ffmpeg录制下来的音频为pcm格式(内部存储着十六进制数据),但pcm格式的音频无法直接播放
本文先将pcm转换成wav格式(提要提前了解音频知识)
首先分析wav文件格式(wav的本质是在pcm数据前加上文件头),即在pcm的十六进制数据前加上文件头(文件头也是十六进制数据,但有些内容是固定的,有些内容是变化的)
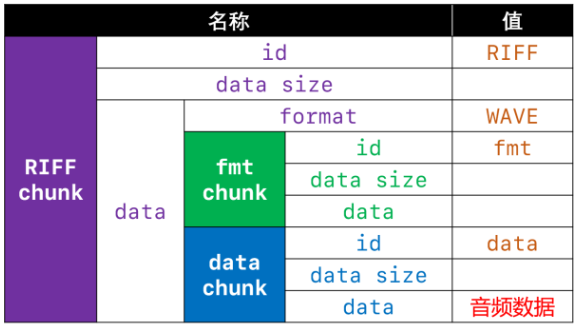
pcm转换成wav基本思路:
首先封装一个方法,该方法需要实现在传入wav文件头后把源pcm文件转为wav文件。具体功能是先将文件头的十六进制数据写入文件(需要记录下变化的地方,等待读取pcm的数据之后才能确定),然后将pcm中的十六进制数据写入wav文件。这些思路都是有wav文件格式确定的
难点:
文件头到底怎么写?(以下是wav文件头的格式,第二张图为文件头十六进制存储的样子,一个十六进制为一个字节,一个ASCII编码占一个字节,文件头总长为44字节)
注意:这里细节的地方太多了,无法每一处都提及

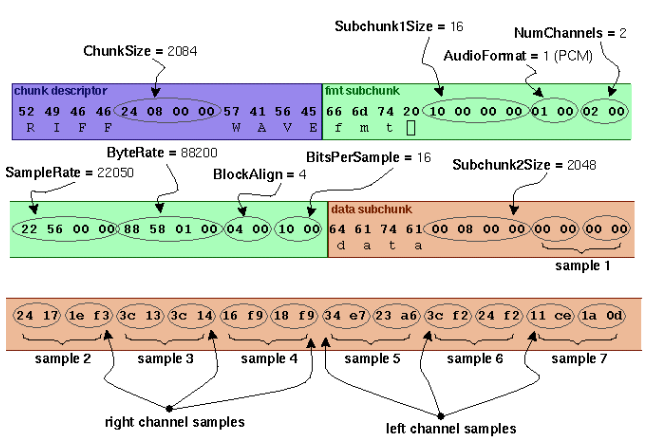
通过结构的方式来理清文件头
typedef struct {
// RIFF chunk的id
uint8_t riffChunkId[4] = {'R', 'I', 'F', 'F'};
// RIFF chunk的data大小,即文件总长度减去8字节
uint32_t riffChunkDataSize;
// "WAVE"
uint8_t format[4] = {'W', 'A', 'V', 'E'};
/* fmt chunk */
// fmt chunk的id
uint8_t fmtChunkId[4] = {'f', 'm', 't', ' '};
// fmt chunk的data大小:存储PCM数据时,是16
uint32_t fmtChunkDataSize = 16;
// 音频编码,1表示PCM,3表示Floating Point
uint16_t audioFormat = AUDIO_FORMAT_PCM;
// 声道数
uint16_t numChannels;
// 采样率
uint32_t sampleRate;
// 字节率 = sampleRate * blockAlign
uint32_t byteRate;
// 一个样本的字节数 = bitsPerSample * numChannels >> 3
uint16_t blockAlign;
// 位深度
uint16_t bitsPerSample;
/* data chunk */
// data chunk的id
uint8_t dataChunkId[4] = {'d', 'a', 't', 'a'};
// data chunk的data大小:音频数据的总长度,即文件总长度减去文件头的长度(一般是44)
uint32_t dataChunkDataSize;
} WAVHeader;
直接把结构体写入文件的方式很巧妙,既确定了写入顺序,又记录下了哪些是会变化的地方
注意:结构体中的某些值是根据音频相关数据决定的,而非一成不变。那相关的值到底如何填,可以直接去搜wav的头文件或者自行下载一个wav文件,将其拖入qt中查看其中的头文件中的数据
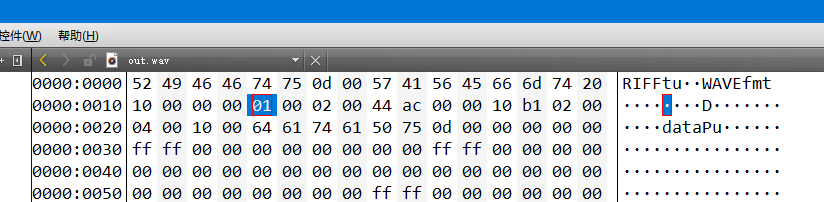
比如audioFormat可能填1可能填3,需要找到相应的含义,按情况而定

具体代码:
FFmpegs.h
#ifndef FFMPEGS_H
#define FFMPEGS_H
#include <stdint.h>
#define AUDIO_FORMAT_PCM 1
#define AUDIO_FORMAT_FLOAT 3
// WAV文件头(44字节)
typedef struct {
// RIFF chunk的id
uint8_t riffChunkId[4] = {'R', 'I', 'F', 'F'};
// RIFF chunk的data大小,即文件总长度减去8字节
uint32_t riffChunkDataSize;
// "WAVE"
uint8_t format[4] = {'W', 'A', 'V', 'E'};
/* fmt chunk */
// fmt chunk的id
uint8_t fmtChunkId[4] = {'f', 'm', 't', ' '};
// fmt chunk的data大小:存储PCM数据时,是16
uint32_t fmtChunkDataSize = 16;
// 音频编码,1表示PCM,3表示Floating Point
uint16_t audioFormat = AUDIO_FORMAT_PCM;
// 声道数
uint16_t numChannels;
// 采样率
uint32_t sampleRate;
// 字节率 = sampleRate * blockAlign
uint32_t byteRate;
// 一个样本的字节数 = bitsPerSample * numChannels >> 3
uint16_t blockAlign;
// 位深度
uint16_t bitsPerSample;
/* data chunk */
// data chunk的id
uint8_t dataChunkId[4] = {'d', 'a', 't', 'a'};
// data chunk的data大小:音频数据的总长度,即文件总长度减去文件头的长度(一般是44)
uint32_t dataChunkDataSize;
} WAVHeader;
class FFmpegs
{
public:
FFmpegs();
static void pcm2wav(WAVHeader &header,const char *pcmFilename,const char *wavFilename);
};
#endif // FFMPEGS_H
FFmpegs.cpp
#include "ffmpegs.h"
#include <QFile>
#include <QDebug>
FFmpegs::FFmpegs()
{
}
void FFmpegs::pcm2wav(WAVHeader &header, const char *pcmFilename, const char *wavFilename)
{
header.blockAlign = header.bitsPerSample * header.numChannels >> 3;
header.byteRate = header.sampleRate * header.blockAlign;
// 打开pcm文件
QFile pcmFile(pcmFilename);
if (!pcmFile.open(QFile::ReadOnly)) {
qDebug() << "文件打开失败" << pcmFilename;
return;
}
header.dataChunkDataSize = pcmFile.size();
header.riffChunkDataSize = header.dataChunkDataSize
+ sizeof (WAVHeader) - 8;
// 打开wav文件
QFile wavFile(wavFilename);
if (!wavFile.open(QFile::WriteOnly)) {
qDebug() << "文件打开失败" << wavFilename;
pcmFile.close();
return;
}
// 写入头部
wavFile.write((const char *) &header, sizeof (WAVHeader));
// 写入pcm数据
char buf[1024];
int size;
while ((size = pcmFile.read(buf, sizeof (buf))) > 0) {
wavFile.write(buf, size);
}
// 关闭文件
pcmFile.close();
wavFile.close();
}
封装的代码中也可以看出,基本上头文件中的数据都已经初始化了,还剩下声道数numChannels、采样率sampleRate、位深度bitsPerSample来自行赋值
调用封装的函数:
void MainWindow::on_pushButton_pcm_to_wav_clicked()
{
// 封装WAV的头部,此处我所有的值是大多数情况下音频都是这些数据
WAVHeader header;
header.numChannels = 2;
header.sampleRate = 44100;
header.bitsPerSample = 16;
// 调用函数
FFmpegs::pcm2wav(header, "E:/media/out.pcm", "E:/media/out.wav");
QFile file("E:/media/out.wav");
if(file.exists()){
qDebug()<<"文件转换成功,wav文件已生成";
}
}
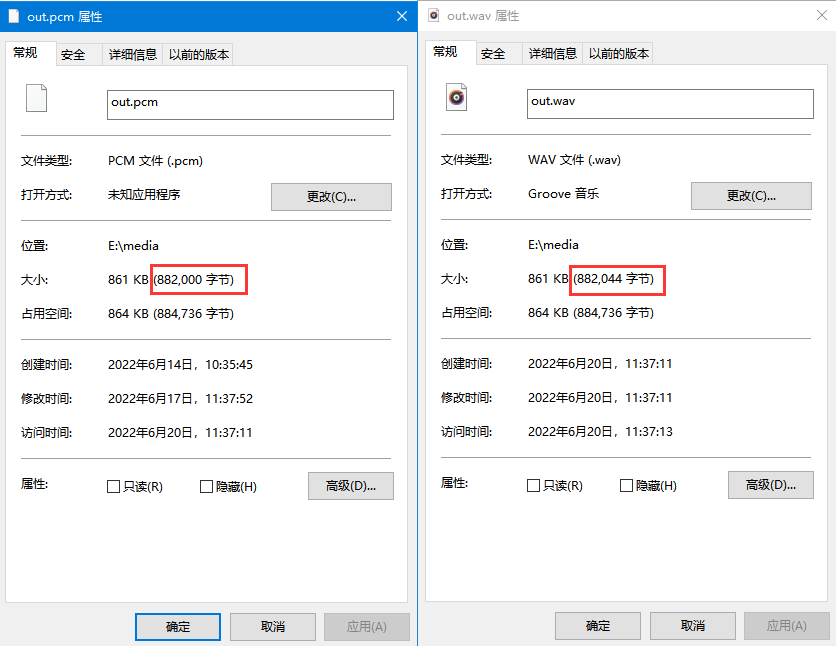
pcm和wav文件大小对比,wav多了44字节的文件头
注意:本文为个人记录,新手照搬可能会出现各种问题,请谨慎使用
码字不易,如果这篇博客对你有帮助,麻烦点赞收藏,非常感谢!有不对的地方
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
解决台式机麦克风不可用问题戴尔灵越3880最近因为需要开线上会议,发现戴尔台式机音频只有输出没有输入,也就是只能听见声音,无法输入声音。先后尝试了各种驱动安装更新之类的调试,无果。之后通过戴尔支持解决~这里多说一句,专业的就是专业,问题描述过去,直接给了解决方案,可能是他们遇到的相似问题比较多了,但也告诉我们,有些时候是可以通过这些官方服务解决问题的,比起自己折腾效率要高很多。那就记录一下吧~问题描述:电脑只能输出声音,不能输入声音。1、前提需要准备一只带麦克风的耳机,将耳机插入面板。2、先确定是否可以听到声音,可以通过播放歌曲或者视频。3、然后确认麦克风是否可用,可以通过调用win自带麦克风
以VSTiTriforce为例,由Tweakbench提供。当加载到市场上的任何VST主机时,它允许主机向VSTi发送(大概是MIDI)信号。然后VSTi将处理该信号并输出由VSTi内的软件乐器创建的合成音频。例如,将A4(我相信是MIDI音符)发送到VSTi会导致它合成高于中央C的A。它将音频数据发送回VST主机,然后它可以在我的扬声器上播放或将其保存为.wav或其他一些音频文件格式。假设我有Triforce,我正在尝试用我选择的语言编写一个程序,它可以通过发送要合成的A4纸条与VSTi交互,并自动将其保存到系统上的文件?最终,我希望能够解析整个单轨MIDI文件(使用已经可用于此
我最近一直在研究ruby,我决定开始一个简单的项目来编写一个ruby脚本,将线路输入声音记录到.wav文件中。我发现ruby不能很好地访问硬件设备(它可能不应该),但是PortAudio可以,而且我发现了一个很棒的PA包装器here(它不是gem,我认为是因为它使用ruby的ffi附加到PortAudio,而且PA库可能在很多地方)。我一直在摸索PortAudio的文档和示例以了解PA的工作原理。我已经很多年没有写过或读过C了。我在创建过程中应该将哪些参数传递给流以及在创建过程中传递给缓冲区时遇到了困难。例如,frame到底是什么,它与channel和samplerat
特性工作电压范围:6V-14V输出功率:7W(CLASSD,7.4V/4Ω,THD=10%)10W(CLASSD,9V/4Ω,THD=10%)18W(CLASSD,12V/4Ω,THD=10%)最高可达92%效率(12V/8Ω)电平设置工作模式无需输出滤波器差分输入优异的“上电,掉电”噪声抑制过流保护、过热保护、欠压保护 eSOP-8封装典型应用电路很简单:如下是本人的设计。 输入电阻:输入电阻主要是确定增益,即输出功率,所以一定要确定输入信号的幅度,喇叭的幅度,前后使用有效值计算。此设计搭配的喇叭是8R3W,额定功率3W,额定电压4.89V(有效值),最大功率4W。我们先确定输入信号的赋值,
做音频处理(虽然它也可以是图像处理)我有一个一维数字数组。(它们恰好是代表音频样本的16位有符号整数,这个问题同样适用于float或不同大小的整数。)为了匹配不同频率的音频(例如,将44.1kHz样本与22kHz样本混合),我需要拉伸(stretch)或压缩值数组以满足特定长度。将数组减半很简单:每隔一个样本丢弃一次。[231,8143,16341,2000,-9352,...]=>[231,16341,-9352,...]将数组宽度加倍稍微不那么简单:将每个条目加倍(或可选地在相邻的“真实”样本之间执行一些插值)。[231,8143,16341,2000,-9352,...]=>[2
我正在尝试实现一个具有两个输入channel和一个输出channel的ScriptProcessorNode。varsource=newArray(2);source[0]=context.createBufferSource();source[0].buffer=buffer[0];source[1]=context.createBufferSource();source[1].buffer=buffer[1];vartest=context.createScriptProcessor(4096,2,1);source[0].connect(test,0,0);source[1].c
出于某些原因,我有一个网页可以解码wave文件。Chrome和Safari似乎工作正常。Firefox有时无法解码文件并给出错误:“传递给decodeAudioData的缓冲区包含无法成功解码的无效内容。”我创建了一个jsfiddle这说明了这个问题:varaudioCtx=new(window.AudioContext||window.webkitAudioContext)();varsource;functiongetData(){source=audioCtx.createBufferSource();request=newXMLHttpRequest();request.ope
我正在尝试在加载Javascriptaudio()对象时调用一个函数,但使用onload时它不起作用。myaud.onload=audioDone;但它正在使用image()对象。我怎样才能让它与audio()对象一起工作?谢谢 最佳答案 安元素有一组特定的事件称为mediaevents,和onload不是其中之一您可以使用canplaythrough检查音频是否已加载并可以播放。事件myaud.addEventListener('canplaythrough',audioDone,false);
我有一个音频元素varaudioSrc='https://mfbx9da4.github.io/assets/audio/dope-drum-loop_C_major.wav'varaudio=document.createElement('audio')audio.src=audioSrc我需要AudioBuffer做beatdetection所以我尝试在加载音频时访问缓冲区:audio.oncanplaythrough=()=>{console.info('loaded');varsource=context.createMediaElementSource(audio);sour