目前为止,我们已经学习了javaScript的一些简单的语法。但是这些简单的语法,并没有和浏览器有任何交互。也就是我们还不能制作一些我们经常看到的网页的一些交互,我们需要继续学习BOM和DOM相关知识。
Javascript 由三部分构成,ECMAScript,DOM和BOM。
BOM(Browser Object Model)是指浏览器对象模型,它使 JavaScript 有能力与浏览器进行“对话”。
DOM (Document Object Model)是指文档对象模型,通过它,可以访问HTML文档的所有元素
所有浏览器都支持 window 对象。它表示浏览器窗口。
window.innerHeight - 浏览器窗口的内部高度
window.innerWidth - 浏览器窗口的内部宽度
window.open() - 打开新窗口
window.close() - 关闭当前窗口
浏览器对象,通过这个对象可以判定用户所使用的浏览器,包含了浏览器相关信息。
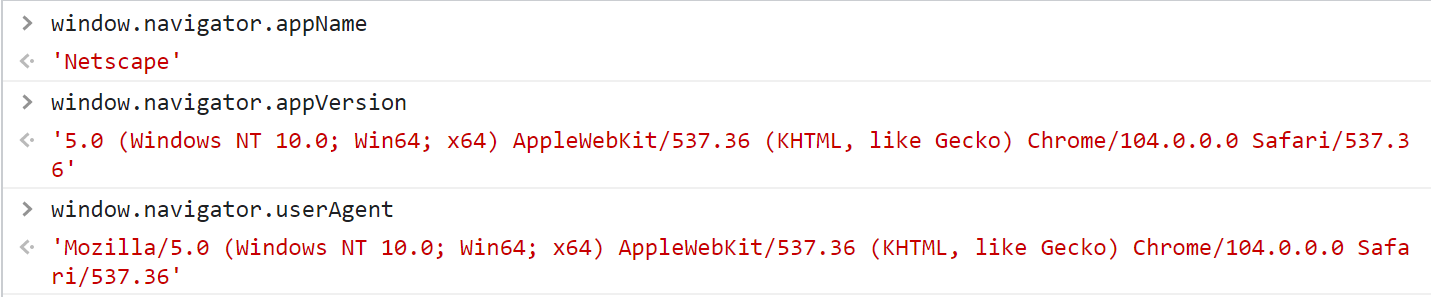
1.浏览器全称
window.navigator.appName
输出结果:
"Netscape"
2.浏览器厂商和版本的详细字符串
window.navigator.appVersion
输出结果:
'5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
3.用来标识\效验当前是否是一个浏览器 是否存在(userAgent)参数
window.navigator.userAgent
输出结果:
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
4.查看当前平台
window.navigator.platform
扩展(user-agent)网站仿爬措施
1.最简单最常用的一个就是校验当前请求的发起者是否是一个浏览器 userAgent
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36
如何破解该措施?
在你的代码中加上上面的user-agent配置即可
浏览历史对象,包含了用户对当前页面的浏览历史,但我们无法查看具体的地址,可以简单的用来前进或后退一个页面。
history.forward() // 前进一页
history.back() // 后退一页
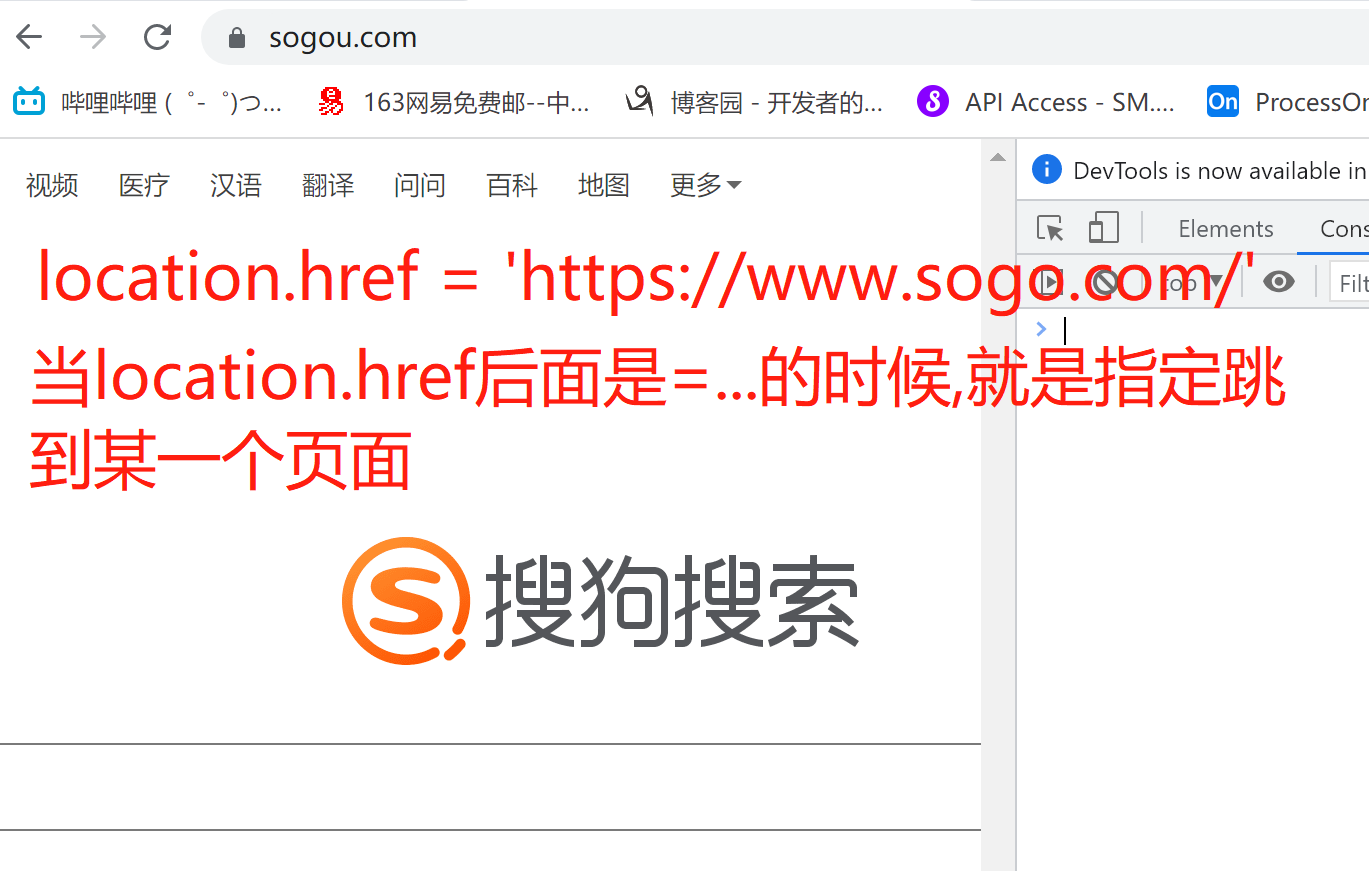
window.location 对象用于获得当前页面的地址 (URL),并把浏览器重定向到新的页面。
location.href 获取URL
location.href="URL" // 跳转到指定页面
location.reload() 重新加载页面

location.href = 'https://www.sogo.com/'
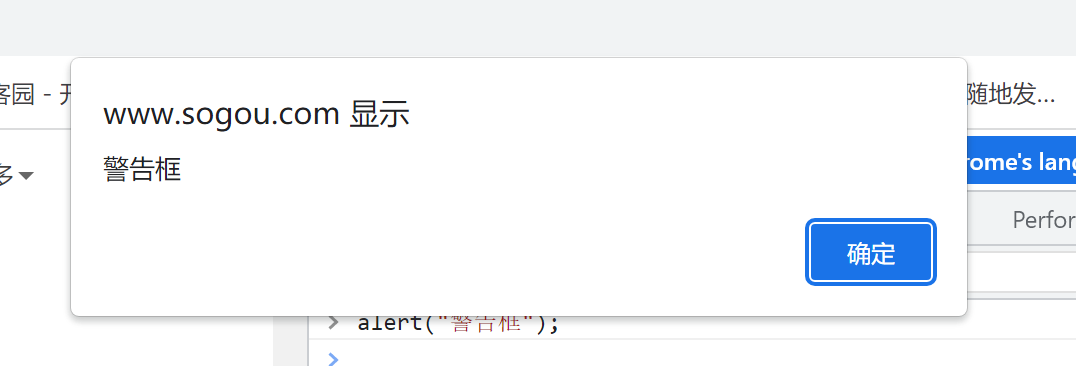
可以在 JavaScript 中创建三种消息框:警告框、确认框、提示框。
警告框经常用于确保用户可以得到某些信息。
当警告框出现后,用户需要点击确定按钮才能继续进行操作。
alert("警告框");
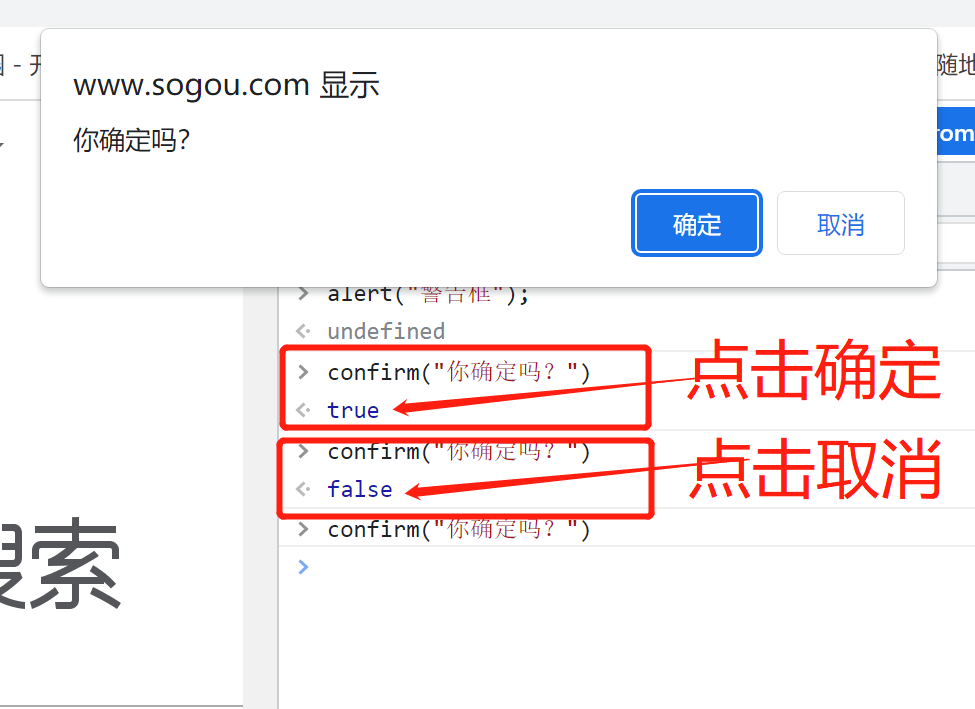
确认框用于使用户可以验证或者接受某些信息。
当确认框出现后,用户需要点击确定或者取消按钮才能继续进行操作。
如果用户点击确认,那么返回值为 true。如果用户点击取消,那么返回值为 false。
confirm("你确定吗?")
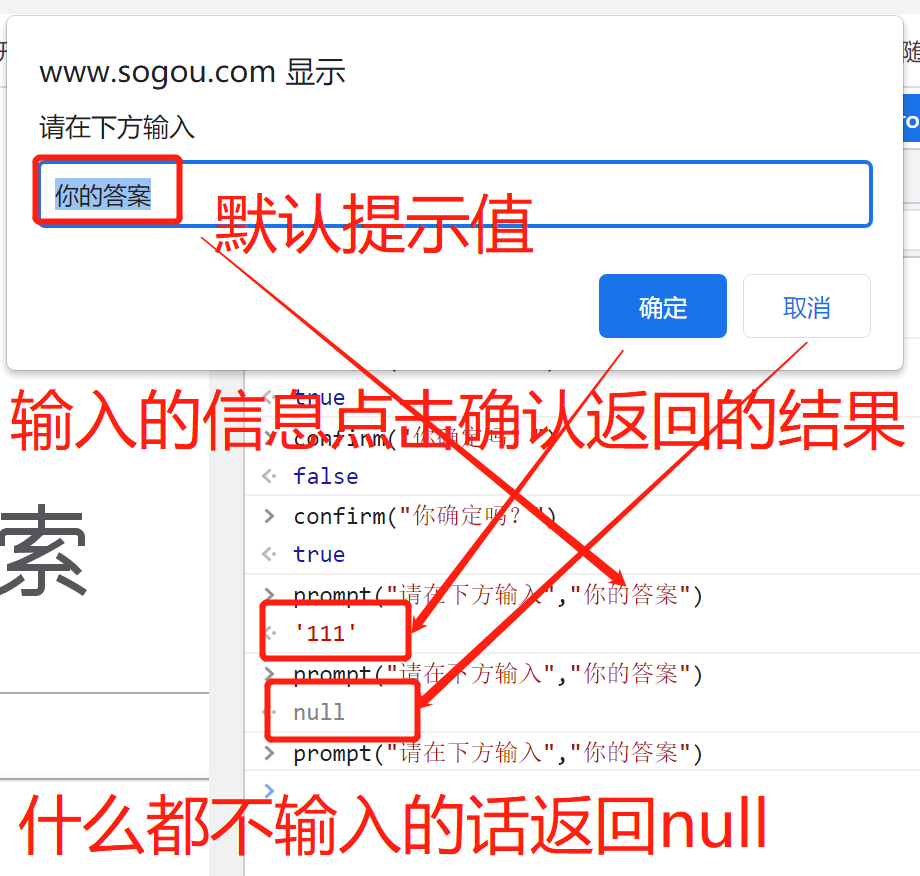
提示框经常用于提示用户在进入页面前输入某个值。
当提示框出现后,用户需要输入某个值,然后点击确认或取消按钮才能继续操纵。
如果用户点击确认,那么返回值为输入的值。如果用户点击取消,那么返回值为 null。
prompt("请在下方输入","你的答案")
通过使用 JavaScript,我们可以在一定时间间隔之后来执行代码,而不是在函数被调用后立即执行。我们称之为计时事件。
案例:过一段时间之后触发(一次)3秒触发一次,可以取消定时任务,就不会进行执行
<script>
function func1() {
alert(123)
}
// 毫秒为单位 3秒之后自动执行func1函数
let t = setTimeout(func1,3000);
// 取消定时任务 如果你想要清除定时任务 需要提前用变量指代定时任务
clearTimeout(t)
</script>
限制每隔3秒触发执行一次,九秒后触发 停止执行。
<script>
function func2() {
alert(123)
}
function show(){
let t = setInterval(func2,3000); // 每隔3秒执行一次
function inner(){
clearInterval(t) // 清除定时器
}
setTimeout(inner,9000) // 9秒中之后触发/执行
}
show()
</script>
DOM 是一套对文档的内容进行抽象和概念化的方法。
当网页被加载时,浏览器会创建页面的文档对象模型(Document Object Model)。
HTML DOM 模型被构造为对象的数。
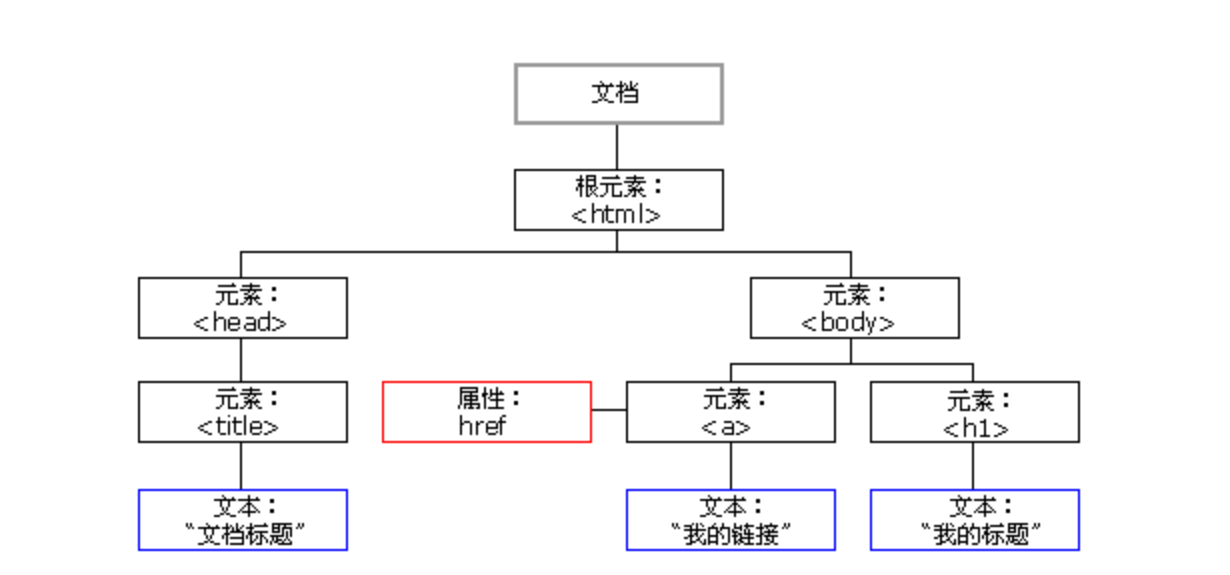
文档节点(document对象):代表整个文档
元素节点(element 对象):代表一个元素(标签)
文本节点(text对象):代表元素(标签)中的文本
属性节点(attribute对象):代表一个属性,元素(标签)才有属性
注释是注释节点(comment对象)
所有的标签都可以称之为是节点
当我们的js文件中涉及到了查找标签的时候,确保能找到该标签,我们要把js文件放入body里面最下面,因为代码是向下走,走到最下面的时候,说明所有涉及到的标签都已经存在了,就可以使用了,不会存在找不到的情况
document.getElementById()
根据id值查找标签 结果直接是标签对象本身
document.getElementsByClassName()
根据class值查找标签 结果是数组类型
document.getElementsByTagName()
根据标签名查找标签 结果是数组类型
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="d2">div
<div>div>div</div>
<p class="c1">div>p
<span>div>p>span</span>
</p>
<p>div>p</p>
</div>
<div>div+div</div>
</body>
</html>
注意三个方法的返回值是不一样的
document.getElementById('d1') # id查询(唯一)
输出结果:
<div id="d1">…</div> // id不存在的话返回null
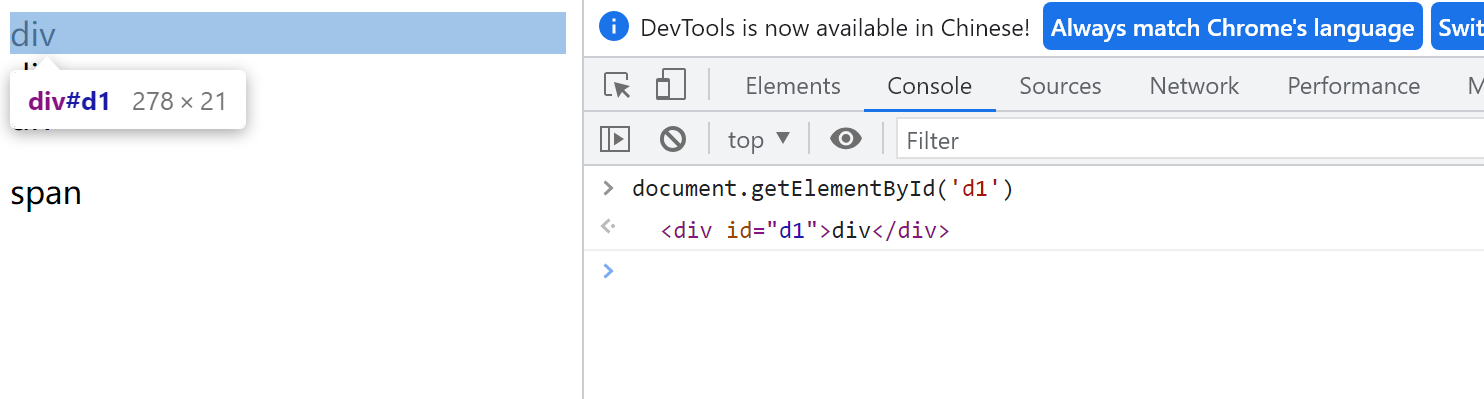
document.getElementsByClassName('c1') # 返回数组
输出结果:
HTMLCollection(2) [div.c1, p.c1]
注意:
Element与Elements区别
Element:代表查询单个元素
Elements: 代表查询多个元素
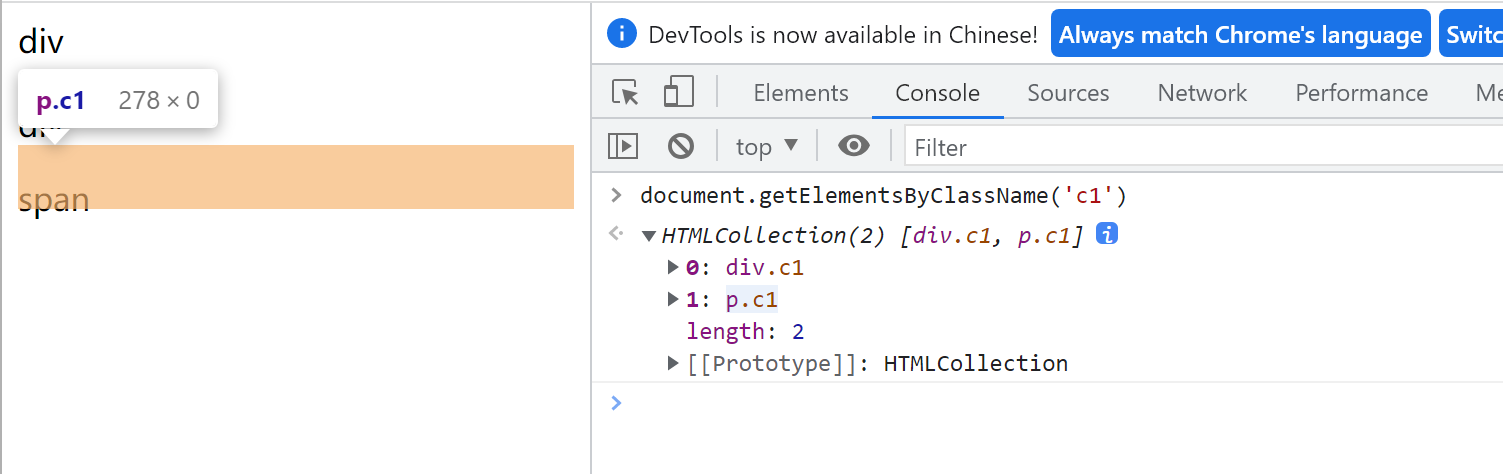
document.getElementsByTagName('div') # 数组
输出结果:
HTMLCollection(3) [div#d1, div, div, d1: div#d1]
索引取值方法(获取标签数组内容)
document.getElementsByTagName('div')[1]
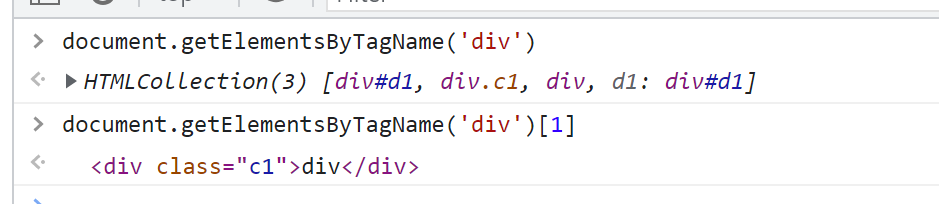
let divEle = document.getElementsByTagName('div')[1]
# 打印变量
divEle
输出结果:
<div class="c1">div</div>
注意:(存储变量名
当你用变量名指代标签对象的时候 一般情况下都推荐你书写成(见名知意)
以下示例:
xxxEle
divEle
aEle
pEle
ps:动态创建 临时有效 非永久
parentElement 父节点标签元素
children 所有子标签
firstElementChild 第一个子标签元素
lastElementChild 最后一个子标签元素
nextElementSibling 下一个兄弟标签元素
previousElementSibling 上一个兄弟标签元素
let divEle = document.getElementById('d1')
let divEle = document.getElementById('d1')
divEle.parentElement
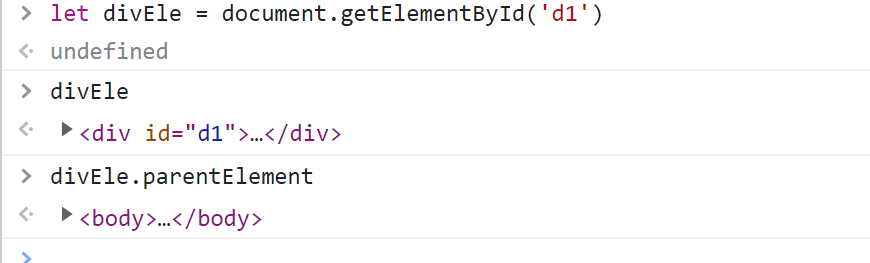
divEle.children
返回结果:
HTMLCollection(3) [p, span, p]

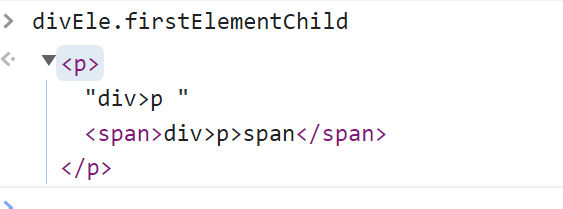
divEle.firstElementChild
1.通过DOM操作动态的创建a标签
2.并且给标签加属性
3.最后将a标签追加到div标签尾部文本中
临时操作(刷新丢失)
1.创建标签
let XXXEle = document.createElement('标签名')
2.添加默认属性值
XXXEle.id = 'id值'
3.添加内部文本
XXXEle.innerText = '内部文本'
4.尾部添加
divEle.append(XXXEle)
XXXEle.属性 只能是默认属性
XXXEle.setAttribute() 默认属性、自定义属性(可以只记住这个)
例子:
1.既可以设置自定义的属性也可以设置默认的书写
imgEle.setAttribute('username','jason')
undefined
2.打印标签
imgEle
<img src="111.png" username="jason">
divEle.innerText # 获取标签内部所有的文本
输出结果:
"div 百度
div>p
div>span"
divEle.innerHTML # 内部文本和标签都拿到
输出结果:
"div
<a href="https://www.baidu.com/">百度</a><p id="d2">div>p</p>
<span>div>span</span>"
对比innerText与innerHTML区别
divEle.innerText = 'heiheihei'
"heiheihei"
divEle.innerHTML = 'hahahaha'
"hahahaha"
divEle.innerText = '<h1>heiheihei</h1>' # 不识别html标签
"<h1>heiheihei</h1>"
divEle.innerHTML = '<h1>hahahaha</h1>' # 识别html标签
"<h1>hahahaha</h1>"
总结它们俩个的区别
innerText: 只能获取标签内部的文本 设置文本的时候不识别HTML标签
innerHTML: 文本和标签都获取 设置文本的时候识别HTML标签
这是一个研究案例:......我正在尝试使用WatirRuby的API引用名为“bar”的嵌入元素。该元素由Chrome的DOM检查器显示,但我无法使用Watir的任何查找方法找到它:browser.embeds()#onlyisfoundbrowser.html.include?'bar'#=>false为什么会这样?为什么Watir不显示完整的HTML?如果我有不同框架中的元素或由Javascript初始化函数动态插入的元素,是否可以使用Watir访问它们?谢谢 最佳答案 如果元素在框架中,你必须使用这样的东西:browser.
我正在为Mechanize而苦苦挣扎。我希望“单击”一组只能通过其位置(div#content中的所有链接)或其href来识别的链接。以上两种识别方法我都试过了,都没有成功。从文档中,我无法弄清楚如何根据链接在DOM中的位置而不是直接通过链接上的属性返回一组链接(用于单击)。其次,documentation建议你可以使用:href来匹配部分href,page=agent.get('http://foo.com/').links_with(:href=>"/something")但我让它返回链接的唯一方法是传递一个完全限定的URL,例如page=agent.get('http://foo
有没有办法从传入的html_tag元素向上攀登DOM树?ActionView::Base.field_error_proc=Proc.newdo|html_tag,instance|#implementationend无论如何我可以实现这个方法来向上移动DOM树并将一个类放在父div上吗?例如:EmailAddress我想在div.email上放置一个类,而不是直接在输入/标签上放置一些东西。这可以用field_error_proc方法完成还是有一个干净的替代方法?我想避免在我对每个表单字段的View中明确地这样做。(像下面这样).email{:class=>object.errors
🐱个人主页:不叫猫先生🙋♂️作者简介:前端领域新星创作者、阿里云专家博主,专注于前端各领域技术,共同学习共同进步,一起加油呀!💫系列专栏:vue3从入门到精通、TypeScript从入门到实践📢资料领取:前端进阶资料以及文中源码可以找我免费领取🔥前端学习交流:博主建立了一个前端交流群,汇集了各路大神,一起交流学习,期待你的加入!(文末有我wx或者私信)目录前言一、vue自定义指令directive讲解二、基于DOM的实现方式1.思路整理2.新建index.vue3.新建`directives`文件4.在`directives`文件下创建`index.ts`文件5.在`main.ts`中全局引
有没有办法做到this使用capybara+phantomjs。或者更复杂的东西,比如将整页屏幕截图裁剪到特定的dom元素? 最佳答案 Apullrequest已提交此功能。即将关闭,您将可以使用driver.renderselector:'#some_id`在下一个版本中。 关于ruby-使用ruby的特定dom元素的屏幕截图,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/
我有一个网页,我需要从中抓取一些数据。问题是,每个页面可能有也可能没有特定数据,或者在DOM中它的上方或下方可能有额外的数据,并且没有CSSid可言。通常我可以使用CSSid或XPath来找到我正在寻找的节点。在这种情况下我没有那个选项。我要做的是搜索“标签”文本,然后在下一个中获取数据节点:Name:JoeSmith在上面的HTML中,我会搜索:doc.search("[text()*='Name:']")获取我需要的数据之前的节点,但我不确定如何从那里导航。 最佳答案 next_element可能是您正在寻找的方法。requir
是否可以从原子Electron桌面开发工具包中的webview元素中抓取html,我正在尝试访问DOM但我什么也没得到,我在运行时尝试了控制台中的document.links但我得到了空属性和对象作为返回?window.onresize=doLayout;varisLoading=false;onload=function(){varwebview=document.querySelector('webview');doLayout();vart=webview.executeJavaScript("console.log(document.links);");document.que
当元素在DOM中的位置发生变化时,是否有可能让React移动元素而不是重新创建它?假设我正在制作一个包含2个Pane的组件,并且我希望能够隐藏/取消隐藏一个Pane。让我们也想象一下Pane本身很重。在我的例子中,每个Pane都有2000多个元素。在我的实际代码中,当有2个Pane时,我使用了拆分器。为了只显示一个Pane,我需要移除拆分器并将其替换为一个div。下面的代码对此进行了模拟。如果只有一个Pane,它会使用div来包含该Pane。如果有2个Pane,它会使用pre来包含它们。在我的例子中,它是div有1个痛点和一个splitter有2个痛点。因此,检测document.cr
我有以下类(class)classMatchBoxextendsReact.Component{constructor(props){super(props);this.countdownHandler=null;this.showBlocker=true;this.start=this.start.bind(this);}start(){...}render(){...return(...);}};functionmapStateToProps(state){...}functionmatchDispatchToProps(dispatch){...}exportdefaultwit
为什么DOM有一个名为self的对象和另一个名为window的对象,而它们是同一事物?更让人困惑的是window有一个名为self的属性,所以:window===window.self===self为什么会这样?我应该使用哪一个? 最佳答案 self由javascript环境定义并指向[global]对象(但不是规范的一部分,因此可能不存在),而window是DOM规范的一部分。在大多数浏览器中,window被用作[global]对象,但并非总是如此。self==window.self并不奇怪,因为它们是同一个对象-当查找self时