在处理pandas数据框内的数据方面需要一些帮助。欢迎任何帮助。我有CSV格式的OHCLV数据。我已将文件加载到Pandas数据框中。如何将体积列从2.90K转换为2900或将5.2M转换为5200000。该列可以包含以千为单位的K和以百万为单位的M。importpandasaspdfile_path='/home/fatjoe/UCHM.csv'df=pd.read_csv(file_path,parse_dates=[0],index_col=0)df.columns=["closing_price","opening_price","high_price","low_price"
“但凡有点机会,千万别去外包!”在程序员圈子里面,外包程序员似乎永远处于一个尴尬的角色,如果你说他们不是程序员吧,他们也是程序员。应该说是外包这个词比较尴尬吧。赶着和正式工一样的伙,待遇缺天差地别,没有福利,逢年过节也没有礼品啥的。平常也不好去融进正式工的圈子。工作中都是一个人。经常会有朋友问我:面试通过了·,但是在纠结到底该不该去外包,看网上都在说“千外不要去外包”搞得自己也很纠结。我只能说如果能力不够,就不要眼高手低,可以接受外包,但不要一辈子都是外包,不要心安理得,要把“外包”作为一种跳板。其实现在就业还是比较艰难的,失业的被裁裁的比比皆是。所以在没有其他更好的选择的时候,去外包也不是不
我正在使用scikitlearn进行聚类(k-means)。当我使用详细选项运行代码时,它会打印每次迭代的惯性。算法完成后,我想获得每个形成的簇的惯性(k个惯性值)。我怎样才能做到这一点? 最佳答案 我设法使用fit_transform方法获取该信息,他们获取每个样本与其簇之间的距离。model=cluster.MiniBatchKMeans(n_clusters=n)distances=model.fit_transform(trainSamples)variance=0i=0forlabelinmodel.labels_:var
我正在对约100万个项目(每个表示为一个约100个特征向量)运行k-means聚类。我已经为各种k运行了聚类,现在想用sklearn中实现的轮廓分数来评估不同的结果。尝试在没有采样的情况下运行它似乎不可行并且需要很长时间,所以我假设我需要使用采样,即:metrics.silhouette_score(feature_matrix,cluster_labels,metric='euclidean',sample_size=???)不过,我不太清楚什么是合适的抽样方法。给定矩阵的大小,是否有关于使用多大样本的经验法则?是取我的分析机可以处理的最大样本更好,还是取更多较小样本的平均值更好?我
平时我一直用Notion来记录内容为主,但也一直关注着其他开源产品。上周正好看到一款非常受欢迎的开源免费笔记,今天就推荐给大家:VNote。VNote一个由程序员为程序员打造的开源笔记应用,基于Qt开发,专注于使用Markdown来写作的群体。它提供完美的编辑体验和强大的笔记管理功能,使得使用Markdown记笔记更加轻松简单。VNote将来还会支持更多的文档格式。由于Qt的支持,VNote可以高效地运行在Linux、Windows和macOS平台上。VNote的编辑可以通过下面的几张截图来初步了解:可以看到,VNote的界面非常简洁且符合现代审美。它支持原地预览和双边预览,方便我们查看编写效
我一直在使用scipy'sk-means现在已经有一段时间了,我对它在可用性和效率方面的工作方式感到非常满意。但是,现在我想探索不同的k-means变体,更具体地说,我想申请sphericalk-means在我的一些问题中。您知道球形k均值的任何良好Python实现(即类似于scipy的k均值)吗?如果不是,修改scipy的源代码以使其k-means算法适应球形有多难?谢谢。 最佳答案 在球形k-means中,您的目标是保证中心位于球体上,因此您可以调整算法以使用余弦距离,并且还应该对最终结果的质心进行归一化。当使用欧几里得距离时,
最近,一些AI生成视觉形象的应用爆火,例如只需9块9就能生成个人写真的「妙鸭相机」。由于操作简单,不涉及任何技术操作,很多用户都纷纷在朋友圈晒出妙鸭相机生成的写真。妙鸭相机虽然好用,但它是一个需要付费的应用。现在,一个名为FaceChain的开源项目可以用AI模型打造人物写真。项目上线一周,已经狂揽2.5kstar,今天还上了Github趋势排行榜第一名。项目地址:https://github.com/modelscope/facechain用户仅需提供最低三张照片,就可以获得特定风格的个人写真。例如,生成商务证件照:也可以在ModelScope创空间中直接体验这项应用,无需任何安装步骤。试玩
我需要在一维numpy.array中找到最小的第n个元素。例如:a=np.array([90,10,30,40,80,70,20,50,60,0])我想得到第5个最小的元素,所以我想要的输出是40。我目前的解决方案是这样的:result=np.max(np.partition(a,5)[:5])然而,找到5个最小的元素然后取其中最大的一个对我来说似乎有点笨拙。有更好的方法吗?我是否缺少一个可以实现我的目标的函数?有些问题的标题与此类似,但我没有看到任何可以回答我的问题的问题。编辑:我本来应该提到它,但性能对我来说非常重要;因此,heapq解决方案虽然不错,但对我来说并不适用。impor
K平均算法的介绍k平均聚类发明于1956年,是一个聚类算法,把n的对象根据他们的属性分为k个分割,kk近邻算法的案例介绍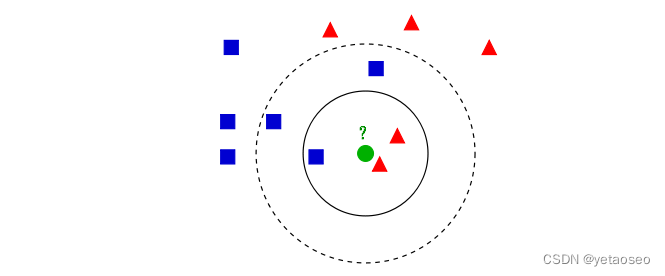如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。也就是说,现在,我们不知道中间那个绿色的数据是从属于哪一类(蓝色小正方形or红色小三角形),下面,我们就要解决这个问题:给这个绿色的圆分类。我们常说,物以类聚,人以群分,判别
在Python中,如果n是的倍数,很容易将n长的列表分成k大小的block>k(IOW,n%k==0)。这是我最喜欢的方法(直接来自docs):>>>k=3>>>n=5*k>>>x=range(k*5)>>>zip(*[iter(x)]*k)[(0,1,2),(3,4,5),(6,7,8),(9,10,11),(12,13,14)](诀窍在于[iter(x)]*k生成k对相同迭代器的引用列表,作为返回通过iter(x)。然后zip通过恰好调用迭代器的每个k副本来生成每个block。*在[iter(x)]*k之前是必需的,因为zip期望将其参数作为“单独的”迭代器接收,而不是它们的列表。