# GET请求方式(固定写法)
# indexName 要查询的索引库
# _search 查询语句的固定格式
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}注:不会把所有查询到的结构都显示,默认只显示10条数据
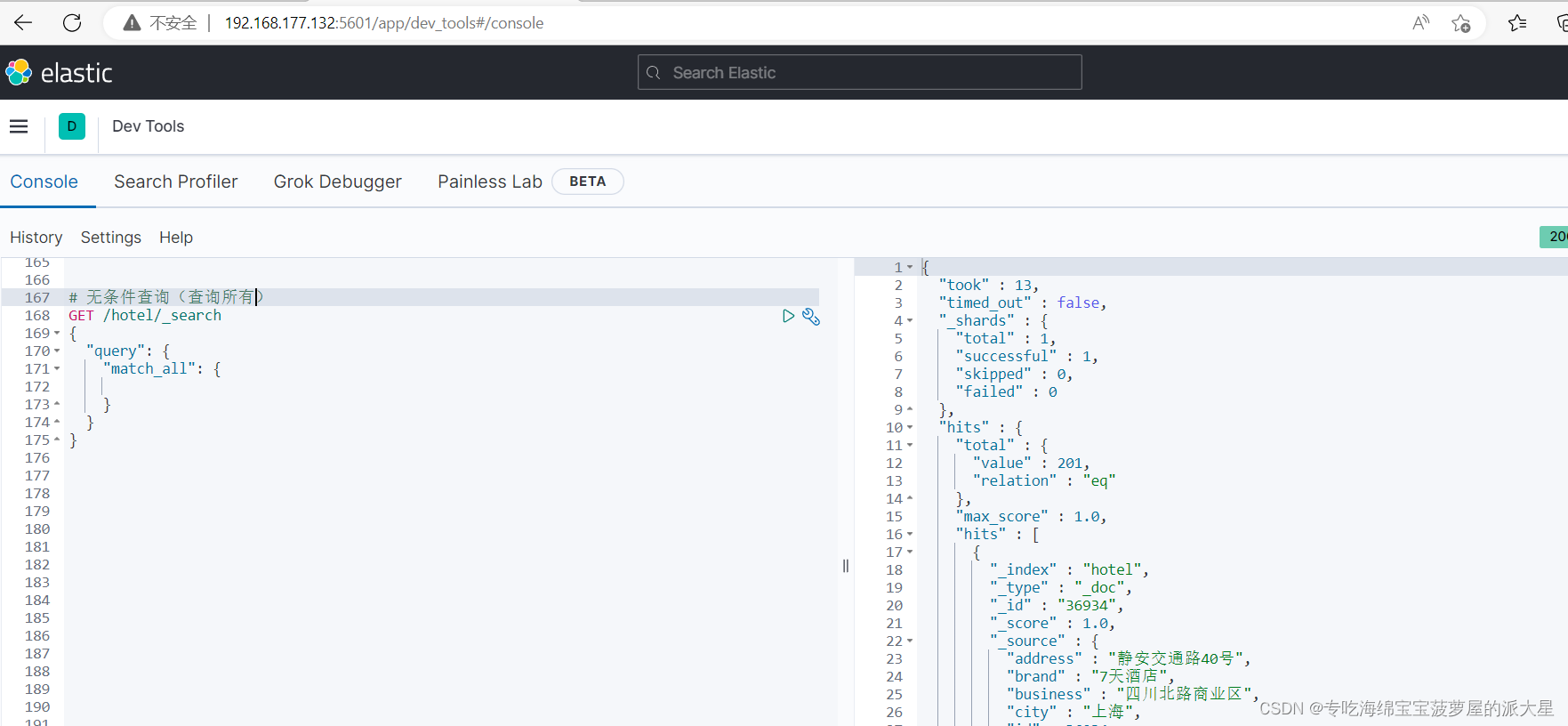
# 查询所有
# GET请求方式(固定写法)
# indexName 要查询的索引库
# _search 查询语句的固定格式
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
全文检索查询的基本流程如下:
对用户搜索的内容做分词,得到词条
根据词条去倒排索引库中匹配,得到文档id
根据文档id找到文档,返回给用户
比较常用的场景包括:
商城的输入框搜索
百度输入框搜索
常见的全文检索查询包括:
match查询:单字段查询
multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件
全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索
语法:
# match 全文检索查询的一种语句
# FIELD 要查询的字段名
# TEXT 查询条件
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}示例:
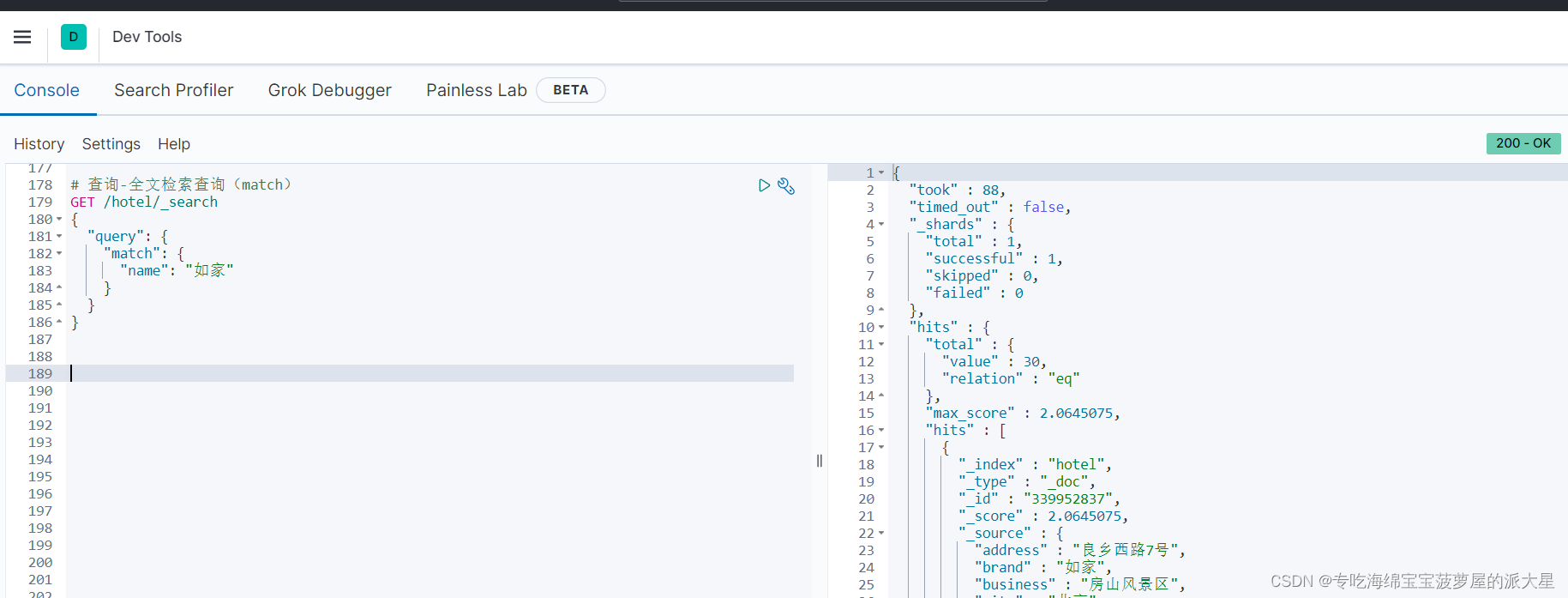
# 查询-全文检索查询(match-单字段查询)
GET /hotel/_search
{
"query": {
"match": {
"name": "如家"
}
}
}
与match查询类似,只不过允许同时查询多个字段,
注:不推荐使用此方法,因为查询多个字段,查询的性能不佳,推荐使用虚拟字段查询
虚拟字段查询,也就是在把频繁查询的多个字段,复制一份到一个all字段中,以后同时查询这几个字段时,可以直接使用match查询all字段
语法:
# multi_match 全文检索查询的一种语句
# FIELD 要查询的字段名
# TEXT 查询条件
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD2"]
}
}
}示例:
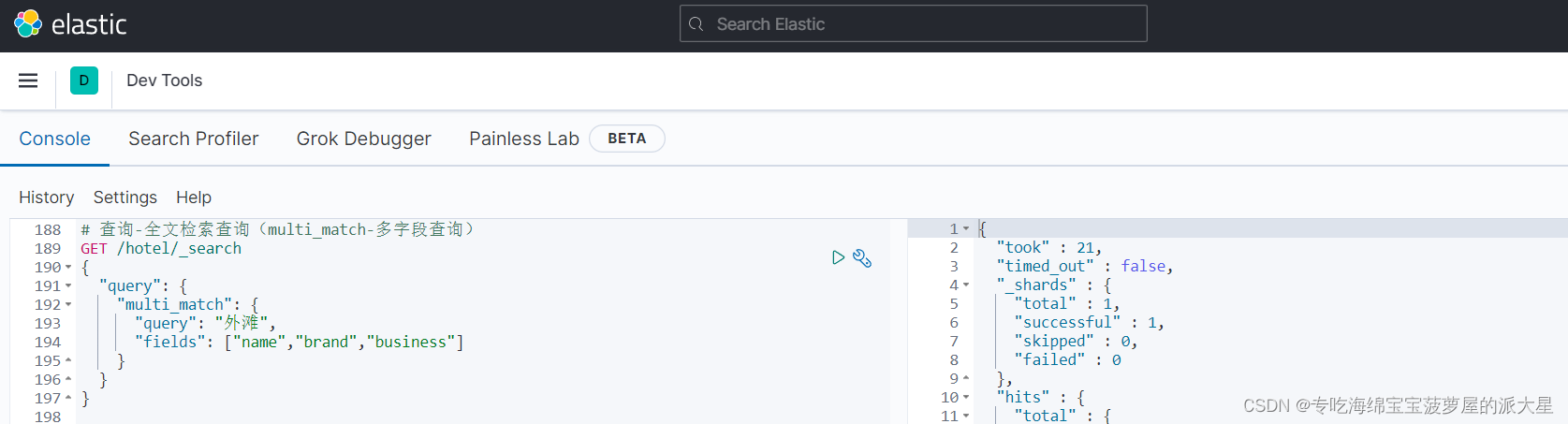
# 查询-全文检索查询(multi_match-多字段查询)
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩",
"fields": ["name","brand","business"]
}
}
}
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。
常见的有:
term:根据词条精确值查询
range:根据值的范围查询
语法说明:
# term查询
# FIELD 查询字段名
# value 固定写法
# VALUE 查询条件
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}示例
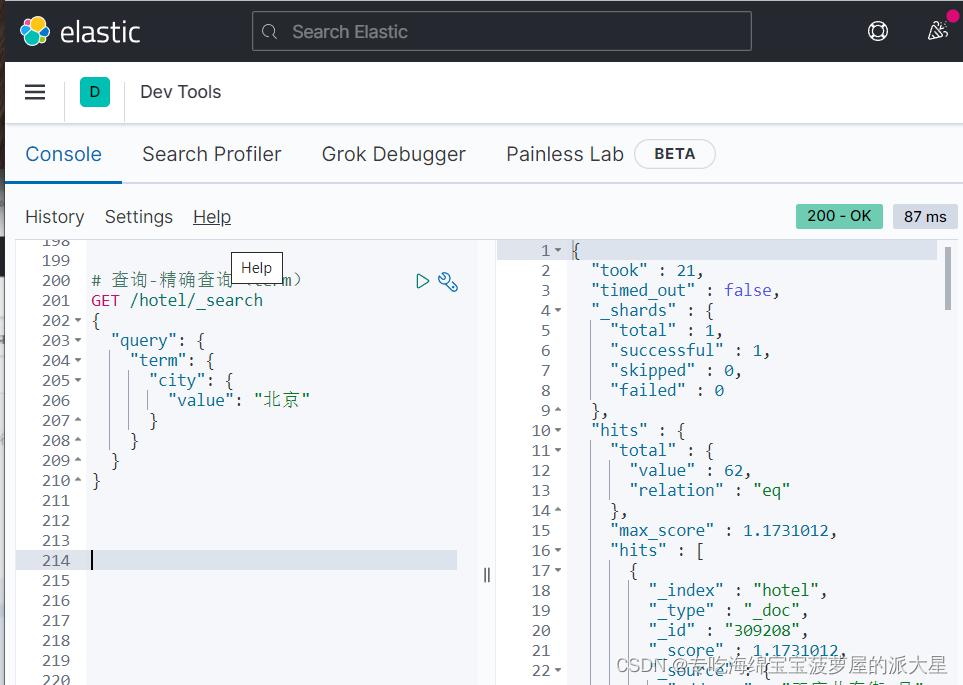
# 查询-精确查询(term)
GET /hotel/_search
{
"query": {
"term": {
"city": {
"value": "北京"
}
}
}
}
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
语法:
# range查询
# FIELD 查询字段名
# 这里的gte代表大于等于,gt则代表大于
# lte代表小于等于,lt则代表小于
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10,
"lte": 20
}
}
}
}示例:
# 查询-精确查询(range)
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gte": 100,
"lte": 200
}
}
}
}
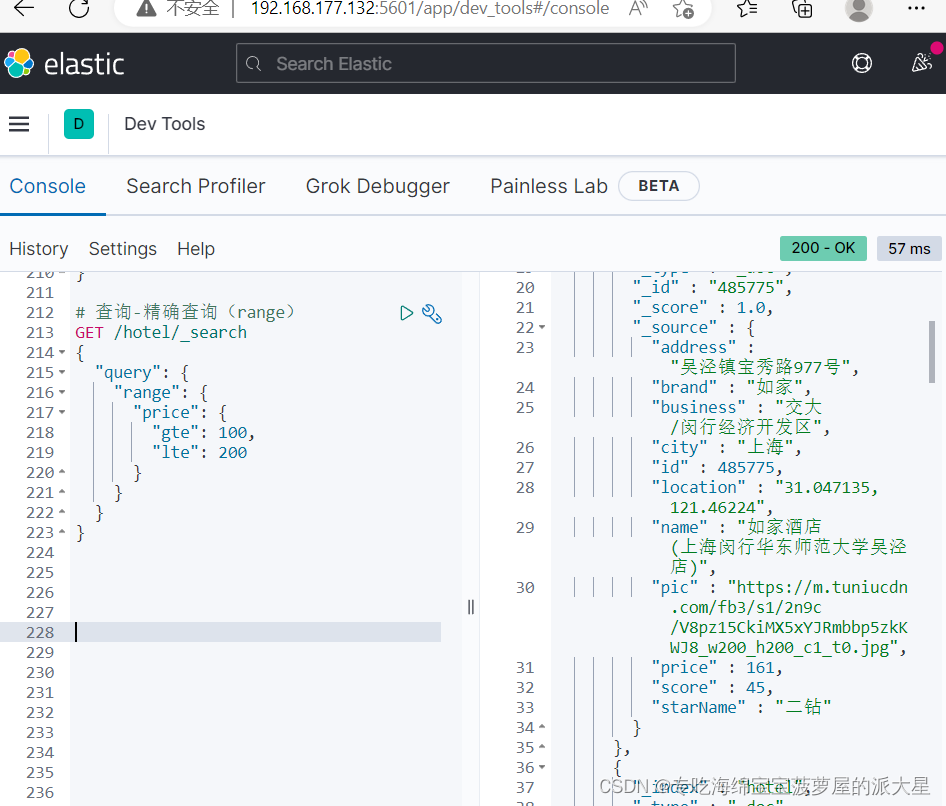
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档:Geo queries | Elasticsearch Guide [8.5] | Elastic
常见的使用场景包括:
携程:搜索我附近的酒店
滴滴:搜索我附近的出租车
微信:搜索我附近的人
实际开发用的少!!!
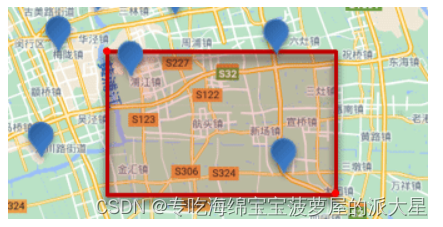
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
语法如下:
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:
语法说明:
# geo_distance 查询
# FIELD 文档中保存经纬度的字段名
# distance 距离半径
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}示例:
# 查询-距离查询
GET /hotel/_search
{
"query": {
"geo_distance":{
"location": "31.047235, 121.46224",
"distance": "3km"
}
}
}
复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。
常见的有两种:
fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
在elasticsearch中,早期使用的打分算法是TF-IDF算法,公式如下:

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

语法说明
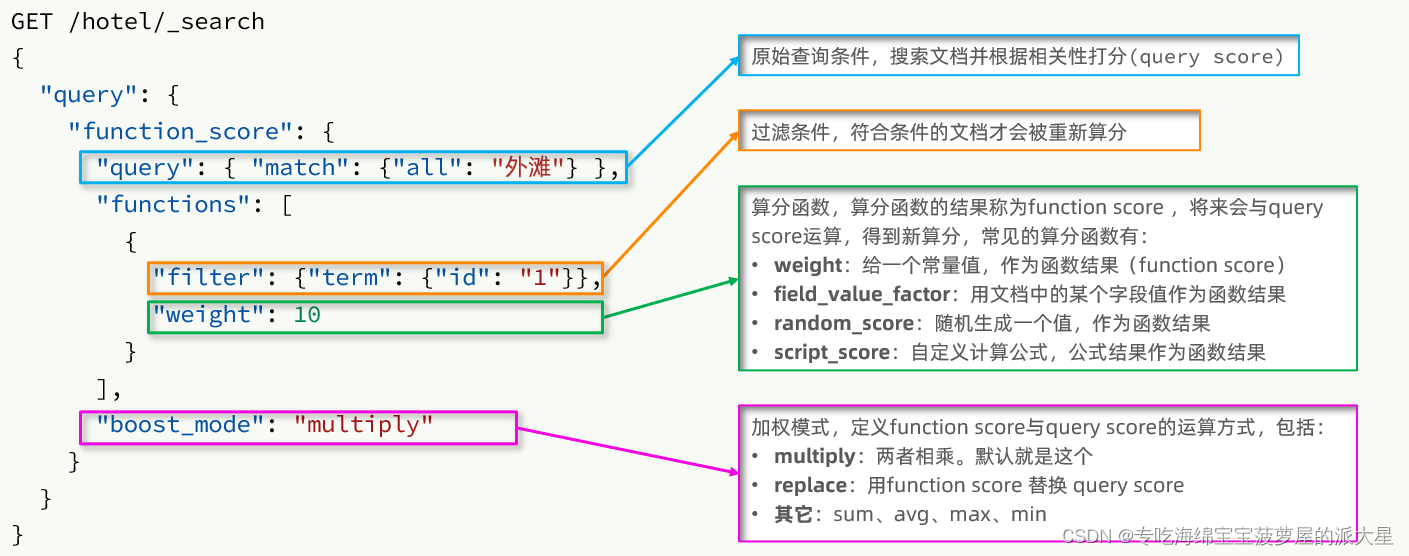
function score 查询中包含四部分内容:
原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
过滤条件:filter部分,符合该条件的文档才会重新算分
算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
weight:函数结果是常量
field_value_factor:以文档中的某个字段值作为函数结果
random_score:以随机数作为函数结果
script_score:自定义算分函数算法
运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
multiply:相乘
replace:用function score替换query score
其它,例如:sum、avg、max、min
function score的运行流程如下:
1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
2)根据过滤条件,过滤文档
3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
过滤条件:决定哪些文档的算分被修改
算分函数:决定函数算分的算法
运算模式:决定最终算分结果
示例:
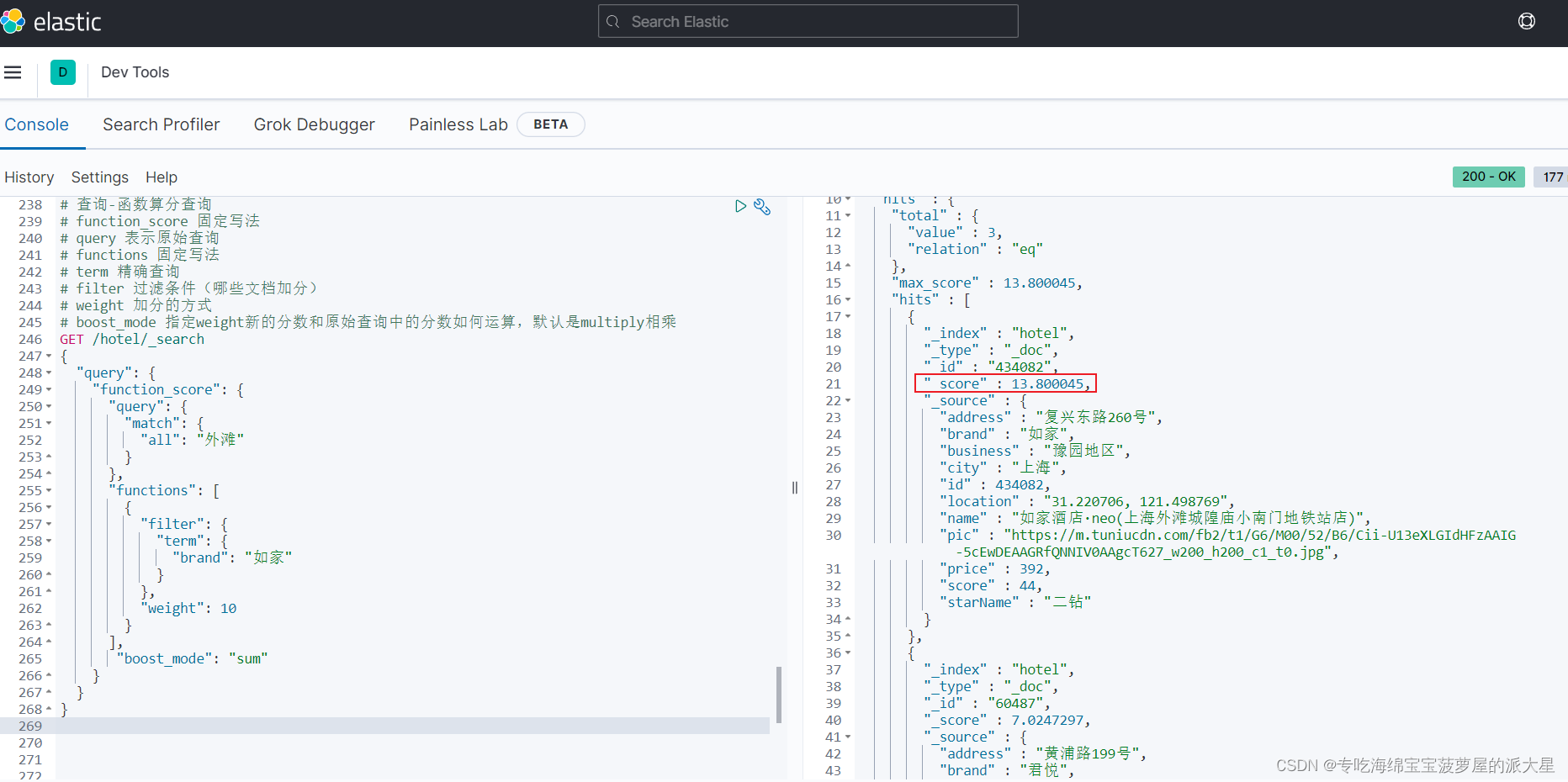
# 查询-函数算分查询
# function_score 固定写法
# query 表示原始查询
# functions 固定写法
# term 精确查询
# filter 过滤条件(哪些文档加分)
# weight 加分的方式
# boost_mode 指定weight新的分数和原始查询中的分数如何运算,默认是multiply相乘
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 10
}
],
"boost_mode": "sum"
}
}
}
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。
子查询的组合方式有:
must:必须匹配每个子查询,类似“与”
should:选择性匹配子查询,类似“或”
must_not:必须不匹配,不参与算分,类似“非”
filter:必须匹配,不参与算分
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
其它过滤条件,采用filter查询。不参与算分
语法示例:
# must 是一个数组,可以有多个条件,以,逗号分隔,是与操作,
# 所有的全文检索查询(模糊查询)都可以使用must,参与算分
# filter 不参与算分,除了模糊查询之外的都可以使用filter
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "上海" }}
],
"should": [
{"term": {"brand": "皇冠假日" }},
{"term": {"brand": "华美达" }}
],
"must_not": [
{ "range": { "price": { "lte": 500 } }}
],
"filter": [
{ "range": {"score": { "gte": 45 } }}
]
}
}
}示例:
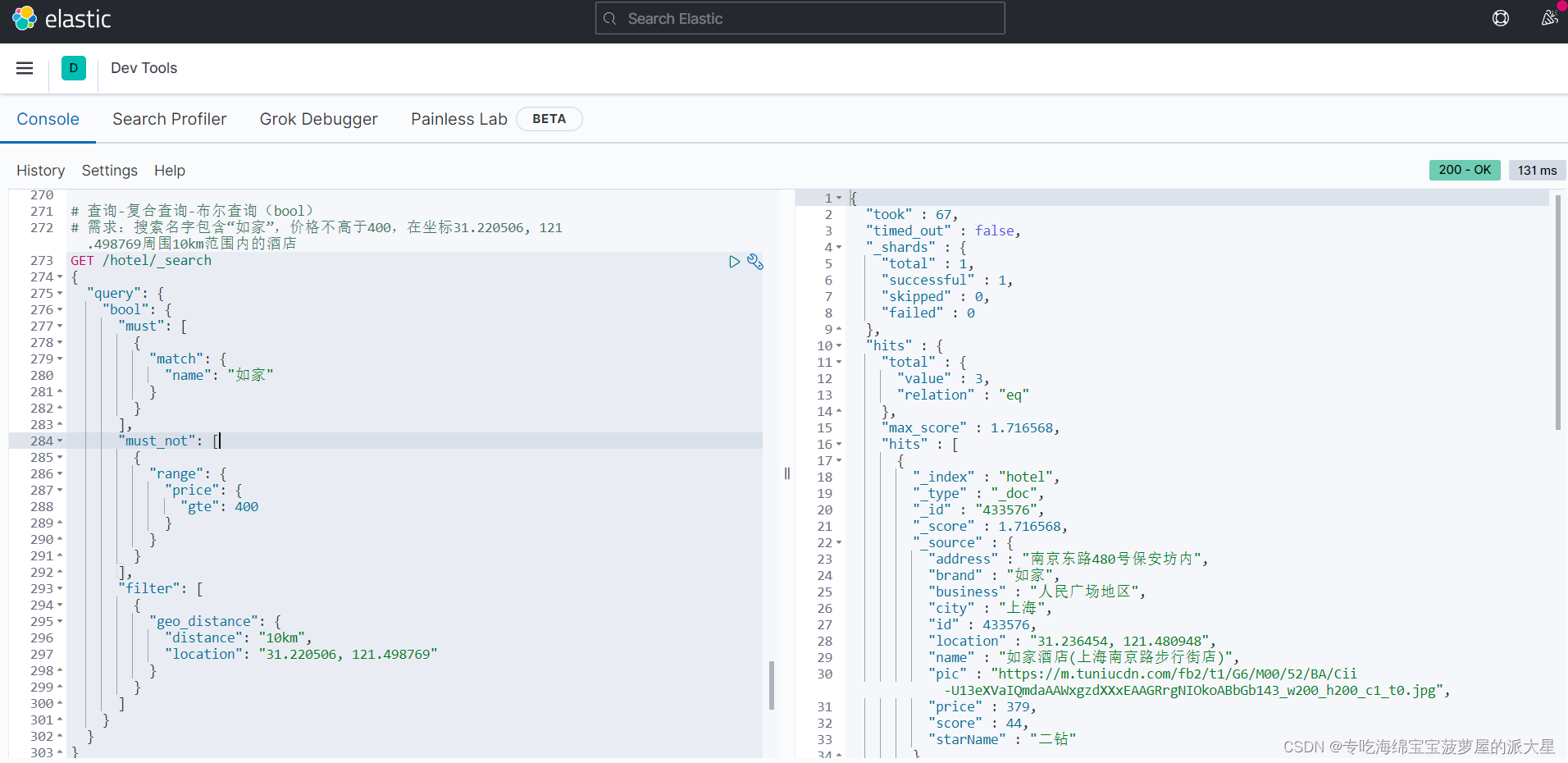
# 查询-复合查询-布尔查询(bool)
# 需求:搜索名字包含“如家”,价格不高于400,在坐标31.220506, 121.498769周围10km范围内的酒店
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}
}
],
"must_not": [
{
"range": {
"price": {
"gte": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": "31.220506, 121.498769"
}
}
]
}
}
}
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
我正在尝试找出如何为我的Ruby项目创建一种“无类DSL”,类似于在Cucumber步骤定义文件中定义步骤定义或在Sinatra应用程序中定义路由。例如,我想要一个文件,其中调用了我的所有DSL函数:#sample.rbwhen_string_matches/hello(.+)/do|name|call_another_method(name)end我认为用我的项目特有的一堆方法污染全局(内核)命名空间是一种不好的做法。因此方法when_string_matches和call_another_method将在我的库中定义,并且sample.rb文件将以某种方式在我的DSL方法的上下文中