操作系统的核心功能就是管理计算机硬件,而CPU就是计算机中最核心的硬件。而通过学习笔记3的简史回顾,操作系统通过多进程图像实现对CPU的管理。所以多进程图像是操作系统的核心图像。
参考资料:
要想管理CPU,就要知道如何使用CPU。
CPU的工作原理已经很熟悉:
所以,管理CPU最直观的方法就是,设置PC的初值,CPU就能按照规则依次执行下去。
这一点在计组实验的前四周手摇实验室设备进行指令执行,也可以有类似的印象。
这样做有什么问题?
来看下面一段程序
int main(int argc,char* argv[]){
int i,to,*fp,sum=0;
to = atoi(agv[1]);
for(i = 1; i <=to; i++){
sum = sum + i;
fprintf(fp,"%d",sum);
}
}
如果要让CPU工作,就是要让PC指向这段程序的起始地址。
但是!程序和程序之间是不一样的。例如将fprintf()替换为其他计算语句
fprintf()是一个IO指令,而替换为计算语句则成为计算指令
替换前后的运行时长进行比较,则前者:后者≈106:1
说明,IO特别慢
而假设我们遇到一种程序,有106个计算指令,然后一条IO指令,如果还是按照上面所说的设置PC初值,让其自动执行,那么对于CPU来说,其忙碌的计算指令只占到了总时长的一半(另一半在等待IO),利用率不高。
而如果IO语句再多一点,CPU利用率就更低了。
怎么办?
举一个烧水的例子,首先往烧水壶里倒水,然后放在插座上,然后就可以去做别的事情了,等烧水壶响了,这就是中断,这时我们就可以来用烧水壶里的热水了,烧水的过程就类似IO
所以解决方案为:多道程序交替执行,一个CPU上交替执行多个程序,即并发
这样一道程序执行到像IO这样慢的步骤时,CPU切换到另一个程序进行,而另一个程序进入等待后,再切换回来。
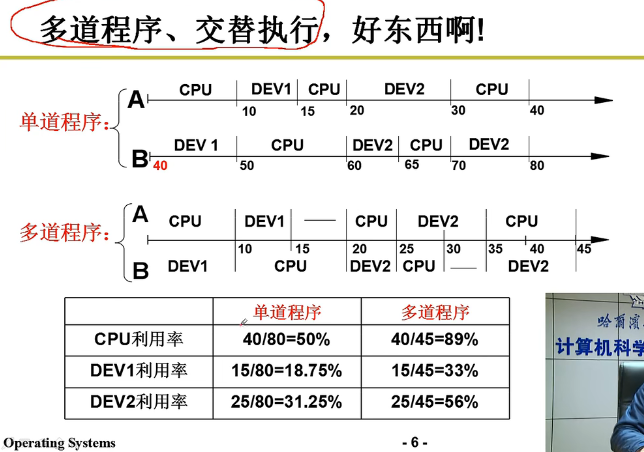
可见,上图两个程序A、B充分利用了CPU的计算资源,总时长从80降到了45.
注意两个名词:并行和并发:
并行多人同时工作,并发一个人交替工作。
并且这里一个隐含条件是切换程序的开销要小于运行程序的开销。
如何实现并发呢?
即控制 PC 进行切换
适当的时候修改PC,使得PC指向另一个程序的指令,但是只修改PC会有问题
例如下图左右两个程序,当PC按照逻辑切换回地址53继续程序1的执行,那么ax和bx寄存器应当存储什么值?
很显然,如果要继续程序1,当然应当为1 和 1,而不是 10 和 10.
所以当程序切换时,除了切换PC,还要切换很多内容
我们需要记录 切换前的上下文,保护现场。
每个程序有一个存放信息的结构:PCB,process control block,进程控制块。
就像我们正在看书,突然被人叫走做别的事,我们就应当停下来,记录当前页码以及故事情节,然后离开,这样回来后才能继续阅读。
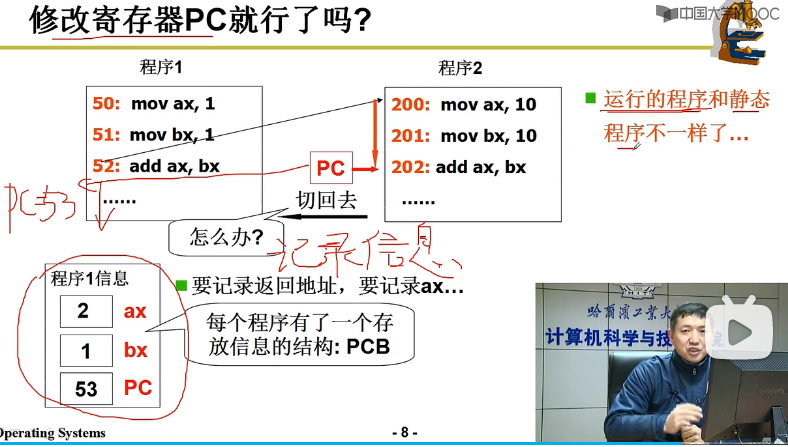
这样,我们实际运行过程中的程序,就跟我们单纯汇编得到的代码不一样了。即运行程序和静态程序不一样。
不同之处简单来说就在于需要PCB来记录程序运行起来的样子。
而程序 + 所有这些不一样 ---> 进程
如何描述这种不同呢?
!进程! 这个概念就用来刻画运行中的程序。比如上图中的程序1 和程序2,就是两个进程。
也即进行中的程序,名字其实很形象。
- 进程有开始、结束,程序没有;
- 进程会走走停停,是动态的,有状态的,而程序没有;
- 进程需要记录ax,bx..... 程序不用;
到这里,我们进程描述CPU的管理:
使用CPU:启动一个进程,让CPU去执行这个进程;
更高效的使用CPU:启动多个进程,让CPU去执行多个进程;
跑多个程序/进程的样子,就是CPU管理的核心样子。
这就是多进程图像。
前文讲到,为了让CPU更好的工作,我们需要让CPU执行多进程,而这个过程如何表征呢?
多进程图像从开机一直存在到关机结束。
系统启动时,最后启动的 main.c 中最后执行了fork()
if(!fork()){init();}
// fork,启动进程的接口
代码意思是:启动一个进程,执行init() ,即执行 shell,接下来就能再 shell 里操作,这就是计算机提供给用户使用的界面(初代版本)。
可以理解为,操作系统要让用户使用计算机,需要创建一个初始化的进程。
补充1:
shell是一个子进程,父进程(main函数)因为成功创建子进程,所以fork()>0 不进
init而子进程fork()==0 进入init,启动shell补充2:
fork()函数返回值是0或1, 返回0代表当前进程是新fork出来的子进程, 非零(也就是为1)代表当前进程为父进程, if条件里的就是父进程的逻辑,一直等待用户输入命令, 然后执行, 一直重复进行
shell 再根据用户输入启动其他进程,执行用户的命令也是在创建进程;
// shell 的核心代码
int main(){
while(1){
scanf("%s",cmd);
if(!fork()){
exec(cmd);
wait();
}
}
}
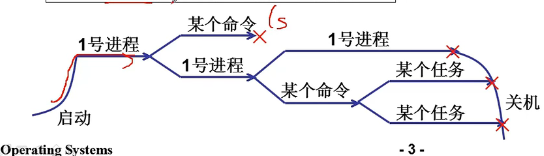
此后,计算机每执行一个任务,就开启一个进程。
在 win10 以上版本中,Ctrl + Shift + Esc 就可看到任务管理器。
为了实现多进程图像,操作系统都应该解决哪些问题?
- 多进程如何组织?
- 多进程如何切换?
- 多进程交替时,如何相互影响?
多进程如何组织?也即多进程如何存放?
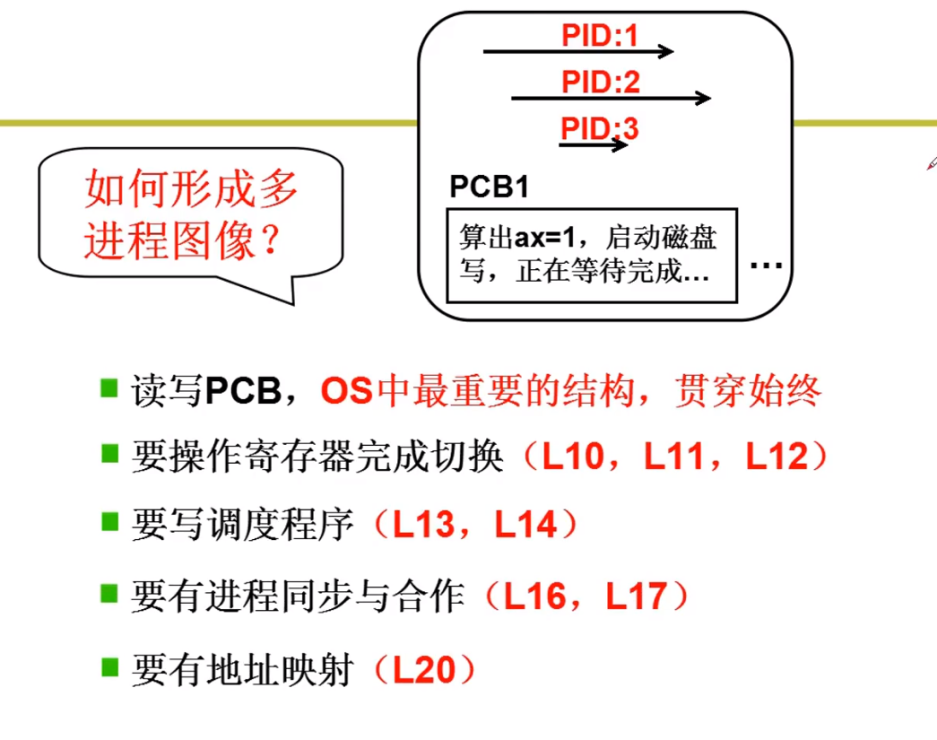
操作系统感知进程依赖于PCB,组织和存放进程也靠PCB,通过PCB形成一些数据结构(队列),来组织多进程;如下图:
PCB在这里相当于结构体,组成数据结构的基本单位。
组织好多进程,才能合理推进多进程。
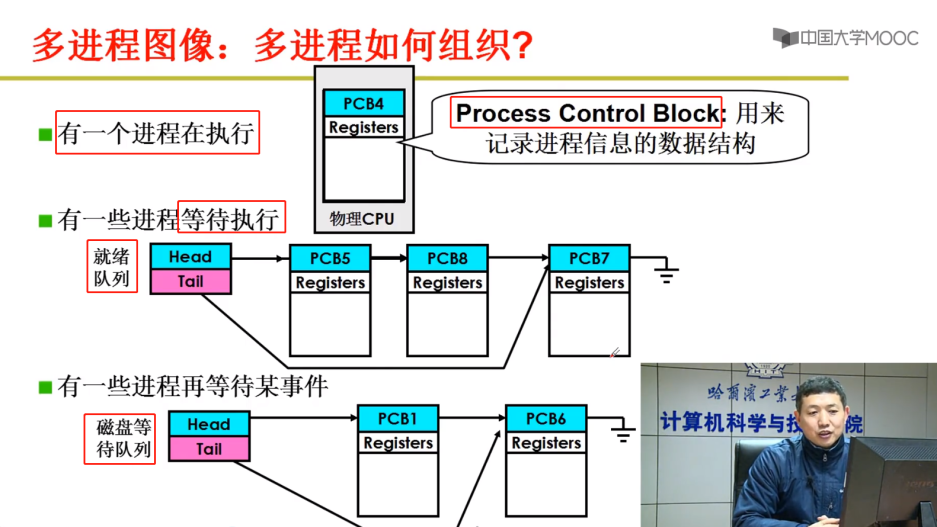
如何推进多进程?
一个进程正在执行
另一些进程在排队(就绪队列)等待执行
还有一些在等待触发事件,即使排到也不能调度执行
比如上图中的第三列PCB,在等待磁盘操作。
PCB是用来记录进程信息的数据结构
总结:多进程对应的PCB分别放在不同的地方,执行不同的处理。
把进程通过状态区分开来,通过操作系统对进程状态的转移控制,多进程就向前推进了。
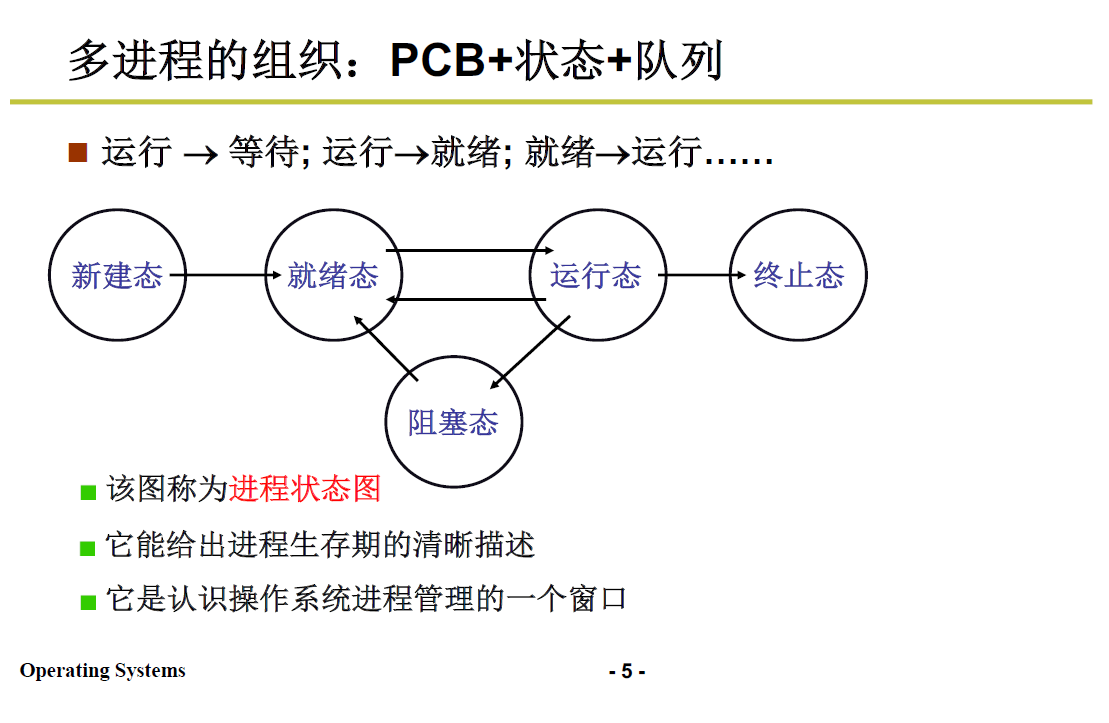
多进程如何交替/切换?
这部分后续会详细讲解,下面还是简略的过程。
情境:一个进程启动磁盘读写,等待时进行切换。
下图展示了关键代码,代码注释见图中红色字体;
schedule()函数是重点,即调度函数;
下图中的getNext从就绪队列中挑出下一个需要占用CPU的进程;
选择哪一个进程合适,即进程调度问题,也会用一讲来讲解。
switch_to就是用 PCB 进行进程上下文的切换,pCur、pNew分别指当前进程的 PCB 和调度得到的下一个进程的 PCB ,即进行执行现场的更替。
交替的三部分:
- 队列操作+调度+切换

进程如何调度?
切换进程
调度找到下一个占用CPU的进程后,就要进行切换;
这个过程需要精细控制,所以需要 汇编代码,下图为伪代码;
做的事情也不难想象,先把将要停下的进程信息保存到PCB1中(将当前CPU的各种信息(寄存器等)保存到pCur中),
再从将要进行的进程的PCB2中取出信息赋到对应寄存器/位置(将pNew中的寄存器等信息恢复到CPU中)

多进程交替时,如何相互影响?
互斥、锁的概念。
多进程看似不打照面,但实际上它们同时在一个内存来存放。
多个进程交替执行会相互影响,包括正面的多进程合作,负面的内存地址冲突等等

比如,进程1中,修改了某个地址的值,而这个地址,正好时进程2 包含的地址,这时就会引起进程2崩溃。
如何解决进程间矛盾?
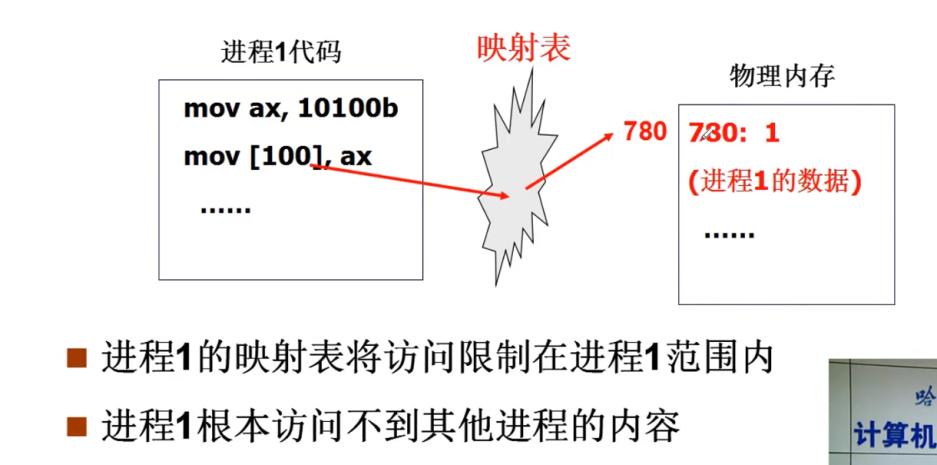
限制对进程2地址的读写。即:!内存映射!
其实涉及内存管理了,可见内存管理也服务于CPU管理的多进程图像。
通过一个映射表,将真实物理地址转化为虚拟存储地址;
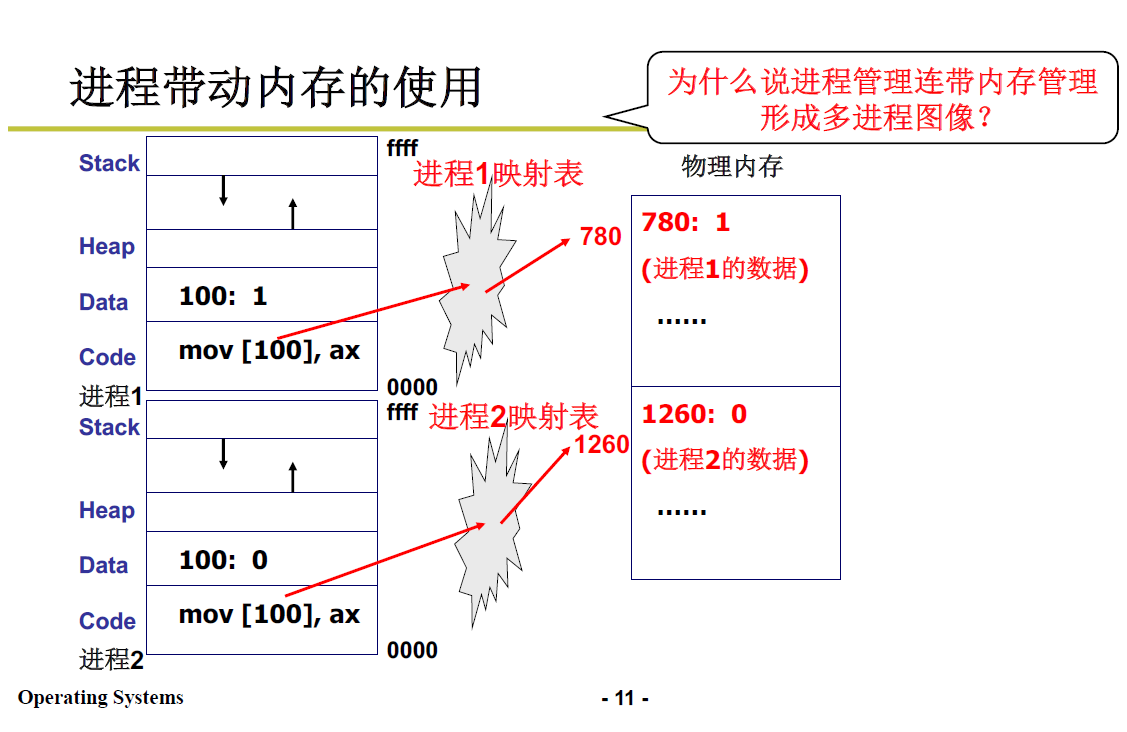
两个进程的100内存地址,是虚拟逻辑地址,会映射到不同的物理内存;下图中展示了两个进程的100地址分别映射到了物理地址780和1260
还有一些时候,进程之间需要进行合作,如何进行进程间合作?
举例1(浅显):
举例2(稍深):生产者-消费者实例
 、
、
生产者和消费者通过共享数据buffer[]进行合作
如果缓冲区满了,就不应该再放了,
用counter记录,如果==buffer_size,说明满了,死循环;没满则counter++;
如果要避免缓冲区满而还向里放的情况,counter 这个信号量必须要保持正确(我突然感觉这是工程代码调试的一个关键)
如果多个进程都在内存中交替执行,counter可能就会出错。
下面是个具体的例子:
初始counter=5,生产者执行counter++,消费者执行counter--,在寄存器层面将会是:
// 生产者P
register = counter;
register = register+1;
counter = register;
// 消费者C
register = counter;
register = register -1;
counter = register;
当生产者的程序执行到中间切换到消费者,可能的代码序列如右上角所示,counter 直接乱了。后续合作就也会乱套。

解决合作问题(合作各方的合理推进顺序)的核心在于 !进程同步!
给 counter 上锁,即写 counter 时阻断其他进程访问 counter.

理解CPU管理的基本想法
直观感受了操作系统的多进程
具体了解了多进程图像,探讨了操作系统如何实现多进程图像。
补充操作系统 多进程图像的发展:
批处理(顺序)--->多道程序处理---->分时系统
这时多进程图像的大致轮廓,后续会一一展开:
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳