在 Flask 中处理文件上传非常简单。它需要一个 HTML 表单,其 enctype 属性设置为“multipart/form-data”,将文件发布到 URL。
URL 处理程序从 request.files[] 对象中提取文件,并将其保存到所需的位置。
每个上传的文件首先会保存在服务器上的临时位置,然后将其实际保存到它的最终位置。
目标文件的名称可以是硬编码的,也可以从 request.files[file] 对象的filename属性中获取。
但是,建议使用 secure_filename() 函数获取它的安全版本。
可以在 Flask 对象的配置设置中定义默认上传文件夹的路径和上传文件的最大大小。
app.config[‘UPLOAD_FOLDER’] 定义上传文件夹的路径
app.config[‘MAX_CONTENT_LENGTH’] 指定要上传的文件的最大大小(以字节为单位)
以下代码具有 '/upload' URL 规则,该规则在get请求下- templates 文件夹中显示 'upload.html',在post请求下用于调用 upload() 函数处理上传过程,在'/download/<filename>'请求下可以通过文件名下载对应提交文件。
'upload.html' 有一个文件选择器按钮和一个提交按钮。(界面较为简单,有需求可自己美化界面)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{# enctype设置不对字符编码 #}
<form action="upload" method="POST" enctype="multipart/form-data">
<input type="file" name="file" accept=".jpg, .png" />
<input type="submit" />
</form>
</body>
</html>
以下是 Flask 应用程序的 Python 代码。
from flask import Flask, render_template, request, send_from_directory
from werkzeug.utils import secure_filename
import os
import uuid
app = Flask(__name__)
# 设置文件上传保存路径
app.config['UPLOAD_FOLDER'] = 'static/upload/'
# MAX_CONTENT_LENGTH设置上传文件的大小,单位字节
app.config['MAX_CONTENT_LENGTH'] = 1 * 1024 * 1024
@app.route('/upload', methods=['GET', 'POST'])
def upload():
# 如果是get请求响应上传视图,post请求响应上传文件
if(request.method == 'GET'):
return render_template('upload.html');
else:
f = request.files['file'];
fname = secure_filename(f.filename);
ext = fname.rsplit('.')[-1];
# 生成一个uuid作为文件名
fileName = str(uuid.uuid4()) + "." + ext;
# os.path.join拼接地址,上传地址,f.filename获取文件名
f.save(os.path.join(app.config['UPLOAD_FOLDER'], fileName))
return 'ok';
# 图片下载
@app.route('/download/<filename>', methods=['GET'])
def download(filename):
if request.method == "GET":
#通过文件名下载文件
path = os.path.isfile(os.path.join(app.config['UPLOAD_FOLDER'], filename));
if path:
return send_from_directory(app.config['UPLOAD_FOLDER'], filename, as_attachment=True)
if __name__ == '__main__':
app.run(debug=True)
效果
当请求是get时,响应视图
选择对应的图片文件上传
上传成功后,可以在预设的文件夹下找到对应的图片
通过文件名下载对应上传的文件
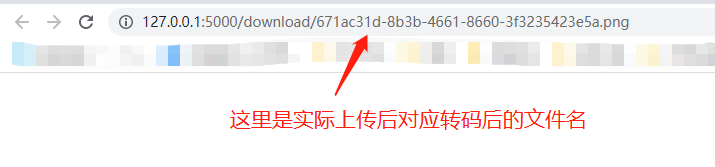
下载成功
实际开发中,还可以在视图函数中把接收到的图片转为base64格式,存储在数据库中,方便存取。或者**使用专门OOS对象存储OSS(Object Storage Service)**进行存储。
如果你希望访问源码:Flask-code gitee
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只