
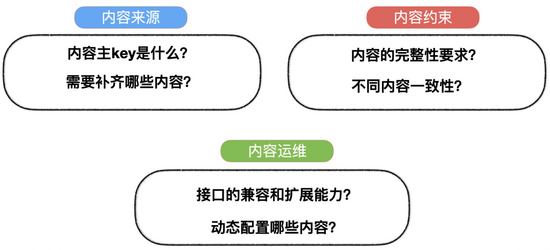
 比如对于我们淘系业务,搭建一套服务,我们需要先想清楚下面的几个点
比如对于我们淘系业务,搭建一套服务,我们需要先想清楚下面的几个点
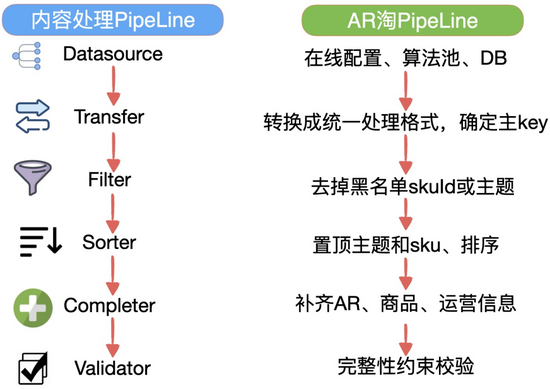
public class PipeLine<D, C> {
private List<PipeLineFunction<D, C>> functionList = new ArrayList<>();
public PipeLine<D, C> add(PipeLineFunction<D, C> pipeLineFunction) {
functionList.add(pipeLineFunction);
return this;
}
public D execute(D data, C context) throws Exception {
for (PipeLineFunction function : functionList) {
data = (D) function.execute(data, context);
}
return data;
}
}
public void initSkuResultHotRecommendPipeLine() {
PipeLine<SkuResultVO, SkuQuery> skuResultHotRecommendPipeLine = new PipeLine();
skuResultHotRecommendPipeLine
.add((data, context) -> skuResultDataSource.fromConfig(context))
.add((data, context) -> skuResultSorter.shuffle(data))
.add((data, context) -> skuResultSorter.topTheme(data, context))
.add((data, context) -> skuResultSorter.page(data, context))
.add((data, context) -> skuResultCompleter.addSkuInfo(data))
.add((data, context) -> skuResultCompleter.addAREffect(data, context))
.add((data, context) -> skuResultValidator.check(data));
}
public ResultVO<SkuResultVO> getSkuList(SkuQuery skuQuery) {
try {
SkuResultVO skuResultVO = skuResultHotRecommendPipeLine
.execute(new SkuResultVO(), skuQuery);
} catch (Exception e) {
log.error("", e.fillInStackTrace());
return ResultVO.failOf(e.getMessage());
}
return ResultVO.failOf(CameraArCause.No_Valid_Ar_Type
.toMessage(skuQuery.toString()));
}
@FunctionalInterface
public interface FilterFunction<T> {
boolean execute(T t) throws Exception;
}
@FunctionalInterface
public interface IterateFunction<T> {
T execute(T t, FilterFunction filterFunction);
}
private IterateFunction<SkuResultVO> skuVOFilterIterator = (skuResultVO, filter) -> {
List<SkuFeedUnitVO> skuFeedUnitVOList = skuResultVO.getSkuFeedUnitVOList()
.stream().filter(skuFeedUnitVO -> {
List<SkuVO> filterSkuVOList = skuFeedUnitVO.getSkuVOList()
.stream().filter(skuVO -> {
try {
return filter.execute(skuVO);
} catch (Exception e) {
log.warn("", e);
return false;
}
}).collect(toList());
if (filterSkuVOList.size() == 0) {
return false;
}
skuFeedUnitVO.setSkuVOList(filterSkuVOList);
return true;
}).collect(toList());
if (skuFeedUnitVOList.size() == 0) {
log.warn(CameraArCause.No_Valid_Sku_Feed_Unit_List
.toMessage(skuResultVO.toString()));
}
skuResultVO.setSkuFeedUnitVOList(skuFeedUnitVOList);
return skuResultVO;
};
public SkuResultVO byArType(SkuResultVO skuResultVO) {
return skuResultIterator.getSkuVOFilterIterator()
.execute(skuResultVO, (FilterFunction<SkuVO>) skuVO ->
!CameraArSwitch.Black_List_Config.getArType()
.contains(skuVO.getArType()));
}
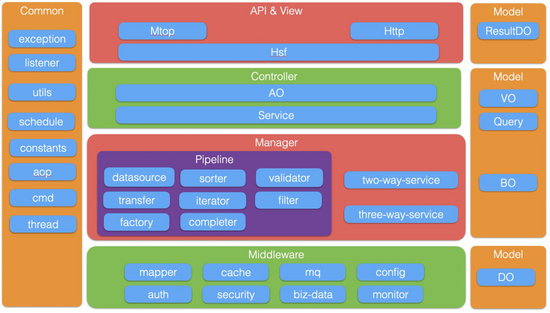
| 数据补齐二方服务 | 优势 | 劣势 |
| 商品中心(IC) | 最底层的数据源,有item和sku维度的信息 | 维度不够多,比如一些商品的运营信息 |
| 阿拉丁 | 维度比较多,比如商品白底图 | 只有item维度信息,但是有些数据源不稳定,比如品牌信息有些商品会缺失 |
| 搜索的Summary | 跟主搜的信息保持一致,信息比较实时,比如优惠、销量信息 | 只有item维度信息,维度不够多 |
{
"tabList": [
{
"tabName": "tab1",
"tabId": "xxx",
"filterList": [
{
"filterName": "xxx",
"filterId": "xxx",
"filterItemList": [
{
"filterItemName": "fitler1",
"filterItemId": "xxx"
},
{
"filterItemName": "fitler2",
"filterItemId": "xxx"
}
]
}
]
},
{
"tabName": "tab2",
"tabId": "xxx",
"filterList": [
{
"filterName": "xxx",
"filterId": "xxx",
"filterItemList": [
{
"filterItemName": "fitler1",
"filterItemId": "xxx"
},
{
"filterItemName": "fitler2",
"filterItemId": "xxx"
}
]
}
]
}
]
}
{
"tabId": "xxx",
"filterList": [
{
"filterId": "xxx",
"filterItemList": [
{
"filterItemId": "xxx"
},
{
"filterItemId": "xxx"
}
]
},
{
"filterId": "xxx",
"filterItemList": [
{
"filterItemId": "xxx"
},
{
"filterItemId": "xxx"
}
]
}
]
}
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack