Redis 是一个高性能的键值存储系统,支持多种数据结构。
包含五种基本类型 String(字符串)、Hash(哈希)、List(列表)、Set(集合)、Zset(有序集合),和三种特殊类型 Geo(地理位置)、HyperLogLog(基数统计)、Bitmaps(位图)。
每种数据结构都是为了解决特定问题而设计的,适用不同的场景。想要用好Redis,必须了解底层实现原理和使用技巧,同时结合具体的业务场景和需求进行选择和使用。无论是工作还是面试中,这些必备的知识。
下面就详细介绍一下每种数据类型的使用方式、实现原理和适用场景。
String(字符串)是Redis中最基本的数据结构之一,它可以存储任意类型的数据,包括数字、文本、序列化的对象等。Redis中的字符串最大可以存储512MB的数据。
字符串类型的操作是最基本的,包括设置值、获取值、修改值、追加值等。字符串类型支持的操作包括:

Redis字符串的内部编码有三种:
哈希类型是一种键值对的集合,其中键值对的值可以是字符串、列表或者其他哈希类型。哈希类型支持的操作包括:
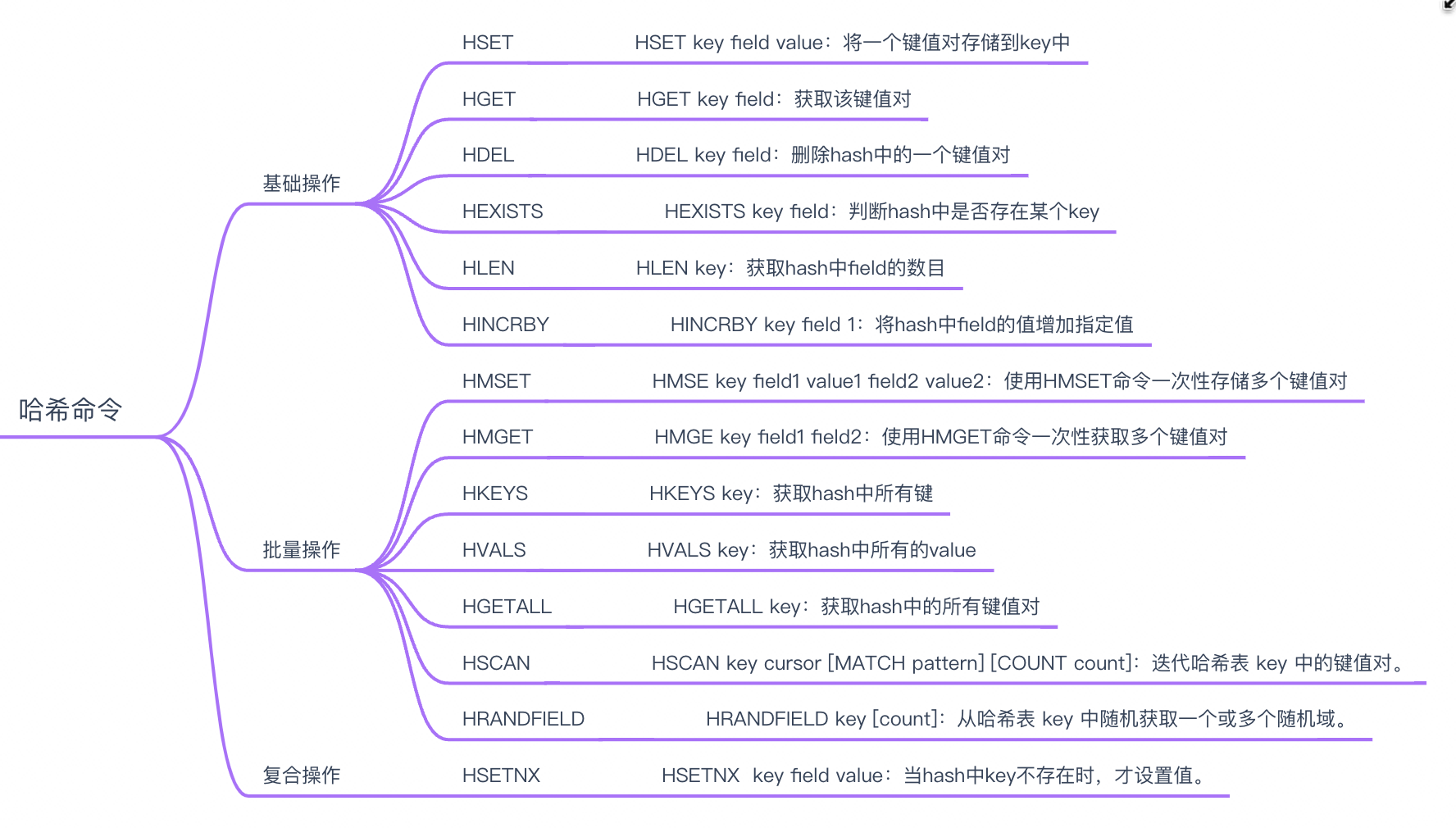
Redis哈希类型的内部编码有两种:
Redis List类型是一个有序的字符串列表,支持在列表的头部或尾部添加元素,也支持在列表任意位置插入或删除元素。支持的操作包括:
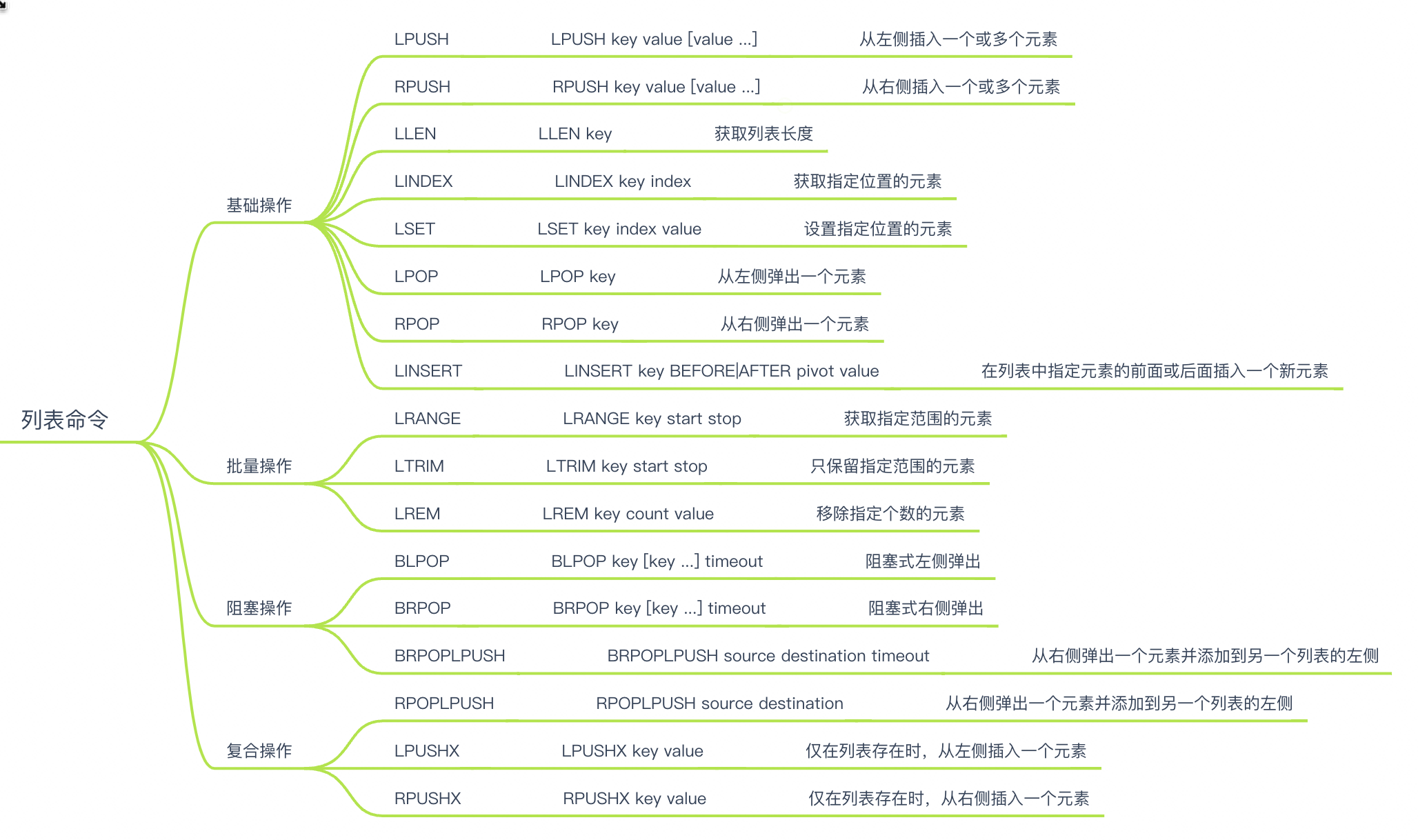
Redis List类型由于支持在列表的头部或尾部添加元素,也支持在列表任意位置插入或删除元素,因此非常适合以下场景:
Redis List类型内部编码有两种,分别是ziplist和linkedlist。
ziplist是一种特殊的编码方式,它可以将小数据量的列表存储在一个连续的内存块中,节省了内存空间,同时还可以提高存取效率。
ziplist编码的列表最大长度为2^16-1个元素,每个元素可以是字符串类型、整数类型或浮点数类型。在ziplist中,每个元素都被存储为一个字节数组,并包含一个前缀和一个后缀,用于标识该元素的类型和长度。
linkedlist是一种常规的双向链表结构,它可以存储任意长度的列表,并且支持高效的插入和删除操作。在linkedlist中,每个节点都包含了一个指向前一个节点和后一个节点的指针,以及一个存储元素数据的指针。
linkedlist适用于存储大数量的列表,它没有像ziplist那样的内存限制,但是会占用更多的内存空间。
Redis Set(集合)是一个无序的字符串集合,其中每个元素都是唯一的,不允许重复。Redis Set类型支持的操作包括:
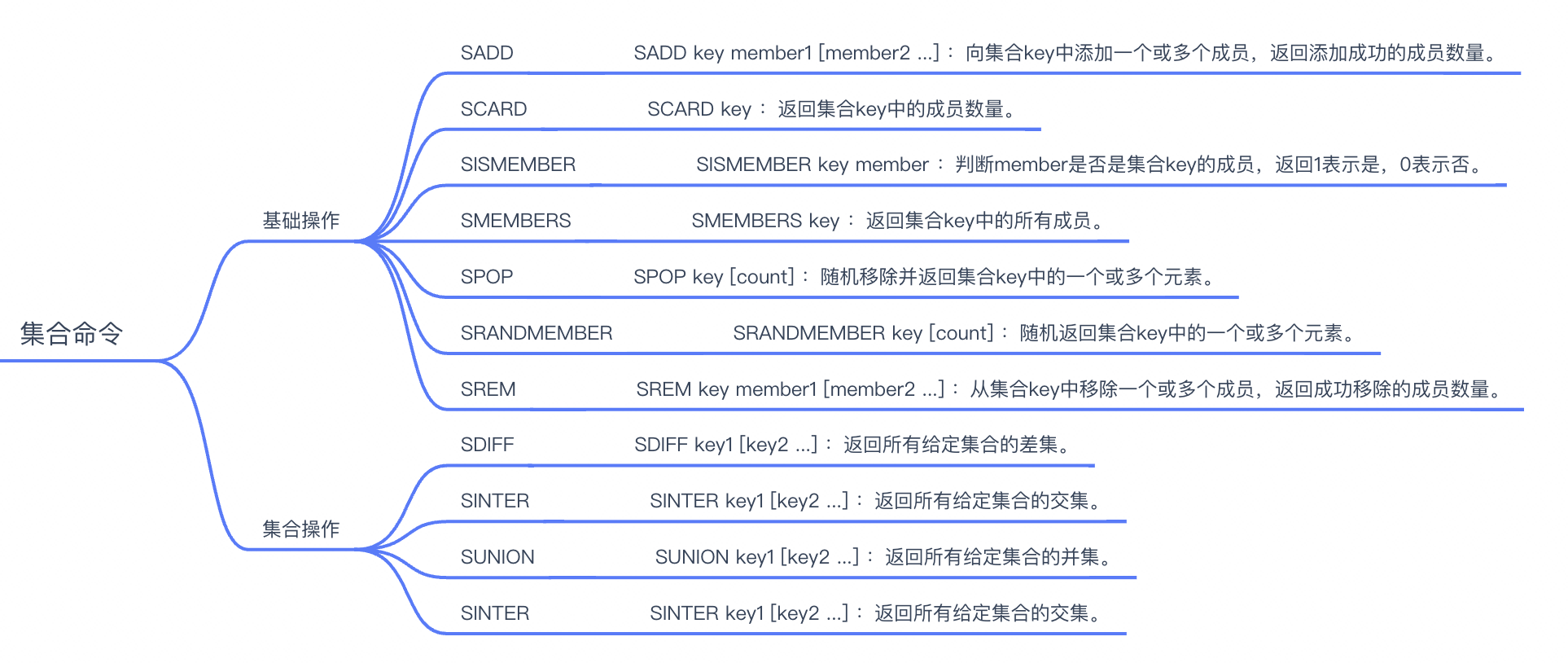
Redis Set类型的使用场景包括:
总的来说,Set类型适用于需要存储一组不重复的数据,并支持集合操作的场景。
Redis Set类型的内部编码有两种:
在实际使用中,当Set类型的元素全部为整数类型时,建议使用intset编码;而当Set类型的元素包含非整数类型时,才使用hashtable编码。
Redis中的Zset(有序集合)是一个键值对集合,其中每个元素都关联一个分值(score),通过分值进行排序,可以看作是一个字典(dict)和一个跳跃列表(skip list)的混合体,它可以存储多个相同的元素,但每个元素必须有一个唯一的score值。
支持的操作包括:

Redis Zset是一种有序集合,其使用场景主要包括以下几个方面:
Redis Zset的内部编码有两种:
Redis Geo(地理位置)是一个键值对集合,其中每个元素都包含一个经度和纬度,可以用于存储地理位置信息并支持基于位置的搜索。Redis Geo支持的操作包括:

Redis Geo类型适用于需要存储地理位置信息并支持基于位置的搜索的场景,比如附近的人、附近的商家等。
Redis Geo类型的使用场景如下:
Redis Geo类型内部使用zset来存储地理位置信息,其中元素的score值为经度,member值为经纬度组合的字符串。在使用GEORADIUS和GEORADIUSBYMEMBER命令搜索元素时,Redis会构建一个跳跃表,以实现高效的搜索。
Redis HyperLogLog(基数统计)是一种基于概率统计的数据结构,用于估计大型数据集合的基数(不重复元素的数量),以及对多个集合进行并、交运算等。HyperLogLog的优点是可以使用极少的内存空间,同时可以保证较高的准确性。
每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。

HyperLogLog的使用场景主要包括以下几个方面:
使用HyperLogLog可以大大减少内存占用和计算时间,是处理大数据量去重计数的有效工具。
Redis HyperLogLog类型的内部编码使用的"稀疏矩阵"和”稠密矩阵“。
当计数较少时,采用”稀疏矩阵“,其中绝大部分元素都是0。计数增多后,超过阈值后,会转换成”稠密矩阵“。
Redis Bitmaps(位图)是一种紧凑的数据结构,可以用于表示一个只有0和1的数组。位图可以用于高效地存储大规模的布尔值,以及进行位运算、位图图形化等操作。Redis Bitmaps支持的操作包括:

Redis Bitmaps适用于需要高效地存储大规模的布尔值,并进行位运算、统计等操作的场景。比如:
Redis Bitmaps类型的内部编码使用了一种称为“压缩位图”的数据结构。它通过使用两个数组来存储位图数据:一个存储实际位的值,另一个存储每个字节中1的个数。这种编码方式可以大大压缩位图数据的大小。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.