H264是基于运动补偿的视频编码标准。所谓编码我的理解就是对数据进行压缩便于网络传输。而视频编码就是依据图像帧的像素块之间的相似性对图像进行压缩。
H264结构中,一幅图像编码后的数据叫一帧,一帧由一个或多个Slice片组成,一片由一个或多个MB宏块组成,一个宏块由16*16的yuv数据组成。宏块是H264编码的基本单位。
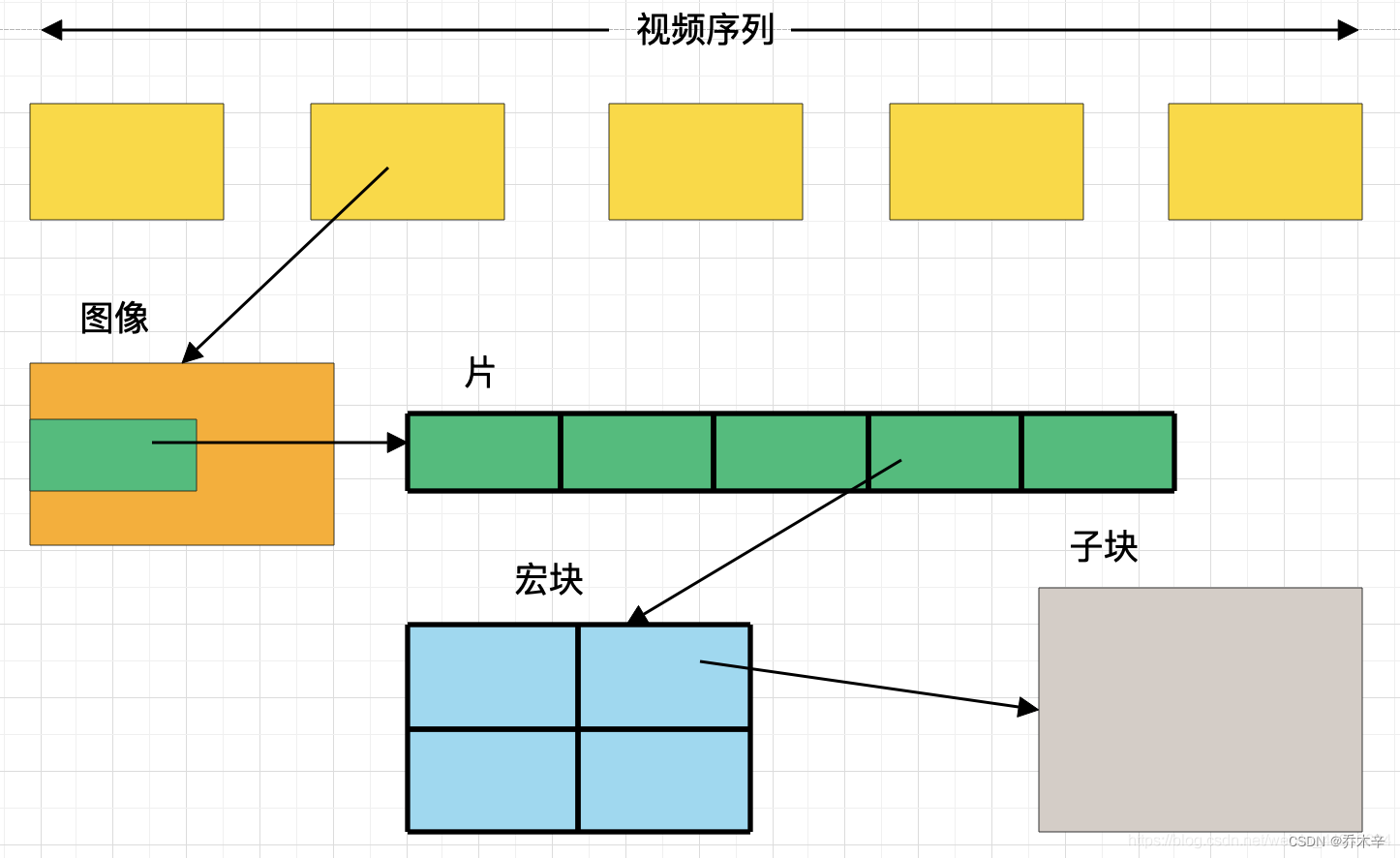
H264定义了三种帧,I帧,P帧,B帧。
group of picture 两个I帧之间的所有帧为一个GOP。
H264对关联度高的视频帧进行分组,其算法是在相邻几幅图像画面中,一般有差别的像素只有10%以内的点,亮度差值变化不超过2%,而色度差值的变化只有1%以内,我们认为这样的图可以分到一组GOP。
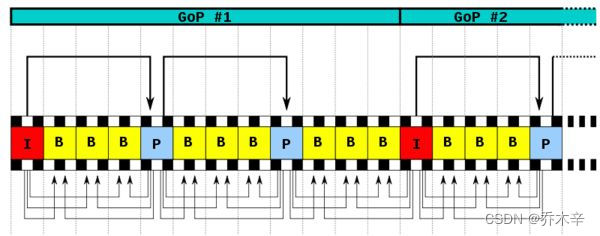
IDR帧都是I帧,但I帧不一定是IDR帧。当解码器遇到IDR帧就会清空参考队列,将已解码的数据全部输出或抛弃,开始解码新的序列。
而普通的I帧不会清理参考队列,也就是说IDR可以阻断误差的累计,而普通I帧不行。

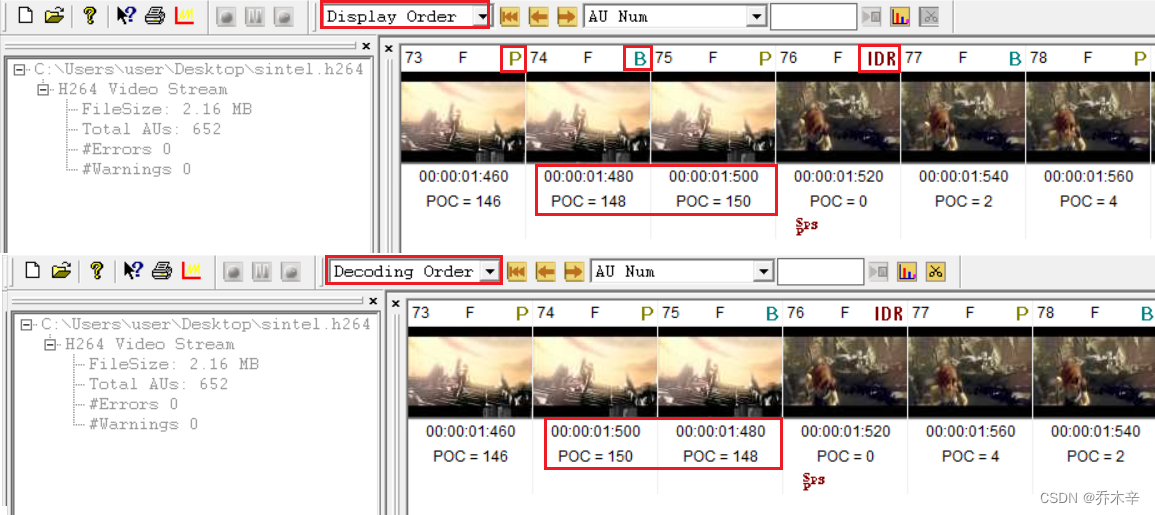
PTS(Presentation Time Stamp):PTS 主要用于度量解码后的视频帧什么时候被显示出来
DTS(Decode Time Stamp):DTS 主要是标识内存中的 bit 流什么时候开始送入解码器中进行解码

DTS 主要用户视频的解码,在解码阶段使用。PTS主要用于视频的同步和输出,在显示的时候使用。
由于B帧的存在,要参考前后帧,所以在有B帧的情况下 DTS!=PTS。没有B帧则两者相等。
https://zhuanlan.zhihu.com/p/31056455
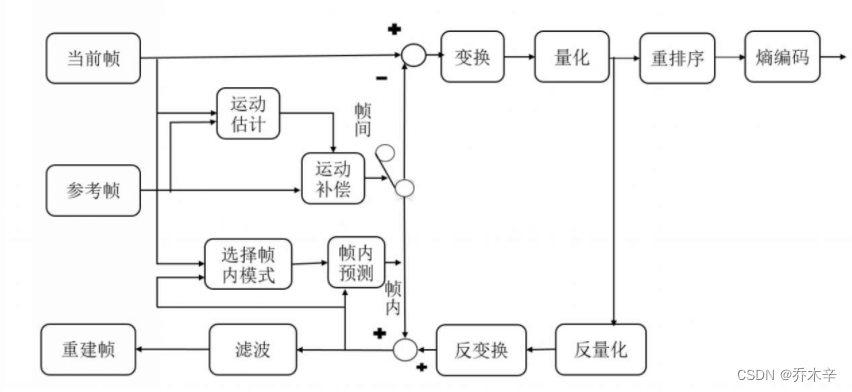
视频图像被送到H264编码器中,编码器给每一个图像划分宏块。H264默认使用16*16大小作为一个宏块。但为了更高的压缩率,还可以将宏块划分为8*16、 16*8、 8*8、 4*8、 8*4、 4*4大小的子块。

对划分好的宏块计算宏块的像素值。最终一幅图中每个宏块都处理完后如下图:

运动估计与运动补偿:
运动估计:当前帧的某个区域(A)在参考帧中寻找一个合适的匹配区域(B)。
运动补偿:找到区域A和区域B的不同。
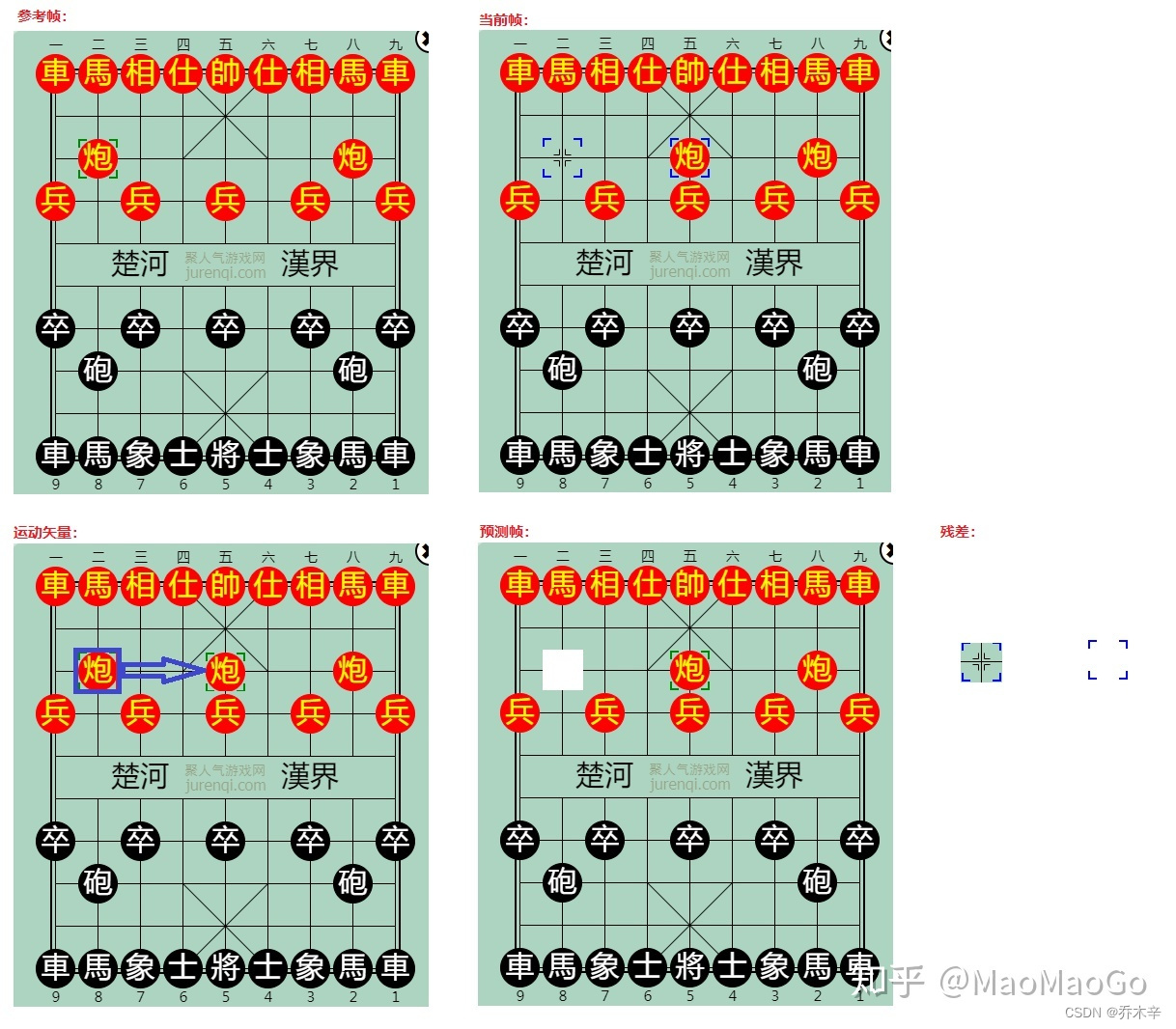
这运动矢量就是炮二的区域移动到炮五的区域,移动后产生一个预测帧。预测帧和当前帧并不完全一样,他们的区别就是残差。 此时的残差则是炮二位置的棋格,以及炮五边框的颜色变化。
预测性编码的产出就是这些运动矢量和残差,通过这个例子我们能看到这些产出数据是远远小于一个完整帧的数据量的。
https://www.cnblogs.com/charybdis/p/6049108.html
对于一幅图像,相邻的两个像素的亮度和色度是比较接近的,所以在保存一个像素时不需要将这个像素的全部信息保存,只需要保存这个像素与其参考像素的插值即可。
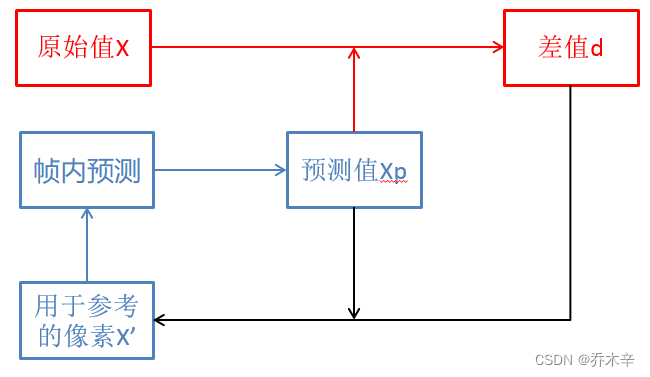
使用上一个像素X’做参考像素,经过帧内预测获得当前像素X的预测像素Xp,X减去Xp就获得了差值d。
在解码的时候,同样利用X’获得预测像素Xp,Xp加上插值d,就可以获取原始值X。
同时这个X可以作为下一个像素的X’从而成为一个完整的循环。
当然在H264中,因为以像素为单位太小,所以以宏块为单位(16*16像素、4*4像素)进行计算。
上述遗漏的问题,预测值Xp怎么来的?Xp是通过X’利用某个公式计算的。在白皮书中 4*4 有9种预测模式,16*16有4种预测模式。
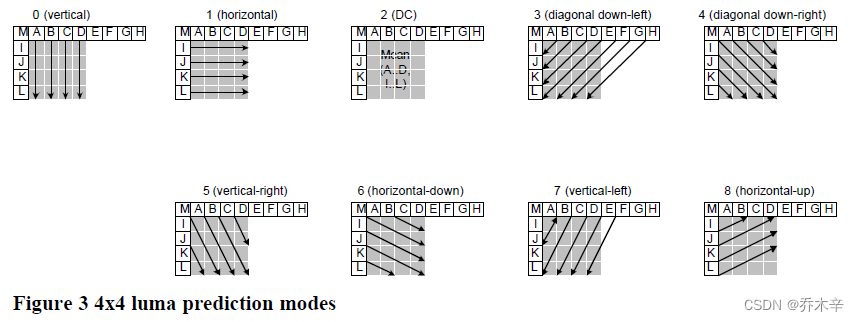
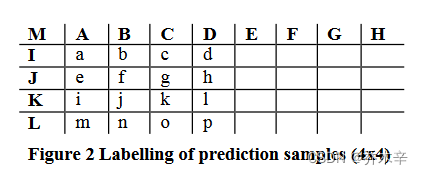
如何在这9种算法种选择,当然是希望误差越小越好,所以也有对应的算法去计算误差。例如:SAD,SATD等。
同时因为选择了不同的算法,所以解码器也需要知道每个宏块具体使用哪种算法。所以有1bit用于保存是由与上一个一样,如果不一样则用4bit保存具体选择哪个算法。
X’真的与原始X完全一样么?
理论上上讲按前面的算法应该是一样的,但因为差值传到解码器的过程种经过了量化、变换、反变换和反量化,有了精度算是,因此X’真的与原始X无法完全一致。
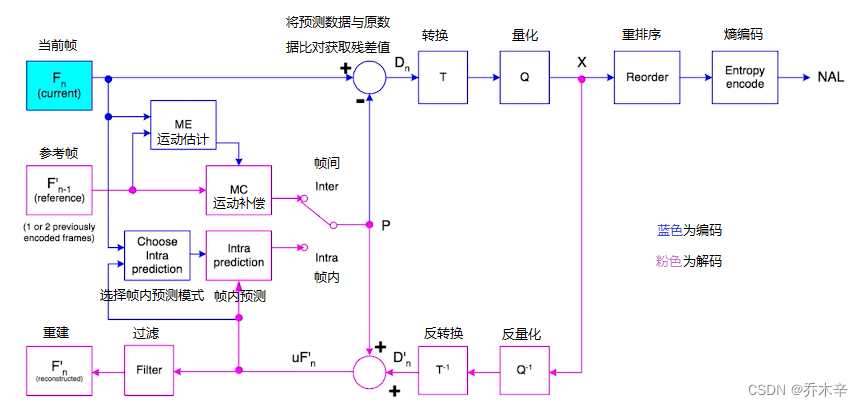
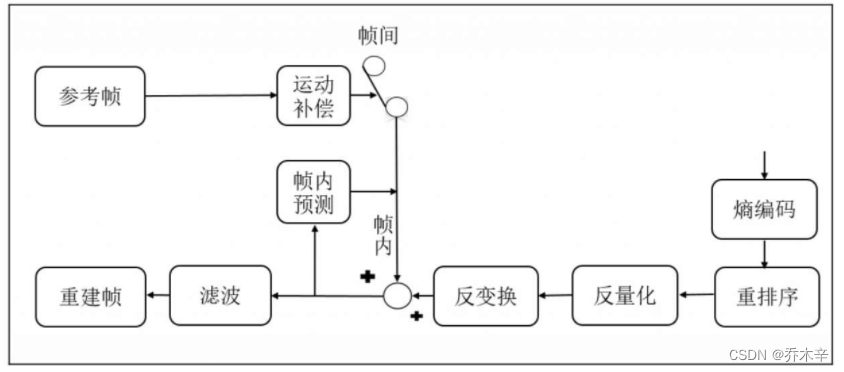
H264的主要目标是为了有高视频压缩比和良好的网络亲和性。
为了这两个目的H264将系统架构划分了两个层面 VCL 和 NAL。
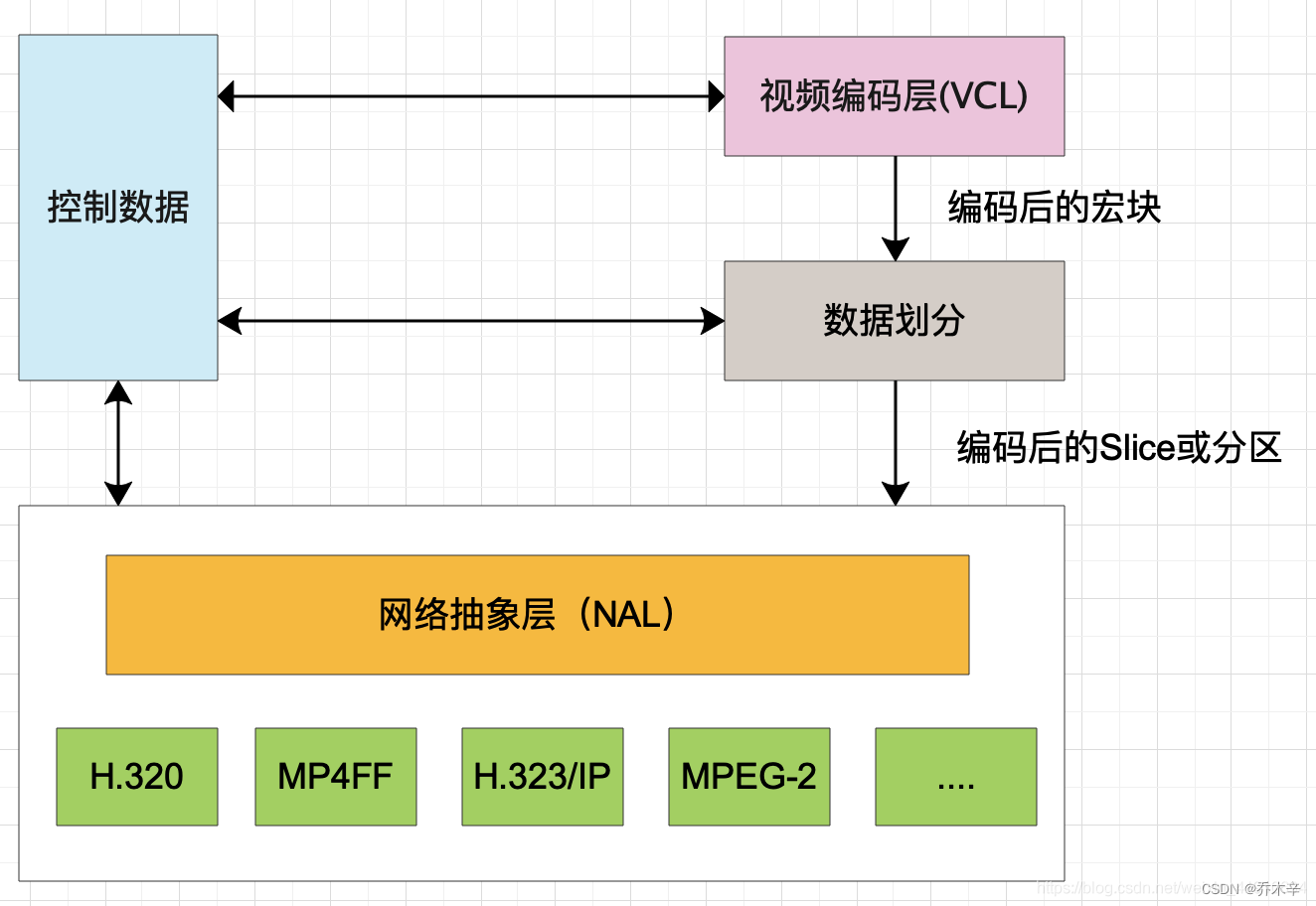
对核心算法引擎、块、宏块及片的语法级别的定义,负责有效表示视频数据的内容,最终输出编码完的数据SODB(数据比特串)
定义了片级以上的语法级别(如序列参数集和图像参数集),负责以网络所要求的恰当方式去格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。
『NAL』就是为了包装『VCL』以达到更好网络传输效果。NAL层将 SODB 打包成 RBSP(原始字节序列负荷) 然后加上NAL header 组成一个NALU。
RBSP(Raw Byte Sequence Payload,原始字节序列载荷):
PBSP就是在SODB后添加了trailing bits,即一个bit 1和若干个bit 0,以便字节对齐。
传统的视频码流仅有VCL视频编码层,而H264可以根据不同应用增加不同的NAL header,用来适应不同的网络应用环境,减少码流的传输错误。VCL数据在传输前先被映射到NAL单元中。
EBSP:(Encapsulated Byte Sequence Payload, 扩展字节序列载荷)
H264规定,当检测到当检测到0x000000时,也可以表示当前NALU的结束。
那这样就会产生一个问题,就是如果在NALU的内部,出现了0x000001或0x000000时该怎么办?
在编码时,每遇到两个字节连续为0(0x0000),就插入一个字节的0x03。解码时将0x03去掉。

ps:H264有两种封装:⼀种是annexb模式,传统模式,有startcode。⼀种是mp4模式,⼀般mp4,mkv都是mp4模式,没有startcode,SPS和PPS以及其它信息被封装在container中,每⼀个frame前⾯4个字节是这个frame的⻓度很多解码器只⽀持annexb这种模式。
H264码流是一个个连续的NALU,一个NALU包含 [NALU Header][NALU Payload (RBSP)] 三部分。
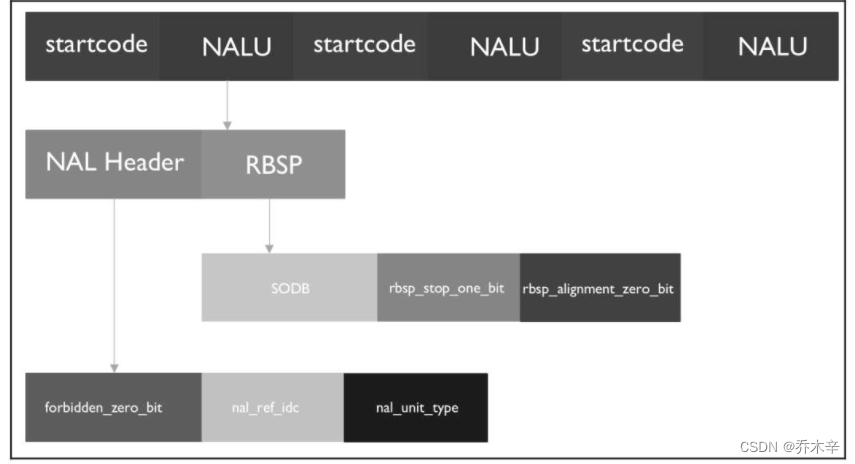
主要是为了将相邻两个NALU划分开,让他们有一个界线,方便解码。必须是 0x00 00 00 01 或者0x00 00 01。
那么玩意数据中间正好有个 0x00 00 00 01 或者 0x00 00 01 怎么办?见上述EBSP。
并且h264有个防止竞争的机制,在编码一个NAL时,如果出现有连续两个0x00字节,就在连续两个0x00后面插入一个0x03(解码的时候这个0x03会被丢弃)。

由 1字节(8位)组成。禁止位(1位)、重要性指示位(2位)、NALU类型(5位)。
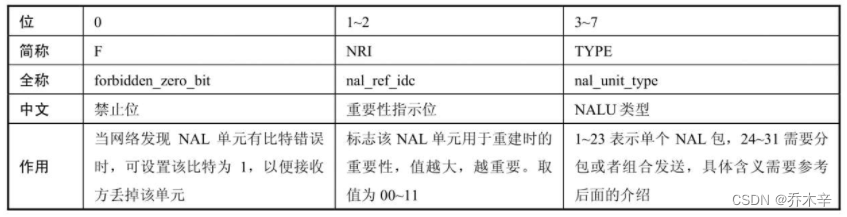
nal_unit_type取值说明:
SPS 和 PPS
https://zhuanlan.zhihu.com/p/27896239
从上图可知SPS和PPS是一个NALU的类型。
实际网络传输编码好的数据流的时候会出现丢包,而如果丢包数据为图像头等关键信息的时候甚至会导致后续解码失败。在H264之前,为了应对图像头关键信息被丢失的做法是在很多包(也有说法是每一个包)都会携带图像头关键信息(冗余做灾备的思想)。但是,在H264种,为了提高网络传输鲁棒性,重新设计出SPS和PPS。
SPS(序列参数集):SPS中保存了一组编码视频序列(Coded Video Sequence)的全局参数。因此该类型保存的是和编码序列相关的参数。
https://yinwenjie.blog.csdn.net/article/details/52771030
PPS(图像参数集):PPS中保存了整体图像相关的参数。
https://yinwenjie.blog.csdn.net/article/details/52877689
根据Vega分析,IDR帧中就包含了SPS,PPS和IDR本身的NALU。
SEI:补充增强信息
Access Unit分隔符:Access Unit:是一个或者多个 NALU 的集合,代表了一个完整的帧。

通过 Vega 分析,不同的 H264 文件有不用的 Profile 和 level。
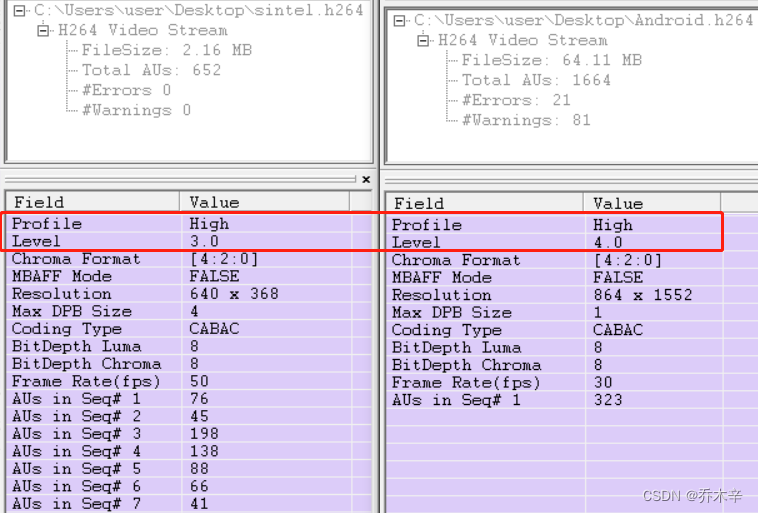
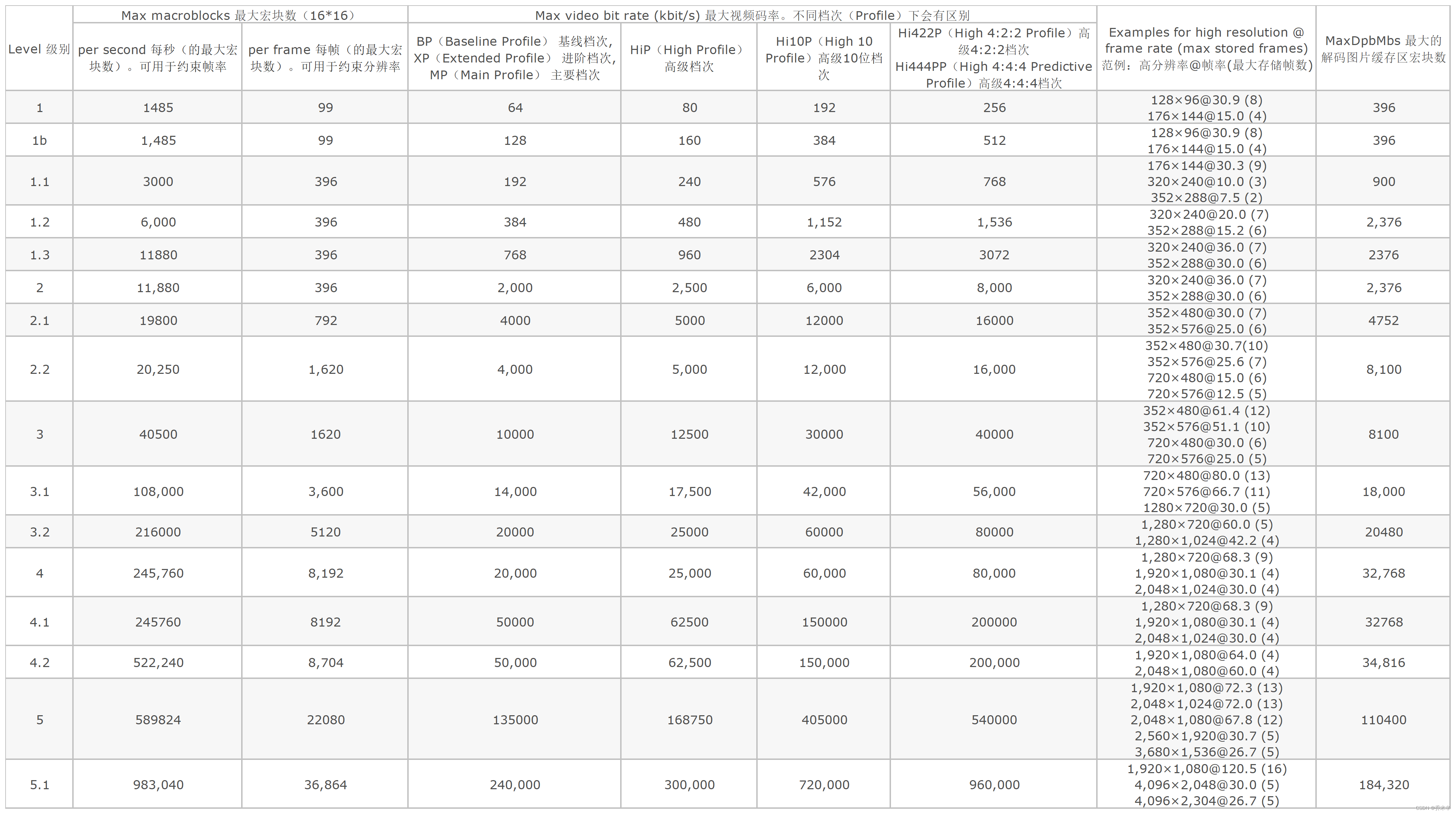
计算支持1080P(1920*1080)的最低级别:
一个宏块大小16*16.。ceil是向上取整
水平宏块数(PicWidthInMbs)= ceil(视频宽度 / 16) = ceil(1080 / 16) = ceil(67.5) = 68
垂直宏块数(FrameHeightInMbs)= ceil(视频宽度 / 16) = ceil(1920 / 16) = ceil(120) = 120
每帧宏块数(Macroblocks per frame)= 水平宏块数 * 垂直宏块数 = 68 * 120 = 8160
查询上面的级别详表可知,支持每帧8160个宏块的最低级别是4。
级别4 允许的每秒最大宏块数是 245,760 。所以 245760 / 8160 =30.1,即最高支持每秒30.1帧。当然级别更高支持的帧数也更多。
MaxDpbMbs
表中最后一列为 MaxDpbMbs 最大解码缓冲区宏块数。也就是解码时参考缓冲区中的宏块数。
DpbMbs = ref(参考帧数) * PicWidthInMbs(水平宏块数) * FrameHeightInMbs(垂直宏块数)
我们可以根据 MaxDpbMbs 倒推出 最大参考帧数。
公式为:max_ref = min(floor(MaxDpbMbs / (PicWidthInMbs * FrameHeightInMbs)), 16)。floor是向下取整。
以1080P + Level 4 为例:
min(floor(32,768 / (68*120)),16) = 4 注:后面的16 是因为 参考帧数组大只能为16
所以1080P的视频在 Level 4 级别下,最高支持 4 个参考帧。
反推可知,在解码时参考帧的帧数并不只是前1帧,而是前多帧。同理编码时当前帧的参考帧也不只是前一帧,而是前多帧。
这也就应证了I帧和IDR帧的区别。虽然应证了,但还是存在疑问,既然I帧已经可以独立编码解码了,那么为什么在编码解码的时候还要参考I帧之前的帧?
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图