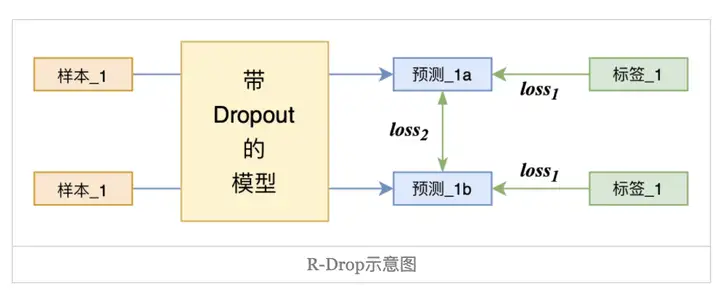
摘要:基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。
本文分享自华为云社区《R-Drop论文复现与理论讲解》,作者: 李长安。
由于深度神经网络非常容易过拟合,因此 Dropout 方法采用了随机丢弃每层的部分神经元,以此来避免在训练过程中的过拟合问题。正是因为每次随机丢弃部分神经元,导致每次丢弃后产生的子模型都不一样,所以 Dropout 的操作一定程度上使得训练后的模型是一种多个子模型的组合约束。基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。论文通过实验得出一种改进的正则化方法R-dropout,简单来说,它通过使用若干次(论文中使用了两次)dropout,定义新的损失函数。实验结果表明,尽管结构非常简单,但是却能很好的防止模型过拟合,进一步提高模型的正确率。模型主体如下图所示。
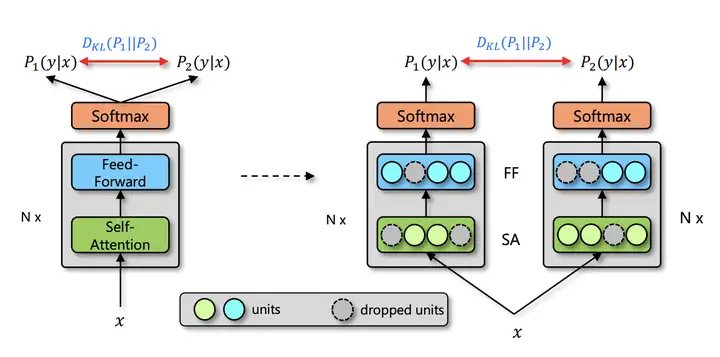
由于深度神经网络非常容易过拟合,因此 Dropout 方法采用了随机丢弃每层的部分神经元,以此来避免在训练过程中的过拟合问题。正是因为每次随机丢弃部分神经元,导致每次丢弃后产生的子模型都不一样,所以 Dropout 的操作一定程度上使得训练后的模型是一种多个子模型的组合约束。基于 Dropout 的这种特殊方式对网络带来的随机性,研究员们提出了 R-Drop 来进一步对(子模型)网络的输出预测进行了正则约束。
与传统作用于神经元(Dropout)或者模型参数(DropConnect)上的约束方法不同,R-Drop 作用于模型的输出层,弥补了 Dropout 在训练和测试时的不一致性。简单来说就是在每个 mini-batch 中,每个数据样本过两次带有 Dropout 的同一个模型,R-Drop 再使用 KL-divergence 约束两次的输出一致。既约束了由于 Dropout 带来的两个随机子模型的输出一致性。
模型的训练目标包含两个部分,一个是两次输出之间的KL散度,如下:
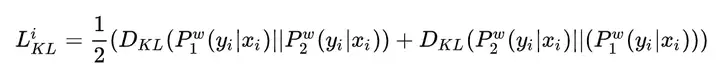
另一个是模型自有的损失函数交叉熵,如下:
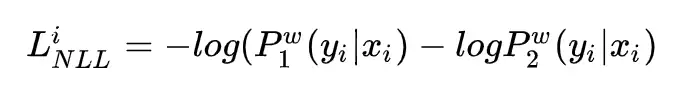
总损失函数为:
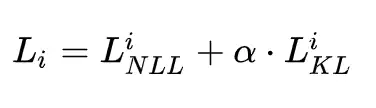
与传统的训练方法相比,R- Drop 只是简单增加了一个 KL-divergence 损失函数项,并没有其他任何改动。其PaddlePaddle版本对应的代码实现如下所示。
交叉熵=熵+相对熵(KL散度) 其与交叉熵的关系如下:
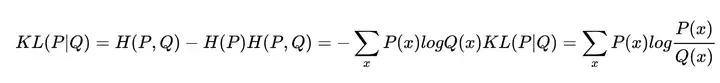
import paddle.nn.functional as F
# define your task model, which outputs the classifier logits
model = TaskModel()
def compute_kl_loss(self, p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, axis=-1), F.softmax(q, axis=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, axis=-1), F.softmax(p, axis=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)
# 论文中对于CV任务的超参数
α = 0.6
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss本次实验以白菜生长的四个周期为例,进行生长情况识别实验。数据来自于讯飞的比赛。数据展示如下:发芽期、幼苗期、莲座期、结球期。




!cd 'data/data107306' && unzip -q img.zip
!cd 'data/data106868' && unzip -q pdweights.zip
# 导入所需要的库
from sklearn.utils import shuffle
import os
import pandas as pd
import numpy as np
from PIL import Image
import paddle
import paddle.nn as nn
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle.nn.functional as F
from paddle.metric import Accuracy
import warnings
warnings.filterwarnings("ignore")
# 读取数据
train_images = pd.read_csv('data/data107306/img/df_all.csv')
train_images = shuffle(train_images)
# 划分训练集和校验集
all_size = len(train_images)
# print(all_size)
train_size = int(all_size * 0.9)
train_image_list = train_images[:train_size]
val_image_list = train_images[train_size:]
train_image_path_list = train_image_list['image'].values
label_list = train_image_list['label'].values
train_label_list = paddle.to_tensor(label_list, dtype='int64')
val_image_path_list = val_image_list['image'].values
val_label_list1 = val_image_list['label'].values
val_label_list = paddle.to_tensor(val_label_list1, dtype='int64')
# 定义数据预处理
data_transforms = T.Compose([
T.Resize(size=(256, 256)),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean = [0, 0, 0],
std = [255, 255, 255],
to_rgb=True)
])
# 构建Dataset
class MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, train_img_list, val_img_list,train_label_list,val_label_list, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
self.img = []
self.label = []
self.valimg = []
self.vallabel = []
# 借助pandas读csv的库
self.train_images = train_img_list
self.test_images = val_img_list
self.train_label = train_label_list
self.test_label = val_label_list
# self.mode = mode
if mode == 'train':
# 读train_images的数据
for img,la in zip(self.train_images, self.train_label):
self.img.append('data/data107306/img/imgV/'+img)
self.label.append(la)
else :
# 读test_images的数据
for img,la in zip(self.test_images, self.test_label):
self.img.append('data/data107306/img/imgV/'+img)
self.label.append(la)
def load_img(self, image_path):
# 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟
image = Image.open(image_path).convert('RGB')
image = np.array(image).astype('float32')
return image
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
image = self.load_img(self.img[index])
label = self.label[index]
return data_transforms(image), label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.img)
#train_loader
train_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='train')
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=8, shuffle=True, num_workers=0)
#val_loader
val_dataset = MyDataset(train_img_list=train_image_path_list, val_img_list=val_image_path_list, train_label_list=train_label_list, val_label_list=val_label_list, mode='test')
val_loader = paddle.io.DataLoader(val_dataset, places=paddle.CPUPlace(), batch_size=8, shuffle=True, num_workers=0)
from work.senet154 import SE_ResNeXt50_vd_32x4d
from work.res2net import Res2Net50_vd_26w_4s
from work.se_resnet import SE_ResNet50_vd
# 模型封装
# model_re2 = SE_ResNeXt50_vd_32x4d(class_num=4)
model_re2 = Res2Net50_vd_26w_4s(class_dim=4)
model_ss = SE_ResNet50_vd(class_num=4)
model_ss.train()
model_re2.train()
epochs = 2
optim1 = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model_re2.parameters())
optim2 = paddle.optimizer.Adam(learning_rate=3e-4, parameters=model_ss.parameters())
import paddle.nn.functional as F
def compute_kl_loss(p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, axis=-1), F.softmax(q, axis=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, axis=-1), F.softmax(p, axis=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
predicts1 = model_re2(x_data)
predicts2 = model_ss(x_data)
loss1 = F.cross_entropy(predicts1, y_data, soft_label=False)
loss2 = F.cross_entropy(predicts2, y_data, soft_label=False)
# cross entropy loss for classifier
ce_loss = 0.5 * (loss1 + loss2)
kl_loss = compute_kl_loss(predicts1, predicts2)
# 论文中对于CV任务的超参数
α = 0.6
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss
# 计算损失
acc1 = paddle.metric.accuracy(predicts1, y_data)
acc2 = paddle.metric.accuracy(predicts2, y_data)
loss.backward()
if batch_id % 50 == 0:
print("epoch: {}, batch_id: {}, loss1 is: {}".format(epoch, batch_id, loss.numpy()))
optim1.step()
optim1.clear_grad()
optim2.step()
optim2.clear_grad()本文介绍了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升,并以白菜生长情况识别为例对R-Drop进行了实战。
R-Drop论文的实现思路实际上非常简单,在论文中,作者对CV以及NLP两大任务进行了实验,但是几乎用的都是Transformer的模型,深度神经网络是深度学习的基础,但其在训练模型时会出现过拟合的问题,而简单易用的 Dropout 正则化技术可以防止这种问题的发生。然而 Dropout 的操作在一定程度上会使得训练后的模型成为一种多个子模型的组合约束。
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
所以我从维基百科上抓取了这段ruby代码并做了一些修改:@trie=Hash.new()defbuild(str)node=@triestr.each_char{|ch|cur=chprev_node=nodenode=node[cur]ifnode==nilprev_node[cur]=Hash.new()node=prev_node[cur]end}endbuild('dogs')puts@trie.inspect我首先在控制台irb上运行它,每次我输出node时,每次{}都会给我一个空哈希值,但当我实际调用时该函数使用参数'dogs'字符串构建,它确实有效,并输出{"d"=>
运行有问题或需要源码请点赞关注收藏后评论区留言一、利用ContentResolver读写联系人在实际开发中,普通App很少会开放数据接口给其他应用访问。内容组件能够派上用场的情况往往是App想要访问系统应用的通讯数据,比如查看联系人,短信,通话记录等等,以及对这些通讯数据及逆行增删改查。首先要给AndroidMaifest.xml中添加响应的权限配置 下面是往手机通讯录添加联系人信息的例子效果如下分成三个步骤先查出联系人的基本信息,然后查询联系人号码,再查询联系人邮箱代码 ContactAddActivity类packagecom.example.chapter07;importandroid
Two-StreamConvolutionalNetworksforActionRecognitioninVideos双流网络论文精读论文:Two-StreamConvolutionalNetworksforActionRecognitioninVideos链接:https://arxiv.org/abs/1406.2199本文是深度学习应用在视频分类领域的开山之作,双流网络的意思就是使用了两个卷积神经网络,一个是SpatialstreamConvNet,一个是TemporalstreamConvNet。此前的研究者在将卷积神经网络直接应用在视频分类中时,效果并不好。作者认为可能是因为卷积神经
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x
各位朋友们,大家好啊,今天我要分享的是关于文件操作方面的知识。文章目录为什么会有文件操作什么是文件文件操作文件指针文件的打开与关闭fopen(打开文件)fclose(关闭文件)打开文件的方式文件的顺序读写fgets函数fputc函数fgets函数fputs函数fprintf函数fscanf函数文件的非顺序读写fseek函数ftell函数rewind函数二进制读写fwrite函数`fread函数结语为什么会有文件操作那么大家可能会问:为什么会有文件操作呢?前面我们可能都了解了通讯录,我们知道当我们使用通讯录的时候我们可以添加联系人,也可以删除联系人,但是当我们退出程序之后下次再进来的时候,我们要
我有一些大的固定宽度文件,我需要删除标题行。跟踪迭代器似乎不是很惯用。#ThisiswhatIdonow.File.open(filename).each_line.with_indexdo|line,idx|ifidx>0...endend#ThisiswhatIwanttodobutIdon'tneeddrop(1)toslurp#thefileintoanarray.File.open(filename).drop(1).each_linedo{|line|...}Ruby的成语是什么? 最佳答案 这稍微更整洁:File.op