本文目录
阅读本文前请注意,本文仅仅展示springboot整合es中大部分场景api的操作,对其概念并没有过多的阐述,想获得更完整的文档,请查阅官方文档
https://www.elastic.co/cn/elasticsearch/
在介绍使用之前,先对比一下es与mysql关键字术语描述的比较吧

es镜像: elasticsearch:7.14.0
kibana镜像: kibana:7.14.0
ik分词器:ik-7.14.0
该es版本与springboot 2.3.10.RELEASE对应
注意:es与spring需要有严格的版本对应包括与分词器的对应
<!--elasticsearch-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version> 2.3.10.RELEASE</version>
</dependency>
elasticsearch:
host: 192.168.137.157:9200
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {
@Value("${elasticsearch.host}")
private String host;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration
.builder().connectedTo(host).build();
return RestClients.create(clientConfiguration).rest();
}
}
public class HotelConstants {
public static final String MAPPING_TEMPLATE =" {\n" +
" \"properties\": {\n" +
" \"id\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"starName\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"location\":{\n" +
" \"type\":\"geo_point\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\" \n" +
" }\n" +
" }\n" +
" }";
/**
* 创建索引
* @throws IOException
*/
@Test
void createIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("hotel"); // 索引库名
request.mapping(MAPPING_TEMPLATE, XContentType.JSON); // 常量静态导入
// 发起请求
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 索引是否存在
*/
@Test
void existsIndex() throws IOException {
GetIndexRequest indexRequest = new GetIndexRequest("hotel");
boolean exists = restHighLevelClient.indices().exists(indexRequest, RequestOptions.DEFAULT);
System.out.println(exists?"已存在":"不存在");
}
/**
* 删除索引
*/
@Test
void deleteIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("hotel");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(delete.toString());
}
可以发现创建删除都是采用rest风格的去定义的java API,创建请求是都需要传入索引名,注意索引库是不支持修改操作的,如果有需要修改,直接删除重新创建即可
/**
* 新增单条数据
* @throws IOException
*/
@Test
void testAddOneDocument() throws IOException {
Hotel hotel = iHotelService.getById(45845L); // 数据库中查询的数据
HotelDoc hotelDoc = new HotelDoc(hotel); // 数据实体转换
// 1、准备Request对象
// 索引库中对id的要求必须是字符串
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2、准备Json文档
// 将实体类转换为JSON格式的数据
request.source(JSONUtil.toJsonStr(hotelDoc), XContentType.JSON);
// 3、发送请求
client.index(request, RequestOptions.DEFAULT);
}
java api 对应DSL图
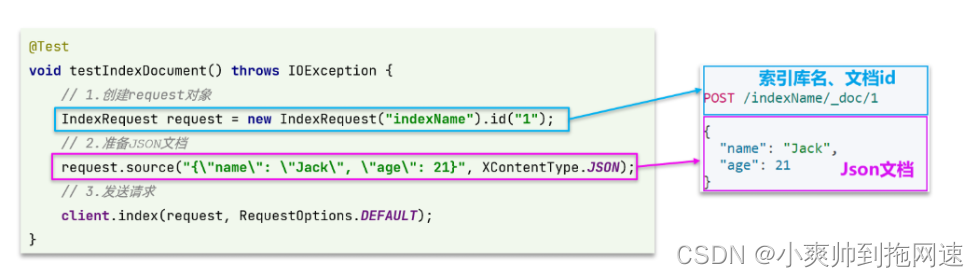
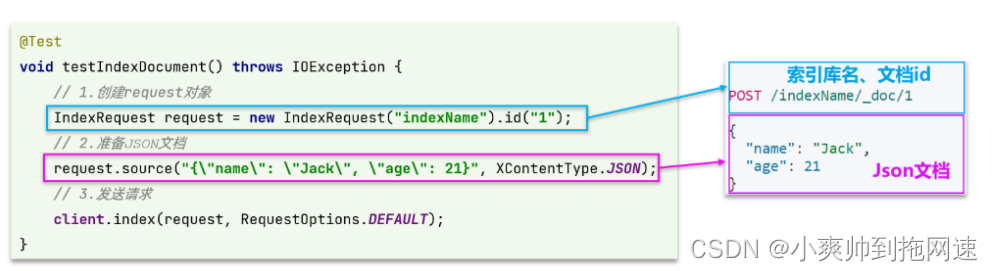
/**
* 查询单条数据
*/
@Test
void testQueryOneDocuemnt() throws IOException {
GetRequest getRequest = new GetRequest("hotel", "45845");
GetResponse documentFields = client.get(getRequest, RequestOptions.DEFAULT);
String jsonString = documentFields.getSourceAsString();
// 将json格式数据转换为实体
System.out.println(JSONUtil.toBean(jsonString, HotelDoc.class));
}
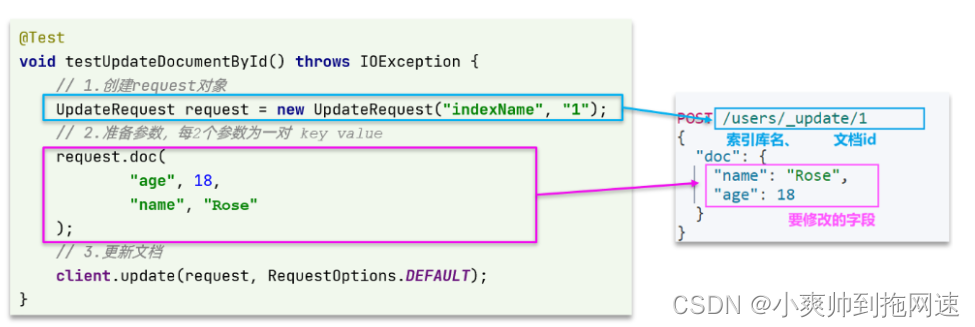
/**
* 修改文档的方式有两种
* 方式一:全量更新,写入一样的id,就会删除旧文档,添加新文档
* 方式二:局部更新,只更新部分字段
*/
@Test
void testUpdateDocumentById() throws IOException {
/* Hotel hotel = iHotelService.getById(45845L);
hotel.setScore(46);
HotelDoc hotelDoc = new HotelDoc(hotel);
UpdateRequest updateRequest = new UpdateRequest("hotel", hotel.getId().toString());
updateRequest.doc(JSONUtil.toJsonStr(hotelDoc),XContentType.JSON);*/
UpdateRequest updateRequest = new UpdateRequest("hotel", "45845");
updateRequest.doc("score", "48"); // 直接按照kv的格式
UpdateResponse update = client.update(updateRequest, RequestOptions.DEFAULT);
}
/**
* 删除文档
*/
@Test
void testDeleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("hotel", "45845");
System.out.println(client.delete(deleteRequest, RequestOptions.DEFAULT).getVersion());
}
/**
* 批量导入文档
*/
@SneakyThrows
@Test
void testBatchAddDoucument(){
// 查询所有记录并转换成HotelDoc
List<HotelDoc> hotelDocs = iHotelService.list().stream().map(hotel -> new HotelDoc(hotel)).collect(Collectors.toList());
BulkRequest bulkRequest = new BulkRequest("hotel");
for (HotelDoc hotelDoc : hotelDocs) {
bulkRequest.add(new IndexRequest("hotel")
.id(hotelDoc.getId().toString())
.source(JSONUtil.toJsonStr(hotelDoc),XContentType.JSON));
}
client.bulk(bulkRequest,RequestOptions.DEFAULT);
}
除了批量新增,同时可以批量修改删除

DSL:


java rest:
@Test
@SneakyThrows
void testMatchAll(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.matchAllQuery());
SearchHit[] hits = client.search(searchRequest, RequestOptions.DEFAULT).getHits().getHits(); // 第二个hits才能获取到数据
List<HotelDoc> hotelDocs = Arrays.stream(hits).map(hit -> {
// 使用流提取其中的json转换成HotelDoc实体后添加进集合中
return JSONUtil.toBean(hit.getSourceAsString().toString(), HotelDoc.class);
}).collect(Collectors.toList());
hotelDocs.forEach(hotelDoc -> System.out.println(hotelDoc.getName()));
}

@Test
@SneakyThrows
void testMultipMatch(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.multiMatchQuery("如家","brand","name"));
handleResponse(searchRequest);
}

@SneakyThrows
@Test
void testTerm(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.termQuery("city","北京"));
handleResponse(searchRequest);
}

@SneakyThrows
@Test
void testTerm(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source()
.query(QueryBuilders.rangeQuery("price").lte(400));
handleResponse(searchRequest);
}

@Test
@SneakyThrows
void testBooleanQuery(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("brand","如家"))
.mustNot(QueryBuilders.rangeQuery("price").gte(500))
.filter(QueryBuilders.geoDistanceQuery("location").point(31,121 ).distance(50, DistanceUnit.KILOMETERS))
);
handleResponse(searchRequest);
}


@Test
@SneakyThrows
void testGeoDistance(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.geoDistanceQuery("location")
.distance(15,DistanceUnit.KILOMETERS).point(31.21,121.5));
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
List<HotelDoc> hotelDocs = Arrays.stream(searchResponse.getHits().getHits()).map(hit -> {
return JSONUtil.toBean(hit.getSourceAsString().toString(), HotelDoc.class);
}).collect(Collectors.toList());
hotelDocs.forEach(hotelDoc -> {
System.out.println(hotelDoc.getName());
});
}
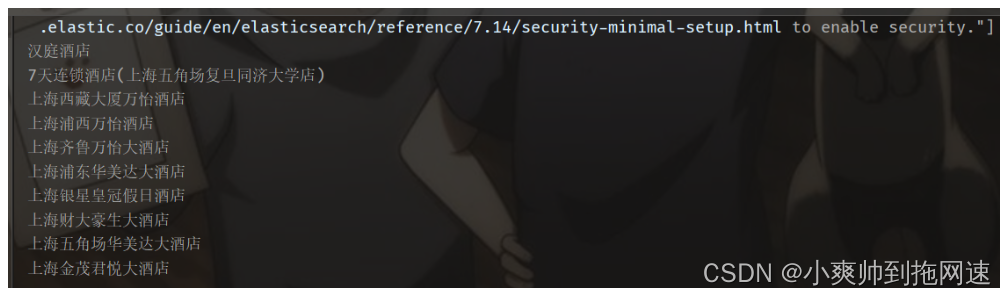

@Test
@SneakyThrows
void testFunctionScore(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().query(QueryBuilders.functionScoreQuery(
QueryBuilders.matchQuery("all","上海"),
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
QueryBuilders.rangeQuery("price").gte(700),
ScoreFunctionBuilders.weightFactorFunction(10)
)
}
));
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
List<HotelDoc> hotelDocs = Arrays.stream(searchResponse.getHits().getHits()).map(hit -> {
return JSONUtil.toBean(hit.getSourceAsString().toString(), HotelDoc.class);
}).collect(Collectors.toList());
hotelDocs.forEach(hotelDoc -> {
System.out.print("name:"+hotelDoc.getName());
System.out.println(" age:"+hotelDoc.getPrice());
});
}
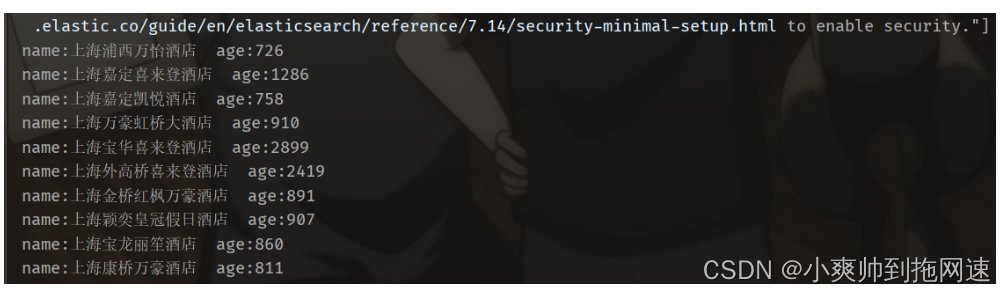

@Test
@SneakyThrows
void testSortPageQuery(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source()
.query(QueryBuilders.termQuery("brand","如家"))
.from(10).size(1)
.sort("price", SortOrder.DESC).sort("score",SortOrder.ASC);
handleResponse(searchRequest);
}
注意:如果查询的字段不是高亮的字段,必须显示修改require_field_match的值为false
高亮的结果与查询的文档结果默认是分离的,并不在一起。因此解析高亮的代码需要额外的做处理

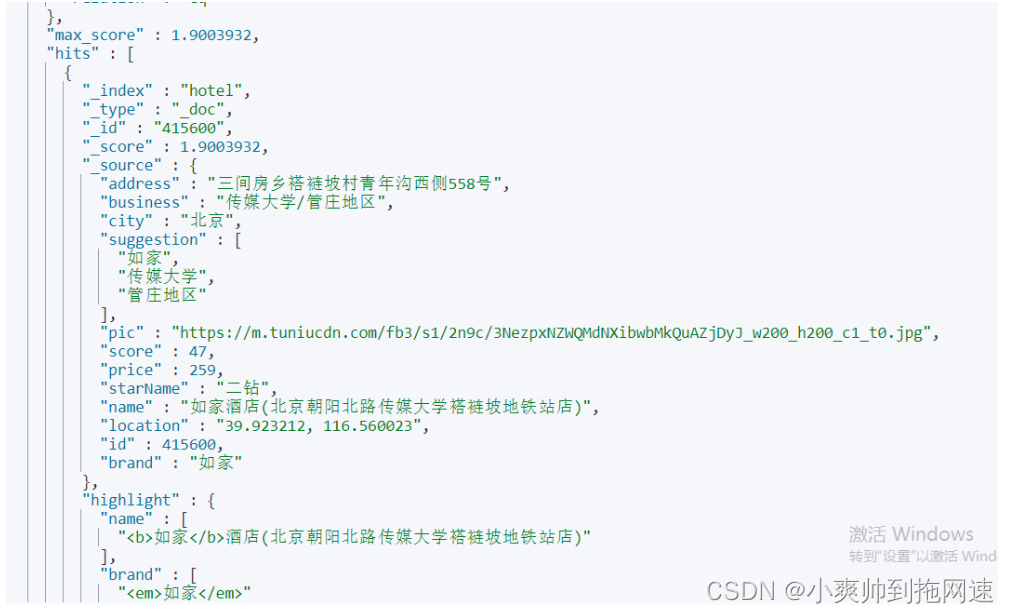
@Test
@SneakyThrows
void testHighlighter(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source()
.query(QueryBuilders.termQuery("name","如家"))
.highlighter(new HighlightBuilder().field("name").requireFieldMatch(false)
.preTags("<b>").postTags("<b>")
// 以最后一个标签为主
.field("brand").preTags("<em>").postTags("</em>"));
handleResponse(searchRequest);
}
private void handleResponse(SearchRequest searchRequest) throws IOException {
SearchHits searchHits = client.search(searchRequest, RequestOptions.DEFAULT).getHits();
System.out.printf("总共获取的条数为:%s", searchHits.getTotalHits().value+"\n");
SearchHit[] hits = searchHits.getHits();
List<HotelDoc> hotelDocs = Arrays.stream(hits).map(hit -> {
String highlightName = null;
String highlightBrand = null;
if (!CollectionUtils.isEmpty(hit.getHighlightFields())){
// 获取高亮字段
highlightName = hit.getHighlightFields().get("name").getFragments()[0].string();
highlightBrand = hit.getHighlightFields().get("brand").getFragments()[0].string();
}
HotelDoc hotelDoc = JSONUtil.toBean(hit.getSourceAsString().toString(), HotelDoc.class);
if (highlightName!=null){
// 将查询出来的高亮字段覆盖到原查询的实体中的字段
hotelDoc.setName(highlightName);
}
if (highlightBrand!=null){
hotelDoc.setBrand(highlightBrand);
}
return hotelDoc;})
.collect(Collectors.toList());
// hotelDocs.forEach(hotelDoc -> System.out.println("酒店名:"+hotelDoc.getName()+" 酒店品牌:"+hotelDoc.getBrand()));
hotelDocs.forEach(System.out::println);
}

聚合常见的有三类:
这里只展示前面两种
品牌聚合,并且排序,限定聚合范围


@Test
@SneakyThrows
void testAggregationsBrand(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source()
.query(QueryBuilders.rangeQuery("price").gte(100).lte(500))
.aggregation(AggregationBuilders.terms("brand_agg") // 聚合字段名
.field("brand").order(BucketOrder.key(false)).size(10)
);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 注意转换的类型为Terms
Terms brand_agg = (Terms) searchResponse.getAggregations().get("brand_agg");
for (Terms.Bucket bucket : brand_agg.getBuckets()) {
System.out.println(bucket.getKeyAsString());
}
}
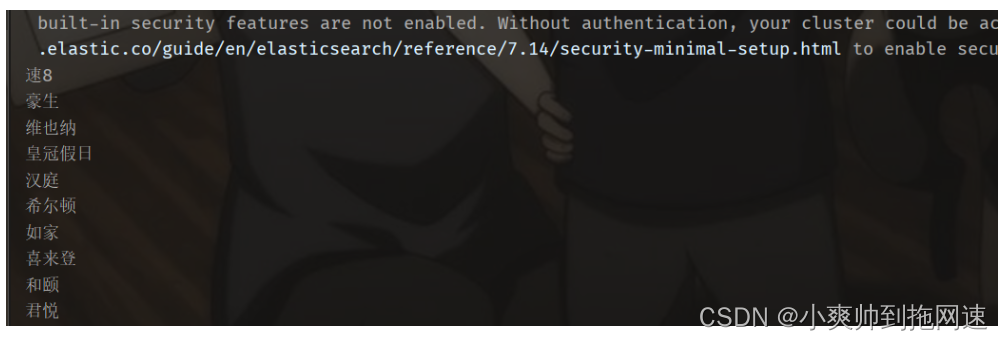
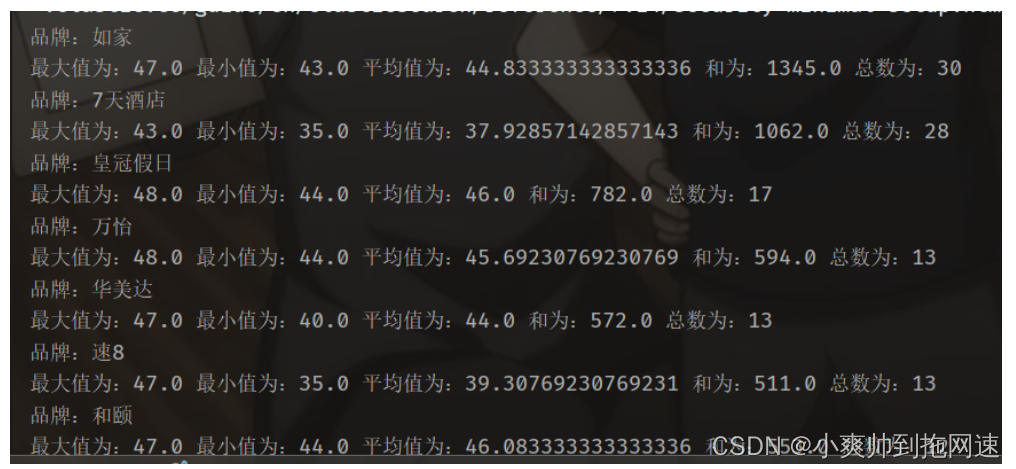
前面的Bucket聚合对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果


@Test
@SneakyThrows
void testAggregationBrand_score(){
SearchRequest searchRequest = new SearchRequest("hotel");
searchRequest.source().aggregation(AggregationBuilders.terms("brand_agg")
.field("brand").size(20)
// 在对品牌做聚合的前提下做分数的聚合
.subAggregation(AggregationBuilders.stats("score_stats").field("score")));
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
Terms terms = (Terms) searchResponse.getAggregations().get("brand_agg");
terms.getBuckets().forEach(bucket ->{
System.out.println("品牌:"+bucket.getKeyAsString());
ParsedStats stats = (ParsedStats) bucket.getAggregations().get("score_stats");
System.out.printf("最大值为:%s ", stats.getMaxAsString());
System.out.printf("最小值为:%s ", stats.getMinAsString());
System.out.printf("平均值为:%s ", stats.getAvgAsString());
System.out.printf("和为:%s ", stats.getSumAsString());
System.out.printf("总数为:%s\n", stats.getCount());
} );
}
好啦,本文关于springboot整合es的主要api的操作就介绍到这里啦,如果你对本文的内容有疑问或者其他方面的见解,欢迎到评论区留言
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t