leader安排了爬虫的任务;
代码采用了selenium调用谷歌浏览器模拟登录,登录后有模拟鼠标点击菜单,最后模拟点击进行翻页;
代码写好了就一直跑啊跑啊。一共4W多页数据,每次差不多爬取了1千多页就会出现chrome崩溃的情况;
如图:
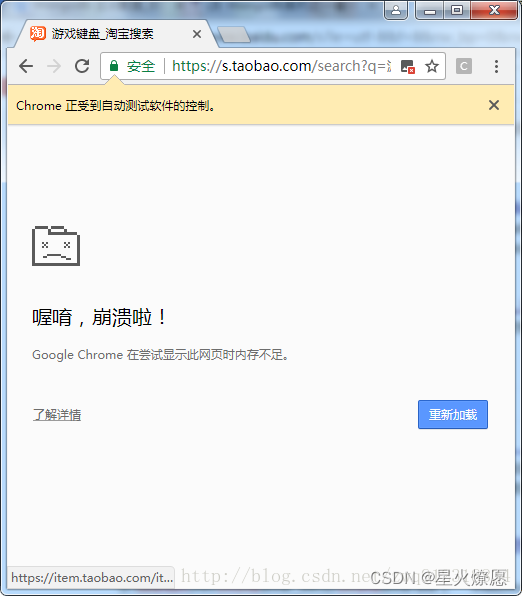
(网上找的图,当时的具体报错找不到了,其实可以重现;)
后来排查到,在运行一段时间后,内存明显被吃满了。到这里可以判断肯定是浏览器把我内存吃了,最后导致自己崩溃了,哈哈;
我把爬取翻页的代码放在了try内,试图在浏览器崩溃时被try检测到,从而重新发送请求(相当于刷新),开始爬取数据;
但是… 我想错了;
当浏览器崩溃时,相当于卡主了,代码也就卡主了;
嗯,对,浏览器崩溃不算异常;- . - |
浏览器崩溃时,手动刷新了下,就恢复了,同时也保持了登录后的cookie,并没有退出登录,所以尝试让代码来刷新浏览器;
但是,问题来了,代码检测不到浏览器什么时候崩溃,所以什么时候刷新就成了问题;每隔一段时间刷新一次,这种手法…额…确实会影响效率;
在浏览器崩溃时,手动清空了缓存,也可以解决浏览器内存泄漏的问题;
但是,这次遇到了两个问题;
一是,何事进行清空缓存的动作;
二是,清空缓存的代码无法取消cookie的勾;(如果清空了cookie,还得重新进行模拟登陆,所以不能清空cookie)
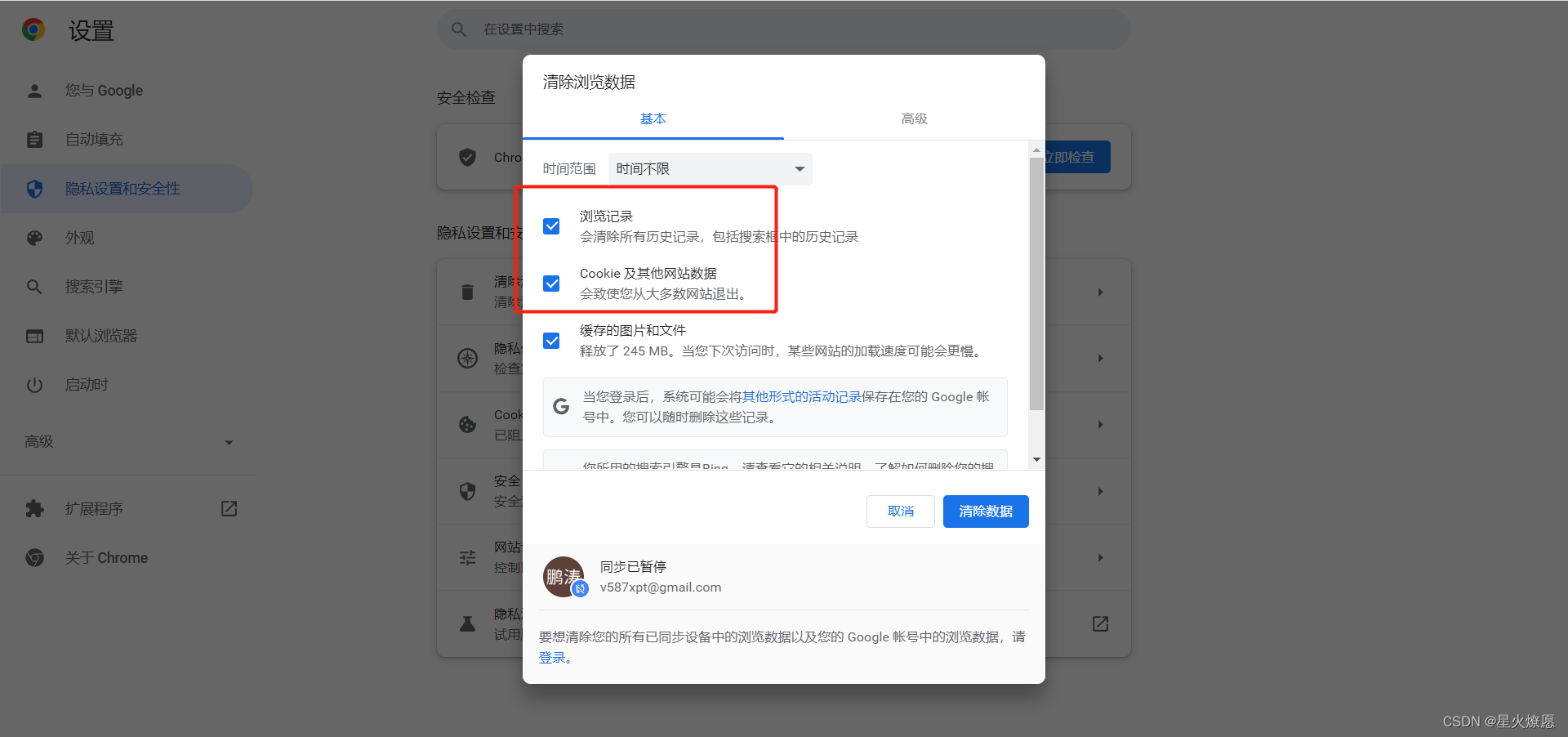
在查阅了网上的一些资料和同病相怜的博客之后,发现这是seleinum调用chrome的一个bug——内存泄漏;
既然是bug,那…就不用chrome了,换了firefox浏览器之后,一切都解决了。
firefox内核下载:https://github.com/mozilla/geckodriver/releases
调用firefox示例代码:
# browser = webdriver.Chrome(options=option) # 调用谷歌浏览器
browser = webdriver.Firefox() # 调用火狐浏览器
感谢其他同学提供的参考:
https://blog.csdn.net/zwq912318834/article/details/79000040
https://qa.1r1g.com/sf/ask/4348349491/
https://blog.csdn.net/wt321088/article/details/84986313
https://www.csdn.net/tags/NtjaMg5sNjAzNDMtYmxvZwO0O0OO0O0O.html
https://segmentfault.com/a/1190000040517845
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
当我在Rails控制台中按向上或向左箭头时,出现此错误:irb(main):001:0>/Users/me/.rvm/gems/ruby-2.0.0-p247/gems/rb-readline-0.4.2/lib/rbreadline.rb:4269:in`blockin_rl_dispatch_subseq':invalidbytesequenceinUTF-8(ArgumentError)我使用rvm来管理我的ruby安装。我正在使用=>ruby-2.0.0-p247[x86_64]我使用bundle来管理我的gem,并且我有rb-readline(0.4.2)(人们推荐的最少
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
GivenIamadumbprogrammerandIamusingrspecandIamusingsporkandIwanttodebug...mmm...let'ssaaay,aspecforPhone.那么,我应该把“require'ruby-debug'”行放在哪里,以便在phone_spec.rb的特定点停止处理?(我所要求的只是一个大而粗的箭头,即使是一个有挑战性的程序员也能看到:-3)我已经尝试了很多位置,除非我没有正确测试它们,否则会发生一些奇怪的事情:在spec_helper.rb中的以下位置:require'rubygems'require'spork'
如何在ruby中调用C#dll? 最佳答案 我能想到几种可能性:为您的DLL编写(或找人编写)一个COM包装器,如果它还没有,则使用Ruby的WIN32OLE库来调用它;看看RubyCLR,其中一位作者是JohnLam,他继续在Microsoft从事IronRuby方面的工作。(估计不会再维护了,可能不支持.Net2.0以上的版本);正如其他地方已经提到的,看看使用IronRuby,如果这是您的技术选择。有一个主题是here.请注意,最后一篇文章实际上来自JohnLam(看起来像是2009年3月),他似乎很自在地断言RubyCL