......我有2个index,假设其中index1中数据是 id1,id2,id3,index2 中是 id1,id3。我的目的是能找出缺失的 id2 的数据,并且后续进去的 id4,id5 如果有缺失的也能发现。——问题来源:死磕 Elasticsearch 知识星球
假定有两个索引 index1、index2,这两个索引中有大量相同数据。
这个问题的本质是实现类似:linux 下的 diff 命令的操作,找出一个索引中存在而在另外一个索引不存在的数据。
Elasticsearch 没有直接实现找索引数据差异的类 diff 命令可用。
但,redis 中有 sdiff 命令可以一键搞定一个集合中有而另外一个集合中没有的数据。
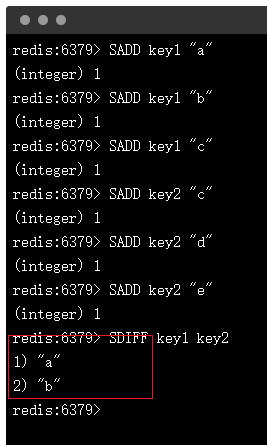
这就引申出方案一:借助 redis 实现。
那么问题来了,不用 redis, Elasticsearch 自身能否搞定呢?
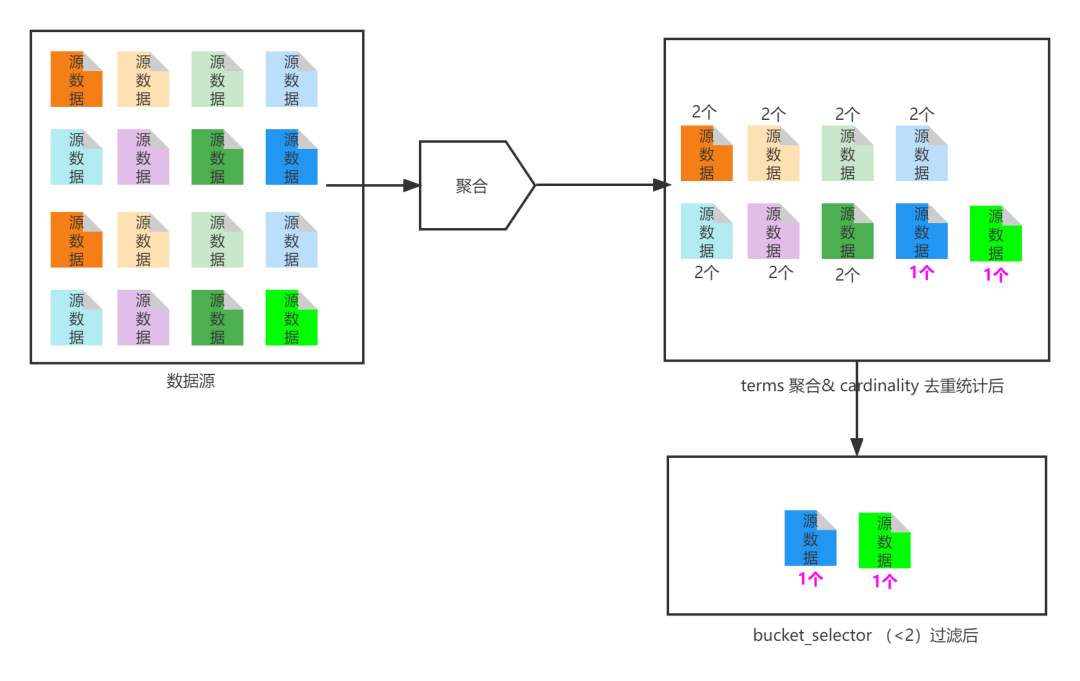
其实是可以搞定的。我们通过组合索引检索,然后对索引中公有相同主键字段进行聚合,然后进行去重统计,找出计数 < 2 的就是我们想要的 id 。因为:如果两个索引都有数据,势必聚合后计数 >= 2。此为方案二。
还有,我们可以借助 Elasticsearch transform 实现,此为方案三。
类似问题是个业界通用问题,有没有开源实现方案呢?此为方案四。
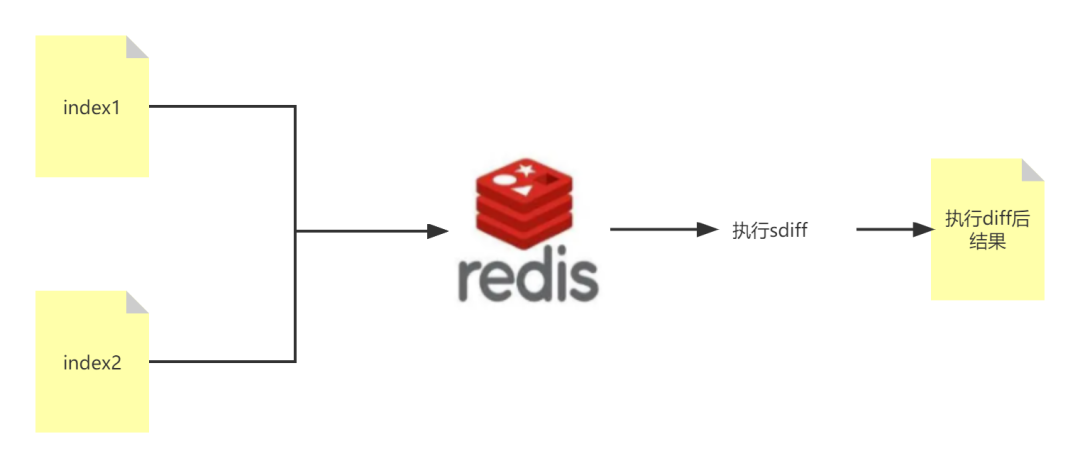
前提:Elasticsearch 索引数据中有类似 MySQL 主键的字段,能唯一标定一条记录。如果没有可以使用 _id 字段,但不建议使用 _id ,下文会说原因。
实施步骤如下:
步骤1:将 index1 (数据量多的,全量索引)的主键字段 uniq_1 导入 redis;
步骤2:将 index2 的主键字段 uniq_2 导入 redis;
步骤3:使用 sdiff 命令行返回结果就是期望不同 id 值。
我们用 kibana 自带的索引数据仿真一把。
POST _reindex
{
"source": {
"index": "kibana_sample_data_flights"
},
"dest": {
"index": "kibana_sample_data_flights_ext"
}
}
GET kibana_sample_data_flights/_count
共60个,用作不同的值区分用
POST kibana_sample_data_flights_ext/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"OriginCountry.keyword": {
"value": "US"
}
}
},
{
"term": {
"OriginWeather.keyword": {
"value": "Rain"
}
}
},
{
"term": {
"DestWeather.keyword": {
"value": "Rain"
}
}
}
]
}
}
}
删除掉了60条记录 "deleted" : 60,
POST kibana_sample_data_flights_ext/_delete_by_query
{
"query": {
"bool": {
"must": [
{
"term": {
"OriginCountry.keyword": {
"value": "US"
}
}
},
{
"term": {
"OriginWeather.keyword": {
"value": "Rain"
}
}
},
{
"term": {
"DestWeather.keyword": {
"value": "Rain"
}
}
}
]
}
}
}这样操作之后,_data_flights_ext 索引就比 _data_flights 索引少了 60 条数据。
如何实现聚合呢?
先全局设置修复可能的报错,设置如下:
PUT _cluster/settings
{
"persistent": {
"indices.id_field_data.enabled": true
}
}POST kibana_sample_data_flights,kibana_sample_data_flights_ext/_search
{
"size": 0,
"aggs": {
"group_by_uid": {
"terms": {
"field": "_id",
"size": 1000000
},
"aggs": {
"count_indices": {
"cardinality": {
"field": "_index"
}
},
"values_bucket_filter_by_index_count": {
"bucket_selector": {
"buckets_path": {
"count": "count_indices"
},
"script": "params.count < 2"
}
}
}
}
}
}size 值设置的比较大,是因为提高聚合精度的原因,否则结果会不准确。
前面如果不设置的话,会报错如下:
"reason" : "Fielddata access on the _id field is disallowed, you can re-enable it by updating the dynamic cluster setting: indices.id_field_data.enabled"也就是说 8.X 版本不推荐使用 id 作为聚合操作的字段,这也解释了前文让自己生成 uniq_id 的原因所在。
执行结果如下:

doc_count 为 1 的结果值,就是我们期望的结果。
如果上面聚合不好理解,简化版图解如下:
transform 咱们之前文章提及的少,这里简单说一下。
transform 含义如其英文释义一致“转换、改造”的意思。就是把已有索引“转换、改造”为汇总索引(summarized indices),方便我们做后续的分析操作。
transform 常见的 API 如下所示:

https://www.elastic.co/guide/en/elasticsearch/reference/current/transform-apis.html
其实这一步非必须,只不过我们后面使用了 _id 字段,不先创建索引、指定 mapping 的话会报错。
PUT compare
{
"mappings": {
"_meta": {
"_transform": {
"transform": "index_compare",
"version": {
"created": "8.2.2"
},
"creation_date_in_millis": 1656279927899
},
"created_by": "transform"
},
"properties": {
"unique-id": {
"type": "keyword"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-1"
}
},
"aliases": {}
}compare 就是我们目标生成的:汇总索引 。
细心的读者会发现,这个 compare 像是系统生成的索引。没错的,这是借助:POST _transform/_preview ...生成然后人工做部分修改后的索引。
PUT _transform/index_compare
{
"source": {
"index": [
"kibana_sample_data_flights",
"kibana_sample_data_flights_ext"
],
"query": {
"match_all": {}
}
},
"dest": {
"index": "compare"
},
"pivot": {
"group_by": {
"unique-id": {
"terms": {
"field": "_id"
}
}
},
"aggregations": {
"compare": {
"scripted_metric": {
"map_script": "state.doc = new HashMap(params['_source'])",
"combine_script": "return state",
"reduce_script": """
if (states.size() != 2) {
return "count_mismatch"
}
if (states.get(0).equals(states.get(1))) {
return "match"
} else {
return "mismatch"
}
"""
}
}
}
}
}source:指定了两个源索引,便于后续的 compare 操作。
pivot:中枢、枢纽的意思,所有的核心操作都放到这里面。执行的核心:先以_id 做了聚合操作,然后针对聚合后的结果做了处理;聚合结果不为2(必然为1),就是我们期望的结果,返回:count_mismatch。其他,若相等返回:match。
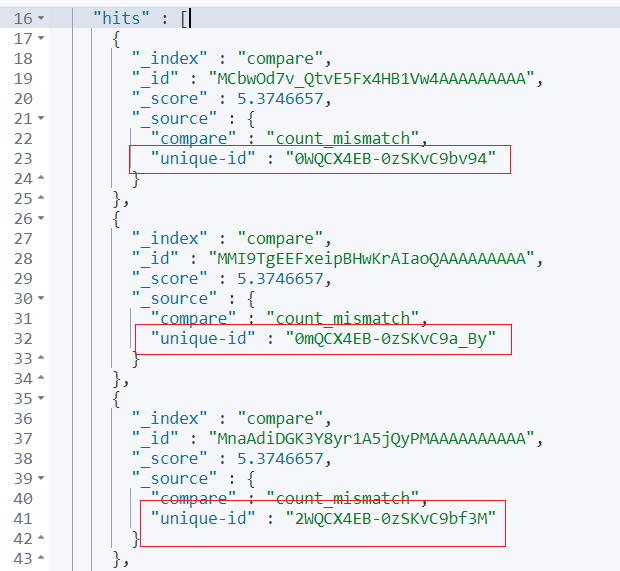
POST _transform/index_compare/_startPOST compare/_search
{
"track_total_hits": true,
"size": 1000,
"query": {
"term": {
"compare.keyword": {
"value": "count_mismatch"
}
}
}
}返回结果就是我们期望的不同值,截图如下所示:
认知前提:只要我们认为是问题的点,极大可能“前人”早已经遇到过,更大可能“前人”早已经给出了解决方案甚至已经开源了解决方案。这是我从业10年+感触比较深的地方,一句话:“非必要,不重复造轮子”。
开源方案 1:https://github.com/Aconex/scrutineer/
可实现不同数据源,如:Elasticsearch VS Elasticsearch,Elasticsearch VS Solr 之间的索引数据比较。
开源方案 2:https://github.com/olivere/esdiff
可实现比较不同索引之间文档的差异。
实现参考如下:
$ ./esdiff -u=true -d=false 'http://localhost:19200/index01/tweet' 'http://localhost:29200/index01/_doc'
Unchanged 1
Updated 3 {*diff.Document}.Source["message"]:
-: "Playing the piano is fun as well"
+: "Playing the guitar is fun as well"
Created 4 {*diff.Document}:
-: (*diff.Document)(nil)
+: &diff.Document{ID: "4", Source: map[string]interface {}{"message": "Climbed that mountain", "user": "sandrae"}}只要思想不滑坡,方案总比问题多。
自己写程序能否实现呢?当然也是可以的。“index1是完整的可以作为参照物。以插入时间为主线(时间戳,应该每条记录都会有一条数据)拿 index1 的每个id数据在 index2 中进行检索,如果存在,ok没有问题;如果不存在,记录一下id,id 存入一个集合里面,这个 id 集合就是想要的 目标 id 集合。”
你的业务场景有没有遇到类似问题,如何解决的呢?
欢迎留言讨论。

更短时间更快习得更多干货!
和全球 1600+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur