ChatGPT真的“无敌”了吗????
我们邀请ChatGPT参加一项关于算法和数据结构的本科计算机科学考试。我们把它的答案手抄到一张考卷上,然后在盲测的情况下,随机选200名参与的学生。我们发现ChatGPT以20.5(满分40分)的成绩勉强通过了考试。这一令人印象深刻的表现表明,ChatGPT确实可以成功完成大学考试等具有挑战性的任务。同时,我们考试中的问题在结构上与其他考试相似,解决的家庭作业题,以及可以在网上找到的教学材料,这些材料可能是ChatGPT训练数据的一部分。因此,从这个实验中得出ChatGPT对计算机科学有任何理解的结论是不充分的。我们也评估了GPT-4带来的改进。我们发现,GPT-4比GPT-3.5多获得17%的考试分数,达到了普通学生的表现。
许多人已经注意到ChatGPT1的功能OpenAI的一种新型聊天机器人模型令人印象深刻,该模型甚至可以成功完成大学考试等具有挑战性的现实任务。事实上,已有证据表明这可能是事实。此外,对模型响应的评估通常不是盲目的,这可能是有问题的,因为众所周知ChatGPT会产生需要解释的奇怪答案。因此,尽管有很多关于这个话题的讨论,到目前为止,关于ChatGPT在大学考试中的能力的系统证据很少。
我们提出了一个简单但严格的实验的结果,评估的能力。关于算法和数据结构的本科生计算机科学考试。我们在常规大学考试的同时进行了这个实验,这使我们能够在一个盲设置中与学生一起评估模型的反应。我们以简单的标准化格式提出了不同的考试问题,使ChatGPT能够对所有考试问题给出明确的答案。
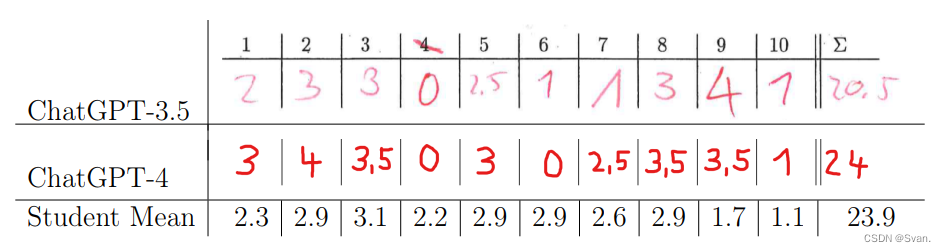
表1:在我们的考试中,ChatGPT在10个不同的练习中获得的分数,与参加我们考试的200名学生获得的平均分数进行比较。
- 第一行描述了ChatGPT使用GPT-3.5基本模型获得的点。这是本文讨论的主要实验的结果,其中模型反应与学生反应一起盲目评分。ChatGPT-3.5获得了20.5分(满分40分)。
- 第二行描述了ChatGPT使用GPT-4基本模型获得的点。在这里,模型响应根据主实验中使用的相同评分方案进行评分,但评分不是盲目的。我们估计ChatGPT-4将获得约24分,达到平均学生的表现。
- 第三行表示参加考试的200名学生获得的平均分数。
实验的结果是,ChatGPT将以20.5分(满分40分)的成绩侥幸通过考试。这令人印象深刻,但也突出了当前模型版本的局限性。特别是,该模型的表现比参加考试的平均学生的表现更差(平均学生获得约24分,比较表1)。就考试相对标准化而言,ChatGPT的混合表现是有趣的。类似的考试在世界各地都有,并且涵盖了很多关于主题的信息。
我们也评估了GPT-4带来的改进。我们发现,使用GPT-4基础模型的ChatGPT在考试中比使用GPT-3.5基础模型的ChatGPT多获得17%的分数,达到了普通学生的成绩。
我们考虑一个关于算法和数据结构的入门课程的考试。考试内容包括排序算法、图遍历和动态规划。总的来说,考试涵盖的主题在世界各地都以类似的方式进行教学。考试包含不同类型的问题,包括多项选择题、写小题、写伪代码和画图。进行这个实验的想法并没有把考试中的练习偏向于ChatGPT的能力。

我们在与模型的19个不同的对话中提出了考试问题,依赖于考试的latex源文件。我们告诉模型,我们正在问计算机科学考试中关于算法的问题,并要求它提供简短、准确的答案,在整个过程中,我们并没有试图设计提示来引导模型走向更好或更差的答案,唯一的目标是,该模型将为所有问题提供明确的答案。
一些考试题目涉及数学、伪代码或图形。在本例中,我们简单地使用来自考试的latex源代码提示模型,如下例所示:

例如,当我们要求模型写一个小的证明时,它会用乳胶方程来回应。类似地,当我们要求模型完成伪代码时,它以有效的方式完成了给定的伪代码。
在与模型进行对话之后,我们将答案手写在一张试卷上,在这样做的过程中,我们当然将模型的所有乳胶输出“渲染”到纸张上。
在本节中,我们将讨论GPT-3.5的主要实验结果。所带来的改善GPT-4将在下一节讨论。主要结果是,ChatGPT获得20.5分(满分40分),通过了考试。由于要通过考试至少需要20分,ChatGPT仅以非常微弱的优势通过。
在考试的其他部分,ChatGPT给出了错误的答案,有时甚至是奇怪的答案,(如下图)特别是,该模型在涉及结构化输出(不是伪代码)的所有练习中都遇到了困难。

在本节中,除了本文考虑的主要实验外,我们还评估了GPT-4带来的改进。GPT-4技术报告在许多不同的考试中比较了GPT-4和GPT-3.5,并报告了巨大的性能提升(OpenAI, 2023)。然而,由于报告中使用的数据集不可用,因此很难复制和评估这些结果。然而,有人指出,有证据可以对训练数据进行测试。
总的来说,ChatGPT-4获得了24分(满分40分)。这是3.5个百分点,即17%ChatGPT与GPT-3.5基础模型。有趣的是,这意味着ChatGPT-4在我们的考试中与普通学生的表现相当。虽然改进看起来很小,但实际上它确实意味着ChatGPT-4能够回答一些更有挑战性的多项选择题,这些问题是以前版本的模型难以回答的。
我们的实验结果与现有的研究一致,这些研究记录了大型语言模型令人印象深刻的能力,以及它们严重的局限性。我们想强调的是,ChatGPT能够通过我们的考试这一事实并不意味着它对计算机科学有任何理解,就像我们可能期望它能够通过考试的人那样。当然可以合理地假设ChatGPT在培训过程中看到了许多与我们考试中相似的练习和解决方案。一般来说,为了了解像ChatGPT这样的模型的能力和局限性,需要进行更多的研究。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
Ruby中如何“一般地”计算以下格式(有根、无根)的JSON对象的数量?一般来说,我的意思是元素可能不同(例如“标题”被称为其他东西)。没有根:{[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]}根包裹:{"posts":[{"title":"Post1","body":"Hello!"},{"title":"Post2","body":"Goodbye!"}]} 最佳答案 首先,withoutroot代码不是有效的json格式。它将没有包
目标我正在尝试计算自给定日期以来周的距离,而无需跳过任何步骤。我更喜欢用普通的Ruby来做,但ActiveSupport无疑是一个可以接受的选择。我的代码我写了以下内容,这似乎可行,但对我来说似乎还有很长的路要走。require'date'DAYS_IN_WEEK=7.0defweeks_sincedate_stringdate=Date.parsedate_stringdays=Date.today-dateweeks=days/DAYS_IN_WEEKweeks.round2endweeks_since'2015-06-15'#=>32.57ActiveSupport的#weeks
LL库和HAL库简介LL:Low-Layer,底层库HAL:HardwareAbstractionLayer,硬件抽象层库LL库和hal库对比,很精简,这实际上是一个精简的库。LL库的配置选择如下:在STM32CUBEMX中,点击菜单的“ProjectManager”–>“AdvancedSettings”,在下面的界面中选择“AdvancedSettings”,然后在每个模块后面选择使用的库总结:1、如果使用的MCU是小容量的,那么STM32CubeLL将是最佳选择;2、如果结合可移植性和优化,使用STM32CubeHAL并使用特定的优化实现替换一些调用,可保持最大的可移植性。另外HAL和L
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进