哈喽兄弟们
在大家的日常python程序的编写过程中,都会有自己解决某个问题的解决办法,或者是在程序的调试过程中,用来帮助调试的程序公式。
小编通过几十万行代码的总结处理,总结出了22个python万用公式,可以帮助大家解决在日常的python编程中遇到的大多数问题,一起来看看吧。

对于数值的输入问题,是很多笔试题目中经常遇到的问题,一次性输入多个参数值 ,可以节省时间和代码量,为后面的程序编写节省时间。
# 确定数值的输入时
num1,num2 = map(int,input().split())
print("num1:",num1)
print("num2:",num2)
# 不确定数值的输入时
list1 = list(map(int,input().split()))
print("list1:",list1)
运行结果
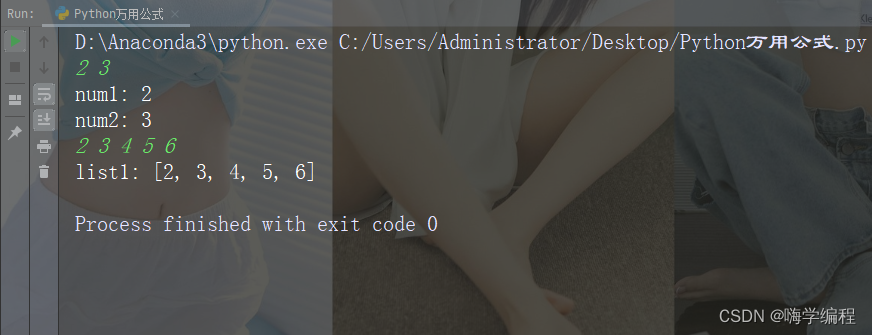
在进行数值的迭代时,可以利用enumerate的内置函数来获取可迭代对象数值的同时,得到数值的索引,并利用索引对数值进行操作。
list2 = [1,2,3,4,5,6]
for k, v in enumerate(list2):
if k % 2 == 0:
print("v**2:",v**2)
else:
print("v:",v)
运行结果
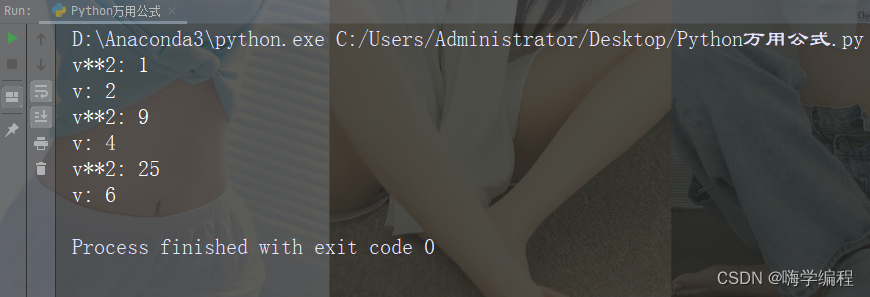
通过下图的程序,可以进行对象的内存占用量查询。
from sys import getsizeof
num = 1
print(getsizeof(num))
运行结果
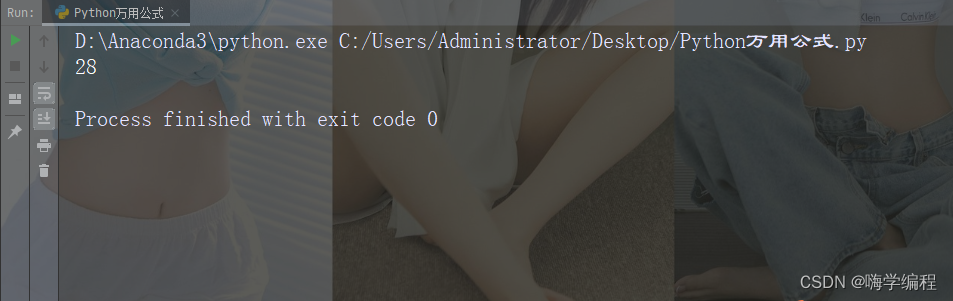
通过内置函数id(),可以进行不同变量的内存地址的查询
num1 = 20
str1 = "hello world"
print(id(num1))
print(id(str1))
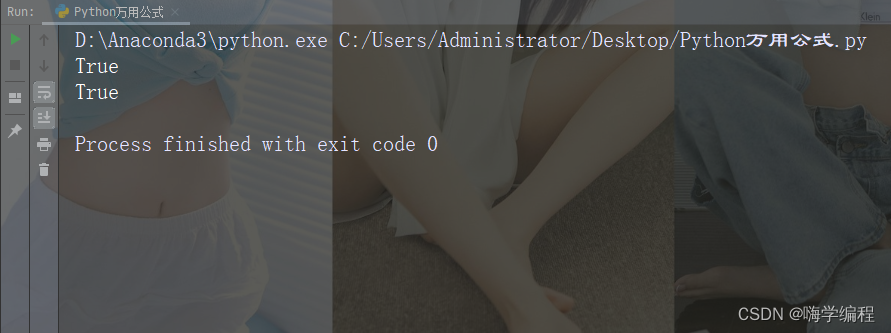
运行结果

不同的字符串,可以有相同的字母组成,同样,列表也可以有相同的元素组成,通过下述的程序,可以判断不同字符串或者是列表是否有相同的元素。
def CheckStr(gen1,gen2):
return sorted(gen1) == sorted(gen2)
print(CheckStr("python","python"))
print(CheckStr([1,2,3],[3,2,1]))
运行结果
当处理json数据或者是数据库中的内容时,会用到字典的合并,有时候还会遇到具有相同键值的字典,可以通过下图程序中的两种方法进行解决。
dict1 = {"name":['Jame','Alice'],"num":["212019","312016"]}
dict2 = {"sex":["M","F"]}
# 方法1
finaldict = {**dict1,**dict2}
print(finaldict)
# 方法2
finaldict = dict1.copy()
finaldict.update(dict2)
print(finaldict)
运行结果
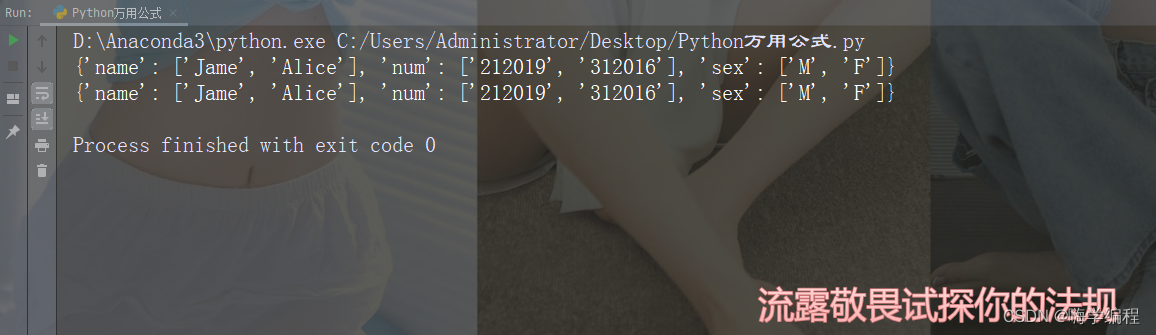
在程序运行中,会遇到保存一些图片、文字的情况,这个时候就需要利用程序来判断某个文件或者文件夹是否存在。
import os
def CheckFile():
print("文件夹存在:",os.path.exists("data"))
if not os.path.exists("data"):
os.mkdir("data")
CheckFile()
运行结果
通过Python语言的内联for循环的方式,实现对于列表中的所有元素的操作。
list8 = range(1,8)
list_squares = [i**2 for i in list8]
print(list_squares)
运行结果

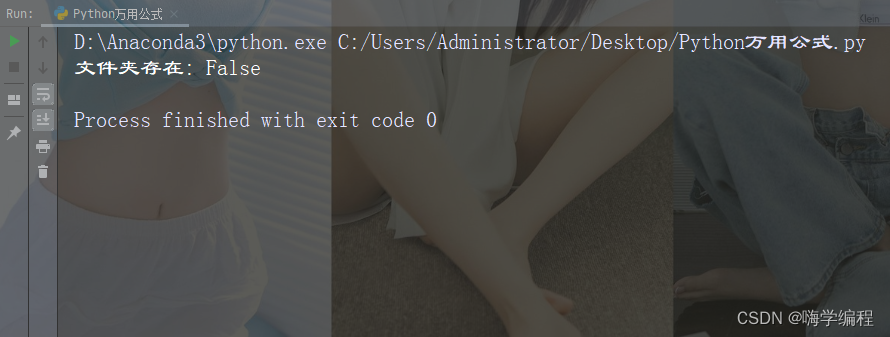
将两个列表转换为字典,常见的情况是一个列表作为键,另一个列表作为值来构造字典。
list1 = ['James','Alice','Hoton']
list2 = [88,86,91]
# 方法1 利用zip内置函数
dict1 = dict(zip(list1,list2))
# 方法2 去除dict的隐式转换
dict2 = {key:value for key,value in zip(list1,list2)}
# 方法3 利用for循环
dict3 = {}
for k, v in zip(list1,list2):
if k not in dict3.keys():
dict3[k] = v
print("dict1:",dict1)
print("dict2:",dict2)
print("dict3:",dict3)
运行结果
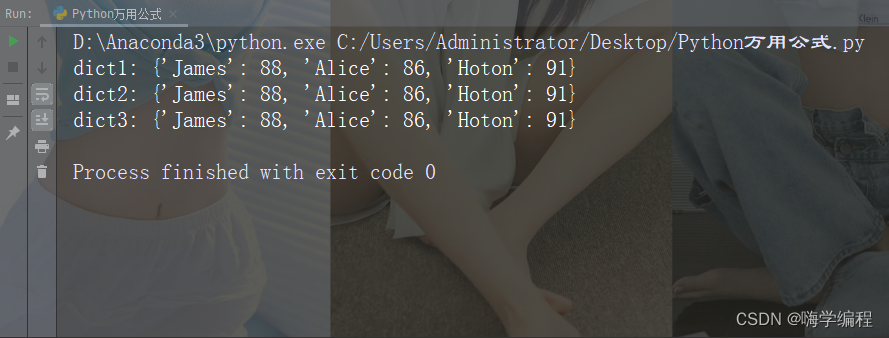
当大家需要对一个字符串列表进行排序时,可以利用下图中的程序进行排序。
list1 = ['James','Alice','Hoton','Cris']
print(sorted(list1,key=lambda x:x.lower()[0])) # 按照字符串的第一个字母排序
print(sorted(list1,key=lambda x:x.lower()[-1])) # 按照字符串的最后一个字母排序
运行结果
利用if和else的操作,可以基于某些条件过滤数据,如下图所示。
list11 = list(range(1,20))
print("偶数平方:",[i**2 if i % 2 == 0 else i for i in list11])
运行结果

对于两个列表的合并,可以通过花式的列表合并来将两个列表组合成一个新的列表。
list1 = ["1","2","3","4"]
list2 = ["one","two","three","four"]
new_list = [x + y for x,y in zip(list1,list2)]
print("逐元素相加:",new_list)
运行结果
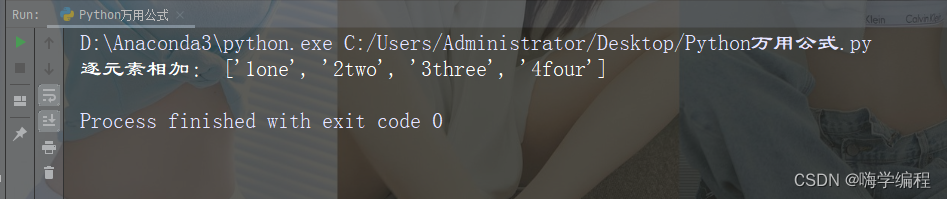
当有字典组成的列表时,可以按照字典的键值对列表进行排序。
dict1 = [
{"name":"James",
"num":25},
{"name":"Alice",
"num":39},
{"name":"Hoton",
"num":35}
]
# 方法1 利用字典的sort函数
dict1.sort(key=lambda item:item["num"])
print(dict1)
# 方法2 利用sorted函数
dict1 = sorted(dict1,key=lambda item:item["num"])
print(dict1)
运行结果
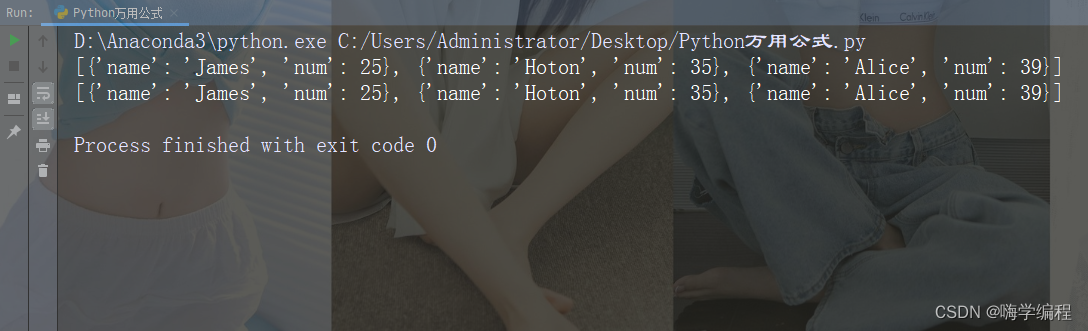
对于程序计算时间 的计算,可以帮助大家对于程序或者算法的性能有更好的了解。
from time import sleep
def funcl():
for i in range(10000000):
a = i
sleep(2)
# 方法1
from datetime import datetime
start = datetime.now()
funcl()
print("程序执行所用的时间为:",datetime.now()-start)
# 方法2
import time
start_time = time.time()
funcl()
print("程序执行所用的时间为:",time.time()-start_time)
运行结果
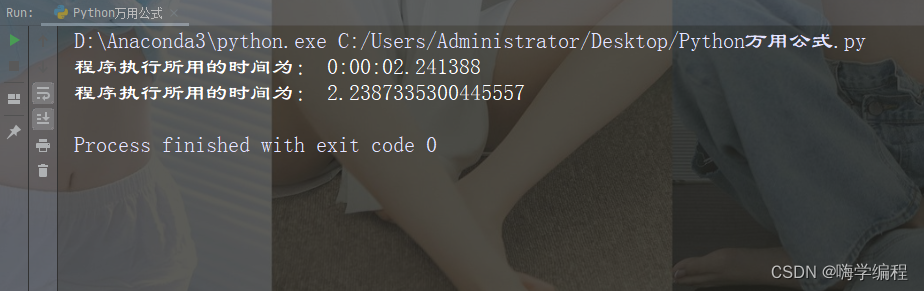
对于子字符串的检查是Python日常应用中经常遇到的一个问题,当一个字符串中包含某些关键子字符串时,将这些字符串进行打印。
str_list = ["轻松学python","hello world","轻松玩python","嗨学编程"]
keywords = 'python'
for strs in str_list:
if keywords in strs:
print(strs)
运行结果
对于Python的输入,逻辑和输出。这三个部分在编写代码时都需要某种格式,Python提供了多种格式化字符串的方法,以便获得更好和易于阅读的输出。
name = "爱坤"
num = 100
# 方法1 字符串相加
print("我的名字是"+name+",我的成绩是"+str(num)+"。")
# 方法2 Python3 中的F-strings
print(f"我的名字是{name},我的成绩是{num}。")
# 方法3 join函数
print(''.join(["我的名字是",name,",我的成绩是",str(num),"。"]))
# 方法4 操作字符处理
print("我的名字是%s,我的成绩是%d。" % (name,num))
# 方法5 format(python2.7以上的版本)
print("我的名字是{},我的成绩是{}。".format(name,num))
运行结果
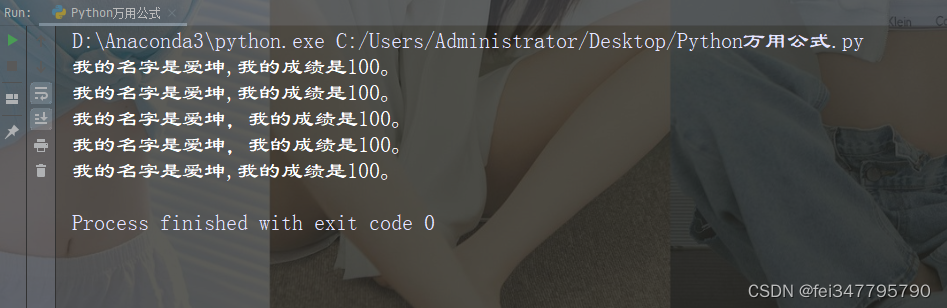
在Python语言中,提供了使用try,except和finally块处理异常报错的方法
# 错误1 扣除为0
try:
num1 = 10
num2 = 0
print(num1 / num2)
except ZeroDivisionError :
print("除数不能为0")
print("=================")
# 错误2 找不到文件
try:
with open("data.txt",'r') as fr:
print(fr.readlines())
except IOError:
print("该文件不存在")
finally:
print("程序执行结束")
运行结果
对于列表等可迭代对象中的元素进行频次的统计,也是一项非常常见的问题。
list1 = [1,2,3,4,5,6,7,8,3,3,4,5,2,3,2]
# 方法1 利用for循环统计
frequ_dict = {}
for i in list1:
if i in frequ_dict.keys():
frequ_dict[i] += 1
else:
frequ_dict[i] = 1
print(frequ_dict)
# 方法2 李彤Counter类
from collections import Counter
Counter = Counter(list1)
print(Counter.most_common())
运行结果

下图的程序中,不需要if-else的操作,即可制作一个简易的计算器。
from operator import add, sub, truediv, mul
operation = {
"+" : add,
"-" : sub,
"/" : truediv,
"*" : mul,
"**" : pow
}
print(operation['+'](2,3))
print(operation['*'](2,3))
print(operation['**'](2,3))
print(operation['/'](10,3))
运行结果
通过一行程序,可以调用多个不同的函数,进行计算。
def add(x,y):
return x + y
def sub(x,y):
return x - y
x,y = 2,3
print((sub if x > y else add)(x,y))
# 通过条件判断执行的函数
运行结果
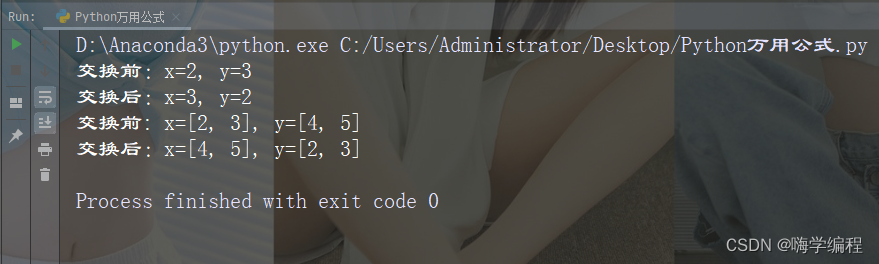
Python中的交换,不仅仅可以直接通过a,b = b,a的方式进行数值的交换,而且还可以进行列表等可迭代对象的交换。
x, y = 2, 3
print("交换前:x={}, y={}".format(x, y))
x, y = y, x
print("交换后:x={}, y={}".format(x, y))
x, y = [2, 3], [4,5]
print("交换前: x={}, y={}".format(x, y))
x, y = y, x
print("交换后:x={}, y={}".format(x, y))
运行结果
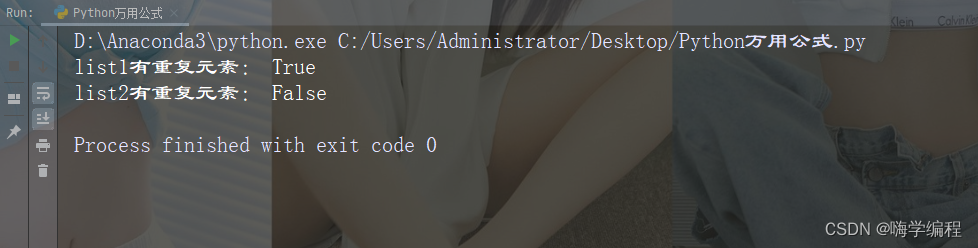
对于检查列表中是否有重复的元素,可以通过将列表转换为set来快速检查。
list1 = [1,2,3,4,2,4,5]
list2 = [1,2,3,4,5,6,7]
print("list1有重复元素:",len(list1) != len(set(list1)))
print("list2有重复元素:",len(list2) != len(set(list2)))
# 兄弟们学习pytho n,有时候不知道怎么学,从哪里开始学。掌握了基本的一些# 语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
# 那么对于这些大末名片自取即可!兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及源代码!、
都在这个群 872937351 自即可
以上的22个Python万用公式,可以帮助大家解决大多数日常的Python问题。
当在程序运行的过程中遇到问题时,大家只需要耐心的排查,就能够找到对应的错误,进行解决,在不断解决错误的过程中不断总结和提高,提升自己的能力和经验。
今天的分享就到这里结束了,咱们下次见!
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源