Calcite在大数据系统中有着广泛的运用, 比如Apache Flink, Apache Drill等都大量使用了Calcite,理解Calcite的原理可以说已经成为理解大数据系统中SQL访问层实现原理的必备条件之一。
但是不少人在学习Calcite的过程中都发现关于Calcite的实践案例其实很少,本文就将为大家详细介绍如何基于Calcite框架的SQL语法扩展探索使之更符合你的业务需求,以及扩展SQL在数栈产品的应用实践。
Apache Calcite是一个动态的数据管理框架,本身不涉及任何物理存储信息,而是专注在SQL解析、基于关系代数的查询优化,通过扩展方式来对接底层存储。
目前Apache Calcite被应用在广泛的数据开源系统中,比如Apache Hive、Apache Phoenix、Apache Flink等。
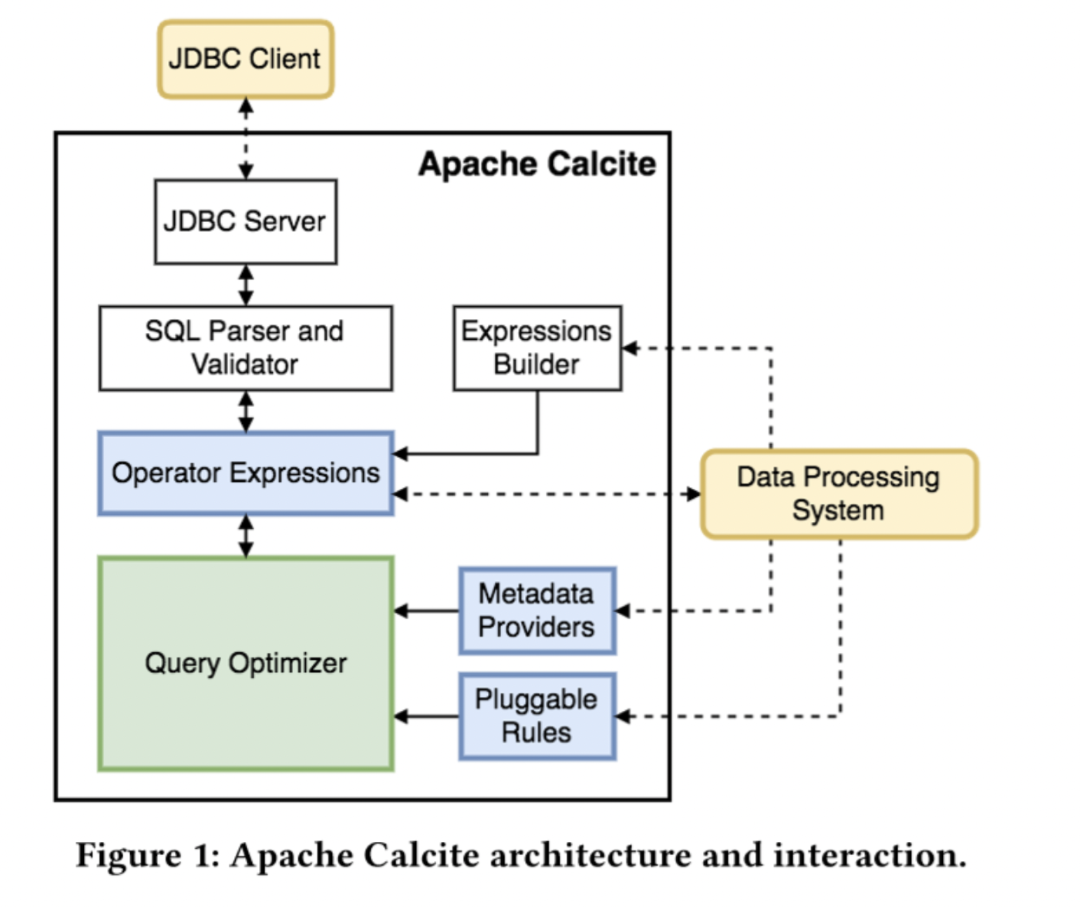
Calcite提供了ANSI标准SQL的解析,以及各种SQL 方言,针对来自于不同数据源的复杂SQL,在Calcite中会把SQL解析成SqlNode语法树结构,然后根据得到的语法树转换成自定义Node,通过自定义Node解析获取到表的字段信息、以及表信息、血缘等相关信息。
下图展示了一部分对外提供的接口信息:
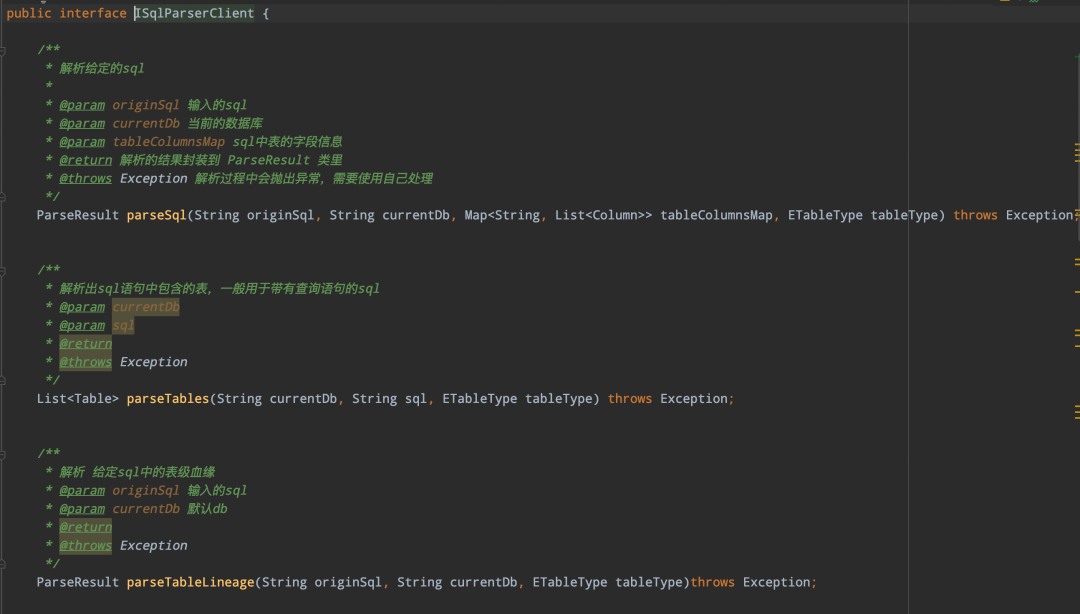
sqlparser 解析模块主要提供了以下几种功能 :
• 解析SQL包含的所有表、字段信息
• 解析SQL的udf函数
• 解析SQL的血缘信息,包括表级血缘、字段血缘
• 解析自定义SqlNode
• api服务变量解析替换
了解完Calcite是什么以及用途后,下面为大家分享Calcite SQL语法扩展的相关内容。
在 sqlparser 中进行sql解析的场景中,有两种情况需要使用到自定义扩展,一是Calcite不支持的一些语法;二是在一些场景中存在sql中带有${var}自定义变量语法。
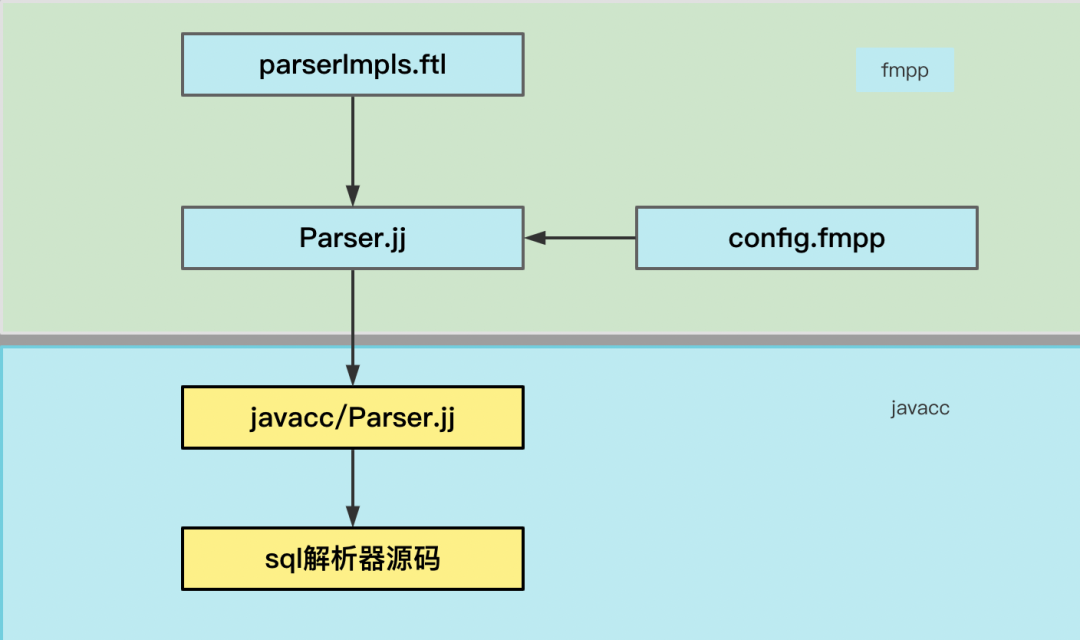
那么针对上面的这两种情况,Calcite的自定义扩展是如何实现的呢?自定义扩展主要涉及到以下三个文件:
• Parser.jj:Parser.jj是一个Calcite核心的语法和词法文件,基于Apache FreeMaker模版,该模版包含着变量,这些变量在编译时可以被替换
• parserImpl.ftl:提供自定义SQL语句、literals、dataType的实现方法
• config.fmpp:该文件是FMPP的配置文件,提供了SQL语句、literals、dataType的接口扩展入口
Calcite使用javacc作为语法解析器,freemaker作为模版,把parserImpls.ftl、config.fmpp、Parser.jj模版合成最终的语法词法文件,最终通过javacc编译成自定义的解析器源码,整体流程如下图所示:
● 工程目录
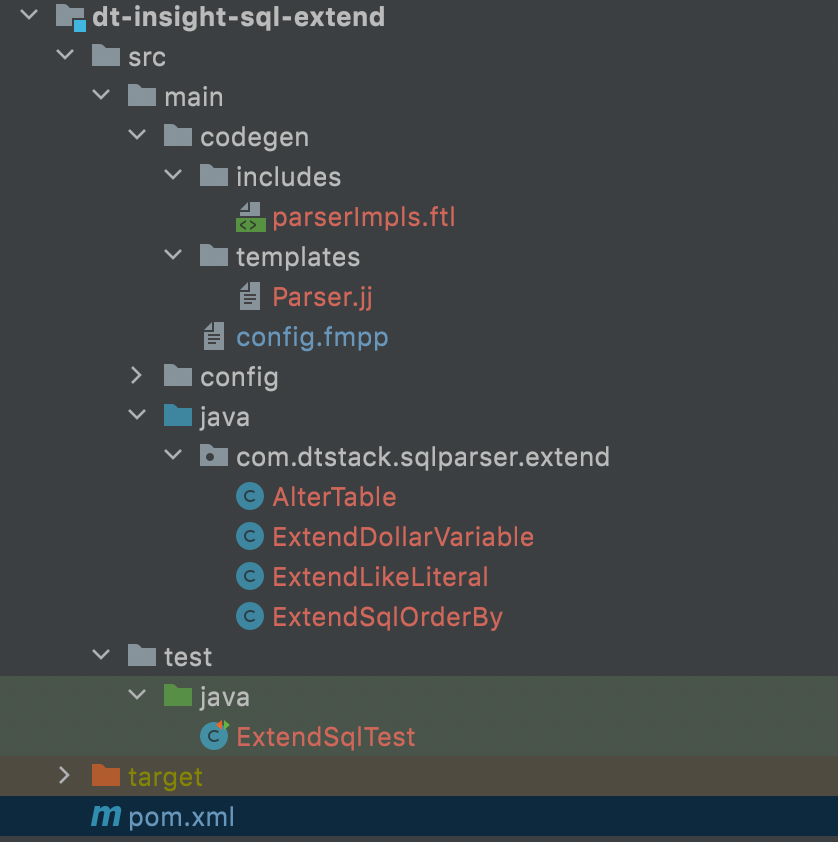
● 扩展sql实现案例
支持以下limit相关语法以及数字可以写成${var}形式:
-> limit count, limit start count
-> limit count offset start
-> offset start limit count
在原生的Calcite解析是支持limit count语法的,但是由于返回SqlOrderBy对象内部类Operator的unparse方法在SQL输出过程中对原始SQL进行了改写,因此需要使用扩展SQL得到正确的SQL。
下面介绍一个limit offset语法扩展样例,扩展SQL如下:
select id, name from test where id > 3 order by id desc limit 1 offset ${offset_val}
整体流程如下:
01
Parser.jj 定义${var}变量的token词法DOLLAR_VARIABLE:

02
Parser.jj 扩展的变量方法接入,下面方法会在解析到limit、offset关键字后面的一个词时进行调用:

03
Parser.jj limit offset在select语法的核心处理逻辑:
-> 定义变量
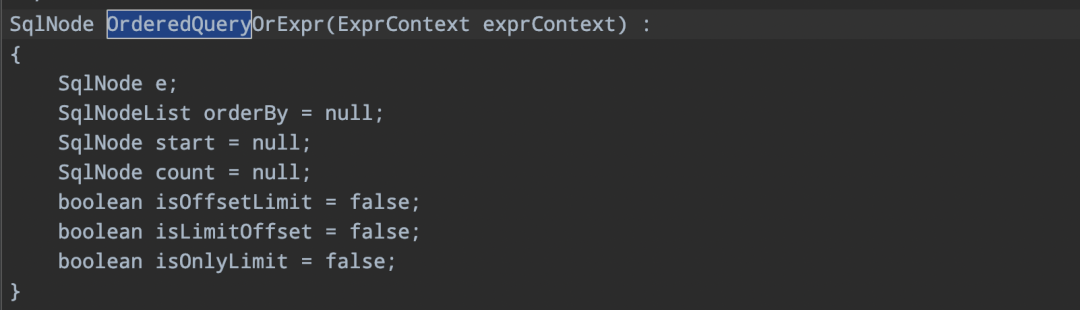
主要定义了三个boolean类型的变量,isOffsetLimit表示offset limit 语法,isLimitOffset表示limit offset语法,isOnlyLimit表示limit count、limit start count语法。
-> 定义处理逻辑
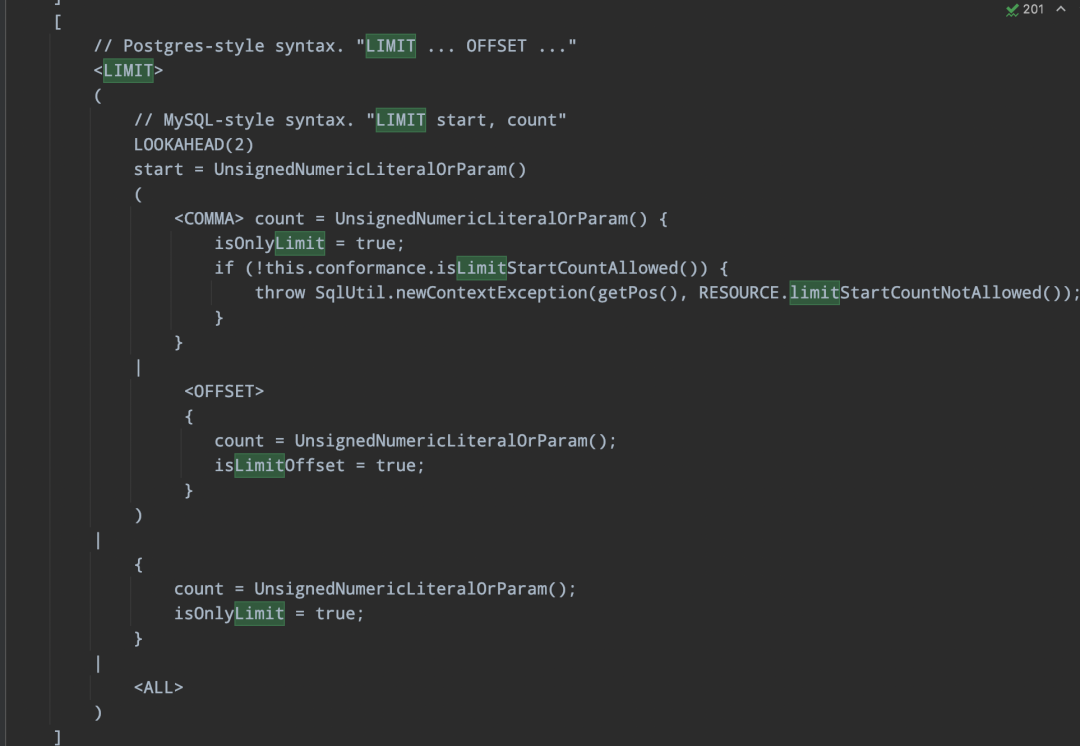
-> 返回自定义SqlNode
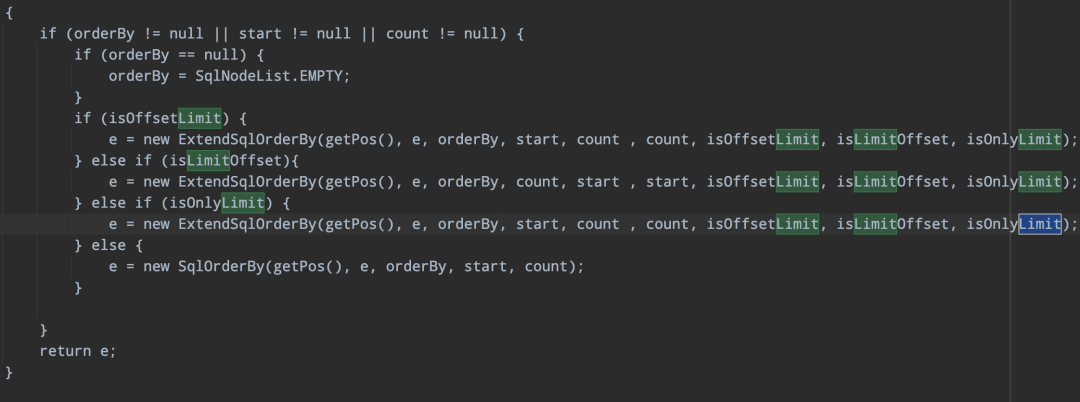
针对符合上面的三个boolean条件时,使用自定义ExtendSqlOrderBy的扩展类。
04
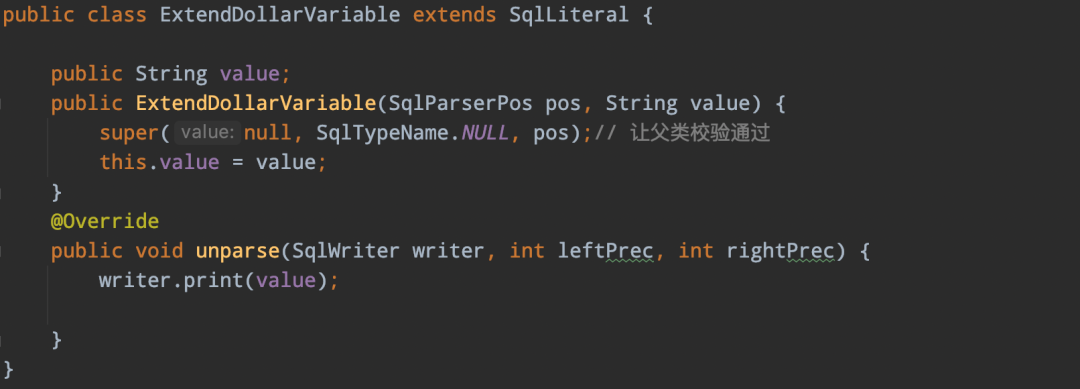
parserImpl.ftl 定义扩展的SqlNode ExtendDollarVariable:
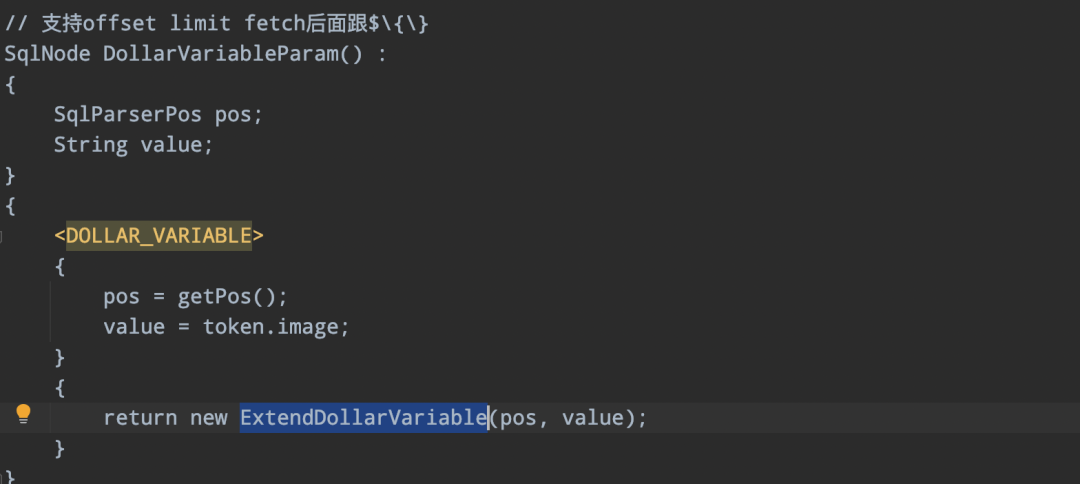
05
config.fmpp 定义包以及扩展实现类的import:
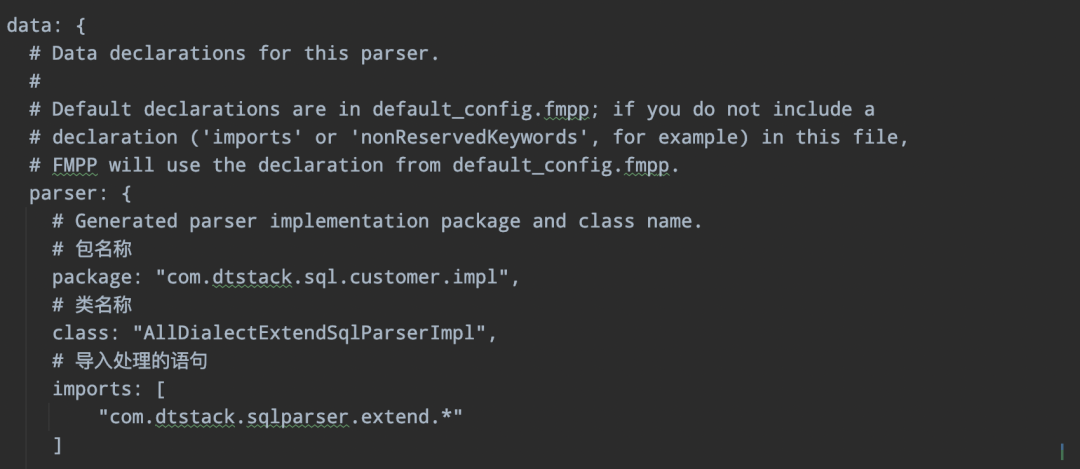
06
扩展SqlNode实现:
-> 变量实现sqlNode
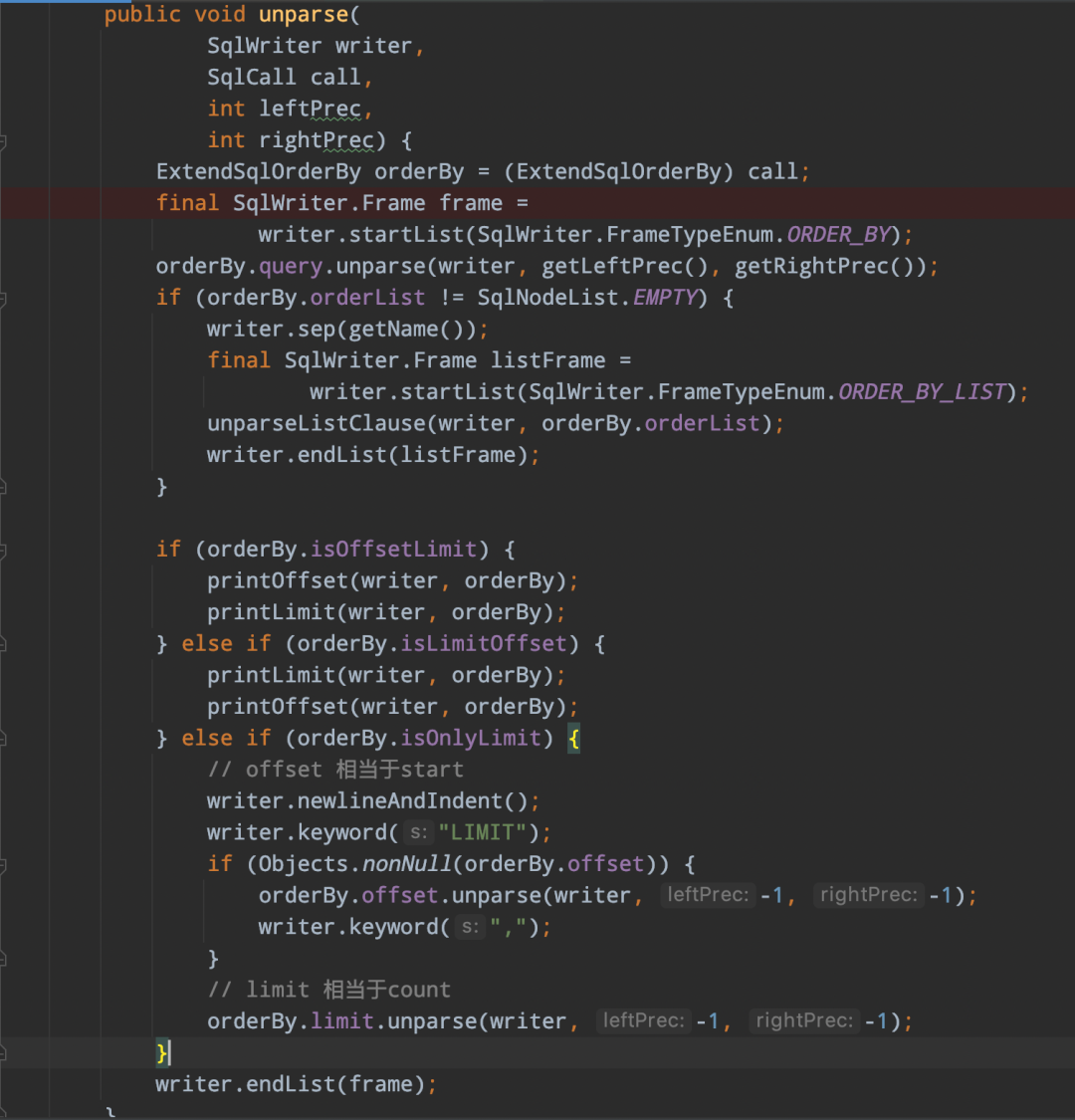
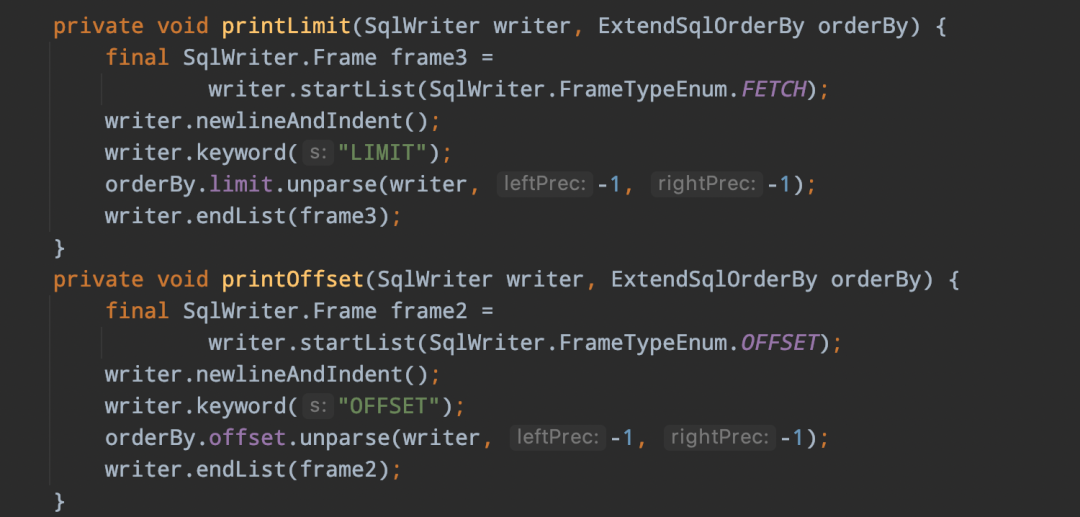
-> 扩展limit实现类ExtendSqlOrderBy,该类实现了SqlOrderBy,并在此基础扩展了limit的SqlNode,以及isOffsetLimit、isLimitOffset、isOnlyLimit三个boolean标识limit的不同语法
通过上面的这些步骤后,最后解析生成的SqlNode语法树如下所示:

目前袋鼠云的底层sqlparser sql解析涉及的子产品应用包括API数据服务、离线开发、客户数据洞察(标签)、实时开发等,虽然大部分针对Calcite的SQL语法扩展相对于上层的产品应用感知不是很明显,但是扩展SQL还是解决了一些痛点,主要如下:
• 逐渐替换底层采用了多种解析工具解析的情况,使维护更简单,减少bug的产生
• 解决一些不支持的语法,避免在上层业务层做处理或者在底层做一些特殊处理
以在API数据服务后续接入的like语法改造为例为大家进行分享,目前的API数据服务中支持like ${var}语法,在执行测试中通过传递like语法来确定执行的模糊匹配方式,例如%xx、xx%、%xx%。
收到客户提出的优化like语法场景,袋鼠云本着客户第一的原则,这种合理的优化需求是采纳的。SQL支持like%${var}、${var}%、%${var}%,这样在执行测试中就不需要输入%了,目前扩展SQL语法已经支持这种优化的like语法,预计在2023年上半年会接入进去,下面通过API数据服务展示当前like SQL和扩展后的SQL差异:
● 当前like ${var}处理
-> 生成API
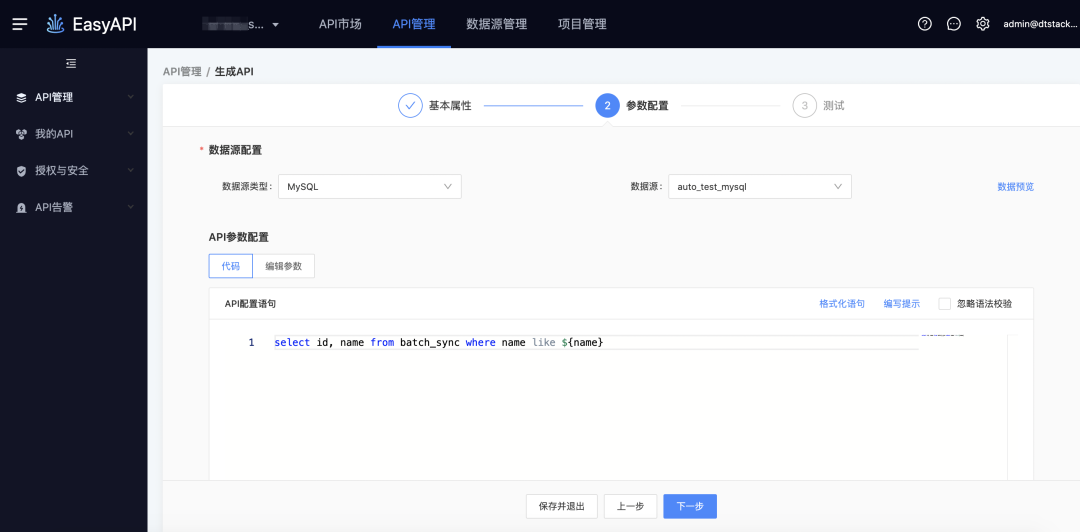
-> 测试执行,模糊匹配需要输入%
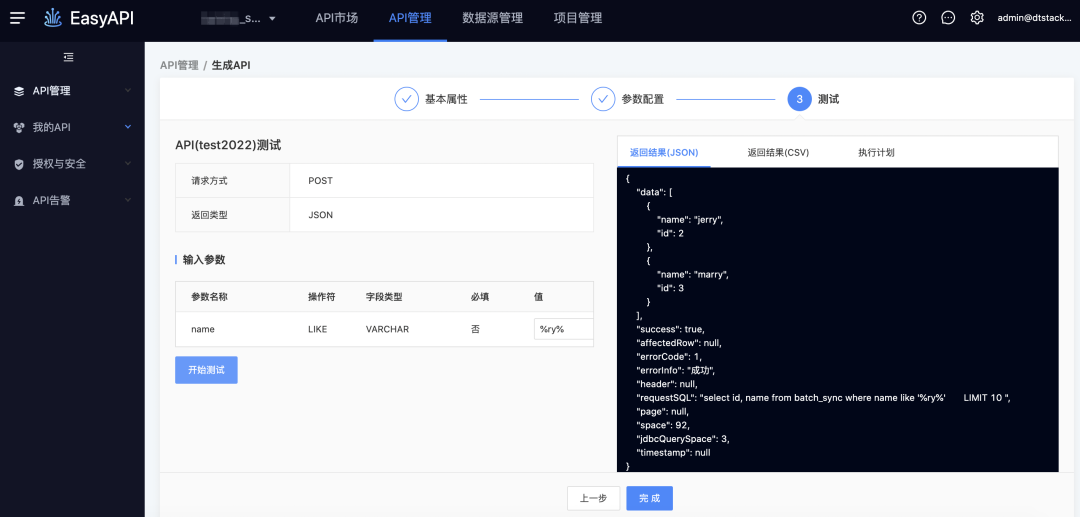
● 扩展like %${var}%
-> 生成API
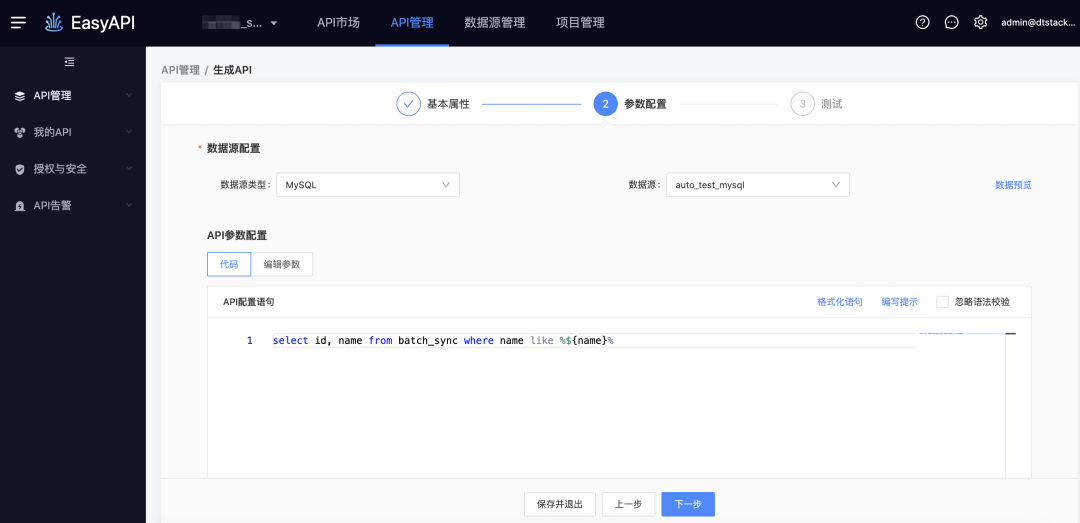
-> 测试执行,由于在SQL阶段已经写了模糊匹配方式,因此可以直接输入值
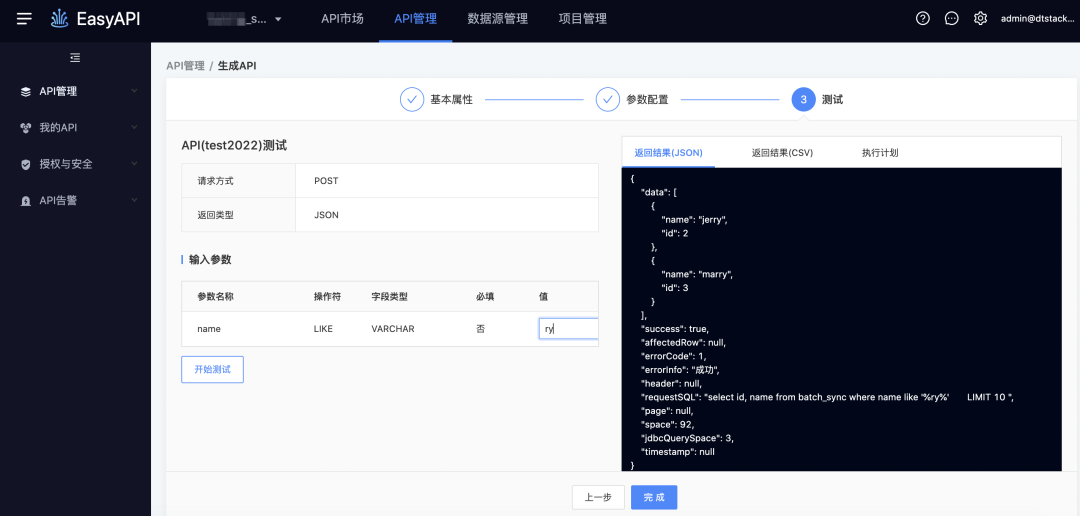
相信通过上面的案例后,大家对于Calcite扩展SQL语法的流程应该有了大致的了解,目前在袋鼠云的业务场景中已经扩展了许多语法,在未来还有一些工作需要进行优化:
• 丰富SQL语法,实现不同数据源扩展SQL语法的隔离
• 逐渐通过SQL语法扩展替换掉底层Calcite和druid共同解析的场景,避免维护多套相同的解析,减少线上问题产生
最后如果是初步接触Calcite SQL语法扩展的同学们,建议先熟悉javacc语法。
地址:https://javacc.github.io/javacc/
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我想这样组织C源代码:+/||___+ext||||___+native_extension||||___+lib||||||___(Sourcefilesarekeptinhere-maycontainsub-folders)||||___native_extension.c||___native_extension.h||___extconf.rb||___+lib||||___(Rubysourcecode)||___Rakefile我无法使此设置与mkmf一起正常工作。native_extension/lib中的文件(包含在native_extension.c中)将被完全忽略。
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"