vcs2018+verdi实现独立仿真带有Vivado IP核的工程
在对带有Vivado IP核的工程进行仿真时,通常有联合仿真和独立仿真两种方法。前者通过在Vivado软件内部与其他仿真器联合实现仿真,但这存在很多弊端,例如每次必须同时启动两个软件,不够方便,效率也低;每次修改工程中的文件,都要重新编译整个工程;从别人那里拷贝来工程还要考虑两个软件的版本问题等等…因此独立仿真在实际工程仿真中有重要意义,本文旨在介绍如何用vcs2018+verdi实现独立仿真带有Vivado IP核的工程。
使用工具包括vcs-mx2018、dve、verdi和Vivado 2019.2,实现环境是Ubuntu 18.04LTS。前三个软件的安装可以参考下面这篇文章,写的非常详细和全面,照着上面一步步来即可。Vivado建议使用2019.2版本,笔者曾用2018和2017版本的Vivado尝试,均会报错与vcs-2018版本不符合。关于vcs和Vivado的版本对应问题,可自行在网上搜索,必须选择对应的版本。
但需要注意的是,必须用vcs-mx2018代替上述文章中安装的vcs2018,原因在于普通vcs只能编译verilog,但在后面对Vivado IP核库编译时还涉及到VHDL语言,因此必须采用vcs混合编译版即vcs-mx,否则在后续操作时会报错。安装包分享如下:
vcs-mx百度网盘
提取码:22r3
如下图,将VCS2018在Ubuntu20 18安装步骤中的安装包解压后,用vcs-mx百度网盘解压后的文件夹替代其中的vcs_vO-2018.09-SP2
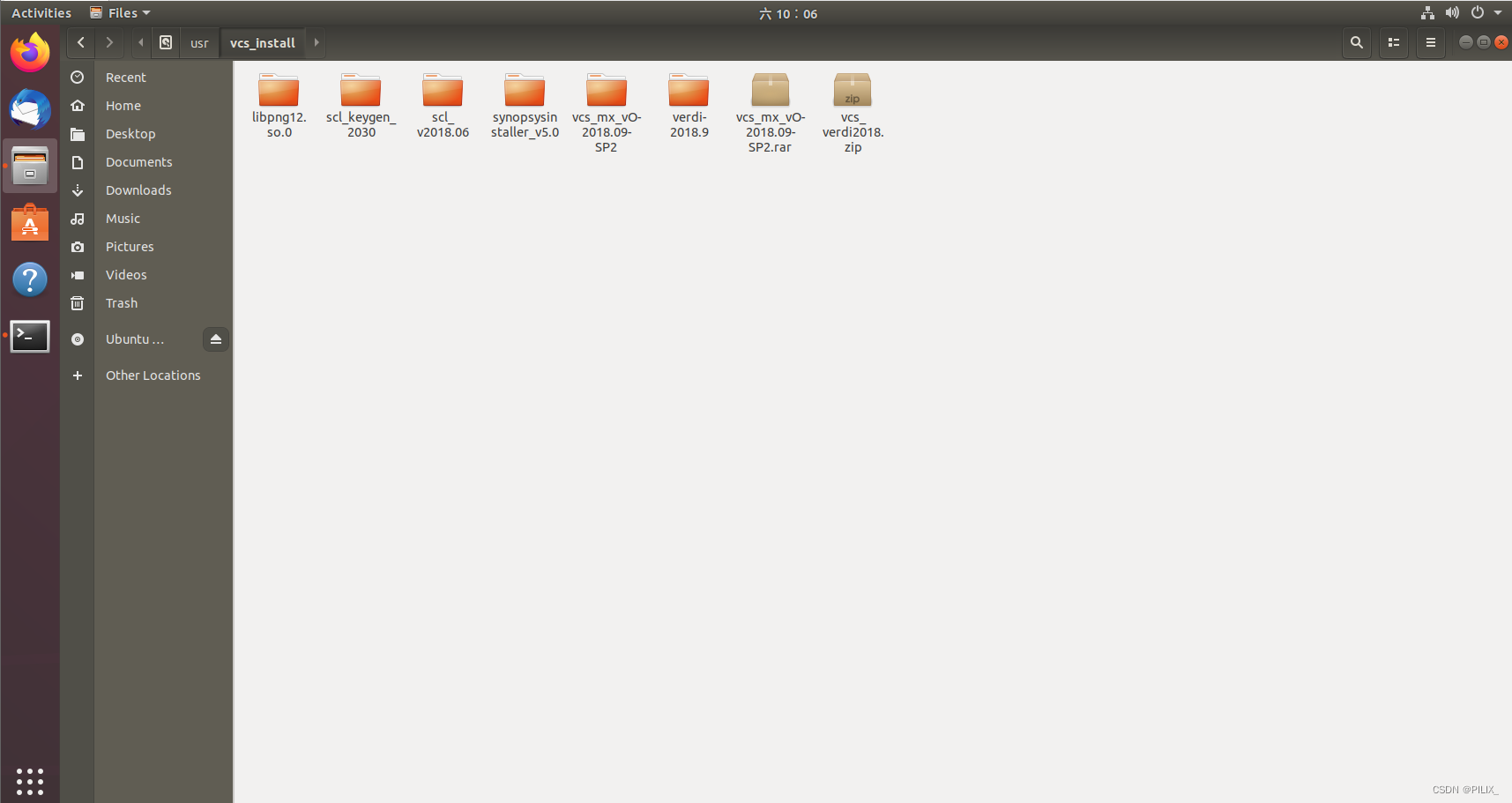
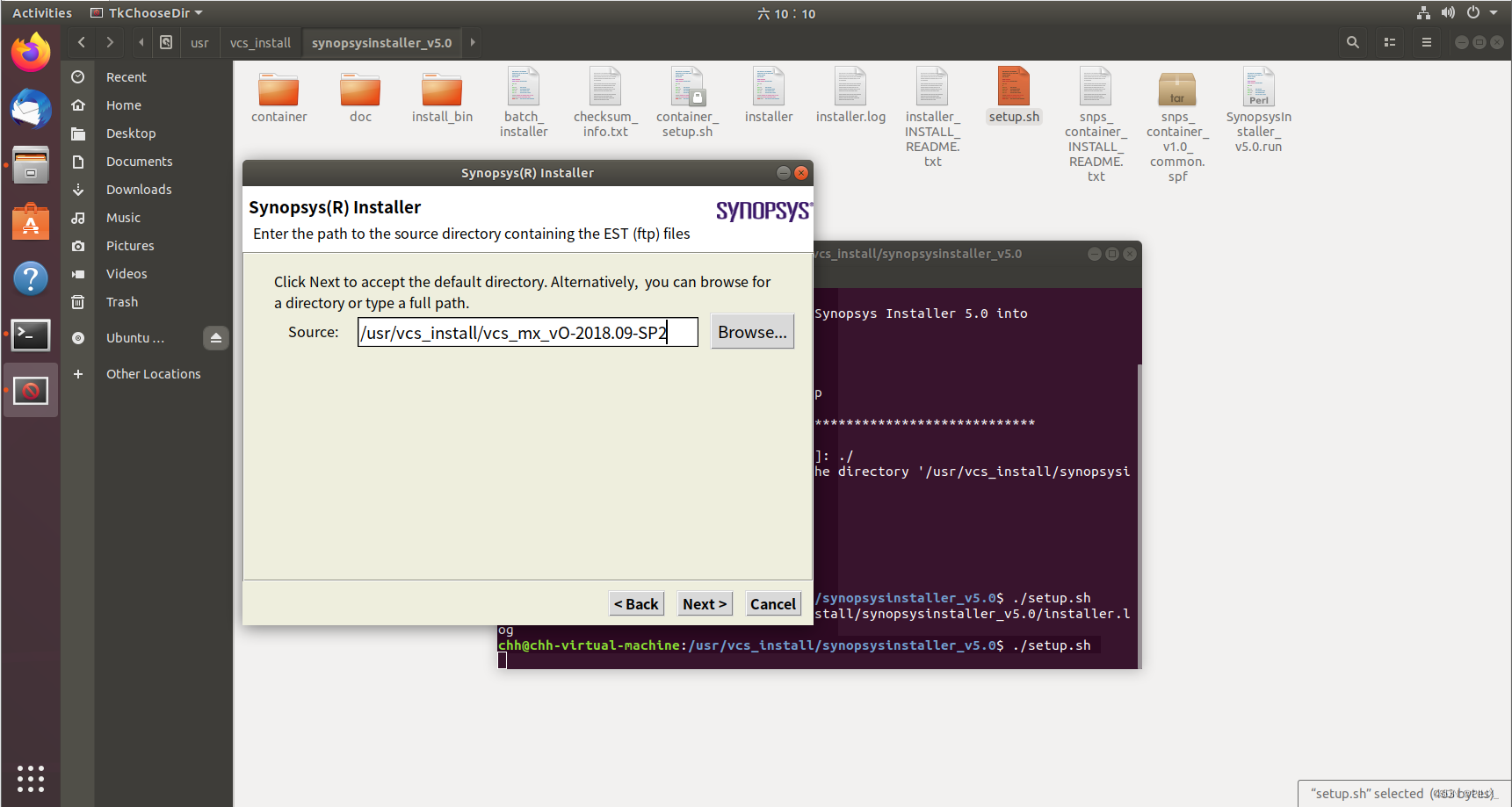
并在后续安装过程中选择安装vcs_mx
在安装完一系列软件后,首先要编译Vivado库文件,如下图所示,在Vivado的安装路径新建一个"vcs_lib“文件夹用于放编译好的一系列库文件:

接着,在Vivado的安装路径下(我这里是/tools/Xilinx/vivado/2019.2)用如下命令行的方式启动vivado,如果直接在图形化界面双击打开,编译时可能会报错。
source settings64.sh
vivado

打开Vivado 2019.2后,点击Tools–>Compile Simulation Libraries,按下图所示配置:

其中:
Compiled library location :选择刚刚创建的vcs_lib路径,用于存放编译好的库文件
Simulator executable path:选择vcs-mx安装路径下的/bin,笔者此处为/usr/software/vcs2018/vcs-mx/O-2018.09-SP2/bin
点击Compile开始编译,经过等待,出现以下信息,error为0即说明编译成功:

接着打开之前创建的vcs_lib目录就可以看到编译好的所有库文件
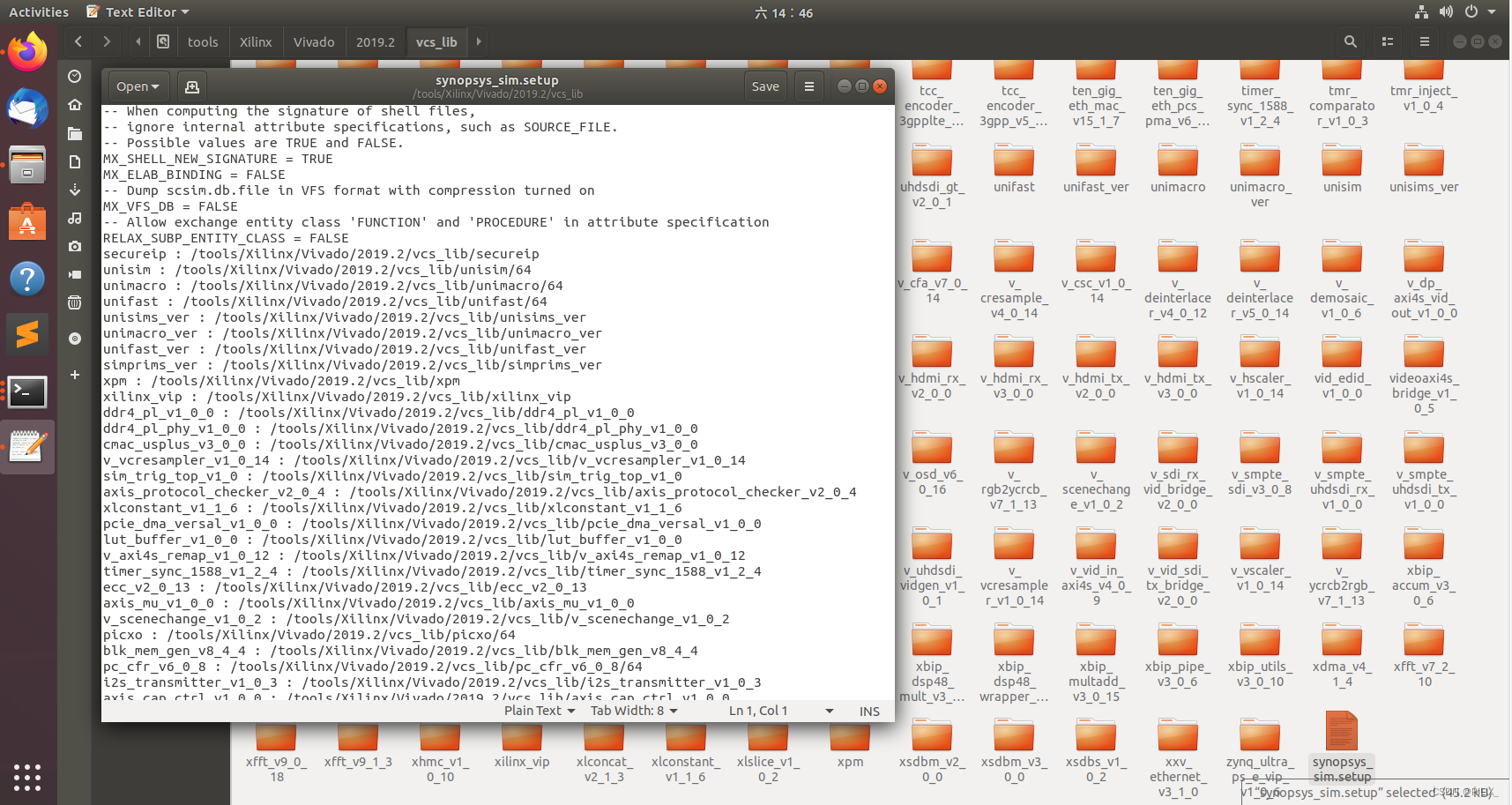
在这些生成的文件中,还包括一个非常重要的文件synopsys_sim.setup
这个文件非常重要,打开可以看到里面指明了Xilinx各个器件库的位置和绝对路径。vcs仿真时会调用这个文件来链接所有的器件库,可以说是我们实现独立仿真的”桥梁”。
以一个工程为例来实现独立仿真,可将工程文件分为两个目录,分别是rtl/和sim/,其中rtl用来存放工程代码和testbench相关文件,此处不再赘述;sim/下主要要有三个文件,分别是makefile文件,file.f(或者其他格式,作用是存放要编译的代码文件名和路径),synopsys_sim.setup文件,用于链接到vcs_lib目录下的synopsys_sim.setup文件。
file.f文件的作用是用来存放要编译的代码文件(包括RTL文件和tb文件),使用file.f文件的好处在于如果工程需要大量的增加或减少编译的文件时,可以直接在该文件里修改,而不是每次都要重新编写makefile文件。
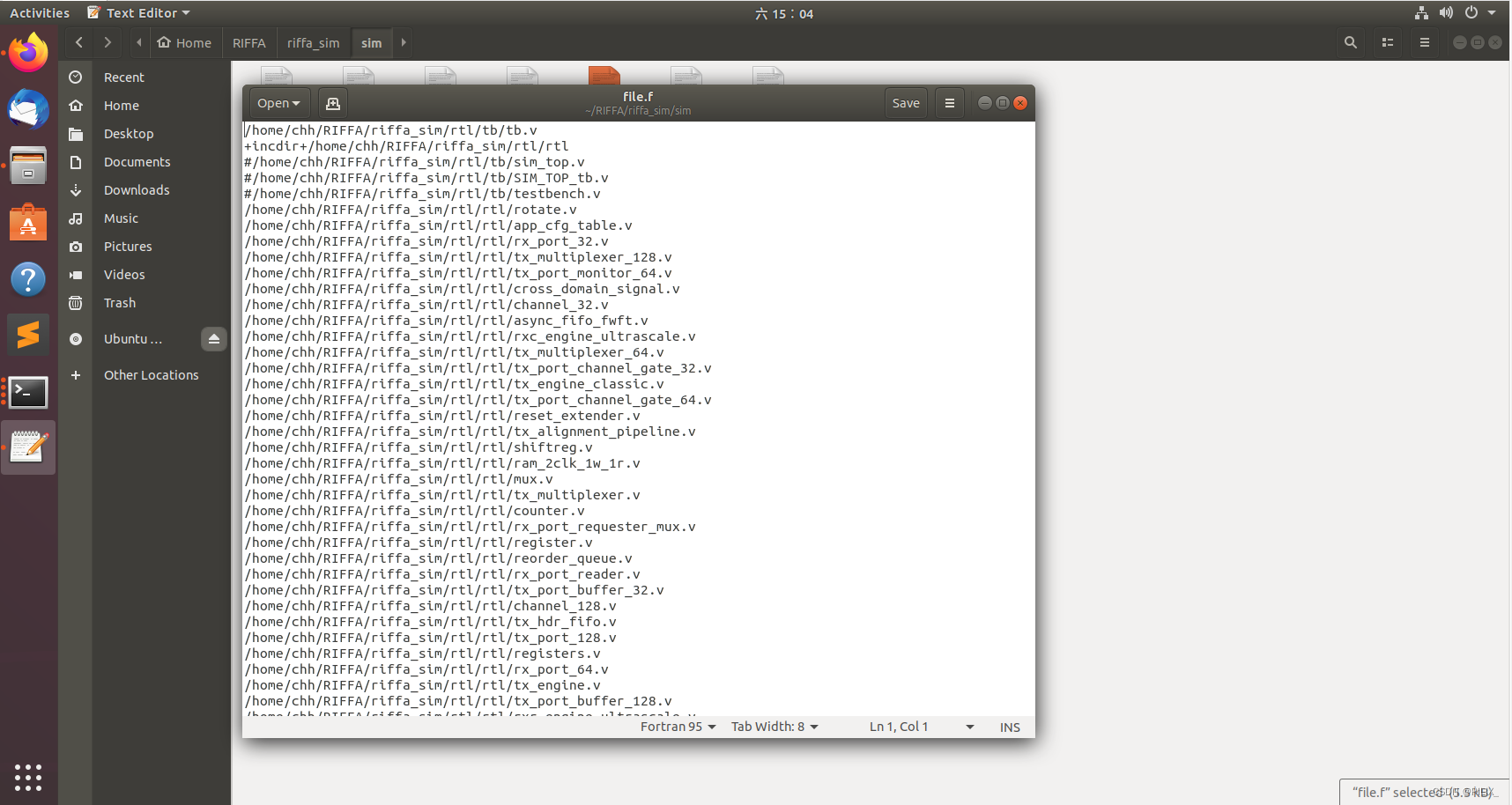
注意:绝对路径要修改为自己的代码文件路径
自定义的setup文件里需要指明vcs_lib下setup文件的绝对路径,且要放在与makefile脚本同目录的路径下。vcs参考手册对synopsys_sim.setup文件搜索路径给出详细解释,可以看到vcs编译工具在运行时会依照先后顺序从以下3个路径查找synopsys_sim.setup文件。
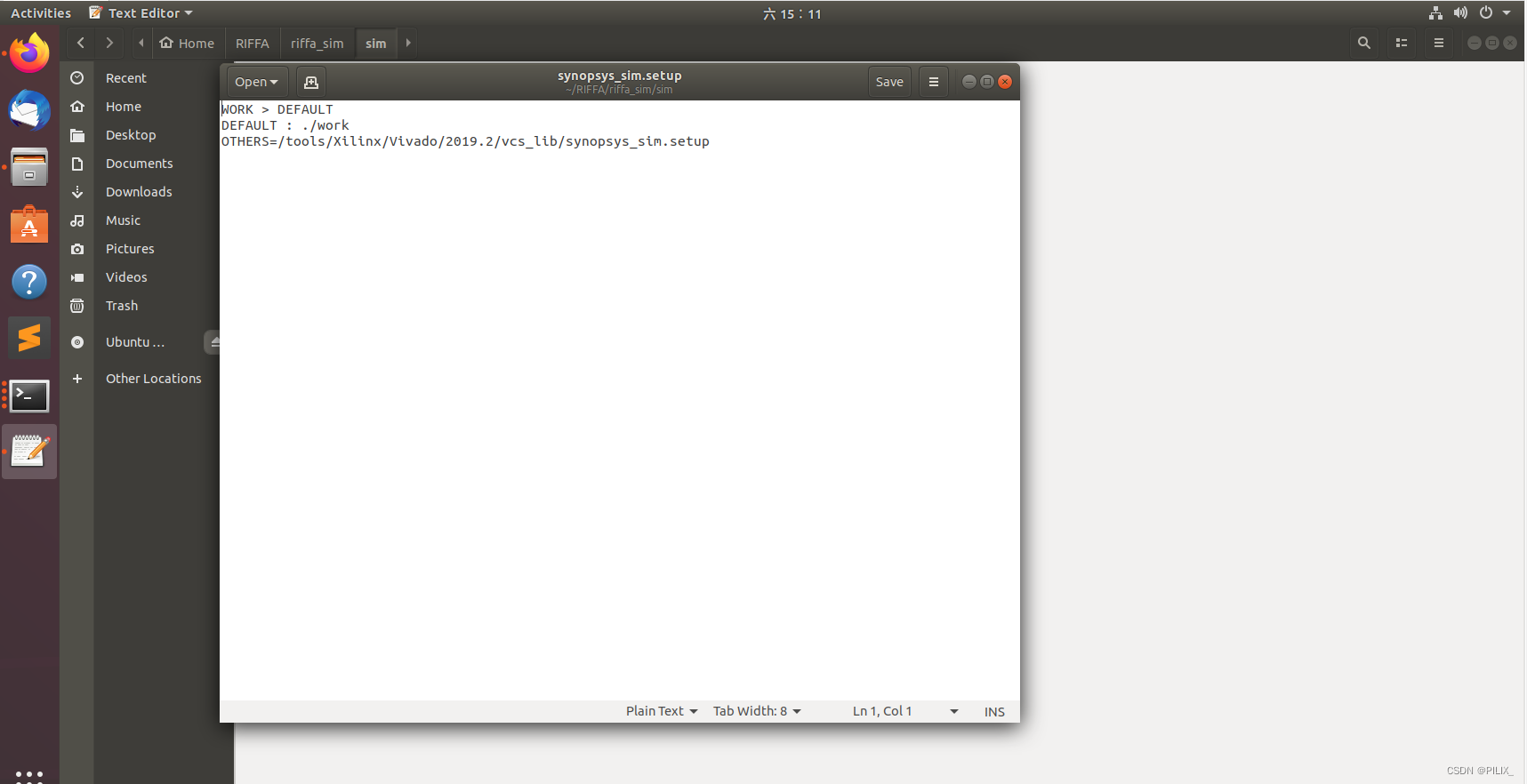

所以需要将synopsys_sim.setup文件放置在与makefile相同的目录下,vcs工具会自动搜索并识别IP库的位置。
关于makefile的具体语法在这里不多介绍,可在网上自行搜索学习,大体可分为三部分:compile、 elaborate、simulate
compile是将硬件描述语言编译成库的过程,也正是这一过程中verilog文件可能会涉及到Xilinx的IP或者硬核,这时候就需要通过synopsys_sim.setup这个文件来指定IP库的位置。

执行如下指令即可实现compile过程:
make compile
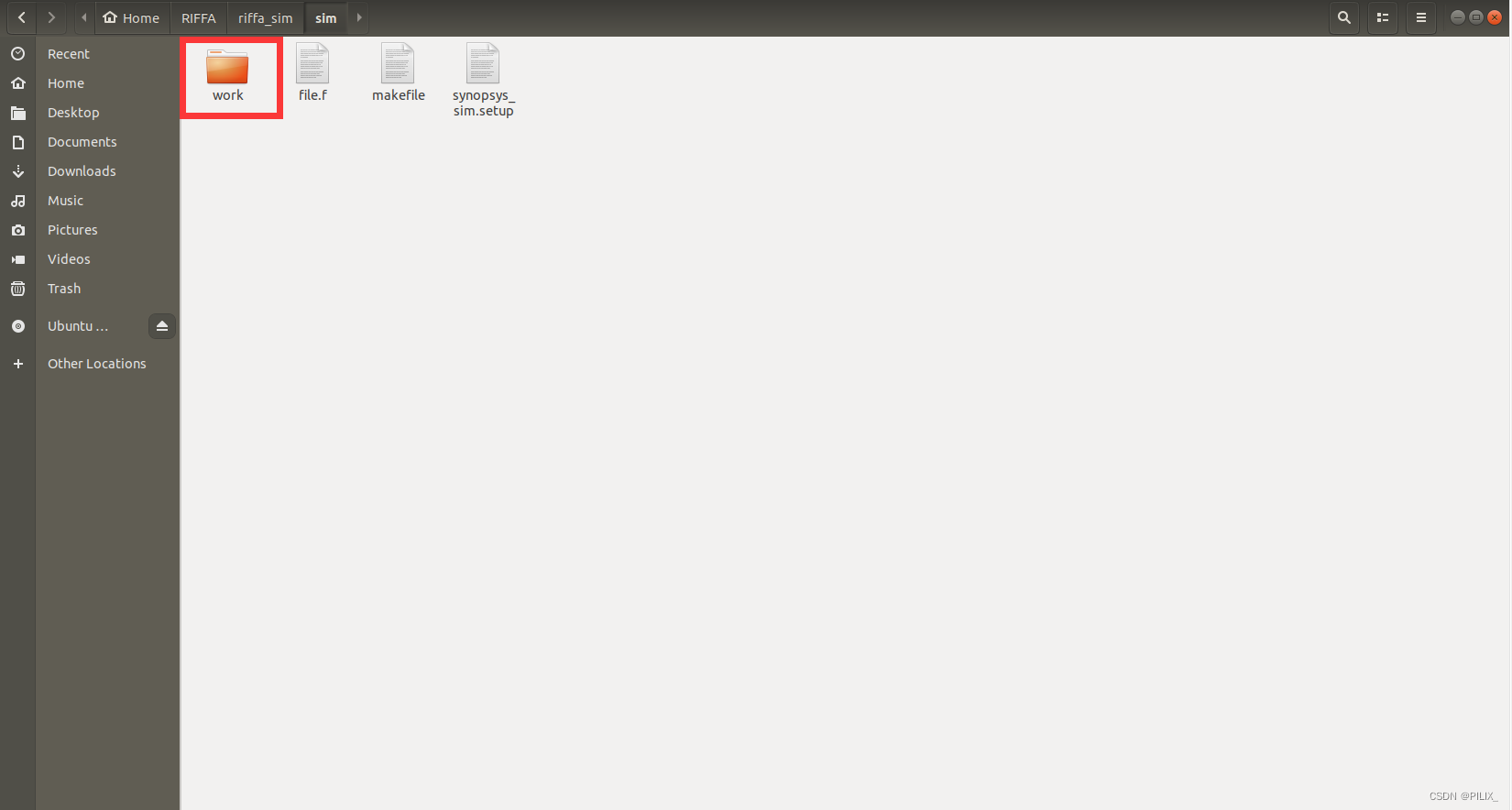
可见生成了work文件夹。
这一步是将compile生成的库文件,以及可能用到的Xilinx IP的库文件,生成仿真的可执行文件(此处为simv文件)。具体的脚本如下,主要需要指定设计的bench顶层(此处为TB)和全局复位的glbl模块
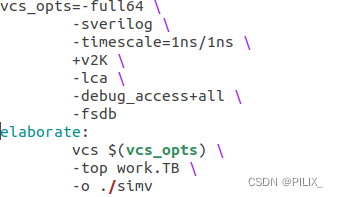
同样执行如下指令:
make elaborate
可见生成了对应的simv可执行文件:
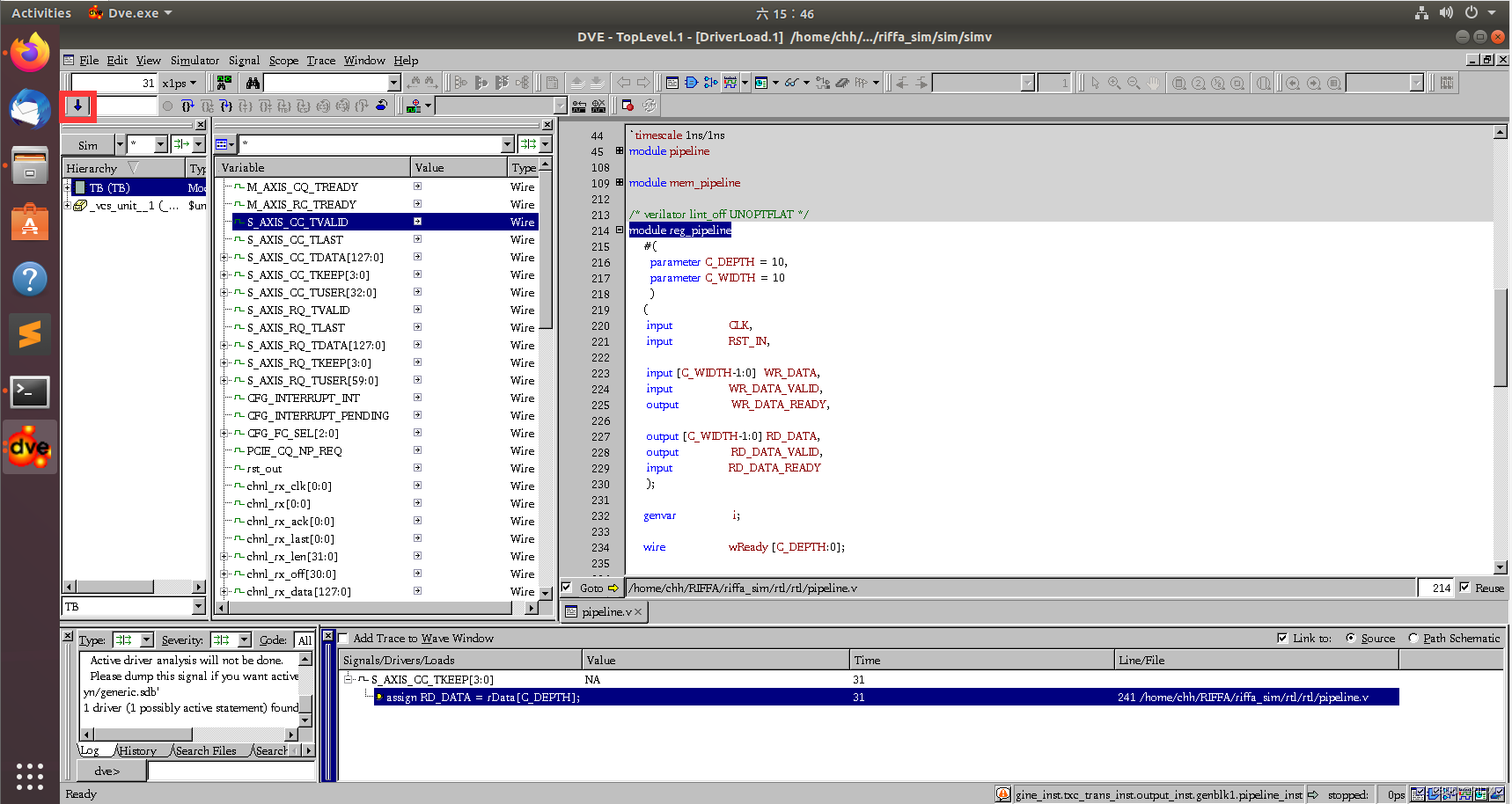
此时生成的simv文件即仿真的可执行文件,想要生成波形文件fsdb有两种方法,第一种是使用dve软件,通过以下指令:
./simv -gui
打开dve可视化界面,点击start键即可生成波形文件:
另一种方法就是在makefile中编写好simulate部分,直接生成fsdb文件,见下一部分
这一步就是执行上面生成的simv.o可执行文件,进行仿真。make simulate生成适用于verdi的fsdb文件:

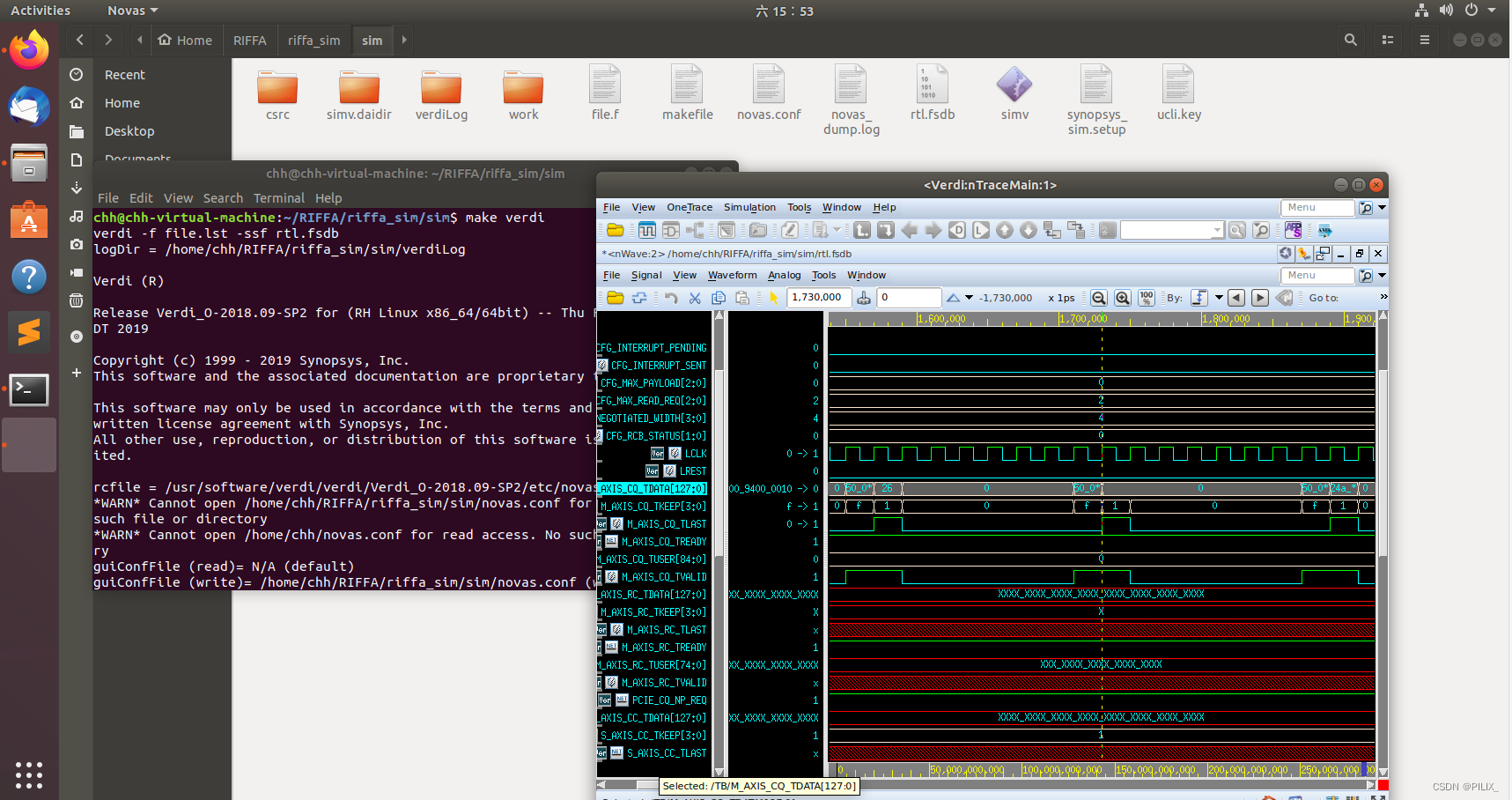
接着再输入:make verdi 即可用verdi打开fsdb文件查看波形啦:
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
说在前面这部分我本来是合为一篇来写的,因为目的是一样的,都是通过独立按键来控制LED闪灭本质上是起到开关的作用,即调用函数和中断函数。但是写一篇太累了,我还是决定分为两篇写,这篇是调用函数篇。在本篇中你主要看到这些东西!!!1.调用函数的方法(主要讲语法和格式)2.独立按键如何控制LED亮灭3.程序中的一些细节(软件消抖等)1.调用函数的方法思路还是比较清晰地,就是通过按下按键来控制LED闪灭,即每按下一次,LED取反一次。重要的是,把按键与LED联系在一起。我打算用K1来作为开关,看了一下开发板原理图,K1连接的是单片机的P31口,当按下K1时,P31是与GND相连的,也就是说,当我按下去时
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
使用rspec-rails3.0+,测试设置分为spec_helper和rails_helper我注意到生成的spec_helper不需要'rspec/rails'。这会导致zeus崩溃:spec_helper.rb:5:in`':undefinedmethod`configure'forRSpec:Module(NoMethodError)对thisissue最常见的回应是需要'rspec/rails'。但这是否会破坏仅使用spec_helper拆分rails规范和PORO规范的全部目的?或者这无关紧要,因为Zeus无论如何都会预加载Rails?我应该在我的spec_helper中做
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
假设我有一个类A,里面有一些方法。假设stringmethodName是这些方法之一,我已经知道我想给它什么参数。它们在散列中{'param1'=>value1,'param2'=>value2}所以我有:params={'param1'=>value1,'param2'=>value2}a=A.new()a.send(methodName,value1,value2)#callmethodnamewithbothparams我希望能够通过传递我的哈希以某种方式调用该方法。这可能吗? 最佳答案 确保methodName是一个符号,而