(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录交叉类型泛型创建泛型函数调用泛型函数:简化调用泛型函数:泛型约束 指定更加具体的类型添加约束 泛型接口 泛型类泛型工具类型 Partial Readonly Pick ,>Record ,>交叉类型交叉类型(&):功能类似于接口继承(extends),用于组合多个类型为一个类型(常用于对象类型)。比如解释:使用交叉类型后,新的类型PersonDetail就同时具备了Person和Contact的所有属性类型。相当于,交叉类型(&)和接口继承(extends)的对比: 相同点:
在Rails4应用程序中使用Arel,我将如何构建WHERE子句的以下部分?:stopped_at我已经有以下内容:started_at_date=Arel::Nodes::NamedFunction.new('DATE',[arel_table[:started_at]])next_day=Arel::Nodes::NamedFunction.new('DATE_ADD',[started_at_date,'INTERVAL1DAY'])conditions=arel_table[:stopped_at].lt(next_day)问题是INTERVAL1DAY被引用:>>condit
我有(例如)一个包含以下内容的mysql表“登录”:user_id|last_login1|2015-02-0105:01:071|2015-02-0112:42:092|2015-02-0122:16:232|2015-02-0215:45:232|2015-02-0421:27:043|2015-02-0406:25:454|2015-02-0503:12:01我的问题是:如何生成每天所有唯一身份用户的摘要。所以我会这样报告:day|count2015-02-01|22015-02-02|12015-02-04|22014-02-05|1此查询无效:SELECTDATE_FORMA
Ø练习1://通过并行化生成rddvalrdd1=sc.parallelize(List(5,6,4,7,3,8,2,9,1,10))//对rdd1里的每一个元素乘2然后排序valrdd2=rdd1.map(_*2).sortBy(x=>x,true)//过滤出大于等于十的元素valrdd3=rdd2.filter(_>=10)//将元素以数组的方式在客户端显示rdd3.collectØ练习2:valrdd1=sc.parallelize(Array("abc","def","hij"))//将rdd1里面的每一个元素先切分在压平valrdd2=rdd1.flatMap(_.split('')
运维安全项目-加密隧道1.加密隧道服务概述2.openVPN应用场景3.虚拟机环境准备3.0准备知识3.1添加网卡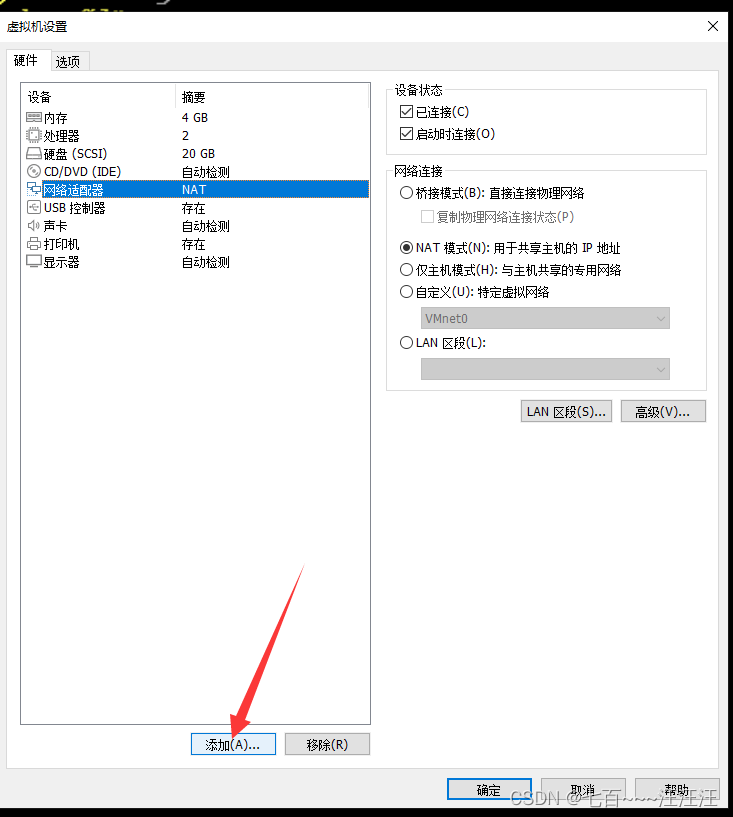3.2配置内网(LAN区段)3.3虚拟机选择LAN区段3.4书写eth1网卡配置文件4.OpenVPN服务端配置4.1环境准备简介4.2证书准备流程4.2.1安装证书创建工具4.2.2创建ca证书4.2.2.1充当权威机构修改vars文件4.2.2.2充当权威机构创建ca证书4.2.3创建server端证书和私钥文件4.2.4创建d
我想使用sparkstreaming从像mysql这样的RDBMS数据库中读取数据。但我不知道如何使用JavaStreamingContext来做到这一点JavaStreamingContextjssc=newJavaStreamingContext(conf,Durations.milliseconds(500));DataFramedf=jssc.??我在网上搜索,但我没有找到任何东西提前致谢。 最佳答案 如果不安装一些第三方软件,你就不能那样做。您可以做的是结合使用SparkSQL包和Streaming包,创建一个个性化的接收
1.ORCAD Capture cls 界面的快捷键键盘 按键对应的操作I放大 (可以滚轮操作)O缩小 (可以滚轮操作)W画线Esc退出现在的状态 (画图界面右键 End xxx)N放置网络标号J放置节点 (控制画线时候,两条线连接的时候是否有交点)F放置电源G放置地H元件左右翻转V元件上下翻转R 元件旋转90度B放置总线 (多条线连在一起)Y画多边形 (和画线差不多)T放置标题N线 写名称,(无线连接)ctrl+c复制ctrl +v 粘贴ctrl+s保存文件2.制作stm32f407ZET6 最小系统的原理图 步骤::新建原理图文件--->新建库文件--->放置元件--->
SELECT*,DAYNAME(created_on)AScreated_dayFROMusers_feedbackWHEREcreated_day='wednesday'当我执行上面的查询时,它会产生如下错误ErrorCode:1054Unknowncolumn'created_day'in'whereclause'ExecutionTime:00:00:00:000TransferTime:00:00:00:000TotalTime:00:00:00:000 最佳答案 您不能在WHERE子句中使用来自SELECT的别名。…WHE
背景spark任务读取hive表,查询字段为小写,但Hive表字段为大写,无法读取数据问题错误:如何解决呢?Inversion2.3andearlier,whenreadingfromaParquetdatasourcetable,SparkalwaysreturnsnullforanycolumnwhosecolumnnamesinHivemetastoreschemaandParquetschemaareindifferentlettercases,nomatterwhether spark.sql.caseSensitive issetto true or false.Since2.4,
一、思维导图二、作业试编程:封装一个学生的类,定义一个学生这样类的vector容器,里面存放学生对象(至少3个)再把该容器中的对象,保存到文件中。封装一个学生的类,定义一个学生这样类的载体容器,里面存放学生对象(至少3个)再把该容器中的对象,保存到文件中.再把这些学生从文件中读取出来,放入另一个容器中并且遍历输出该容器里的学生。再把这些学生从文件中读取出来,放入另一个容器中并且遍历输出该容器里的学生.#include#include#include//包含头文件usingnamespacestd;classStu{public:stringname;intage;public:Stu(){};