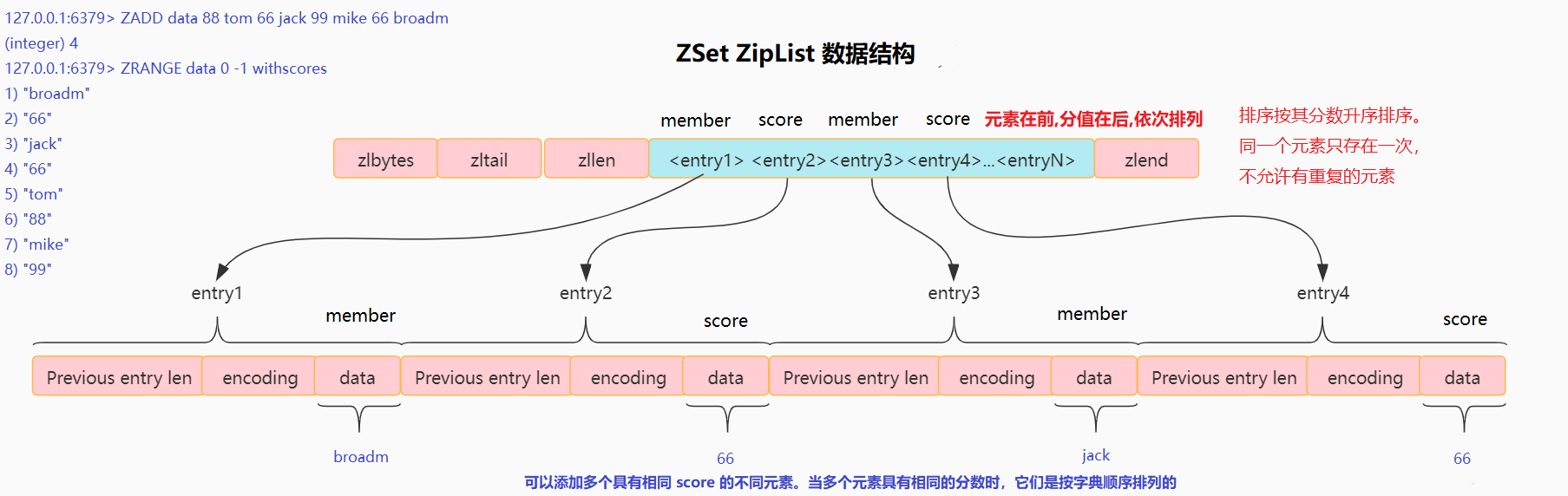
Sorted Set (ZSet), 即有序集合, 底层使用 压缩列表(ziplist) 或者 跳跃表(skiplist)
有趣的命名: Sorted Set 为啥不缩写为 SSet ? GitHub有人提问
跳表是一种数据结构。它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是 O(logn),优于数组的 O(n)复杂度。快速的查询效果是通过维护一个多层次的链表实现的,且与下面一层链表元素的数量相比,每一层链表中的元素的数量更少。
//跳跃表节点
typedef struct zskiplistNode {
robj *obj; // 成员对象
double score; // 分值
struct zskiplistNode *backward; // 后退指针
// 层
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned int span; // 跨度
} level[];
} zskiplistNode;
//跳跃表
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 表头节点和表尾节点
unsigned long length; // 表中节点的数量
int level; // 表中层数最大的节点的层数
} zskiplist;
//有序集合
typedef struct zset {
dict *dict; // 字典,键为成员,值为分值, 用于支持 O(1) 复杂度的按成员取分值操作
zskiplist *zsl; // 跳跃表,按分值排序成员, 用于支持平均复杂度为 O(log N) 的按分值定位成员操作, 以及范围操作
} zset;
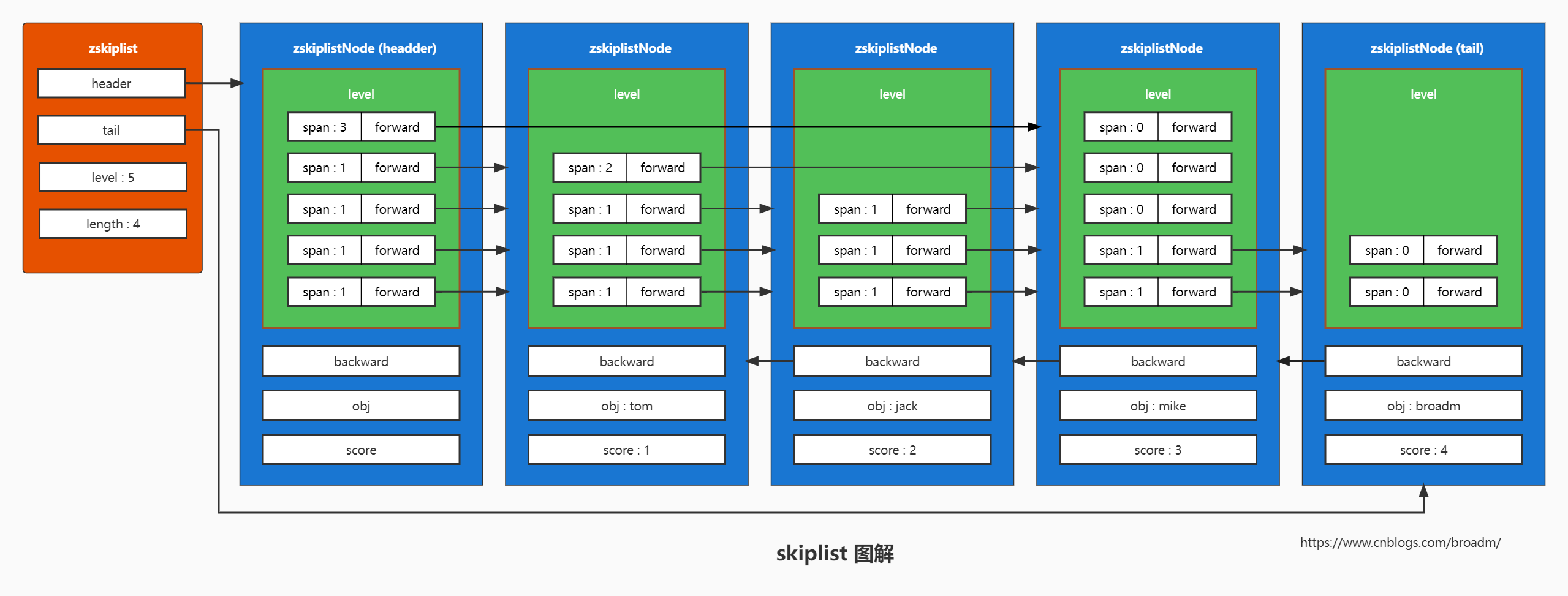
简单说下skiplist的查找过程:
比如查询 分数比 broadm 小的用户名
这里的数据量比较少,不容易看出来效果, 当数据量很大的时候,这种查询是非常高效的,平均时间复杂度为 O(logn),基本和平衡二叉树等效
文章目录认识unity打包目录结构游戏逆向流程Unity游戏攻击面可被攻击原因mono的打包建议方案锁血飞天无限金币攻击力翻倍以上统称内存挂透视自瞄压枪瞬移内购破解Unity游戏防御开发时注意数据安全接入第三方反作弊系统外挂检测思路狠人自爆实战查看目录结构用il2cppdumper例子2-森林whoishe后记认识unity打包目录结构dll一般很大,因为里面是所有的游戏功能编译成的二进制码游戏逆向流程开发人员代码被编译打包到GameAssembly.dll中使用il2ppDumper工具,并借助游戏名_Data\il2cpp_data\Metadata\global-metadata.dat
前言 Slowloris攻击是我在李华峰老师的书——《MetasploitWeb 渗透测试实战》里面看的,感觉既简单又使用,现在这种攻击是很容易被防护的啦。不过我也不敢真刀实战的去试,只是拿个靶机玩玩罢了。 废话还是写在结语里面吧。(划掉)结语可以不看(划掉)Slowloris攻击的原理 Slowloris是一种资源消耗类DoS攻击,它利用部分HTTP请求进行操作。也叫做慢速攻击,这里的慢速并不是说发动攻击慢,而是访问一条链接的速度慢。Slowloris攻击的功能是打开与目标Web服务器的连接,然后尽可能长时间的保持这些连接打开。如果由多台电脑同时发起Slo
目录一、原理部分1、什么是串行通信(1)并行通信与串行通信(2)串行通信的制式(3)串行通信的主要方式 2、配置串口(1)SCON和PCON:串行口1的控制寄存器(2)SBUF:串行口数据缓冲寄存器 (3)AUXR:辅助寄存器编辑(4)ES、PS:与串行口1中断相关的寄存器(5)波特率设置 3、串口框架编写二、程序案例一、原理部分1、什么是串行通信(1)并行通信与串行通信微控制器与外部设备的数据通信,根据连线结构和传送方式的不同,可以分为两种:并行通信和串行通信。并行通信:数据的各位同时发送与接收,每个数据位使用一条导线,这种方式传输快,但是需要多条导线进行信号传输。串行通信:数据一位一
例如,我一直看到称为String#split的方法,但从未见过String.split,这似乎更合乎逻辑。或者甚至可能是String::split,因为您可以认为#split位于String的命名空间中。当假定/隐含类(#split)时,我什至单独看到了该方法。我知道这是ri中识别方法的方式。哪个先出现?例如,这是为了区分方法和字段吗?我还听说这有助于区分实例方法和类方法。但这从哪里开始呢? 最佳答案 不同之处在于您如何访问这些方法。类方法使用::分隔符来表示消息可以发送到类/模块对象,而实例方法使用#分隔符表示消息可以发送到实例对
1、为什么压缩的原始数据一般采用YUV格式(1)利用人对图片感觉的生理特性,对于亮度信息比较敏感,对于色度信息不太敏感,所以视频编码是将Y分量和UV分量分开来编码,并且可以减少UV分量.2、视频压缩原理(1)空间冗余:图像相邻像素之间的相关性,比如一帧图片被划分成多个16x16的块之后,相邻的块之间有很多明显的相似性。(2)时间冗余:时间相差较近的两张图片变化较小。(3)视觉冗余:我们的眼睛对某些细节不太敏感,对图像中的高频信息的敏感度小于低频信息,可以去除一些高频信息。(4)编码冗余:一幅图片中不同像素出现的概率是不同的,对于出现次数较多的像素,用少的位数来编码,对于出现次数较少的像素,用多
Python程序运行原理Python是一种脚本语言,编辑完成的程序,也称源代码,可以直接运行。从计算机的角度看,Python程序的运行过程包含两个步骤:解释器将源代码翻译成字节码(即中间码),然后由虚拟机解释执行。Python程序文件的扩展名通常为.py。在执行时,首先由Python解释器将.py文件中的源代码翻译成中间码,这个中间码是一个扩展名为.pyc的文件,再由Python虚拟机(PythonVirtualMachine,PVM)逐条将中间码翻译成机器指令执行。需要说明的是,pyc文件保存在Python安装目录的pycache文件夹下,如果Python无法在用户的计算机上写人字节码,字节
我正在学习Rails数据库连接池概念。在Rails应用程序中,我将池大小定义为5。我对连接池大小的理解如下。当服务器启动时,rails会自动创建n个在database.yml文件中定义的连接。在我的例子中,它将创建5个连接,因为池大小为5。在每个http请求上,如果需要访问数据库,rails将使用连接池中的可用连接来处理请求。但我的问题是,如果我一次达到1000个请求,那么大部分请求将无法访问数据库连接,因为我的连接池大小只有5个。我上面对rails连接池的理解对吗??谢谢, 最佳答案 目的:数据库连接不是线程安全的;所以Activ
ElasticSearch——刷盘原理流程刷盘原理流程名词和操作解释相关设置刷盘原理流程整个过程会分成几步:数据会同时写入buffer缓冲区和translog日志文件buffer缓冲区满了或者到时间了(默认1s),就会将其中的数据转换成新的segment并写入系统文件缓存,这一步叫refresh其中后台会自动合并小的segment成大的segment;这一步叫段合并当translog达到大小的阈值(默认512M)或者flush默认时长(30m),则会执行flush操作:内存中数据写入新的segment放入缓存(清空内存区)一个commitpoint写入磁盘,表示哪些segment已写入磁盘将缓
此代码取自ActiveRecord2.3.14的gem类ConnectionHandlerdefestablish_connection(name,spec)@connection_pools[name]=ConnectionAdapters::ConnectionPool.new(spec)end似乎每次ruby在模型上调用establish_connection时,它都会创建一个新的连接池。我的问题:如果我有5个模型使用establish_connection连接到同一个数据库,Rails是否足够智能以选择一个已经存在的池而不是创建一个具有相同连接凭据的新池?如果我的5个模型是
实验中我们使用的是52单片机目录前言一、单片机是什么?二、实验步骤1.独立键盘检测1.2代码如下(示例):1.3图片1.4视频2.矩阵键盘检测2.2代码如下(示例):2.3图片2.4视频总结:以上就是今天要讲的内容,本文仅仅简单介绍了单片机键盘检测的应用实现,而单片机键盘检测相关理论可以参考教材进行学习前言文章内主要概念引自郭天祥老师《新概念51单片机C语言版》一书主要展示郭天祥老师书中第四章键盘检测原理及应用实现。分为仿真、实体两部分。一、单片机是什么?单片机就是在一块硅片上集成了微处理器、存储器及各种输入/输出接口的芯片,这样一块芯片就具有了计算机的属性,因而被成为单片微型计算机,简称单片