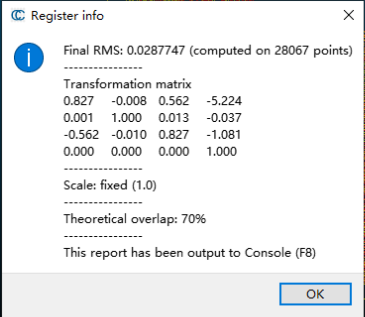
此时,我们就可以快捷的拿到我们想要的配准结果了。在上面我们注意到在Cloudcompare中提到了两个重要的概念,分别是重叠度和精度(均方根误差)。而这也是我们下面文章中主要介绍的内容。
下面这部分的内容是计算方根误差的,其中内部主要是通过kd-tree完成了dist的搜索,从而计算出最近邻匹配点对欧氏距离的平方,并最终拿到我们的RMSE,从而评判出点云的重合性。
float caculateRMSE(pcl::PCLPointCloud2::Ptr& cloud_source, pcl::PCLPointCloud2::Ptr& cloud_target)
{
pcl::PointCloud<pcl::PointXYZ>::Ptr xyz_source(new pcl::PointCloud<pcl::PointXYZ>());
fromPCLPointCloud2(*cloud_source, *xyz_source);
pcl::PointCloud<pcl::PointXYZ>::Ptr xyz_target(new pcl::PointCloud<pcl::PointXYZ>());
fromPCLPointCloud2(*cloud_target, *xyz_target);
float rmse = 0.0f;
pcl::KdTreeFLANN<pcl::PointXYZ>::Ptr tree(new pcl::KdTreeFLANN<pcl::PointXYZ>());
tree->setInputCloud(xyz_target);
for (auto point_i : *xyz_source)
{
// 去除无效的点
if (!pcl_isfinite(point_i.x) || !pcl_isfinite(point_i.y) || !pcl_isfinite(point_i.z))
continue;
pcl::Indices nn_indices(1);
std::vector<float> nn_distances(1);
if (!tree->nearestKSearch(point_i, 1, nn_indices, nn_distances)) // K近邻搜索获取匹配点对
continue;
/*dist的计算方法之一
size_t point_nn_i = nn_indices.front();
float dist = squaredEuclideanDistance(point_i, xyz_target->points[point_nn_i]);
*/
float dist = nn_distances[0]; // 获取最近邻对应点之间欧氏距离的平方
rmse += dist; // 计算平方距离之和
}
rmse = std::sqrt(rmse / static_cast<float> (xyz_source->points.size())); // 计算均方根误差
return rmse;
}
// ---------------------------计算均方根误差------------------------------
//auto Rmse= caculateRMSE(cloud_source, cloud_target);
//cout << "配准误差为:" << Rmse << endl;
下面的代码提供了两种方法计算匹配的区域的点云的重合率,分别使用CorrespondenceEstimation以及kd-tree来实现了点云重合率的计算,当然现在的PCL算法已经自带了均方误差以及变换矩阵和当前变换矩阵的差性等情况,但是这也不妨碍我们通过RMSE以及重合率来单帧分析问题所在
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
如何正确使用git差异来计数:添加,修改,删除和每个文件的总文件行?另外,我需要忽略空白和评论行。看答案您可以通过:gitdiff--stat以及快速的历史概述:gitlog--stat
catalogue关键字一些符号和特殊表示预备知识正文(一)不确定系统的数学表示(二)线性时不变定常系统的LMI稳定性定理(判据)2.1系统模型2.2当u=w=0时系统的LMI稳定性判据2.3.当u=0,w!=0时的保H无穷性能定理(三)多面体模型表示的不确定系统在不同工况下的稳定性定理3.1不确定系统模型的多面体表达式3.2参数无关的鲁棒状态反馈控制率:u=kx3.2.1闭环系统鲁棒稳定性3.2.2闭环系统鲁棒稳定性、保H无穷性能3.3参数相关的鲁棒状态反馈控制率:u=ai*ki*x3.3.1.状态反馈控制下的闭环系统鲁棒稳定性定理(w=0)3.3.2.状态反馈控制下的保H无穷性能、闭环系统
聚合操作,在es中的聚合可以分为大概四种聚合:bucketing(桶聚合)mertic(指标聚合)matrix(矩阵聚合)pipeline(管道聚合)bucket类似于分类分组,按照某个key将符合条件的数据都放到该类别的组中mertic计算一组文档的相关值,比如最大,最小值matrix根据多个key从文档中提取值生成矩阵,这个操作不支持脚本(script)pipeline将其他聚合的结果再次聚合输出聚合是支持套娃(嵌套)操作的,你可以在聚合的结果上接着进行聚合操作,es是不限制聚合的深度的。本篇笔记目录如下:指标聚合的基本结构平均值聚合去重统计聚合统计汇总最大值、最小值聚合百分位统计百分位排
性能指标一、性能测试指标性能测试是通过测试工具模拟多种正常、峰值及异常负载条件来对系统的各项性能指标进行测试。目的:验证软件系统是否能够达到用户提出的性能指标,发现系统中存在的性能瓶颈并加以优化。二、指标分为两大类:软件指标:术语释义TPS:(每秒事务数)在每秒时间内系统可处理完毕的事务数。TPS很大程度体现系统性能能力。TPS(TransactionPerSecond)是指单位时间(每秒)系统处理的事务量。事务可以是用户自定义的一系列操作或者动作的集合,比如“用户注册“事务是点击注册按钮,填写用户注册信息,点击提交按钮,以及加载注册成功页面的动作集合。这3个个公式都是对的第1个公式计算的是绝
我需要用JavaScript(我使用的是jQuery)编写一个函数,该函数知道适合浏览器窗口一行的字符数。我正在使用等宽字体来缓解这个问题,但如果我将它概括为不同的字体会更好。我如何知道在浏览器中有多少字符会填满一行?目的是计算填充一行的字符数。 最佳答案 您可以创建元素并向其附加字符,直到您检测到换行,例如通过观察offsetHeight的变化(您可以使用二分法对其进行优化)。这当然非常依赖于浏览器、系统、安装的字体和用户的设置,因此每次显示页面、调整大小或用户更改字体大小时(甚至整页缩放),您都必须为每个文本片段计算它引入了一些
我知道一点BaconJS,但现在我正尝试通过创建“用户正在输入...”指示器来学习RxJS。这很简单,可以用两个简单的规则来解释:当用户输入时,指示符应该立即可见。当用户停止打字时,指示器应在用户最后一次打字后1秒内仍然可见。我不确定这是否正确,但到目前为止我已经创建了两个流:每秒发出一个0的心跳流。用于捕获用户键入事件并为每个事件发出1的流。然后我将它们合并在一起,然后简单地利用结果。如果它是1,那么我会显示指示器。如果它是0,那么我会隐藏指示器。这是它的样子:constshowTyping=()=>$('.typing').text('Useristyping...');const
我想知道是否有人知道在BigQuery中衡量字符串相似性的方法。似乎是一个很好的功能。我的情况是我需要比较两个url的相似性,因为我想相当确定它们指的是同一篇文章。我可以找到examplesusingjavascript所以也许UDF是可行的方法,但我根本没有使用UDF(或javascript就此而言:))只是想知道是否可以使用现有的正则表达式函数,或者是否有人可以帮助我开始将javascript示例移植到UDF中。非常感谢任何帮助,谢谢编辑:添加一些示例代码所以如果我有一个UDF定义为://distancefunctionfunctionlevenshteinDistance(row
我目前正在研究任何方法来收集一些关于客户端机器性能的分析/指标到我们的网络应用程序。该应用程序大量使用ajax,我们希望收集一些有关客户端机器运行情况的统计数据。我们不一定要在整个应用程序中放置性能监控代码(出于多种原因,这可能无论如何都不可行)。相反,我们希望能够在用户提交反馈时运行某种测试或其他东西,让我们了解他们的浏览器/计算机的性能如何。研究这件事有点棘手,因为它不断引发关于分析等的讨论。这显然很有用,但仅在一定程度上,因为我们的开发机器已被大量压倒。我们希望获得一些关于我们的客户正在连接的机器种类的指标。是否存在任何类型的库/框架或最佳实践?到目前为止,我最好的办法是通过JS
设置在EC2实例上运行的CloudWatch代理向CloudWatch报告审计日志。CloudWatch中的指标筛选器会在报告日志时为成功登录、失败登录等创建指标。问题通过指标筛选器创建的指标不会分配维度,因此我无法通过InstanceId查询CloudWatch来获取一组指标统计信息。这将非常有用,因为我想知道每台机器而不是每个日志组的审计指标。评论使用put-metric-data命令附加维度非常简单。我能够使用InstanceId的维度标记指标,然后使用get-metric-statistics仅检索这些指标。使用指标过滤器+CloudWatch代理设置是否无法实现这种功能?可能