
一、实验目的
熟悉hdfs命令行基本操作
二、实验环境
Windows 10
VMware Workstation Pro虚拟机
Hadoop环境
Jdk1.8
三、实验内容
1:hdfs常见命令:
(1)查看帮助:hdfs dfs -help
(2)查看当前目录信息:hdfs dfs -ls /
(3)创建文件夹:hdfs dfs -mkdir /文件夹名
(4)上传文件:hdfs dfs -put /本地路径 /hdfs路径
(5)下载文件到本地:hdfs dfs -get /hdfs路径 /本地路径
(6)移动hdfs文件:hdfs dfs -mv /hdfs路径 /hdfs路径
(7)复制hdfs文件:hdfs dfs -cp /hdfs路径 /hdfs路径
(8)删除hdfs文件:hdfs dfs -rm /文件名
(9)删除hdfs文件夹:hdfs dfs -rm -r /文件夹名
(10)查看hdfs中的文件:hdfs dfs -cat /文件名
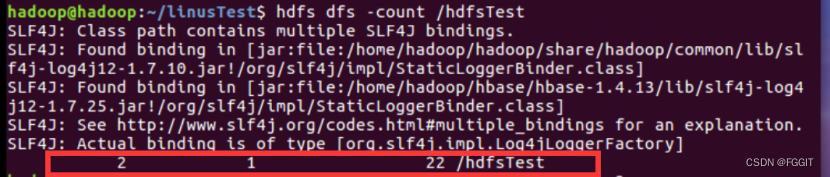
(11)查看文件夹中有多少个文件:hdfs dfs -count /文件夹名
(12)统计目录下的对象数:hdfs dfs -count /文件夹名
(13)统计目录下的对象大小:hdfs dfs -du [-s] [-h] /文件夹名
(14)显示hdfs的容量、数据块和数据节点的信息:hdfs dfsadmin -report
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当hdfs进入安全模式时不允许客户端进行任何修改文件的操作,包括上传文件,删除文件,重命名,创建文件夹等操作。
(15)查看安全模式状态:hdfs dfsadmin -safemode get
(16)强制进入安全模式:hdfs dfsadmin -safemode enter
(17)强制离开安全模式:hdfs dfsadmin -safemode leave
hdfs常见命令运行:
(1)查看帮助:hdfs dfs -help
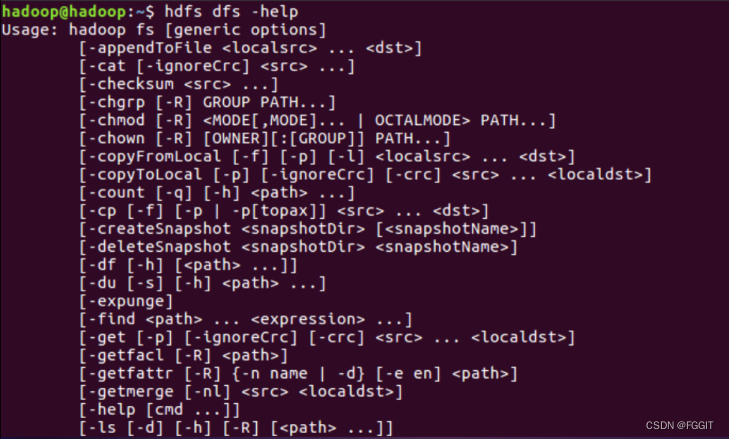
(2)查看当前目录信息:hdfs dfs -ls /
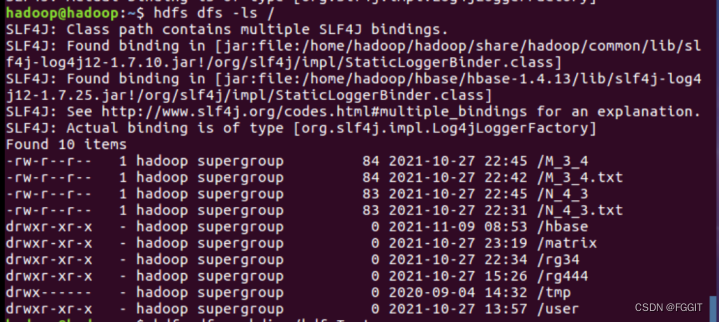
(3)创建文件夹hdfsTest:hdfs dfs -mkdir /hdfsTest
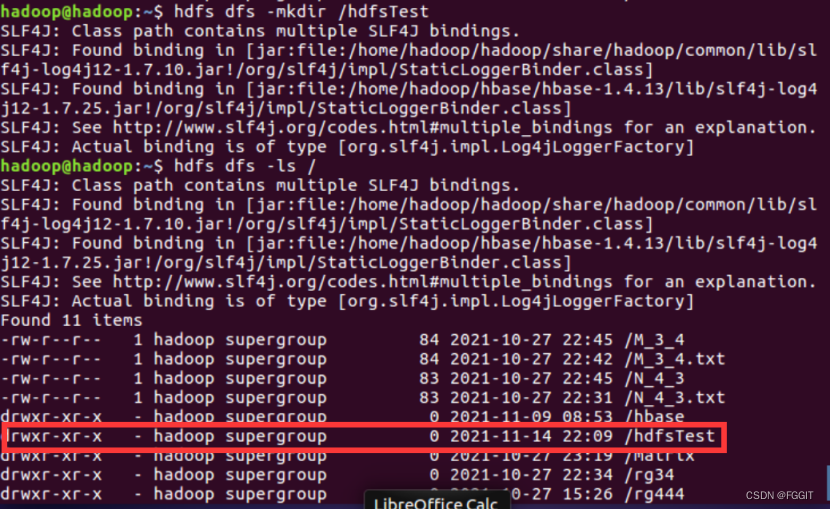
(4)把本地路径为/home/hadoop/rg34/input.txt的文件上传到hdfs文件系统路径为/hdfsTest/hdfsFile1的目录下:hdfs dfs -put /home/hadoop/rg3 4/input.txt /hdfsTest/hdfsFile1
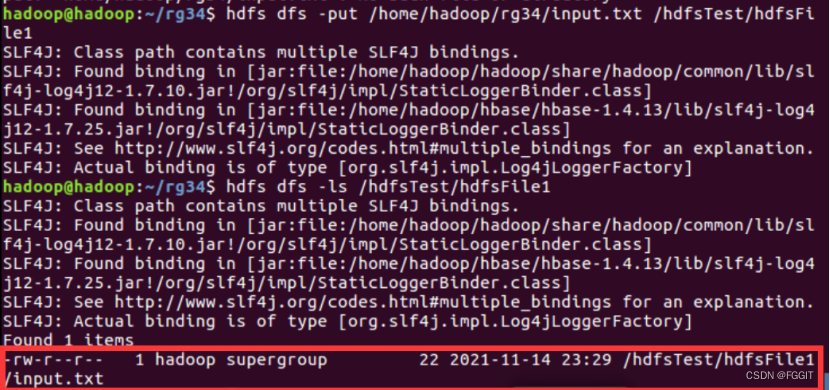
(5)下载路径为/hdfsTest/hdfsFile1/input.txt的hdfs文件到本地/home/hadoop/linusTest目录下:hdfs dfs -get /hdfsTest/hdfsFile1/ input.txt /home/hadoop/linusTest
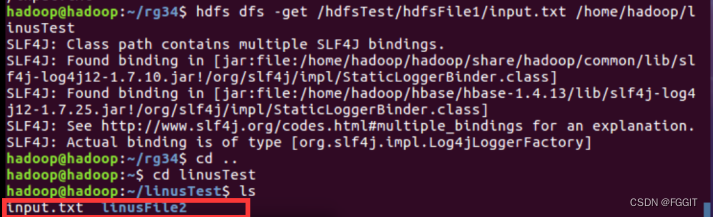
(6)把路径为/hdfsTest/hdfsFile1/input.txt的hdfs文件移动到/hdfsTest/hdfsFile2下:hdfs dfs -mv /hdfsTest/hdfsFile1/input.txt /hdfsTest/hdfsFile2
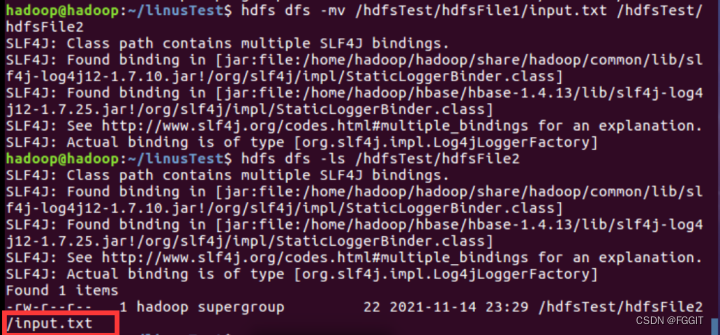
(7)复制一份路径为/hdfsTest/hdfsFile2/input.txt的hdfs文件到路径为/hdfsTest/hdfsFile1目录下:hdfs dfs -cp /hdfsTest/hdfsFile2/input. Txt /hdfsTest/hdfsFile1
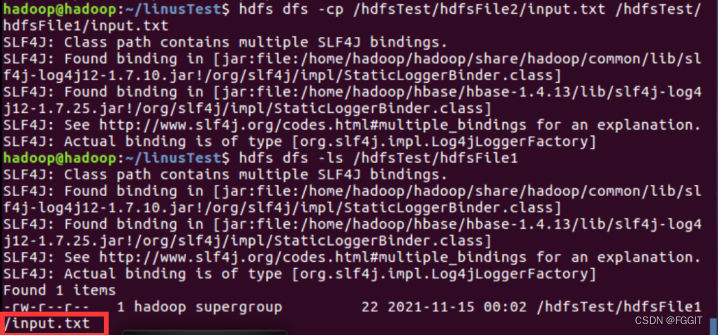
(8)删除路径为/hdfsTest/hdfsFile1/input.txt的hdfs文件:hdfs dfs -rm /hdfsTest/hdfsFile1/input.txt
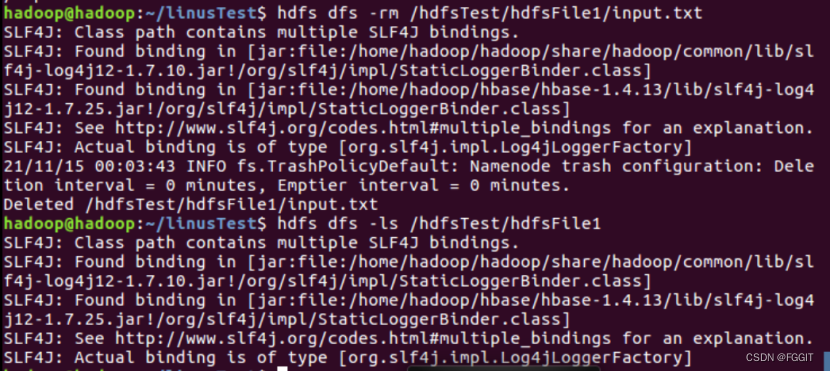
(9)删除路径为/hdfsTest/hdfsFile1的hdfs文件夹:hdfs dfs -rm -r /hdfsTest/hdfsFile1
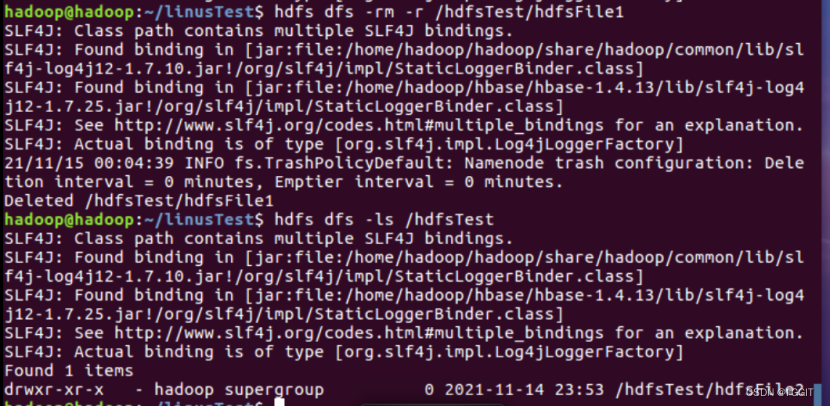
(10)查看路径为/hdfsTest/hdfsFile2/input.txt的hdfs文件:hdfs dfs -cat /hdfsTest/hdfsFile2/input.txt
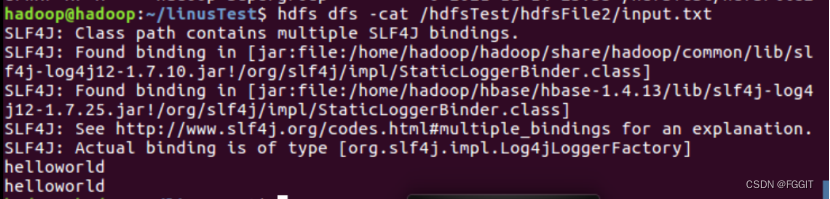
(11)查看hdfsTest文件夹中有多少个文件:hdfs dfs -count /hdfsTest
 (数字2表示有两个文件夹,数据1表示有1个文件)
(数字2表示有两个文件夹,数据1表示有1个文件)
(12)统计某目录下的对象数:hdfs dfs -count /
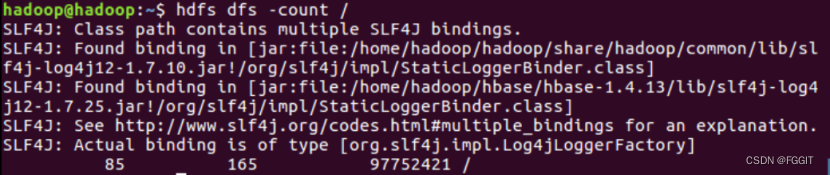
(13)统计某目录下的对象大小:hdfs dfs -du [-s] [-h] /

(14)显示hdfs的容量、数据块和数据节点的信息: hdfs dfsadmin -report
 安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当hdfs进入安全模式时不允许客户端进行任何修改文件的操作,包括上传文件,删除文件,重命名,创建文件夹等操作。
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当hdfs进入安全模式时不允许客户端进行任何修改文件的操作,包括上传文件,删除文件,重命名,创建文件夹等操作。
(15)查看安全模式状态:hdfs dfsadmin -safemode get

(16)强制进入安全模式:hdfs dfsadmin -safemode enter
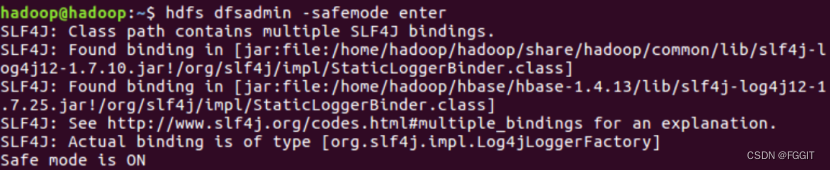
(17)强制离开安全模式:hdfs dfsadmin -safemode leave

我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.