在本文中,我们将介绍 GraphScope 图交互式查询引擎 GAIA-IR,它支持高效的 Gremlin 语言表达的交互图查询,同时高度抽象了图上的查询计算,具有高可扩展性。
在海量数据的分析中,图查询是一种重要的工具。Gremlin[1] 是由 Apache Tinkerpop 提出并维护的工业界标准的图查询语言,被业界流行图数据库广泛应用,例如 Neo4j[2] 、OrientDB[3]、JanusGraph[4]、Microsoft Cosmos DB[5] 以及 Amazon Neptune[6]。而 GraphScope 中的图查询引擎 GAIA 则是业界首个开源的支持大规模分布式并行化 Gremlin 的系统。然而,尽管 Gremlin 语言的灵活性是它显著的优势,在 GAIA 系统的设计和使用中,我们也发现了一些存在的问题。
GAIA 查询系统主要有如下几点弊病:
D1: Gremlin 算子数量繁多,并且对同种语义有多种表达。这就导致为了支持丰富的 Gremlin 算子,GAIA 中需要端到端在各个模块中添加对应的算子,并且算子实现之间可能存在冗余的计算逻辑。例如,当我们有查看属性的需求时,Gremlin 中可以通过elementMap()、 valueMap()、values()、 select().valueMap()、 project().valueMap()等表达方式得到类似的结果,示例如下:
gremlin> g.V().elementMap()
==>[id:1,label:person,name:marko,age:29]
==>[id:2,label:person,name:vadas,age:27]
gremlin> g.V().valueMap('name','age')
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
gremlin> g.V().as('a').select('a').by(valueMap('name', 'age'))
==>[name:[marko], age:[29]]
==>[name:[vadas], age:[27]]
gremlin> g.V().as('a').project('a').by(valueMap('name', 'age'))
==>[a:[name:[marko], age:[29]]]
==>[a:[name:[vadas], age:[27]]]
而为了支持这些类似的表达,GAIA 中需要定义多个冗余算子,并且需要在各个模块中支持,对开发并不友好,可扩展性较差。
D2: GAIA 的语言扩展性差。GAIA 是 Gremlin 并行化查询的定制化实现,而现如今也有很多其他常用的图查询语言,例如 Cypher、GSQL 等。如果未来我们需要进一步接入更多的查询语言,则几乎无法通过扩展 GAIA 来实现。
D3:: Gremlin 对复杂的 expression 支持不佳。例如,我们想通过以下 Gremlin 查询语句,找到 "a" 的两度邻居中,满足一定 "age" 属性条件的人:
g.V().as("a").out().as("b").out().as("c")
.where("c", P.lt("a").or(P.gt("a").and(P.gt("b")))).by("age")
像where() 中这样复杂的嵌套条件过滤并不直观,对用户使用来说不太友好。
D4: GAIA 中没有很好的 Gremlin 语法规范定义,也很难界定当前系统对 Gremlin 算子及算子组合的支持范围,对用户来说并不友好。
为了解决以上的问题,我们进一步提出了与查询语言无关、普适性更强的中间表示层 GAIA-IR(简称 IR),用来描述通用的图查询语义。我们抽象出的操作算子可以分为两类:关系型操作算子及图相关操作算子。其中,关系型操作算子主要与传统关系型数据库上的操作保持一致,如 Projection、 Selection、 GroupBy、 OrderBy 等;而图相关操作算子则是图数据上的特有查询,如点查询、邻点(边)查询等等。通过这层查询语言无关的中间表示层,我们可以解决上述 GAIA 中存在的问题:
A1: GAIA-IR 层用统一中间表示来实现 Gremlin 算子中类似的表达。例如,我们抽象出 project 算子,用于统一表示上述 D1 中 Gremlin 各种取属性操作。
A2: GAIA-IR 层与查询语言无关,这就方便了 GAIA-IR 后续可以进一步接入更多的语言。将来,我们只需要将不同语言的操作算子翻译到 IR 的统一中间表示层,就可以自然地实现该语言的并行化查询,而不需要再针对每套语言去设计分布式并行化实现。
A3: GAIA-IR 还额外提供了丰富的 expression 支持,从而满足用户的需求。例如,对比 D3 中的例子,我们在 where() 算子中加入 expression 的表达支持会更加直观:
g.V().as("a").out().as("b").out().as("c")
.where(expr("@c.age < @a.age || (@c.age > @a.age && @c.age > @b.age)"))
A4: GAIA-IR 中引入了 Antlr 工具,支持 Gremlin 语法检查功能,并且明确了系统对 Gremlin 算子及组合的支持范围,对用户使用更为友好。
接下来,我们介绍 GAIA-IR 的整体设计。
首先,我们介绍 IR 中的一些基本概念。IR 抽象了图数据上的基本计算,从而提供了一套统一的、简洁的、语言无关的中间表示层。
操作算子(IR Operator):目前,我们将操作算子(Graph-Relational Algebra)抽象为两类,即关系型操作和图相关操作。
Projection、Selection、 Join、 Groupby、 Orderby、 Dedup、 Limit 等。这与传统关系型数据库上的操作保持一致。通过以上两类算子抽象,我们既可以表达传统的关系型运算,又可以支持图上特有的查询操作。同时,该抽象算子集合并不受查询语言的限制,由此可以很容易地拓展到其他语言。
数据结构(GRecord):我们定义了数据结构 GRecord,用来表示每个 IR Operator 的输入输出。GRecord 是一个多列的结构,每列有自己的别名(Alias)和值(Value):
As别名。特别的,为了适配 Gremlin,我们额外提供了一个 Unique Alias -- "HEAD",作为匿名别名,特指上一个算子的输出,即当前算子的输入。在 Gremlin 查询中,我们将其翻译成 GRecord 上的一系列 IR Operator 操作,从而支持 Gremlin 的查询语义。例如,在查询 g.V().as('a').select('a').by(valueMap('name', 'age')) 中,g.V().as('a') 会产生如下的中间结果,别名叫做 "a",数据类型为 Vertex 类型:
| R1 | Vertex { name:[marko], age:[29] }, Alias: "a" |
|---|---|
| GR2 | Vertex { name:[vadas], age:[27] }, Alias: "a" |
而我们会将 select('a').by(valueMap('name', 'age')) 翻译为 Project("{a.name,a.age}"),以上述的 GR1、GR2 作为 Project 的输入,我们可以得到输出 GR1'、GR2',即我们所需要的点属性:
| GR1' | CommonObject {a.name:[marko], a.age:[29] } |
|---|---|
| GR2' | CommonObject { a.name:[vadas], a.age:[27] } |
类似的,对于 Gremlin 查询 g.V().valueMap('name','age'),我们只需将 GR1、GR2 的 Alias 变为匿名的 "HEAD",并将 valueMap('name','age') 翻译为 Project("{HEAD.name,HEAD.age}"),便可以得到同样的结果。由此,我们就能够将同一语义、不同表达的 Gremlin 算子,翻译成统一的中间表示。更甚,对于其他语言,例如 SQL 中的取属性操作,我们也可以很直观的翻译成 IR 中的 Project 算子。由此可见,IR 是抽象出了一套更为简洁通用、且与查询语言无关的中间表示层。
接下来,我们给出 GAIA-IR 目前对 Gremlin 的并行化计算架构,如下图所示。
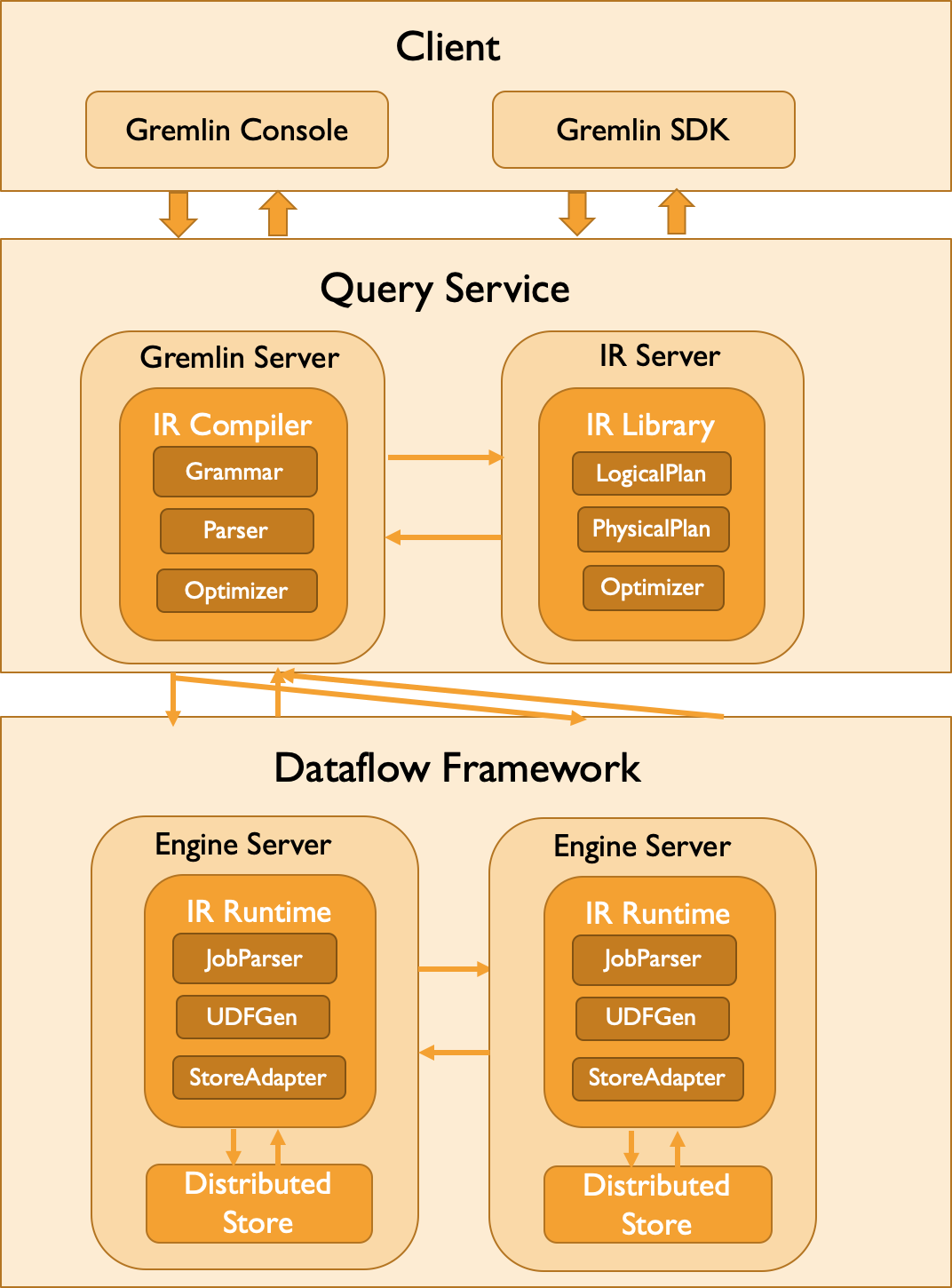
总体来说,我们兼容了官方的 Gremlin Console 以及 Gremlin SDK 的查询方式。在用户提交 Gremlin Query 后:
在介绍完 GAIA-IR 的整体设计后,我们介绍如何使用 GAIA-IR 引擎进行查询。
服务部署:在 GraphScope之前的文章中,我们介绍了如何部署 GraphScope。GAIA-IR 作为 GraphScope 中 GIE 的重要实现,整体的拉起方式与 GraphScope 保持一致。我们以 Helm 部署 GraphScope 为例,只需要在安装过程中,指定引擎选项为 GAIA,便可以顺利拉起 GAIA-IR,安装命令示例如下:
helm repo add graphscope https://graphscope.oss-cn-beijing.aliyuncs.com/charts/ helm install [RELEASE_NAME] --set executor=gaia graphscope/graphscope-store
更多详细的部署操作可以参考官方文档[7]。
Gremlin 查询:在成功拉起服务后,我们可以通过 Gremlin Server host 和 port 来进行查询。以 Gremlin Console 查询为例,在服务顺利拉起并且导入数据(具体数据导入步骤可参考官方文档[8])之后,我们便可以通过配置 Gremlin Console 来进行查询。示例如下:
conf/remote.yaml 配置文件,修改对应的 host 和 port;remote.yaml 的配置,便可以开始查询:gremlin> :remote connect tinkerpop.server conf/remote.yaml
==>Configured localhost/127.0.0.1:8182
gremlin> :remote console
==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182] - type ':remote console' to return to local mode
gremlin> g.V().valueMap('name','age')
==>[name:[marko],age:[29]]
==>[name:[vadas],age:[27]]
本文简述了 GAIA-IR 的设计初衷和总体架构,以及如何使用 GAIA-IR 引擎进行查询。在 GAIA-IR 的目录[9]可以找到 GitHub 上的当前发布版本。GAIA-IR 作为 GraphScope 的图查询引擎,提供高效的 Gremlin 并行化查询实现。同时,在 IR 的统一中间表示上,我们也会引入更多的等价变换、优化实现,支持例如 Pattern Match 等重要场景。在后续的文章中,我们也会介绍更多的技术细节。我们也将持续完善 GAIA-IR 的实现,同时非常欢迎与期待社区的反馈和贡献。
[1]Gremlin: http://tinkerpop.apache.org/
[2]Neo4j: https://neo4j.com/
[3]OrientDB: https://www.orientdb.org/
[4]JanusGraph: https://janusgraph.org/
[5]Microsoft Cosmos DB: https://azure.microsoft.com/en-us/services/cosmos-db/
[6]Amazon Neptune: https://aws.amazon.com/neptune/
[7]官方文档: https://graphscope.io/docs/persistent_graph_store.html
[8]官方文档: https://graphscope.io/docs/persistent_graph_store.html
[9]GAIA-IR 的目录: https://github.com/alibaba/GraphScope/tree/main/research/query_service/ir
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我想设置一个默认日期,例如实际日期,我该如何设置?还有如何在组合框中设置默认值顺便问一下,date_field_tag和date_field之间有什么区别? 最佳答案 试试这个:将默认日期作为第二个参数传递。youcorrectlysetthedefaultvalueofcomboboxasshowninyourquestion. 关于ruby-on-rails-date_field_tag,如何设置默认日期?[rails上的ruby],我们在StackOverflow上找到一个类似的问
我将我的Rails应用程序部署到OpenShift,它运行良好,但我无法在生产服务器上运行“Rails控制台”。它给了我这个错误。我该如何解决这个问题?我尝试更新rubygems,但它也给出了权限被拒绝的错误,我也无法做到。railsc错误:Warning:You'reusingRubygems1.8.24withSpring.UpgradetoatleastRubygems2.1.0andrun`gempristine--all`forbetterstartupperformance./opt/rh/ruby193/root/usr/share/rubygems/rubygems
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame