kNN(k nearest neighbor,k近邻)是一种基础分类算法,基于“物以类聚”的思想,将一个样本的类别归于它的邻近样本。
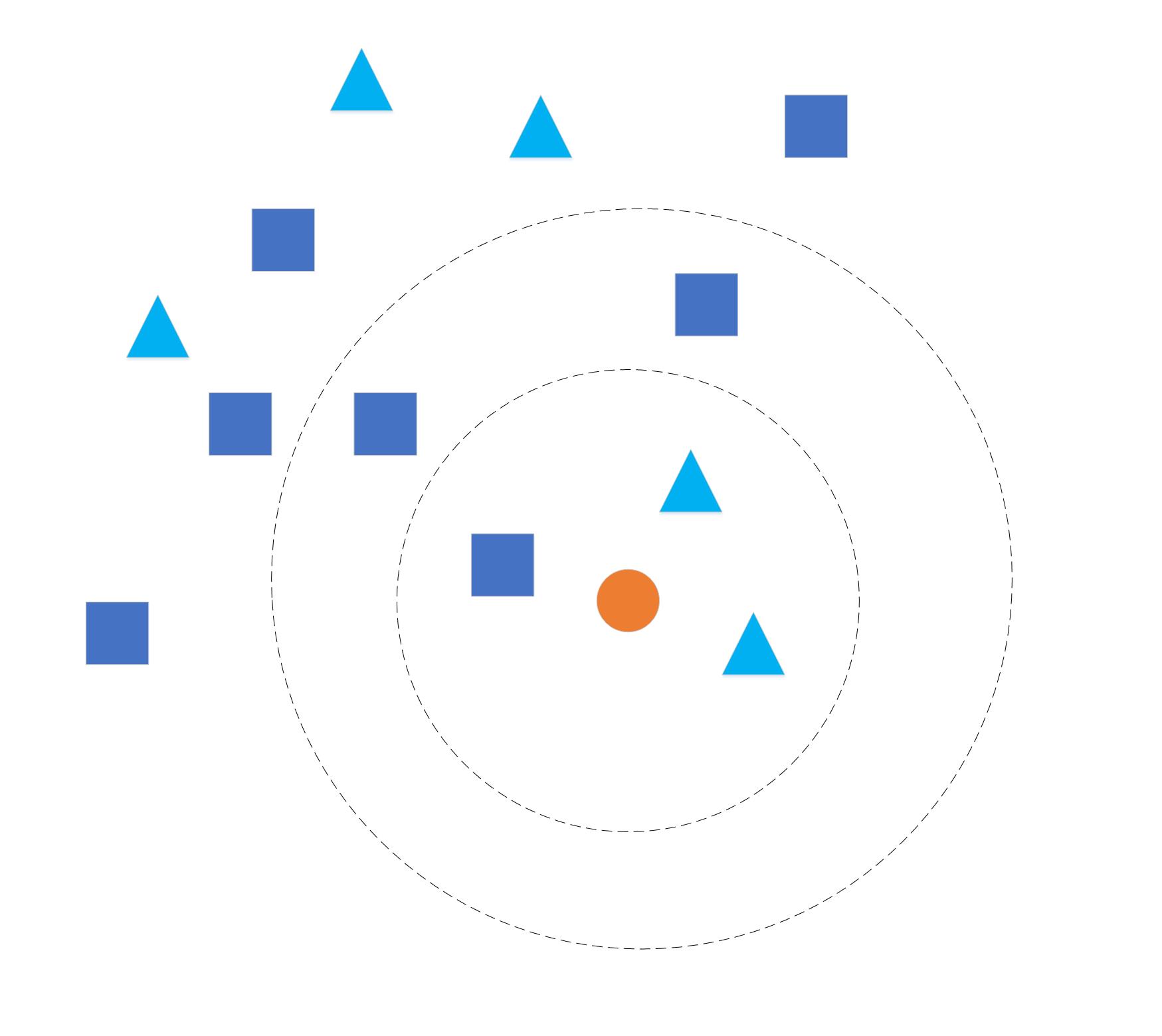
给定训练数据集 \(T=\left\{ \left( x_1,y_1 \right),\left( x_2,y_2 \right),...,\left( x_N,y_N \right) \right\}\),其中\(x_i=\left( x_{i}^{(1)},x_{i}^{(2)},...,x_{i}^{(n)} \right)\)为特征向量,\(y_i\)为样本类别。对于一个待测样本\(x\),计算\(x\)与训练集样本的距离,找到离它最近的\(k\)个邻居,考察这\(k\)个邻居,它们更倾向于哪个类别,就把\(x\)归到那个类别。算法由三个基本要素构成:\(k\)值选择、距离度量、分类决策规则。
k值选择:
若\(k\) 值过小,模型偏向复杂,易于过拟合;若 \(k\) 值过大,模型偏向简单,易于欠拟合。通常由交叉验证法选择最优的\(k\)值,一般不超过20。
距离度量:
距离度量的方式有很多,通常使用欧氏距离,也就是差向量的\(L2\)范数。对两个样本向量\(A=\left( x_{11},x_{12},...,x_{1n} \right)\)和\(B=\left( x_{21},x_{22},...,x_{2n} \right)\),它们之间的欧氏距离为$$d=\sqrt{\sum_{k=1}^{n}{\left( x_{1k}-x_{2k} \right)^{2}}}$$
分类决策规则:
一般是多数表决,即由\(k\)个邻居中较多的决定。也可以根据距离的远近,赋以样本不同的权重。
输入:训练数据集\(T\) ;待测样本 \(x\).
输出:\(x\)所属类别.
(1)计算\(x\)与训练样本间的距离.
(2)确定与\(x\)最近的\(k\)个邻居.
按距离对样本进行排序,选取前 \(k\) 个距离最小的样本,构成邻居集合\(N_{k}\left( x \right)\).样本数量为$$\left| N_k\left( x \right) \right|=M$$
(3)确定 \(x\) 的类别 \(y\) .
多数表决,由邻居集合中类别的多数决定
其中 \(I\) 为指示函数
\(i=1,2,...,M\);\(j=1,2,...,K\).
'''
功能:由sklearn实现kNN分类。
'''
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
## 1.构造训练集和待测样本
#训练集数据
train_x=[
[1.1, 2, 3, 4],
[1, 2.2, 3, 4],
[1, 2, 3.3, 4],
[1, 2, 3, 4.4],
[1.1, 2.2, 3, 4],
[1, 2, 3.3, 4.4]
]
#训练集数据标签
train_y=[
1,
2,
2,
3,
3,
1
]
train_y = list(map(float,train_y)) #浮点化
#待测样本
test_x = [
[1.2, 2, 3, 4],
[1, 2.3, 3, 4]
]
#转为array形式
train_x = np.array(train_x)
train_y = np.array(train_y)
test_x = np.array(test_x)
## 2.定义分类器
knnClf = KNeighborsClassifier(
n_neighbors=2, #选取的k值,即邻居样本数
weights='uniform', #分类决策权重,默认uniform,为均等权重
algorithm='auto',
leaf_size=30,
p=2,metric='minkowski', #距离度量,闵可夫斯基空间下的欧氏距离(p=2)
metric_params=None,
n_jobs=None
)
## 3.训练
Fit_knnClf = knnClf.fit(train_x,train_y)
## 4.预测
pre_y = Fit_knnClf.predict(test_x)
print('预测类别:')
print(pre_y)

End.
参考
1.李航.《统计学习方法》.清华大学出版社
2. https://blog.csdn.net/Albert201605/article/details/81040556?spm=1001.2014.3001.5502
当我将项目添加到我的Postgres数据库时,一切似乎都运行良好。在不做任何更改的情况下,只要在我的应用程序中的任何位置启动Madeleine,我的Rails应用程序就会开始失败:EncodingErrorinEventsController#updateinvalidencodingsymbolapp/controllers/events_controller.rb:137:in`update'137是问题行:135defupdate136@event=Event.find(params[:id])137m=SnapshotMadeleine.new("bayes_data")...
我正在使用rubyclassifiergem其分类方法返回根据训练模型分类的给定字符串的分数。分数是百分比吗?如果有,最大差值是100分吗? 最佳答案 这是概率的对数。对于大型训练集,实际概率是非常小的数字,因此对数更容易比较。从理论上讲,分数的范围从接近零的无穷小到负无穷大。10**score*100.0会给出实际概率,确实最大相差100。 关于ruby-贝叶斯分类器分数代表什么?,我们在StackOverflow上找到一个类似的问题: https://st
我想实现一个简单的贝叶斯分类系统来对短信进行基本的情感分析。欢迎提供在Ruby中实现的实用建议。也欢迎提出除贝叶斯之外的其他方法的建议。 最佳答案 IlyaGrigorik在BayesianClassifiers上的这篇博文中对这个问题给出了很好的答案。此外,您不妨看看ai4rrubygem用于贝叶斯分类器的一些替代方法。ID3是一个不错的选择,因为它提供了即使对机器学习技术没有任何真正了解的人也能“理解”的决策树。 关于ruby-在Ruby中实现贝叶斯分类器?,我们在StackOver
我有一个包含名称和日期的待办事项列表。我希望能够使用标题或日期对列表进行排序。我该怎么做?比较器只允许一种类型的排序。谢谢。 最佳答案 可以在比较器中实现更多逻辑,以便您可以抽象出一些排序逻辑:varCollection=Backbone.Collection.extend({model:myModel,order:'name'comparator:function(model){if(this.order==='name'){returnmodel.get('name');}else{returnmodel.get('date')
我是js和D3的新手。我已经生成了各种热图,并想使用D3的on.mouseover更改图block的颜色。我可以显式更改颜色,但想使用CSS事件规则。可能很容易修复。任何帮助将不胜感激。完整代码如下。谢谢。MJ-HeatmapCountryByDistrict_Port_NmeHeatmapbody{font:10pxsans-serif;}.label{font-weight:bold;}.tile{shape-rendering:crispEdges;}.axispath,.axisline{fill:none;stroke:#000;shape-rendering:crispEd
文章目录任务效果原理图指令编码语音识别模块简介代码设计驱动舵机模块简介驱动主程序源代码任务题目:基于stm32蓝牙智能语音识别分类播报垃圾桶实现功能如下:语音识别根据使用者发出的指令自动对垃圾进行分类根据垃圾的种类实时播报垃圾的类型根据垃圾种类驱动对应的舵机进行转动(模拟垃圾桶打开,并在十秒钟自动复位,模拟垃圾桶关闭)OLED显示屏实时显示四种垃圾桶的状态蓝牙app可以控制垃圾桶开关,同时显示四种垃圾桶状态效果原理图指令编码语音识别模块简介LU-ASR01是一款低成本、低功耗、体积小、高性能的离线语音识别系统。本系统集成了语音识别、语音回复、IO控制(多信号输出)、串口输出、温湿度广播等功能。
好人——我需要一些帮助来找到创建交互式分支图或系统发育树的方法(是的,我已经阅读了所有相关帖子,但没有找到我要找的东西)。问题是,我需要节点可以命名。一个例子是这样的我发现的大多数脚本要么是applets、flash,要么根本不显示节点分类,即在本例中它会跳过“feliformia”。这对我没用,因为我最终会得到食肉动物-匿名节点-匿名节点-匿名节点-老虎,这并不好。这棵树在理论上将覆盖所有生命,因此它可以变得相当大,并从数据库中获取英文和拉丁文的链接和名称。所以:没有Flash,没有小程序。它必须是水平的,没有super树(圆形)。我经历过这个http://bioinfo.unice
我有一个plotly.js条形图,我试图让分类轴的顺序正确。每个类别都有一个条形图,但有时它们是绿色的,有时它们是黄色的。条形图应按从高到低的顺序排列,但实际上似乎是根据不同的填充量对它们进行排序。数据:vardata=[{"marker":{"color":"#006666"},"x":["A:0122","A:0121","A:0434","A:0838","A:0083","A:0081","A:0687"],"y":[1246.0,1096.0,1000.0,200.0,0.0,0.0,0.0],"name":"Green","type":"bar"},{"marker":{"
一、内容提要今天笔者同样以测井岩性分类为实例,为大家分享一种被称为“最简单的机器学习算法之一”的K-近邻算法(K-NearestNeighbor,KNN)。K-近邻算法(KNN,K-NearestNeighbor)可以用于分类和回归[1]。K-近邻算法,意思是每一个样本都可以用它最接近的K个邻居来代表,以大多数邻居的特征代表该样本的特征,据此分类[2]。它的优势非常突出:思路简单、易于理解、易于实现,无需参数估计[3]。本期笔者将KNN算法应用在基于测井数据的岩性分类上。下面分为算法简介、实例计算与代码解读三个部分进行讲解。(代码获取方式详见文末)二、算法简介K-近邻算法K-近邻算法的计算过程
我正在寻找一种将分类数据添加到d3js平行坐标的方法。D3js对我来说是新手,我能理解一些正在做的事情,但还没有想出这样做的方法。平行集不是一个好的选择,因为我的大部分数据都是连续的。如果您想到汽车示例,我希望能够按轴上的品牌进行过滤(例如,过滤以便仅显示福特的数据)。我假设需要一个变量来定义每辆车(例如Peugeot、Ford、BMW、Audi等...)这是汽车的例子。http://bl.ocks.org/1341281感谢所有回复的人。 最佳答案 实际上,您只需要一个序数标度!轴将处理其余部分。检查一下here.基本上我改变了: