无人机在拍摄视频时,由于风向等影响因素,不可避免会出现位移和旋转,导致拍摄出的画面存在平移和旋转的帧间变换, 即“抖动” 抖动会改变目标物体 (车辆、行人) 的坐标,给后续的检测、跟踪任务引入额外误差,造成数据集不可用。


理想的无抖动视频中,对应于真实世界同一位置的背景点在不同帧中的坐标应保持一致,从而使车辆、行人等目标物体的坐标变化只由物体本身的运动导致,而不包含相机的运动 抖动可以由不同帧中对应背景点的坐标变换来描述
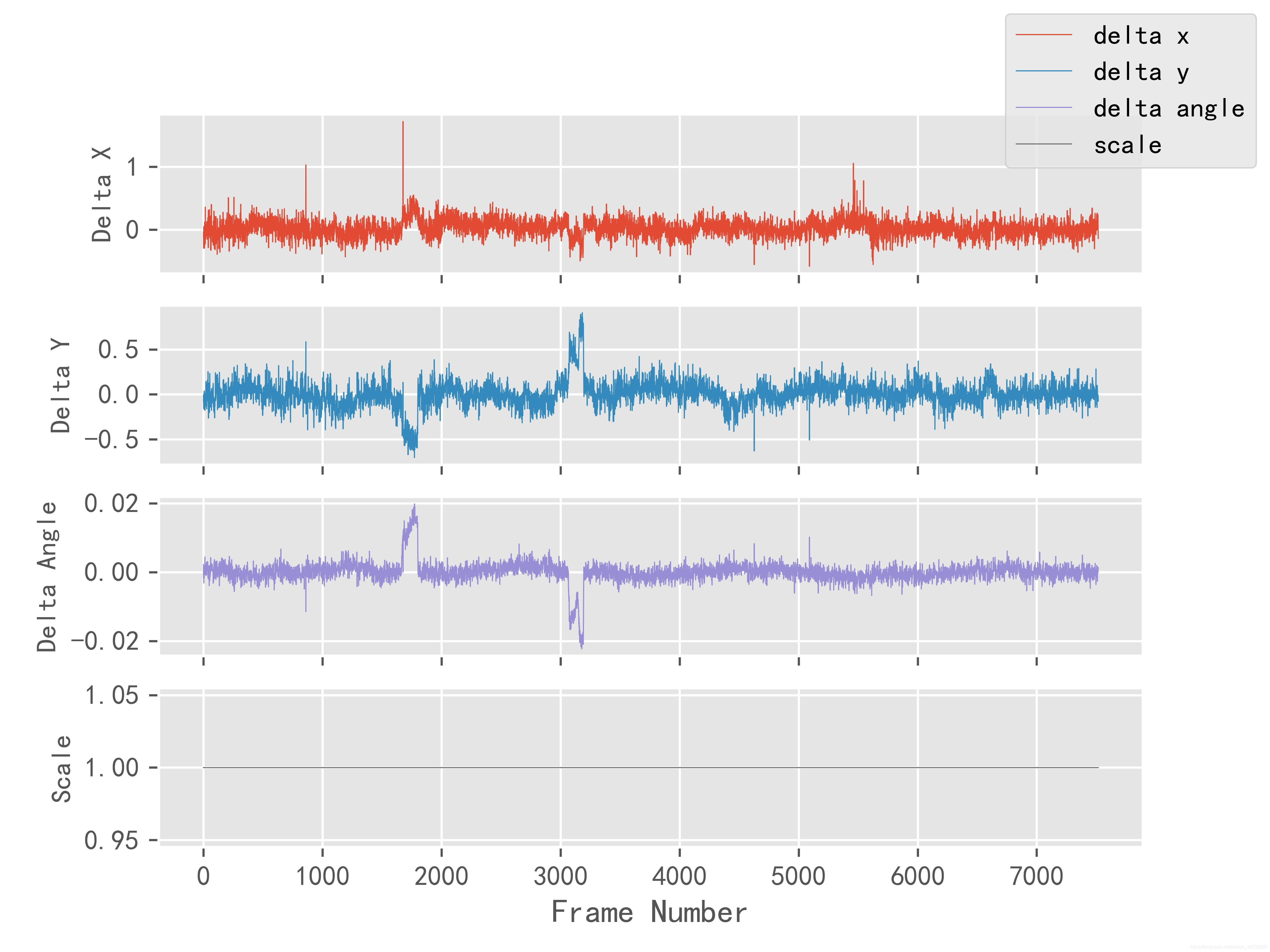
抖动可以用相邻帧之间的 x 方向平移像素 dx,y 方向平移像素 dy,旋转角度 da,缩放比例 s 来描述,分别绘制出 4 个折线图,根据折线图的走势可以判断抖动的程度 理想的无抖动视频中,dx、dy、da 几乎始终为 0,s 几乎始终为 1。
我们最终实现,将视频的所有帧都对齐到第一帧,以达到视频消抖问题,实现逻辑如下图所示。
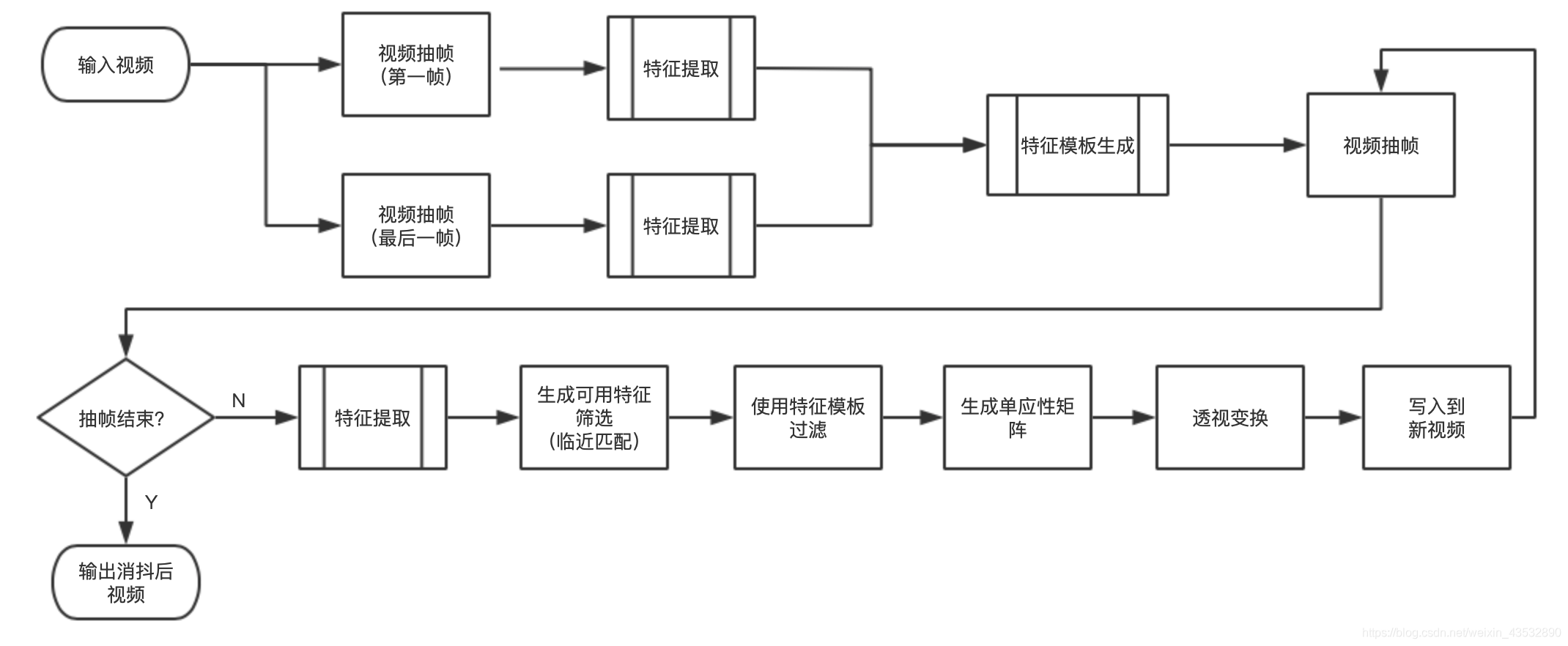
(1)首先对视频进行抽第一帧与最后一帧,为什么抽取两帧?这样做的主要目的是,我们在做帧对齐时,使用帧中静态物的关键点做对齐,如果特征点来源于动态物上,那么对齐后就会产生形变,我们选取第一帧与最后一帧,提取特征点,留下交集部分,则可以得到静态特征点我们这里称为特征模板,然后将特征模板应用到每一帧上,这样可以做有效对齐。
(2)常用特征点检测器:
SIFT: 04 年提出,广泛应用于各种跟踪和识别算法,表现能力强,但计算复杂度高。
SURF: 06 年提出,是 SIFT 的演进版本,保持强表现能力的同时大大减少了计算量。
BRISK: BRIEF 的演进版本,压缩了特征的表示,提高了匹配速度。 ORB: 以速度著称,是 SURF 的演进版本,多用于实时应用。
GFTT: 最早提出的 Harris 角点的改进版本,经常合称为 Harris-Shi-Tomasi 角点。
SimpleBlob: 使用 blob 的概念来抽取图像中的特征点,相对于角点的一种创新。 FAST: 相比其他方法特征点数量最多,但也容易得到距离过近的点,需要经过 NMS。
Star: 最初用于视觉测距,后来也成为一种通用的特征点检测方法。
我们这里使用的是SURF特征点检测器


(3)在上图中,我们发现所提取的特征点中部分来自于车身,由于车是运动的,所以我们不能使用,我们用第一帧与最后一帧做静态特帧点匹配,生成静态特征模板,在下图中,我们发现只有所有的特征点只选取在静态物上

(4)静态特征模板匹配 ,我们这里使用Flann算法,匹配结果如下

(5)使用匹配成功的两组特征点,估计两帧之间的透视变换 (Perspective Transformation)。估计矩阵 H,其中 (x_i, y_i) 和 (x_i^′, y_i^′) 分别是两帧的特征点。
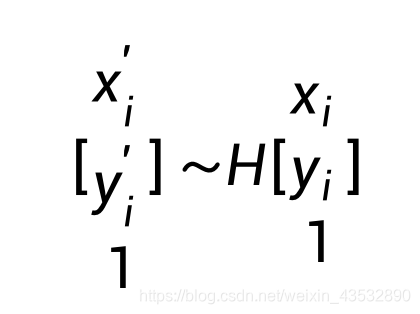


运行环境以及版本,安装命令如下:
python版本:3.X
opencv-python:3.4.2.16
opencv-contrib-python:3.4.2.16
需要卸载之前的opencv-python版本
pip uninstall opencv-python
pip uninstall opencv-contrib-python
安装新的版本
pip install opencv_python==3.4.2.16
pip install opencv-contrib-python==3.4.2.16代码基于python实现,如下所示:
import cv2
import numpy as np
from tqdm import tqdm
import argparse
import os
# get param
parser = argparse.ArgumentParser(description='')
parser.add_argument('-v', type=str, default='') # 指定输入视频路径位置(参数必选)
parser.add_argument('-o', type=str, default='') # 指定输出视频路径位置(参数必选)
parser.add_argument('-n', type=int, default=-1) # 指定处理的帧数(参数可选), 不设置使用视频实际帧
# eg: python3 stable.py -v=video/01.mp4 -o=video/01_stable.mp4 -n=100 -p=6
args = parser.parse_args()
input_path = args.v
output_path = args.o
number = args.n
class Stable:
# 处理视频文件路径
__input_path = None
__output_path = None
__number = number
# surf 特征提取
__surf = {
# surf算法
'surf': None,
# 提取的特征点
'kp': None,
# 描述符
'des': None,
# 过滤后的特征模板
'template_kp': None
}
# capture
__capture = {
# 捕捉器
'cap': None,
# 视频大小
'size': None,
# 视频总帧
'frame_count': None,
# 视频帧率
'fps': None,
# 视频
'video': None,
}
# 配置
__config = {
# 要保留的最佳特征的数量
'key_point_count': 5000,
# Flann特征匹配
'index_params': dict(algorithm=0, trees=5),
'search_params': dict(checks=50),
'ratio': 0.5,
}
# 特征提取列表
__surf_list = []
def __init__(self):
pass
# 初始化capture
def __init_capture(self):
self.__capture['cap'] = cv2.VideoCapture(self.__video_path)
self.__capture['size'] = (int(self.__capture['cap'].get(cv2.CAP_PROP_FRAME_WIDTH)),
int(self.__capture['cap'].get(cv2.CAP_PROP_FRAME_HEIGHT)))
self.__capture['fps'] = self.__capture['cap'].get(cv2.CAP_PROP_FPS)
self.__capture['video'] = cv2.VideoWriter(self.__output_path, cv2.VideoWriter_fourcc(*"mp4v"),
self.__capture['fps'], self.__capture['size'])
self.__capture['frame_count'] = int(self.__capture['cap'].get(cv2.CAP_PROP_FRAME_COUNT))
if number == -1:
self.__number = self.__capture['frame_count']
else:
self.__number = min(self.__number, self.__capture['frame_count'])
# 初始化surf
def __init_surf(self):
self.__capture['cap'].set(cv2.CAP_PROP_POS_FRAMES, 0)
state, first_frame = self.__capture['cap'].read()
self.__capture['cap'].set(cv2.CAP_PROP_POS_FRAMES, self.__capture['frame_count'] - 1)
state, last_frame = self.__capture['cap'].read()
self.__surf['surf'] = cv2.xfeatures2d.SURF_create(self.__config['key_point_count'])
self.__surf['kp'], self.__surf['des'] = self.__surf['surf'].detectAndCompute(first_frame, None)
kp, des = self.__surf['surf'].detectAndCompute(last_frame, None)
# 快速临近匹配
flann = cv2.FlannBasedMatcher(self.__config['index_params'], self.__config['search_params'])
matches = flann.knnMatch(self.__surf['des'], des, k=2)
good_match = []
for m, n in matches:
if m.distance < self.__config['ratio'] * n.distance:
good_match.append(m)
self.__surf['template_kp'] = []
for f in good_match:
self.__surf['template_kp'].append(self.__surf['kp'][f.queryIdx])
# 释放
def __release(self):
self.__capture['video'].release()
self.__capture['cap'].release()
# 处理
def __process(self):
current_frame = 1
self.__capture['cap'].set(cv2.CAP_PROP_POS_FRAMES, 0)
process_bar = tqdm(self.__number, position=current_frame)
while current_frame <= self.__number:
# 抽帧
success, frame = self.__capture['cap'].read()
if not success: return
# 计算
frame = self.detect_compute(frame)
# 写帧
self.__capture['video'].write(frame)
current_frame += 1
process_bar.update(1)
# 视频稳像
def stable(self, input_path, output_path, number):
self.__video_path = input_path
self.__output_path = output_path
self.__number = number
self.__init_capture()
self.__init_surf()
self.__process()
self.__release()
# 特征点提取
def detect_compute(self, frame):
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 计算特征点
kp, des = self.__surf['surf'].detectAndCompute(frame_gray, None)
# 快速临近匹配
flann = cv2.FlannBasedMatcher(self.__config['index_params'], self.__config['search_params'])
matches = flann.knnMatch(self.__surf['des'], des, k=2)
# 计算单应性矩阵
good_match = []
for m, n in matches:
if m.distance < self.__config['ratio'] * n.distance:
good_match.append(m)
# 特征模版过滤
p1, p2 = [], []
for f in good_match:
if self.__surf['kp'][f.queryIdx] in self.__surf['template_kp']:
p1.append(self.__surf['kp'][f.queryIdx].pt)
p2.append(kp[f.trainIdx].pt)
# 单应性矩阵
H, _ = cv2.findHomography(np.float32(p2), np.float32(p1), cv2.RHO)
# 透视变换
output_frame = cv2.warpPerspective(frame, H, self.__capture['size'], borderMode=cv2.BORDER_REPLICATE)
return output_frame
if __name__ == '__main__':
if not os.path.exists(input_path):
print(f'[ERROR] File "{input_path}" not found')
exit(0)
else:
print(f'[INFO] Video "{input_path}" stable begin')
s = Stable()
s.stable(input_path, output_path, number)
print('[INFO] Done.')
exit(0)
参数说明:
-v 指定输入视频路径位置(参数必选)
-o 指定输出视频路径位置(参数必选)
-n 指定处理的帧数(参数可选), 不设置使用视频实际帧
调用示例:
python3 stable.py -v=test.mp4 -o=test_stable.mp4
我们消抖后的视频道路完全没有晃动,但是在边界有马赛克一样的东西,那是因为图片对齐后后出现黑边,我们采用边缘点重复来弥补黑边。
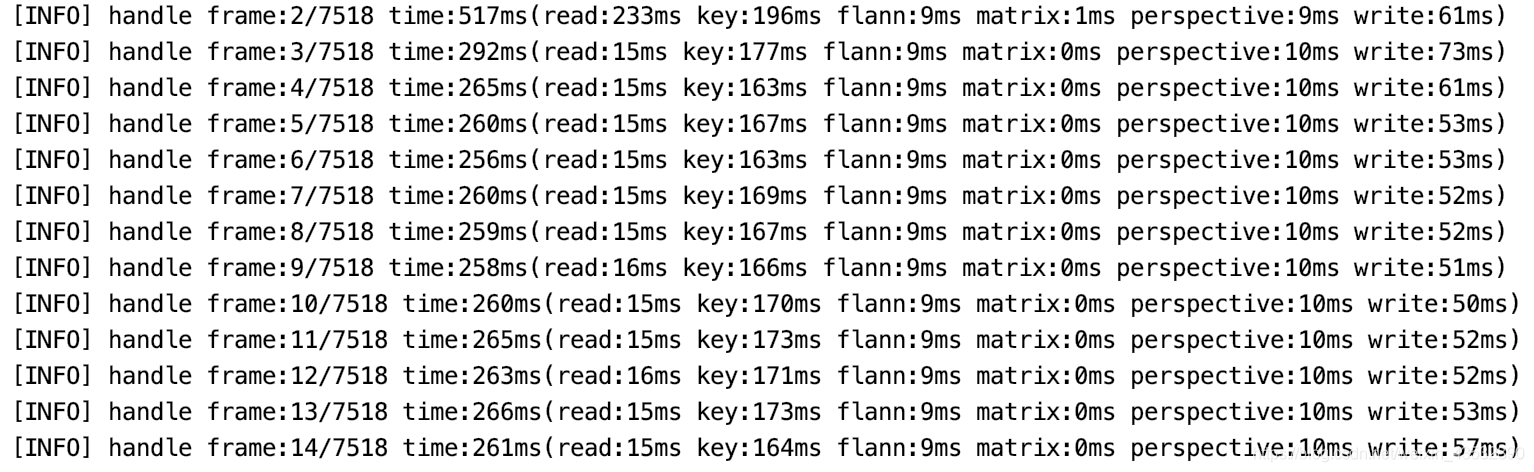
目前的处理效率(原视频尺寸3840*2160),我们可以看出主要时间是花费在特征点(key)提取上。
可以采用异步处理+GPU提高计算效率
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
我对图像处理完全陌生。我对JPEG内部是什么以及它是如何工作一无所知。我想知道,是否可以在某处找到执行以下简单操作的ruby代码:打开jpeg文件。遍历每个像素并将其颜色设置为fx绿色。将结果写入另一个文件。我对如何使用ruby-vips库实现这一点特别感兴趣https://github.com/ender672/ruby-vips我的目标-学习如何使用ruby-vips执行基本的图像处理操作(Gamma校正、亮度、色调……)任何指向比“helloworld”更复杂的工作示例的链接——比如ruby-vips的github页面上的链接,我们将不胜感激!如果有ruby-
我有一个super简单的脚本,它几乎包含了FayeWebSocketGitHub页面上用于处理关闭连接的内容:ws=Faye::WebSocket::Client.new(url,nil,:headers=>headers)ws.on:opendo|event|p[:open]#sendpingcommand#sendtestcommand#ws.send({command:'test'}.to_json)endws.on:messagedo|event|#hereistheentrypointfordatacomingfromtheserver.pJSON.parse(event.d