最近用学习到的知识进行了利用GEE和Landsat 8 SR数据进行土地利用分类的小实验,在这里进行一些学习记录。
一、数据导入
首先在GEE中上传要进行土地利用分类的行政区域边界,这里是以雄安新区为例。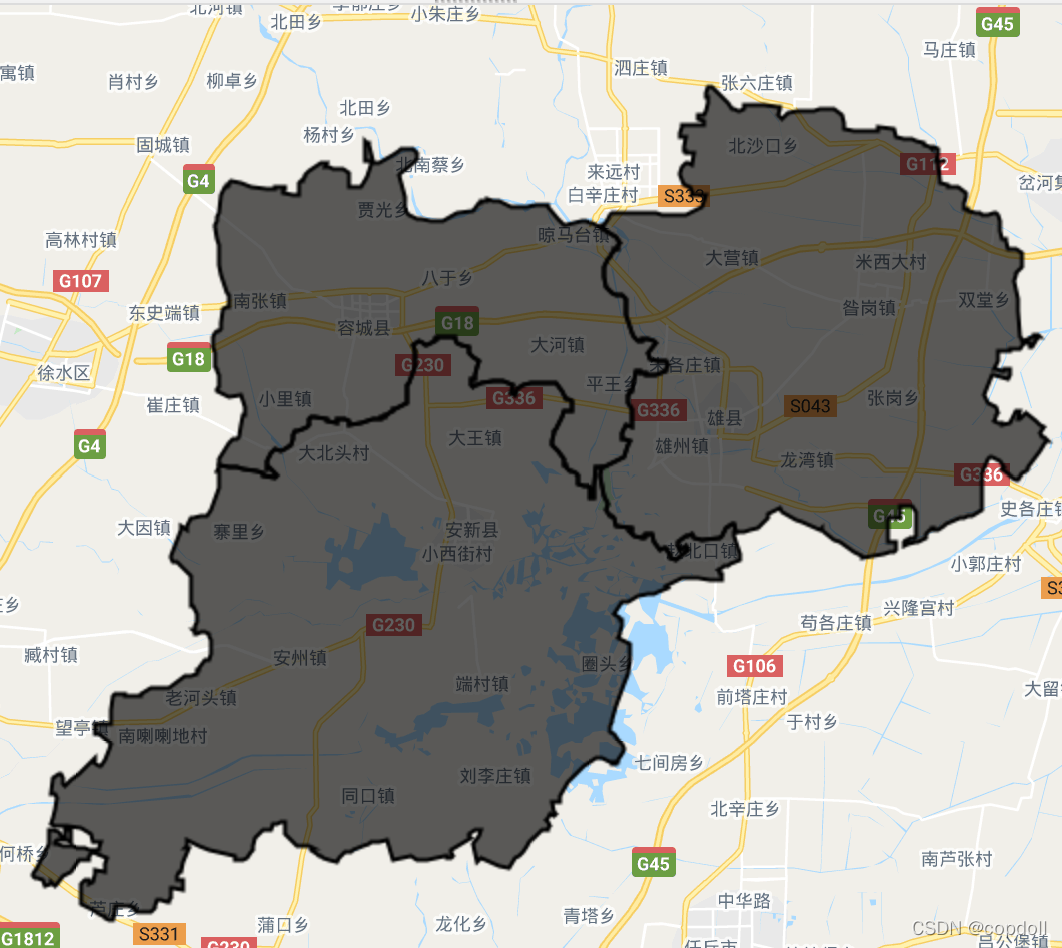
二、遥感数据筛选
使用的数据是Landsat 8 OLI/TIRS传感器的SR数据集,SR数据利用QA波段进行影像去云处理,这里构造了去云函数便于后续调用;
筛选想要进行土地利用分类的时间,并用clip函数将研究区裁剪出来。
// Applies scaling factors.
function applyScaleFactors(image) {
var opticalBands = image.select('SR_B.').multiply(0.0000275).add(-0.2);
var thermalBands = image.select('ST_B.*').multiply(0.00341802).add(149.0);
return image.addBands(opticalBands, null, true)
.addBands(thermalBands, null, true);
}
//L8 cloud_remove
function maskL8sr(image) {
// 第3位和第5位分别是云影和云。
var cloudShadowBitMask = 1 << 4;
var cloudsBitMask = 1 << 3;
// 获取pixel QA band.
var qa = image.select('QA_PIXEL');
// 明确条件,设置两个值都为0
var mask = qa.bitwiseAnd(cloudShadowBitMask).eq(0)
.and(qa.bitwiseAnd(cloudsBitMask).eq(0));
// 更新掩膜云的波段,最后按照反射率缩放,在选择波段属性,最后赋值给影像
return image.updateMask(mask)
.select("SR_B[1-7]*")
.copyProperties(image, ["system:time_start"]);
}
//Filter image collection for time window, spatial location, and cloud cover
var startDate = ee.Date('2016-01-01');
var endDate = ee.Date('2016-12-31');
var collection = l8
.filterDate(startDate, endDate)
.map(applyScaleFactors)//时间过滤
.map(maskL8sr)
.median()
;
//print(remove_cloud(collection))
var image=collection.clip(roi);
var visualParam = {bands: ['SR_B4', 'SR_B3', 'SR_B2'], min:0.0,max: 0.3};//可视化参数1
print("l8Image",visualParam,image)
Map.centerObject(roi, 11);
Map.addLayer(image, visualParam,"l8Image");三、 分类特征集构建
可以构建NDVI/NDBI/MNDWI作为光谱特征;利用DEM数据的坡度和高程作为地形特征;然后将构建的这些特征作为影像的一个波段进行使用。
var mndwi = image.normalizedDifference(['SR_B3', 'SR_B6']).rename('MNDWI');//计算MNDWI
var ndbi = image.normalizedDifference(['SR_B6', 'SR_B5']).rename('NDBI');//计算NDBI
var ndvi = image.normalizedDifference(['SR_B5', 'SR_B4']).rename('NDVI');//计算NDVI
var strm=ee.Image("USGS/SRTMGL1_003");
var dem=ee.Algorithms.Terrain(strm);
var elevation=dem.select('elevation');
var slope=dem.select('slope');
image=image
.addBands(ndvi)
.addBands(ndbi)
.addBands(mndwi)
.addBands(elevation.rename("ELEVATION"))
.addBands(slope.rename("SLOPE"))四、 样本的选取
选取样本的方法就是在视图窗口用point或polygon进行分类选取,这里要注意在样本的属性设置里要改变图层类型为featurecollection,并添加分类属性landcover与这个类对应的值。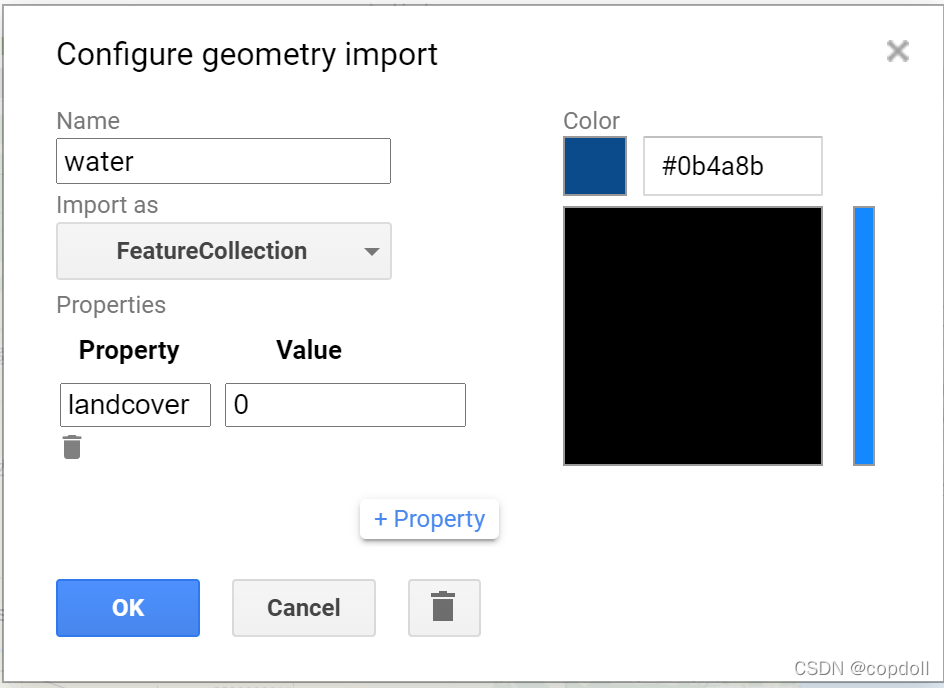
五、样本的处理
这里以选取的透水面和不透水面两类样本进行示例,将两类的全部样本进行混合,然后随机排列,将样本以7:3的比例分为训练集和测试集。
var classNames = butoushuimian2014.merge(toushuimian2014);
var bands = ['SR_B2', 'SR_B3', 'SR_B4', 'SR_B5', 'SR_B6', 'SR_B7','MNDWI','NDBI','NDVI','SLOPE', 'ELEVATION'];
var training = image.select(bands).sampleRegions({
collection: classNames,
properties: ['landcover'],
scale: 30
});
// random uniforms to the training dataset.
var withRandom = training.randomColumn('random');
var split = 0.7;
var trainingPartition = withRandom.filter(ee.Filter.lt('random', split));
var testingPartition = withRandom.filter(ee.Filter.gte('random', split));六、选取合适的分类方法进行分类
下面就可以分类了,除了这里使用的smilerandomForest()随机森林法,还可以使用libsvm/smileCart() 等方法,具体可以查询GEE的函数文档。
var classProperty = 'landcover';
var classifier = ee.Classifier.smileRandomForest(30).train({
features: trainingPartition,
classProperty: 'landcover',
inputProperties: bands
});
var classified = image.select(bands).classify(classifier);
Map.addLayer(classified,imageVisParam3);
print(classified)
var test = testingPartition.classify(classifier);此外,在使用随机森林方法进行分类时,可以根据自己的需要来进行最佳决策树数量的选择和所使用特征的特征重要性计算。
//决策树数量选择
var numTrees = ee.List.sequence(5, 100, 5);
var accuracies = numTrees.map(function(t)
{
var classifier = ee.Classifier.smileRandomForest(t)
.train({
features: trainingPartition,
classProperty: 'landcover',
inputProperties: bands
});
return testingPartition
.classify(classifier)
.errorMatrix('landcover', 'classification')
.accuracy();
});
print(ui.Chart.array.values({
array: ee.Array(accuracies),
axis: 0,
xLabels: numTrees
}));
//随机森林特征重要性
var dict = classifier.explain();
print('Explain:',dict);
var variable_importance = ee.Feature(null, ee.Dictionary(dict).get('importance'));
var chart =
ui.Chart.feature.byProperty(variable_importance)
.setChartType('ColumnChart')
.setOptions({
title: 'Random Forest Variable Importance',
legend: {position: 'none'},
hAxis: {title: 'Bands'},
vAxis: {title: 'Importance'}
});
print(chart);
七、结果评价
使用混淆矩阵、OA、KAPPA系数进行分类效果的评价。
var confusionMatrix = test.errorMatrix('landcover', 'classification');
print('confusionMatrix',confusionMatrix);
print('overall accuracy', confusionMatrix.accuracy());
print('kappa accuracy', confusionMatrix.kappa());
八、各分类类型的面积计算
土地利用分类完成后通常要进行各种地类的面积计算,我这里使用的是pixelArea方式,此外还可以使用count方式。
var areaall = ee.Image.pixelArea().addBands(classified)
.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: "landcover"
}),
geometry: roi,
scale: 30,
maxPixels:10e15,
})
print(areaall)九、 结果输出
这里我是把结果导出到了Drive里,在Google Drive里下载下来就可以在Arcgis和ENVI里进行使用啦~
Export.image.toDrive({
image: classified,
description: 'xiongan_RF',
folder: 'xiongan_RF',
scale: 30,
region: roi,
maxPixels:34e10
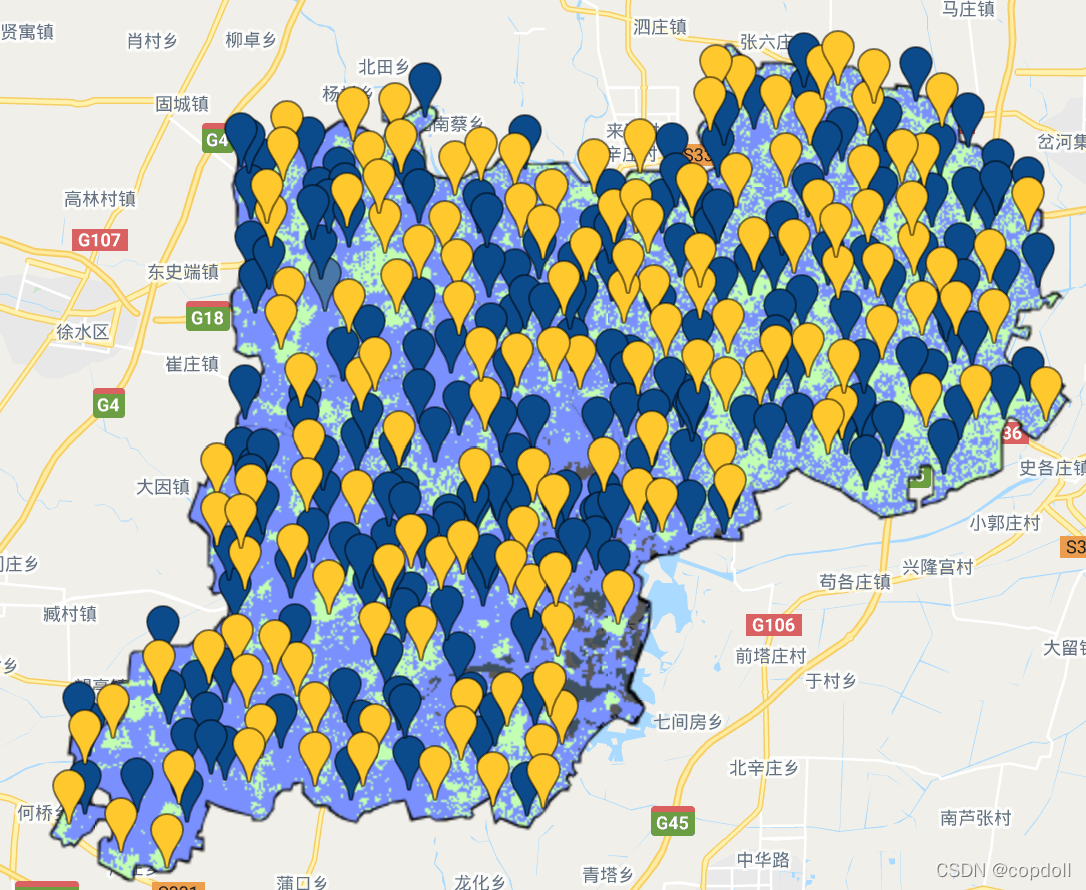
});展示一下用这样的方法得到的分类结果,效果还是可以的(大前提是样本的质和量都要够哈)~
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我有一个像这样的ruby类:require'logger'classTdefdo_somethinglog=Logger.new(STDERR)log.info("Hereisaninfomessage")endend测试脚本行如下:#!/usr/bin/envrubygem"minitest"require'minitest/autorun'require_relative't'classTestMailProcessorClasses当我运行这个测试时,out和err都是空字符串。我看到消息打印在stderr上(在终端上)。有没有办法让Logger和capture_io一起玩得
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使