上一篇博客给大家介绍了使用opencv加载YOLOv5的onnx模型,但我们发现使用CPU进行推理检测确实有些慢,那难道在CPU上就不能愉快地进行物体识别了吗?当然可以啦,这不LabVIEW和OpenVINO就来了嘛!今天就和大家一起看一下如何在CPU上也能感受丝滑的实时物体识别。
OpenVINO是英特尔针对自家硬件平台开发的一套深度学习工具库,用于快速部署应用和解决方案,包含推断库,模型优化等等一系列与深度学习模型部署相关的功能。
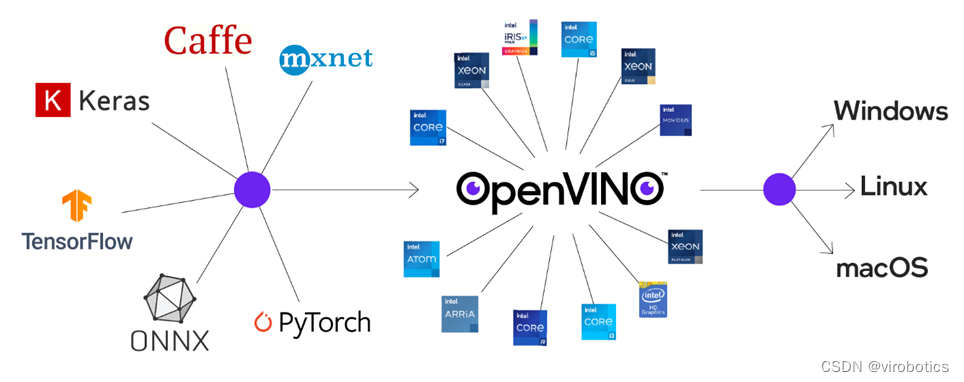
特点:
在边缘启用基于CNN的深度学习推理
支持通过英特尔®Movidius™VPU在英特尔®CPU,英特尔®集成显卡,英特尔®神经计算棒2和英特尔®视觉加速器设计之间进行异构执行
通过易于使用的计算机视觉功能库和预先优化的内核加快上市时间
包括对计算机视觉标准(包括OpenCV *和OpenCL™)的优化调用
通俗易懂点说想要在intel-cpu或者嵌入式上部署深度学习模型,可以考虑考虑openvino
可在如下链接中下载并安装工具包:https://www.cnblogs.com/virobotics/p/16527821.html
下载地址:
2)选择版本,选择如下版本,并DownLoad:
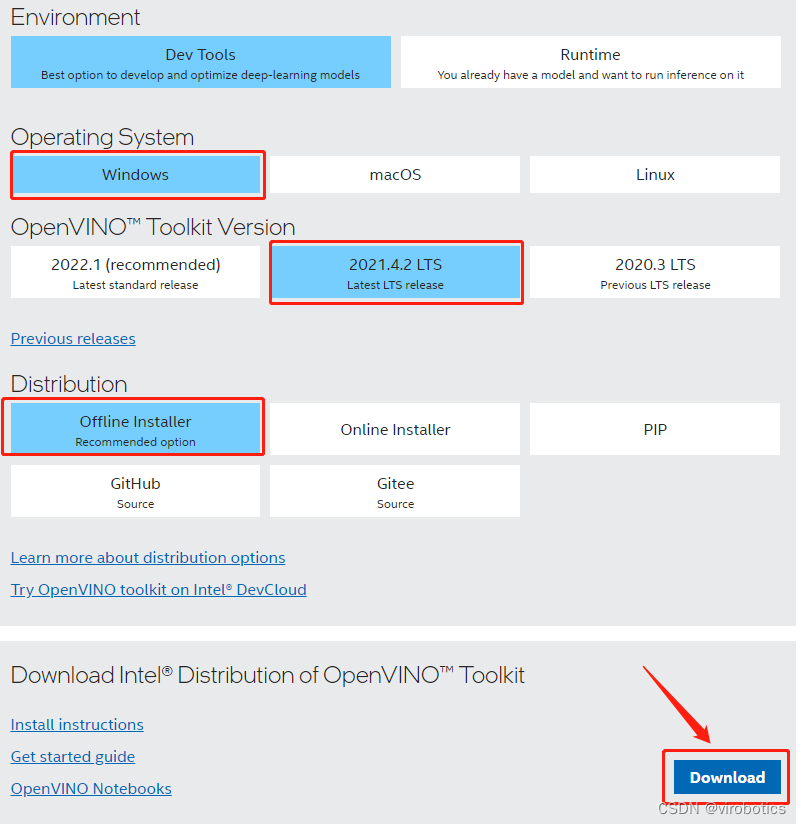
3)下载后,运行安装即可!
4)可以选择安装路径,具体安装可以参考官方文档:
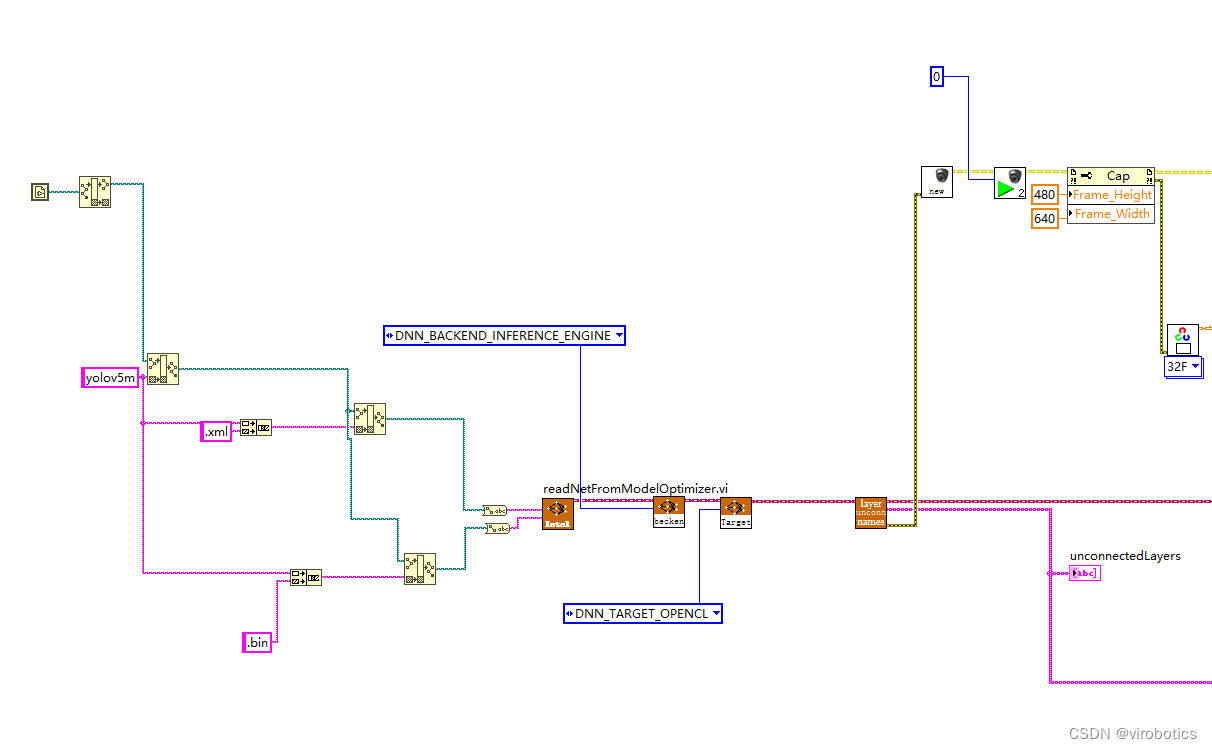
openvino工作流程,和其他的部署工具都差不多,训练好模型,解析成openvino专用的.xml和.bin,随后传入Inference Engine中进行推理。这里和上一篇博客一样可以使用export.py导出openvino模型:python export.py --weights yolov5s.pt --include openvino 当然这里已经为大家转换好了模型,大家可以直接下载,下载链接:
dnn模块调用IR模型(模型优化器)
设置计算后台与计算目标设备(推理引擎加速)
获取输出端的LayerName
图像预处理
推理
后处理
绘制检测出的对象
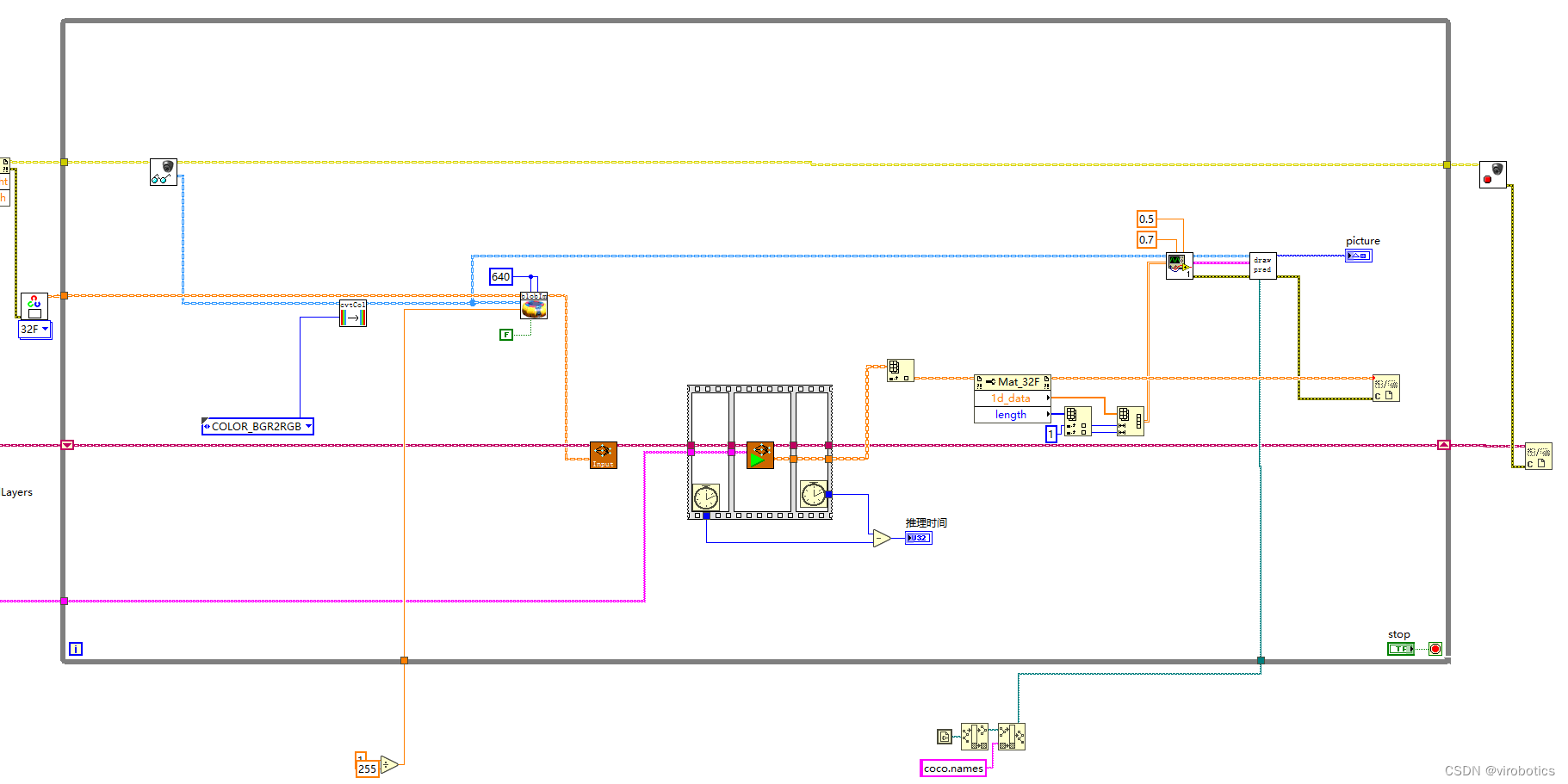
CPU模式下,使用openvino进行推理加速,实时检测推理用时仅95ms/frame,是之前加载速度的三分之一 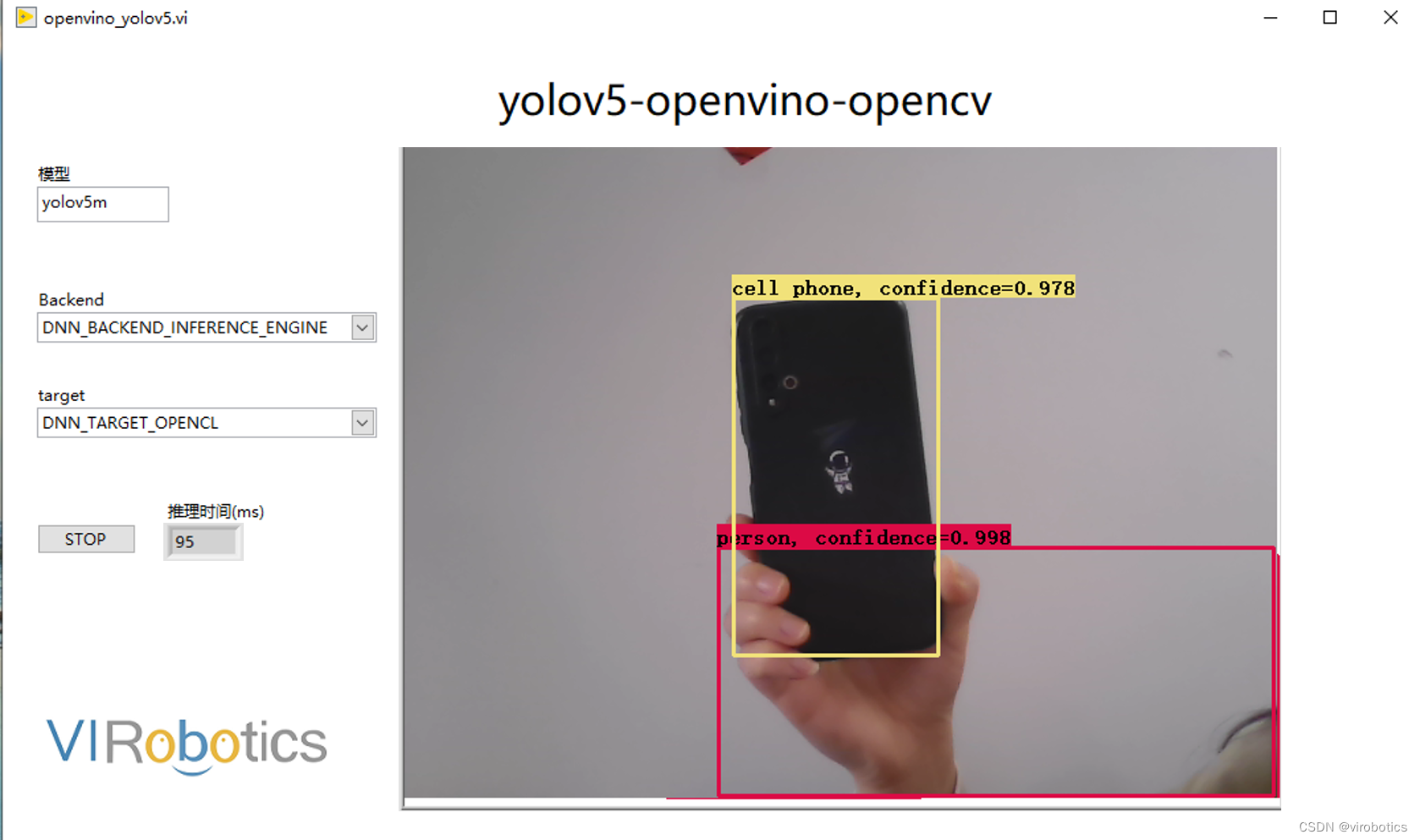
注意:readNetFromModelOptimizer.vi中IR模型路径不可以包含中文
操作系统:Windows10
python:3.6及以上
LabVIEW:2018及以上 64位版本
视觉工具包:techforce_lib_opencv_cpu-1.0.0.73.vip
OpenVINO:2021.4.2
以上就是今天要给大家分享的内容。
如需源码,请关注微信公众号VIRobotics,回复关键词:yolov5_openvino。
我有以下字符串:a="001;Barbara;122"我拆分成字符串数组:names=a.split(";")names=["001","Barbara","122"]我应该怎么做才能将每个元素另外用''引号括起来?结果应该是names=["'001'","'Barbara'","'122'"]我知道这听起来很奇怪,但我需要它在rubyonrails中进行数据库查询。出于某种原因,如果我的名字在“”引号中,我将无法访问数据库记录。我在数据库中确实有mk1==0006但rails不想以某种方式访问它。但是,它确实访问1222。sql="SELECTmk1,mk2,pk1,pk
我的Rails应用程序在暂存服务器上运行速度非常慢,这让我遇到了一些麻烦。最令人困惑的是每个请求的日志输出的最后一行。看起来View和数据库时间甚至不接近整个渲染时间。在一页上,完成时间大约1000毫秒,View大约450毫秒,数据库大约20毫秒。渲染页面所需的其余时间从何而来? 最佳答案 当事情变得神秘时......分析器是你的friend!分析器将统计哪些方法被调用最多以及每个方法调用花费多长时间。ruby-prof当我在RubyLand时,它会帮我解决这个问题,它会生成一个漂亮的调用图(如果需要,可以是html格式),这使得查
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用
很多初学者的代码其实都不够“漂亮”,那是因为没有养成好的编码习惯。本篇博客以C语言为例,总结一些好习惯。其实,很多习惯都是肌肉记忆,举个例子:请你写一个程序,输入2个整数并输出它们的和。有些朋友可能写出来是这个样子。#includeintmain(){ inta=0; intb=0; intsum=0; scanf("%d%d",&a,&b); sum=a+b; printf("%d\n",sum); return0;}我写这段代码,是在模仿有些朋友在初学的时候容易写成的样子。更有甚者,写成这个样子:#includeintmain(){inta=0;intb=0;intsum=0;scanf(
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
假设我希望Ruby进程使用的CPU不超过15%。是否可以?怎么办? 最佳答案 您可以尝试使用Process.setrlimit来自标准核心:Setstheresourcelimitoftheprocess.这看起来只是setrlimit的包装器来自C库,因此它可能仅在Unix-ish平台上可用。setrlimit不支持CPU百分比限制,但它支持以秒为单位限制CPU时间。如果您只是想让您的Ruby进程不占用整个CPU,那么您可以尝试使用Process.setpriority来调整它的优先级。这只是libc的setpriority的包装
条件:a+b+c=100a,b,cpositiveintegersor0期望的输出:[[0,0,100],[0,1,99],...#allotherpermutations[99,1,0],[100,0,0]] 最佳答案 我会写:(0..100).flat_map{|x|(0..100-x).map{|y|[x,y,100-x-y]}}#=>[[0,0,100],[0,1,99]],...,[99,1,0],[100,0,0]]站点注释1:这是一个经典示例,其中列表推导式大放异彩(如果某处有条件则更是如此)。由于Ruby没有LC,我
✅作者简介:大家好,我是小杨📃个人主页:「小杨」的csdn博客🔥系列专栏:小杨带你玩转C语言【初阶】🐳希望大家多多支持🥰一起进步呀!大家好呀!我是小杨。小杨花几天的时间将C语言中的操作符这部分知识做了一个大总结,在方便自己复习的同时也能够帮助到大家。通篇字数在一万字左右,可以算作是非常详细了,一文就可以带领大家彻底掌握操作符这部分内容,文章很长建议先收藏再看,防止下次想看就找不到啦。文章目录✍1,算术操作符✍2,移位操作符 🔍2.1,左移操作符 🔍2.2,右移操作符 ✨2.2.1,算术移位 ✨2.2.2,逻辑移位✍3,位操作符 🔍3.1,按位与&
所以这很奇怪。我在Ruby1.9.3中,float加法没有像我预期的那样工作。0.3+0.6+0.1=0.99999999999999990.6+0.1+0.3=1我在另一台机器上试过了,得到了同样的结果。知道为什么会发生这种情况吗? 最佳答案 浮点运算是不精确的:它们将结果四舍五入到最接近的可表示浮点值。这意味着每个float操作是:float(aopb)=mathematical(aopb)+rounding-error(aopb)如上式所示,舍入误差取决于操作数a和b。因此,如果您以不同的顺序执行操作,float(float(
我们正在使用Unicorn_Rails+nginx。它在我的系统(4GBRam,Intel(R)Core(TM)2DuoCPUP8600@2.40GHz)的开发模式和生产模式下运行良好我能够在本地系统中启动10个worker,但在任何情况下都无法在生产中启动超过2个有时它可以工作,但需要等待15-20米启动unicorn_rails时一直占用99.6%的CPU英特尔(R)至强(R)CPUE5507@2.27GHz但它卡在亚马逊(m1.small实例)1.73GB内存我发现没有人在任何地方谈论使用unicorn_rails启动缓慢...... 最佳答案