1.1、先部署好两台mysql数据库,部署mysql可以查看我的文档
2.1、主机配置
vim /etc/my.cnf 或者 vi /etc/my.cnf
#增加一下配置
log-bin=mysql-bin
server_id=101#选择增加的参数
binlog-do-db= 数据库名 #需要同步的数据库
binlog-ignore-db = 数据库名 #不需要同步的数据库
重启数据库:systemctl resatrt mysql
2.2、主机上创建用于复制的数据库账号,可以使用已经创建好的,也可以新建,需要注意的是mysql8及之后版本,需要先创建好数据库账号
#mysql -uxxx -pxxx 进入数据库
#mysql8以下使用
grant replication slave on *.* to '数据库用户'@'%'identified by '123';
grant replication client on *.* to '数据库用户'@'%'identified by '123';
#mysql8及以上使用
grant replication client,replication slave on *.* to '数据库用户'@'%';
#刷新
flush privileges;
2.3、查看主库信息 show master status;
要记住file 和 position的值,也就是第一和第二列,后面用的上
2.4、配置从库
vim /etc/my.cnf 或者 vi /etc/my.cnf
#增加一下配置
server_id=202 #不能和主库的值一样
重启数据库:systemctl resatrt mysql
2.5、从库关联配置
#进入mysql数据库mysql -uxxx -pxxx
#停掉从的服务,这里一定要停掉服务再去执行下面的
stop slave; #8以下的可以试试slave stop
#配置关联master,3306可以默认不写,master_log_file和master_log_pos参考之前主库show masterstatus;查询出来的信息。
change master to master_host='192.168.3.206', master_port=3306,master_user='root', master_password='root',master_log_file='binlog.000004',master_log_pos=156;
#启动服务
start slave; #8以下的可以试试slave start
#查看是否成功
show slave status \G;
需要保证框起来的都是yes
2.6、show slave status \G;常见问题,本人部署中发现Slave_IO_Running: No,如果这里不正确,可以查看下他的报错
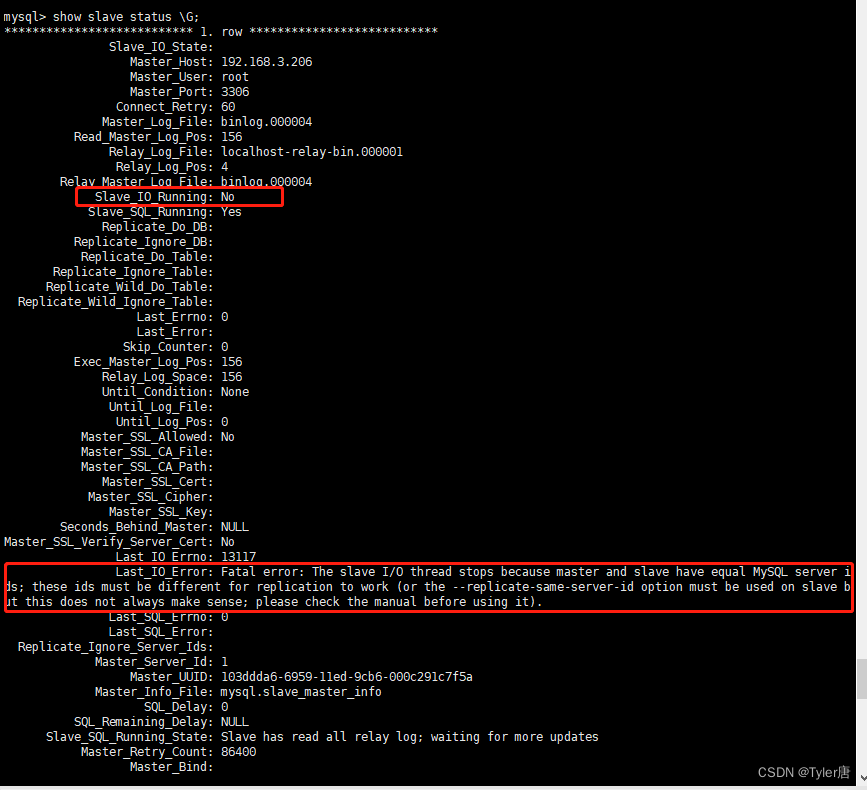
这里常见的有三种报错,一个是报server ids,一个是server UUIDs,还有一种是主库端口不通
#遇见UUIDs
找到data文件夹下的auto.cnf文件,修改里面的uuid值,保证各个主从的uuid不一样,重启数据库即可,可使用find / -name auto.cnf 查找
#遇见ids
找到/etc/my.cnf配置文件中的server_id,修改从库的server_id保证和复制结构中的其他db不一样,重启数据库即可,但是我这里试了依然不行,后面使用下面的方法
#查看server_id
show variables like 'server_id';
#停止slave后,手动修改server_id
mysql> stop slave;
mysql> set global server_id=2;#此处的数值和my.cnf里设置的一样就行
mysql> start slave;
再次查看show slave status \G;
这里需要注意的是我本地部署的时候,发现只要一重启数据库,server_id就会重置成1,然后和主库就一样了,所以这里不能重启数据库,如果知道这个是什么问题,可以留言给我补充。
3.1、使用mysqldump
#在从库使用mysqldump命令复制数据
[root@slave2 ~]# mysqldump --single-transaction --all-databases --master-data=1 --host=192.168.2.138 --user=root --password=root --apply-slave-statements | mysql -uroot -proot-hlocalhost
参数说明
–single-transaction参数可以对Innodb表执行非锁定导出。此选项将事务隔离模式设置为REPEATABLE READ,并在转储数据之前向服务器发送START TRANSACTION SQL语句。它仅适用于Innodb等事务表,因为它会在发出START TRANSACTION时转储数据库的一致状态,而不会阻塞任何应用程序。因此这里假定:1. 所有的应用数据表都使用Innodb引擎。2. 所有系统表数据在备份过程中不会发生变化。
–master-data参数会导致转储输出包含类似 CHANGE MASTER TO MASTER_LOG_FILE=‘binlog.000004’, MASTER_LOG_POS=1480; 的SQL语句,该语句指示主库的二进制日志坐标(文件名和位置)。如果选项值为2,则CHANGE MASTER TO语句将写为SQL注释,因此仅提供信息,不会执行。如果参数值为1,则该语句不会写为注释,并在重新加载转储文件时执行。如果未指定选项值,则默认值为1。
–apply-slave-statements参数会在CHANGE MASTER TO语句之前添加STOP SLAVE语句,并在输出结尾处添加START SLAVE语句,用来自动开启复制。
mysqldump方式的优点是可以进行部分复制,如在配置文件中定义replicate-do-table=db1.*,则用这种方法可以只复制db1库而忽略其它复制事件。缺点是由于mysqldump会生成主库转储数据的SQL语句,实际是一种逻辑备份方式所以速度较慢,不适用于大库。
3.2、如果可以脱机复制直接的数据,可以使用下面的方法
#1、停止复制的所有实例,在主从分别执行
ln -s /usr/local/mysql/bin/mysqladmin /usr/bin/mysqladmin
mysqladmin -hlocalhost -uroot -pwwwwww shutdown
#2、主库复制数据到从库
cd /data
scp -r mysql/* root@192.168.3.208:/usr/local/mysql/data/ #从库的数据文件路径
#3、在从库执行命令,删除auto.cnf文件
cd /data/mysql
rm -rf auto.cnf
#4、重启 实例,主从都需要执行
systemctl start mysql
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我是ruby的新手,正在配置IRB。我喜欢pretty-print(需要'pp'),但总是输入pp来漂亮地打印它似乎很麻烦。我想做的是默认情况下让它漂亮地打印出来,所以如果我有一个var,比如说,'myvar',然后键入myvar,它会自动调用pretty_inspect而不是常规检查。我从哪里开始?理想情况下,我将能够向我的.irbrc文件添加一个自动调用的方法。有什么想法吗?谢谢! 最佳答案 irb中默认pretty-print对象正是hirb被迫去做。Theseposts解释hirb如何将几乎所有内容转换为ascii表。虽
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin