Zabbix 6.0 LTS新增Kubernetes监控功能,可以在Kubernetes系统从多个维度采集指标。我们今天就来实现Zabbix6.0对K8S的监控。
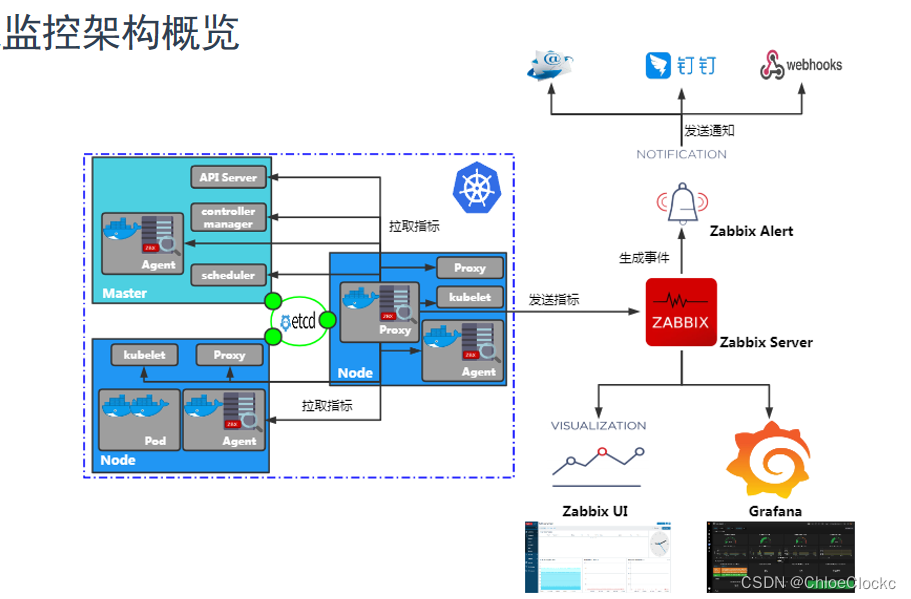

K8S集群以及组件模板
| 模板名称 | 解释 |
|---|---|
| Kubernetes API server by HTTP | K8S ApiServer组件指标模板 |
| Kubernetes cluster state by HTTP | K8S 集群指标模板 |
| Kubernetes Controller manager by HTTP | K8S ControllerManager组件指标模板 |
| Kubernetes kubelet by HTTP | K8S Kubelet组件指标模板 |
| Kubernetes nodes by HTTP | K8S 集群节点发现以及状态指标模板 |
| Kubernetes Scheduler by HTTP | K8S Scheduler组件指标模板 |
K8S节点基础信息指标模板
| 模板名称 | 解释 |
|---|---|
| Linux by Zabbix agent | OS Linux系统监控模板 |
主要监控方式
通过zabbix agent客户端,采集集群节点的CPU、内存、磁盘等基础信息指标。

通过Zabbix内置的“HTTP agent”、“Script”两种类型的监控项,无需安装客户端,通过访问被监控端的API接口即可采集监控指标数据,主要用于K8S集群、服务组件、pod容器状态及性能指标的采集。
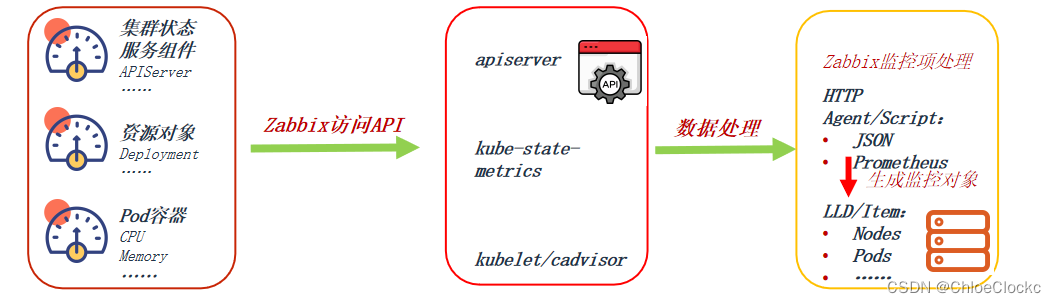
本次实现使用两台虚拟机
| 主机名 | IP |
|---|---|
| k8s-master01 | 192.168.119.81 |
| k8s-node01 | 192.168.119.91 |
在K8S集群中部署Zabbix Proxy 与 Zabbix Agent监控组件,这里采用官方提供的Helm Chart来安装。
文档:https://git.zabbix.com/projects/ZT/repos/kubernetes-helm/browse?at=refs%2Fheads%2Frelease%2F6.0
1、首先需要安装Helm工具
wget https://get.helm.sh/helm-v3.8.1-linux-amd64.tar.gz tar zxvf helm-v3.8.1-linux-amd64.tar.gz cp linux-amd64/helm /usr/local/bin/helm
2、添加Helm Chart Repository
helm repo add zabbix-chart-6.0 https://cdn.zabbix.com/zabbix/integrations/kubernetes-helm/6.0 helm repo list

3、下载Zabbix Helm Chart,并解压
helm pull zabbix-chart-6.0/zabbix-helm-chrt tar xf zabbix-helm-chrt-1.1.1.tgz
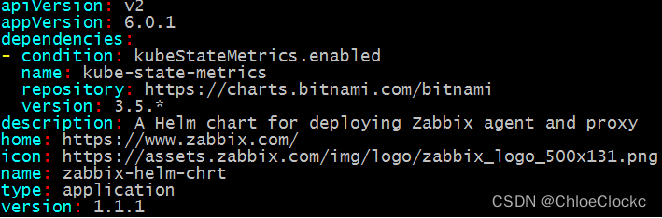
主要记录的是当前Chart的基本信息,包括版本、名称、依赖等。
| 参数 | 解释 |
|---|---|
| apiVersion | Chart API 版本 |
| name | Chart 名称 |
| description | 描述信息 |
| home | 项目home页面的URL |
| icon | 用做icon的SVG或PNG图片URL |
| type | Chart 类型 |
| version | 语义化2 版本 |
| appVersion | 包含的应用版本 |
| dependencies | 依赖的Chart列表,缓存在同级下charts目录中 |
主要为templates目录中定义K8S资源对象的配置文件变量值。
1、Zabbix Proxy 与 Agent参数配置
| 参数 | 值 | 解释 |
|---|---|---|
| fullnameOverride | zabbix | 覆盖完全限定应用名称 |
| kubeStateMetricsEnabled | true | 部署kube-state-metrics |
| zabbixProxy.image.tag | alpine-6.0.1 | ZabbixProxy Docker镜像tag,用于指定ZabbixProxy版本 |
| zabbixProxy.env.ZBX_HOSTNAME | zabbix-proxy-k8s | ZabbixProxy hostname |
| zabbixProxy.env.ZBX_SERVER_HOST | ZabbixServer地址 | |
| zabbixAgent.image.tag | alpine-6.0.1 | ZabbiAgent Docker镜像tag,用于指定ZabbiAgent版本 |
2、kube-state-metrics 依赖Chart参数配置
| 参数 | 值 | 解释 |
|---|---|---|
| Image.repository | bitnami/kube-state-metrics | kube-state-metrics 镜像库配置 |
| Image.tag | 2.2.0 | kube-state-metrics容器镜像本版本 |
1、创建monitoring命名空间
kubectl create namespace monitoring
2、Helm 安装Zabbix Chart
cd zabbix-helm-chrt helm install zabbix . --dependency-update -n monitoring
3、查看K8S Zabbix Pod
kubectl get pods -n monitoring -o wide

4、获取API接口访问Token
kubectl get secret zabbix-service-account -n monitoring -o jsonpath={.data.token} | base64 -d
1、页面创建Zabbix Proxy
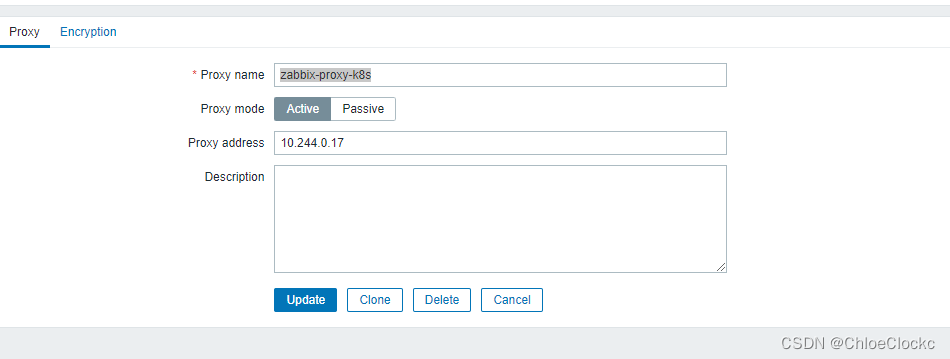
注意此处的proxy ip 地址为kubectl get 到的值
2、创建“k8s-nodes”,挂载“Kubernets nodes by HTTP”,用于自动发现节点主机。
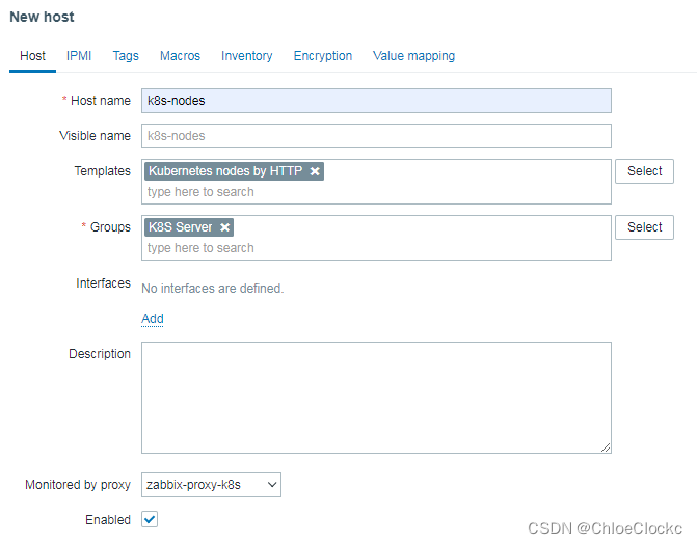
1、宏变量
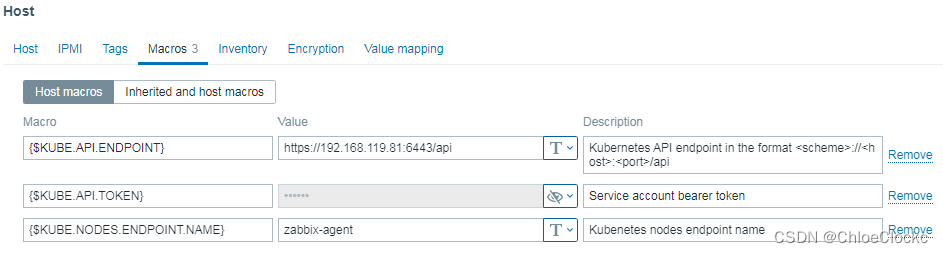
{$KUBE.API.ENDPOINT} https://192.168.119.81:6443/api
{$KUBE.API.TOKEN} 之前获取的一长串值
{$KUBE.NODES.ENDPOINT.NAME} zabbix-agent
2、查看K8S服务endpoint信息
kubectl get ep -n monitoring

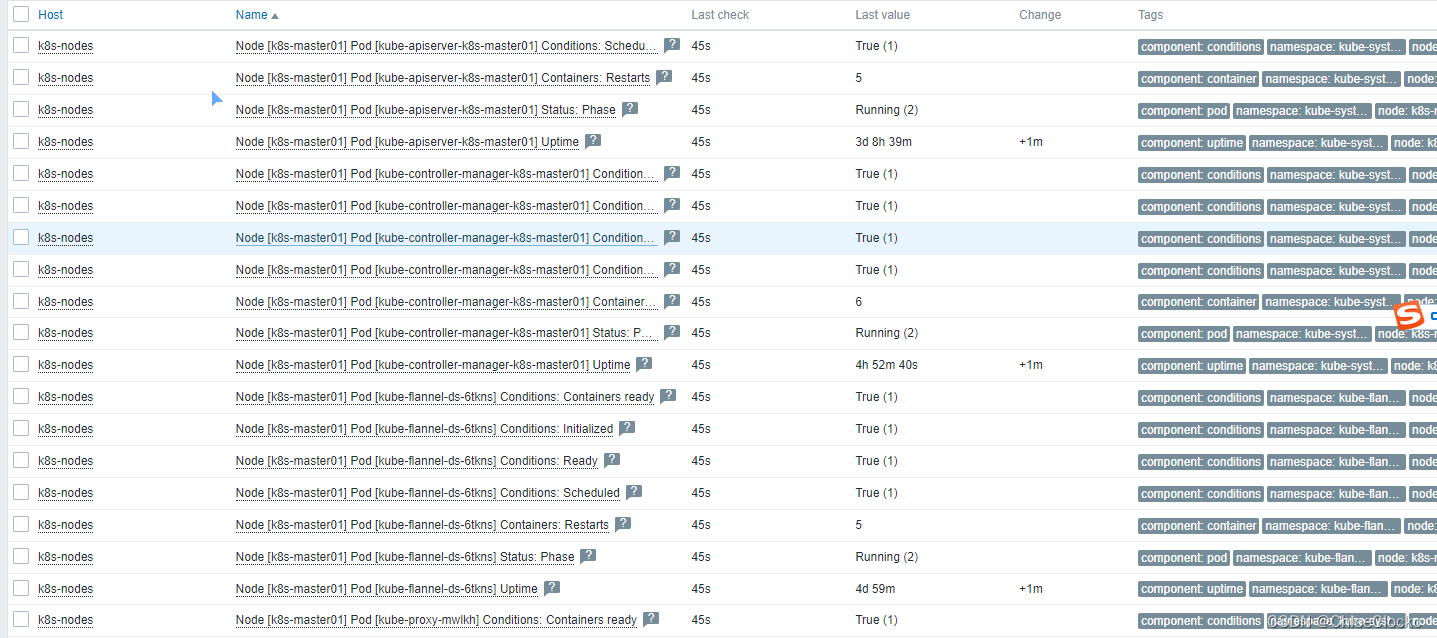
1、自动发现的节点主机

2、最新数据
创建“k8s-cluster”,挂载“Kubernetes cluster state by HTTP”,用于自动发现服务组件。
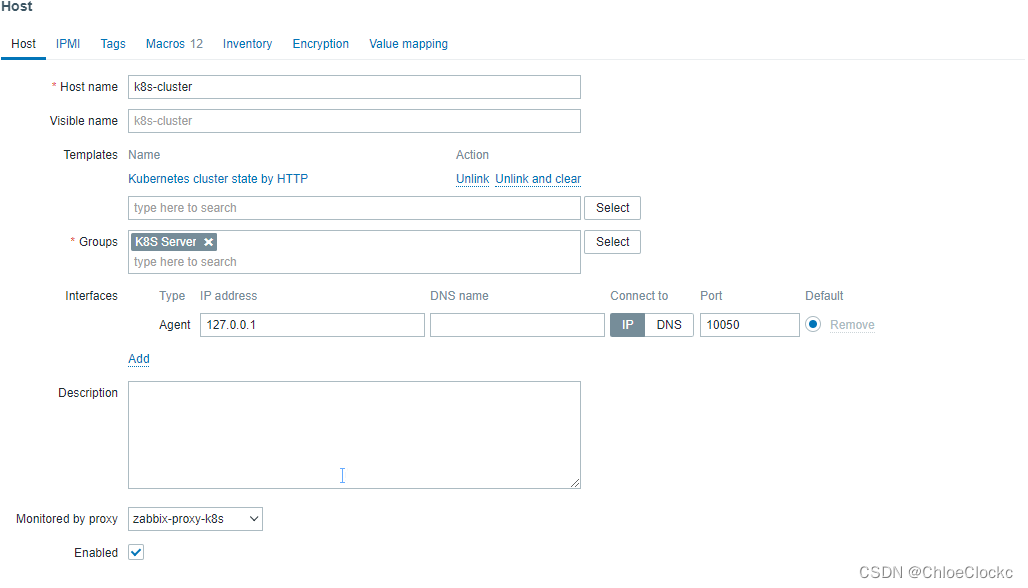
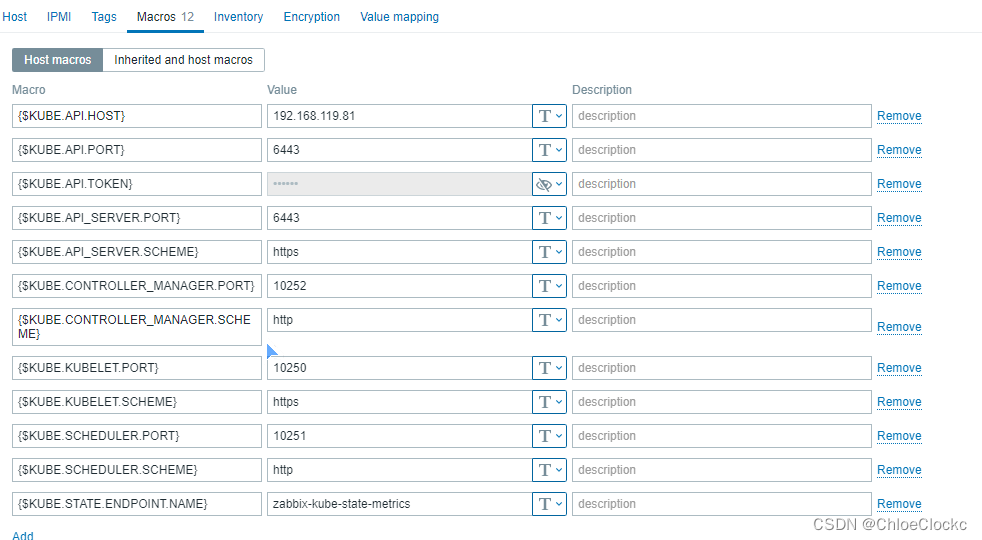
{$KUBE.API.HOST} 192.168.119.81
{$KUBE.API.PORT} 6443
{$KUBE.API.TOKEN}
{$KUBE.API_SERVER.PORT} 6443
{$KUBE.API_SERVER.SCHEME} https
{$KUBE.CONTROLLER_MANAGER.PORT} 10252
{$KUBE.CONTROLLER_MANAGER.SCHEME} http
{$KUBE.KUBELET.PORT} 10250
{$KUBE.KUBELET.SCHEME} https
{$KUBE.SCHEDULER.PORT} 10251
{$KUBE.SCHEDULER.SCHEME} http
{$KUBE.STATE.ENDPOINT.NAME} zabbix-kube-state-metrics
1、自动发现的集群服务组件主机
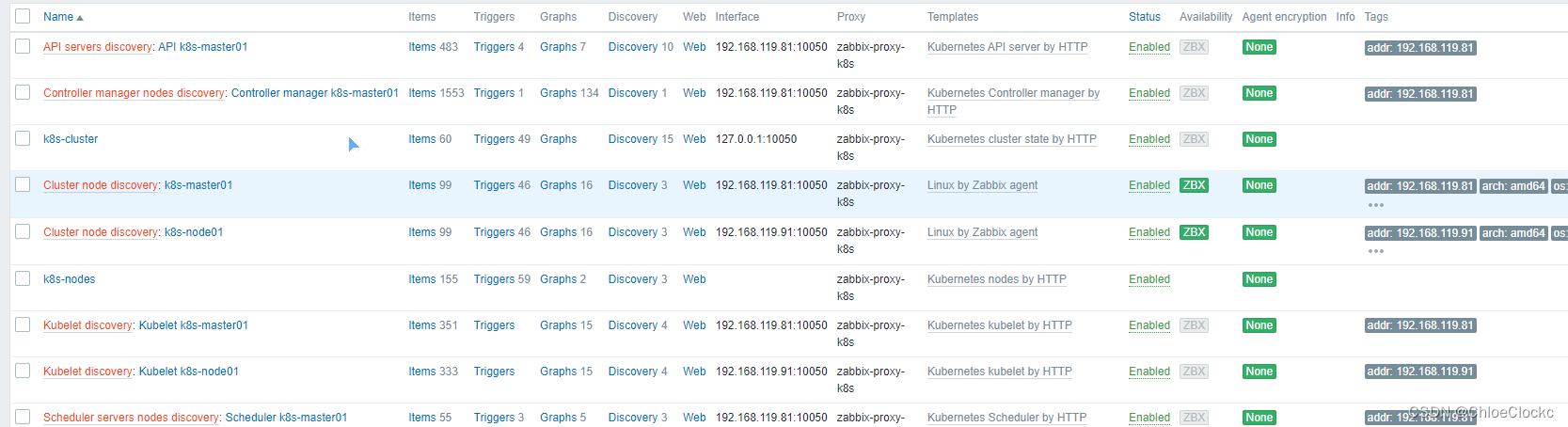
2、最新数据
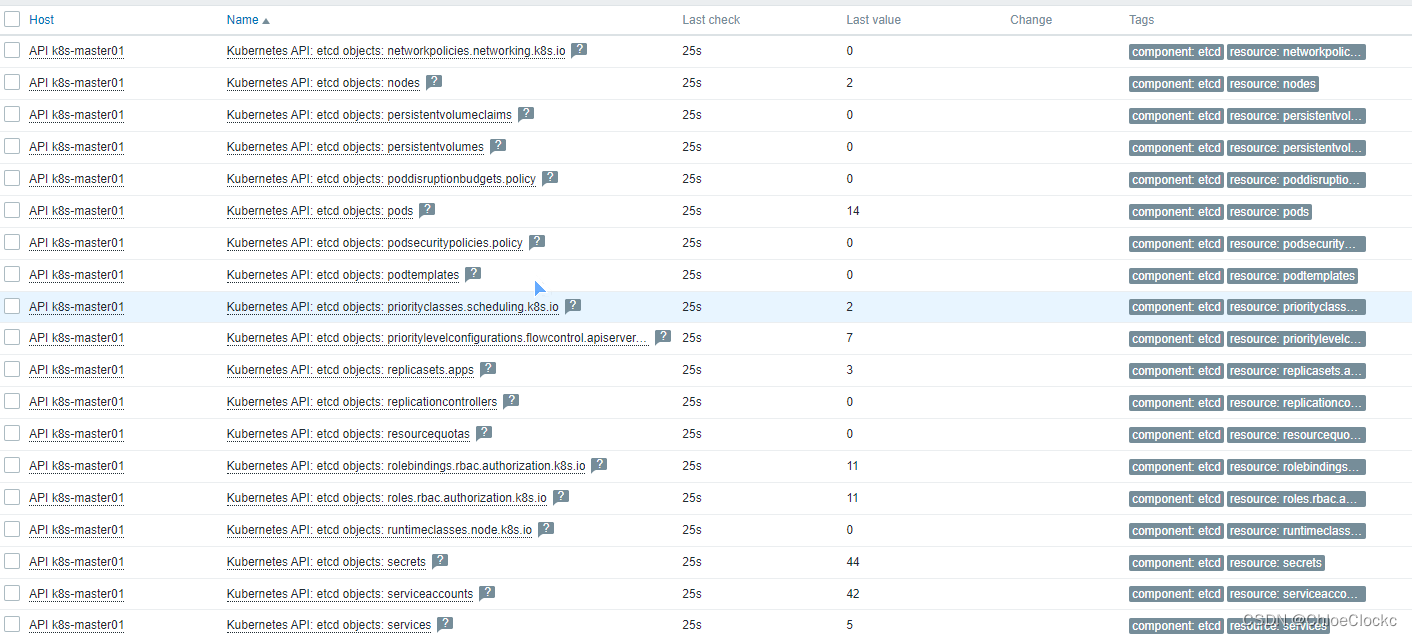
至此,我们已经完成了Zabbix6.0对K8S的监控。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项