1、自动化相关概念
2、自动化相关环境搭建
3、元素定位
1.核心重点(第二章)
2,提高代码质量,自动化水平(第三、四、五、六章)
3.项目实战(第七章)
4.理论及环境与定位(第一章)
概念:由机器设备代替人工自动完成指定目标的过程
1.减少人工劳动力
2.提高工作效率
3.产品规格统一标准
4.规模化(批量生产)
软件测试:校验系统是否满足规定的需求、弄清预期结果与实际结果之间的差别
概念:让程序代替人工去验证系统功能的过程
1.解决-回归测试
2.解决-压力测试
3.解决-兼容性测试
4.提高测试效率,保证产品质量
回归测试:项目在发新版本之后对项目之前的功能进行验证
压力测试:可以理解多用户同时去操作软件,统计软件服务器处理多用户请求的能力
兼容性测试:不同浏览器(IE、Firefox、Chrome)等等
优点
1.较少的时间内运行更多的测试用例:
2.自动化脚本可重复运行:
3.减少人为的错误:
4.克服手工测试的局限性:
误区
1,自动化测试可以完全替代手工测试:
2.自动化测试一定比手工测试厉害:
3.自动化测试可以发掘更多的BUG:
4,自动化测试适用于所有功能:
自动化测试分类
1.Web-自动化测试(本阶段学习)
2.移动-自动化测试
3.接口-自动化测试
4.单元测试-自动化测试
概念:让程序代替人工自动验证web项目功能的过程
1.需求变动不频繁
2.项目周期长
3.项目需要回归测试
手工测试完成
1.黑盒测试
2.灰盒测试
3.白盒测试
提示:
1.以上分类为站在代码可见度上划分
2.web自动化测试属于黑盒测试
1.QTP
是一个商业化的功能测试工具,收费,支持wb,桌面自动化测试。
2.Selenium(本阶段学习)
Selenium是一个开源的web自动化测试工具,免费,主要做功能测试。
3.Robot framework
Robot Framework是一个基于Python可扩展地关键字驱动的测试自动化框架。
Selenium是一个用于web应程序的自动化测试工具:中文的意思(硒)
1.开源软件:源代码开放可以根据需要来增加工具的某些功能
2.平台:Linux、windows、mac
3,支持多种浏览器:Firefox、Chrome、IE、Edge、Opera、Safari等
4,支持多种语言:Python、Java、C#、JavaScript、Ruby、PHP等
5.成熟稳定:目前已经被google、百度、腾讯等公司广泛使用
6,功能强大:能够实现类似商业工具的大部分功能,因为开源性,可实现定制化功能
版本:
selenium1.0
1,selenium IDE(录制自动化代码工具)
2.selenium Grid(分布式工具:同时启动多个浏览器)
3.selenium RC(通过Js模拟浏览器,实现自动化方式)
selenium2.0(稳定推荐版)
selenium2.0 = selenium1.0+webdriver
selenium3.0
2.0升级版,支持JAvA8、windows10 Edge浏览器、safa浏览器
提示:无论是通过2.0还是3.0编写的自动化脚本,API方法是不变的,唯一不同就是环境不同。
4.5.1 目标
1.掌握如何搭建web自动化测试的相关环境
2,熟练掌握web自动化测试脚本编写的基本步骤
4.5.2 环境搭建
1,Python开发环境
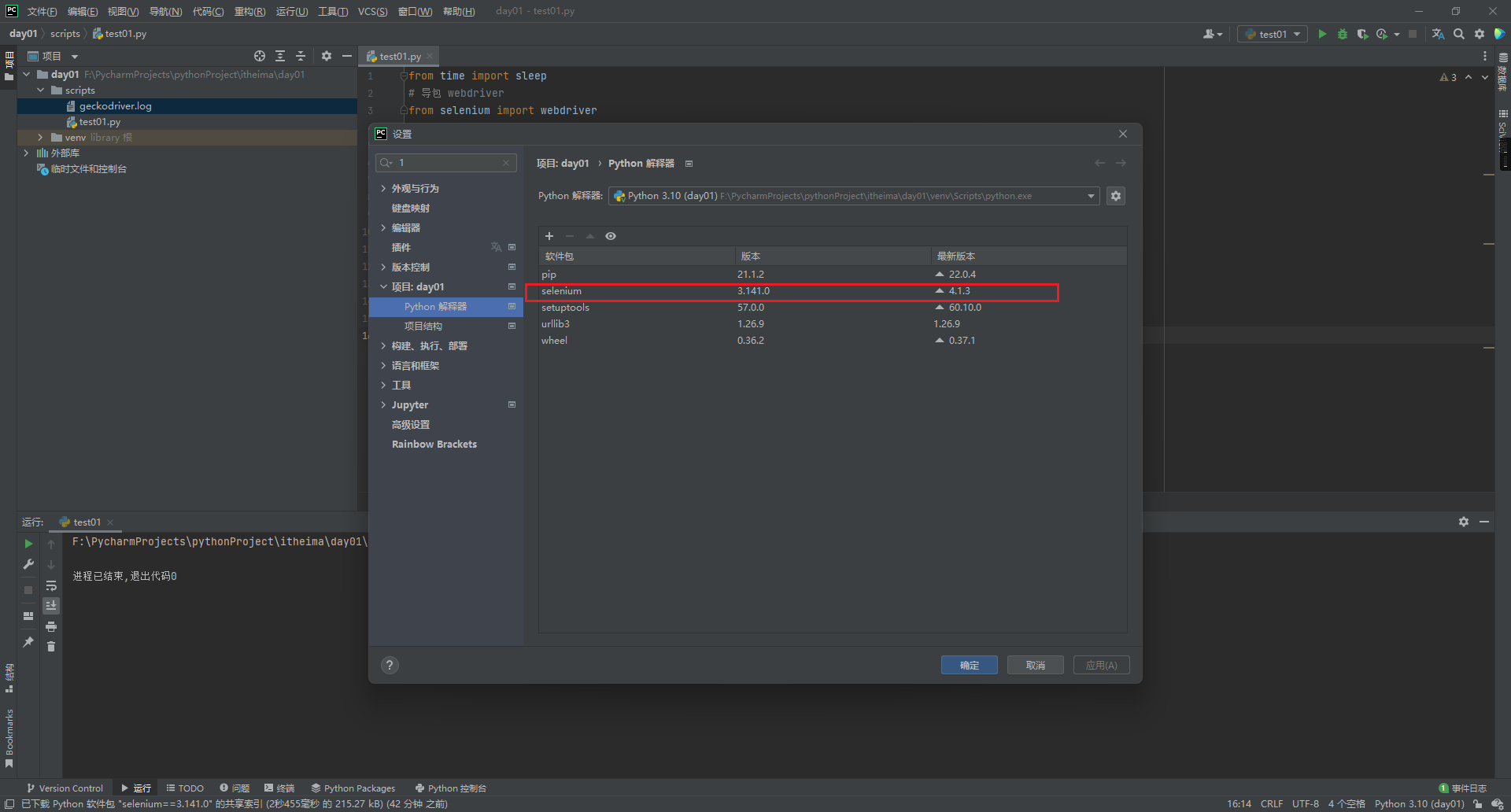
2.安装selenium包
1)通过pip命令;2)通过pycharm安装
3.安装浏览器
4.安装浏览器驱动–保证能够用程序驱动览器,实现自动化测试
4.5.3 安装selenium包
前提:Python3安装完毕且能正常运行
PIP工具
pip是一个通用的Python包管理工具,提供了对Python包的查找、下载、安装、卸载的功能。
安装
pip install selenium
pip install selenium==版本号
查看
pip show selenium
卸载
pip uninstall selenium
拓展
1.安装指定版本pip instal.1se1 enium=版本号如:pip ins3tal13se1 enium=2.48.0
2,如何查看可安装版本?指定版本号为错误版本号
3.pip是python中包管理工具(可以安装,卸载、查看python.工具)
4.pip list:查看通过pip包管理工具安装的插件或工具
提示
1.使用pip必须联网
2.默认安装python:3.0版本以上工具,自带pip包管理工具,默认会自动安装并且添加path环境变量
通过pycharm去安装【推荐】
推荐原因:安装到当前工程环境内。
4.6 浏览器及驱动安装
浏览器:
火狐:官网或百度
谷歌:百度
驱动:
1、火狐: https://github.com/mozilla/geckodriver/releases
2、谷歌: https://chromedriver.storage.googleapis.com/index.html
应用:
1、将浏览器驱动放到指定文件夹
2、将浏览器驱动所在文件夹添加到系统Path环境变量
3、火狐48版本以下内置驱动
参考链接:https://blog.csdn.net/xxlovesht/article/details/80609651
4.7 第一个案例
from time import sleep
# 导包 webdriver
from selenium import webdriver
# 获取谷歌浏览器对象
driver=webdriver.Chrome()
# driver = webdriver.Firefox()
# 打开百度
driver.get("http://www.baidu.com")
# 睡眠三秒
sleep(3)
# 关闭浏览器
driver.quit()
1.掌握id、name、class_name、tag_name、link_text、partial_link_text定位方式的使用
思考:为什么要学习元素定位
让程序操作指定元素,就必须先找到此元素。
html页面由标签构成,标签的基本格式如下:
<标签名属性名1="属性值1"属性名2="属性值2">文本</标签名>
示例:
<input id="username"type="text"name="username"placeholder=""/>
<div id="my_cart">
<span>我的购物车</span>
</div>
元素定位就是通过元素的信息或元素层级结构来定位元素的。
思考:如何快速的查看一个元素的相关信息?
浏览器开发者工具就是给专业的web应用和网站开发人员使用的工具。包含了对HTML查看和编辑、Javascript控制台、网络状况监视等功能,是开发JavaScript、CSS、HTML和Ajax的得力助手。
作用:快速定位元素,查看元素信息
火狐:Firebug(F12获取直接点击Friebug图标)
谷歌:F12键(开发者工具)
定位元素依赖于什么?
1、标签名
2、属性
3、层级
4、路径
Selenium提供了八种定位元素方式
1.id
2.name
3.class_name(使用元素的class属性)
4.tag_name(标签名称<标签名 .../>)
5.link_text(定位超链接 a标签)
6.partial_link_text(定位超链接 a标签 模糊)
7.XPath(基于元素路径)
8.CSS(元素选择器)
汇总:
1、基于元素属性特有定位方式(id、name、class_name)
2、基于元素标签名称定位:tag_name
3、基于超链接文本:(link_text、partial_link_text)
4、基于元素路径:Xpath
5、基于元素选择器:CSS
说明:id定位就是通过元素的id属性来定位元素,HTML规定id属性在整个HTML文档中必须是唯一的
前提:元素有id属性
id定位方法
element = driver.find_element_by_id(id)
案例演示环境说明:
受限于网络速度的影响,我们案例采用本地的htm1页面来演示。这样可以提高学习效率和脚本执行速率
需求:打开注册A.html页面,完成以下操作
1).使用id定位,输入用户名:admin
2).使用id定位,输入密码:123456
3).3秒后关闭浏览器窗口
# 导包
from selenium import webdriver
from time import sleep
# 获取浏览器对象
# driver = webdriver.Chrome()
driver = webdriver.Firefox()
# 打开url(本地文件)
url = "本地页面链接"
driver.get(url)
# 查找用户名元素
username = driver.find_element_by_id('userA')
# 查找密码元素
password = driver.find_element_by_id('passwordA')
# 用户名输入admin send_keys('内容')
username.send_keys("admin")
# 密码输入123456
password.send_keys("123456")
# 暂停三秒
sleep(3)
driver.quit()
提示:
1.输入方法:send keys("输入内容"):
2.退出浏览器驱动:driver.quit():
3.打开ur1:driver.get(url)
4.导包:from selenium import webdriver
5.获取火狐浏览器驱动对象driver=driver.Firefox()
说明:name定位就是根搭阮素name属性来定位。HTML文档中name的属性值是可以重复的。
前提:元素有name属性
element driver.find_element_by_name(name)
需求:打开注册A.html页面,完成以下操作
1).使用name定位用户名,输:admin
2).使用name定位密码,输入:123456
3).3秒后关闭浏览器窗口
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
url = '链接'
driver.get(url)
username = driver.find_element_by_name('userA')
password = driver.find_element_by_name('passwordA')
username.send_keys('admin')
password.send_keys('123456')
sleep(3)
driver.quit()
id:一般为唯一标识符。
name:可以重名
class:多个命名
下方这份完整的软件测试视频学习教程已经上传CSDN官方认证的二维码,朋友们如果需要可以自行免费领取 【保证100%免费】

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您