spdlog日志库说明文档(超详细)spdlog是一个开源、快速、只有头文件的C++11日志库,code地址在https://github.com/gabime/spdlog,基础示例在https://github.com/gabime/spdlog#readme
首先将代码下载下来https://github.com/gabime/spdlog,解压后会得到以下文件,其中include文件夹里是所需的头文件和源码
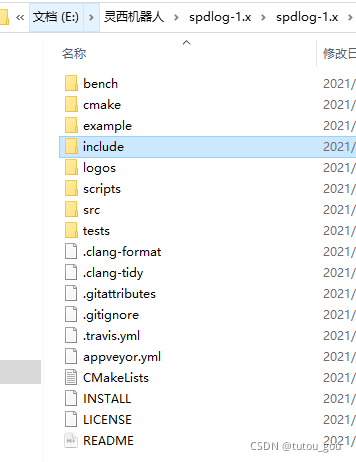

新建一个C++控制台应用程序项目,然后在项目属性页C/C++中常规的附加包含目录中加上include的路径,然后在.cpp中就可以开始测试了
直接在控制台输出,比较低级。
#include "spdlog/spdlog.h"
int main()
{
//输出不同级别的日志
spdlog::info("Hello, {}!", "World");
spdlog::info("Welcome to spdlog!");
spdlog::error("Some error message with arg: {}", 1);
spdlog::warn("Easy padding in numbers like {:08d}", 12);
spdlog::critical("Support for int: {0:d}; hex: {0:x}; oct: {0:o}; bin: {0:b}", 42);
spdlog::info("Support for floats {:03.2f}", 1.23456);
spdlog::info("Positional args are {1} {0}..", "too", "supported");
spdlog::info("{:<30}", "left aligned");
}

warn,critical,info为不同等级的log,输出在控制台会以不同颜色表示
my_logger作为日志的生产者可以初始化为一个全局变量,这种用法功能也比较少
#include <iostream>
#include "spdlog/spdlog.h"
#include "spdlog/sinks/basic_file_sink.h" // support for basic file logging
int main()
{
try
{
//在logs/basic.txt中写下Hello world
auto my_logger = spdlog::basic_logger_mt("sbasic_logger", "logs/basic.txt");
my_logger->info("Hello {}", "world");
}
catch (const spdlog::spdlog_ex& ex)
{
std::cout << "Log initialization failed: " << ex.what() << std::endl;
}
}
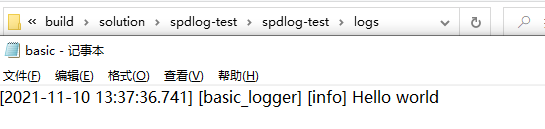
auto my_logger = spdlog::basic_logger_mt("basic_logger", "logs/basic.txt");中”my_logger“为logger名称,可以随意命名
注意,logger使用完,程序关闭之前需要调用drop函数释放logger对象,如果程序没有关闭,就无法建立同样名称的logger
这种basic log不带滚动,日志文件会一直被写入,不断变大
函数名带后缀_mt的意思是multi thread(速度稍微慢一点点,考虑了多线程并发),_st的意思是single thread(速度较快)
循环日志文件可以解决两个问题:
#include <iostream>
#include "spdlog/spdlog.h"
#include "spdlog/sinks/rotating_file_sink.h" // support for rotating file logging
int main()
{
try
{
auto file_logger = spdlog::rotating_logger_mt("file_logger", "myfilename",
1024 * 1024 * 5, 10);
file_logger->set_level(spdlog::level::debug);
int i = 0;
while (i < 1000000)
{
file_logger->debug("Async message #{}", i);
i++;
}
}
catch (const spdlog::spdlog_ex& ex)
{
std::cout << "Log initialization failed: " << ex.what() << std::endl;
}
}
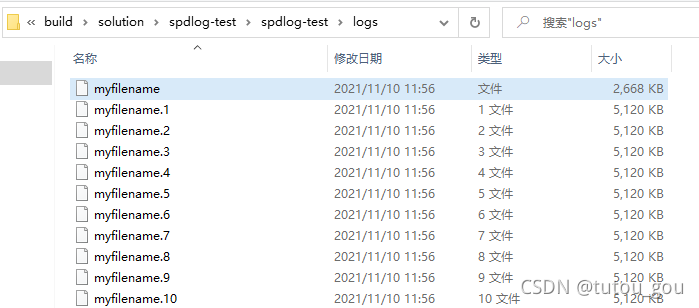
区别于单一文件,循环日志的生产者类是rotating_logger_mt。rotating_logger_mt初始化的时候需要4个参数。
5MB;代码中生成100万条日志,数据大约是65MB。那么在根目录下就会出现10个日志文件,后缀名由1~9。
rotating log 滚动日志,当日志文件超出规定大小时,会删除当前日志文件中所有内容,重新开始写入
每天会新建一个日志文件,新建日志文件的时间可以自己设定
#include <iostream>
#include "spdlog/spdlog.h"
#include "spdlog/sinks/daily_file_sink.h"
int main() {
// Create a daily logger - a new file is created every day on 2:30am
auto daily_logger = spdlog::daily_logger_mt("daily_logger", "logs/daily.txt", 2, 30);
// trigger flush if the log severity is error or higher
daily_logger->flush_on(spdlog::level::err);
daily_logger->info(123.44);
return 0;
}

如果程序不退出,每天2:30会创建新的文件
大型项目中经常有很多场景是对时间有着严苛要求的,此时异步调用打印日志功能就显得十分重要了。
#include <iostream>
#include "spdlog/spdlog.h"
#include "spdlog/async.h"
#include "spdlog/sinks/rotating_file_sink.h"
int main(){
spdlog::init_thread_pool(10000, 1);
auto file_logger = spdlog::rotating_logger_mt<spdlog::async_factory>("file_logger", "mylogs", 1024 * 1024 * 5, 100);
int i = 0;
file_logger->set_level(spdlog::level::debug);
while (i < 1000000)
{
file_logger->debug("Async message #{}", i);
i++;
}
spdlog::drop_all();
return 0;
}
在初始化的时候使用异步工厂spdlog::async_factory进行初始化即可。
目前这个库有一大缺陷就是不支持日志压缩,要知道项目中如果打开了Debug级别的日志,日志量可能是非常恐怖的,如果分割文件的时候不能压缩文件将是对硬盘空间的极大浪费(日志压缩率一般在95%左右)。
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
多年来,我在各种网站上遇到过各种问题,用户在字符串和文本字段的开头/结尾放置空格。有时这些会导致格式/布局问题,有时会导致搜索问题(即搜索顺序看起来不对,但实际上并非如此),有时它们实际上会使应用程序崩溃。我认为这会很有用,而不是像我过去所做的那样放入一堆before_save回调,向ActiveRecord添加一些功能以在保存之前自动调用任何字符串/文本字段上的.strip,除非我告诉它不是,例如do_not_strip:field_x,:field_y或类定义顶部的类似内容。在我去弄清楚如何做到这一点之前,有没有人看到更好的解决方案?明确一点,我已经知道我可以做到这一点:befor
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式