- 🌸个人主页:JOJO数据科学
- 📝个人介绍:统计学top3高校统计学硕士在读
- 💌如果文章对你有帮助,欢迎✌
关注、👍点赞、✌收藏、👍订阅专栏- ✨本文收录于【推荐系统入门到项目实战】本系列主要分享一些学习推荐系统领域的方法和代码实现。
到目前为止,我们讨论的推荐系统都是纯粹基于交互数据的。我们在之前的文章中讨论了为什么使用交互数据能够捕捉这些个性化信息,只需在用户和项目之间找到最大限度解释差异的模式。这个论点在某些条件下理论上是成立的,但也有相当的局限性。在实践中,有几种情况偏离了我们到目前为止所描述的经典设置,需要更复杂的模型,利用侧面信息或特征结构来提高性能,例如:
可能只有有限的交互数据可用。我们的论点是,互动数据足以捕捉微妙的偏好信号,这只适用于极限情况,即当每个用户(或项目)有大量的互动可用时。当可用的互动很少时(或者没有,在冷启动问题中),我们必须依靠用户或物品的特征来估计初始偏好模型。
除了提高性能,为了模型的可解释性,将特征纳入推荐系统可能是更合理的。例如,我们可能希望了解用户对价格变化的反应;要有效地做到这一点,可能需要将价格特征适当地加入到模型中。
但是! 我们之前讨论的方法:矩阵分解(MF)、SVD、基于相似度推荐等方法都只考虑了两个纬度,user,和item,无法引入用户和物品的其他特征
接下来,我们要讨论的FM(Factorization Machines) 是一种可以加入其他特征来提升矩阵分解效果的方法。
隐语义模型通过 γ u γ_u γu和 γ i γ_i γi将用户和物品嵌入低维空间,然后通过内积对它们之间的交互进行建模;因子分解机扩展了这种方法,以合并用户、项目和其他特征之间的任意成对交互
思考:现在假设我们的输入交互数据如下,包括用户ID、项目ID和与交互相关的其他特征(例如星期、和价格)

我们之前讨论过为什么我们不能将所有这些特征放入一个简单的线性模型中——因为我们需要捕捉交互特征来获得个性化推荐部分,之前我们介绍的SVD矩阵分解模型,针对的数据集是只包含用户和物品之间的矩阵,无法处理上述这种数据情况。
**思想:**每个特征都存在一个关联的低维向量(例如我们之前MF中的user matrix和item matrix)
因子分解机的基本思想是为特征之间的任意相互作用建模。每个特征维度都与一个潜在的表征
γ
i
γ_i
γi相关联;然后,模型方程是以所有(非零)特征(特征维度为F)来定义的。
f
(
x
)
=
w
0
+
∑
i
=
1
F
w
i
x
i
+
∑
i
=
1
F
∑
j
=
i
+
1
F
<
γ
i
,
γ
j
>
x
i
x
j
f(x) = w_0 +\sum_{i=1}^{F}w_ix_i+\sum_{i=1}^{F}\sum_{j=i+1}^{F}<\gamma_i,\gamma_j>x_ix_j
f(x)=w0+i=1∑Fwixi+i=1∑Fj=i+1∑F<γi,γj>xixj
如果交互矩阵仅包含用户和项目的情况,则上述等式等价于潜在因子模型,即对于用户 u 和项目 i,唯一的交互项是
γ
u
⋅
γ
i
γ_u · γ_i
γu⋅γi。因此,分解机可以看作是潜在因子模型的泛化,它允许考虑其他类型的交互。
解析:
上市包含两个部分:其中一阶项代表单独每个特征的信息,可以理解成一个简单的线性回归,但是我们之前讨论了线性回归无法包含个性化信息,因此,二阶项给了我们各自特征之间交互的个性化信息。
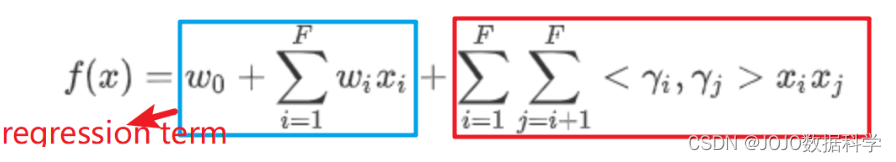
二阶项可以简化成下列形式:
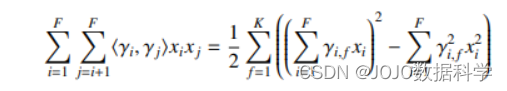
然后我们要做的就是估计出这些未知参数,具体计算代码后文给出。下面我们来看具体的示例
假设:我们有一个数据集,有Item ID, User ID,Weekday,那么我们现在如何建立因子分解机模型,结果如下:
f ( x ) = w 0 + w 1 x i + w 2 x u + w 3 x w + < γ i , γ u > x i x u + < γ i , γ w > x i x w + < γ w , γ u > x w x u f(x)=w_0 + w_1x_i+w_2x_u+w_3x_w+<\gamma_i,\gamma_u>x_ix_u+<\gamma_i,\gamma_w>x_ix_w+<\gamma_w,\gamma_u>x_wx_u f(x)=w0+w1xi+w2xu+w3xw+<γi,γu>xixu+<γi,γw>xixw+<γw,γu>xwxu
其中 x i , x u , x w x_i,x_u,x_w xi,xu,xw在这里分别表示item,user,weekday进行one-hot编码后得到的向量,而 γ i , γ u , γ w \gamma_i,\gamma_u,\gamma_w γi,γu,γw包含了它们之间的交互信息我们的目标就是拟合出这些系数,然后得到我们的 f ^ ( x ) \hat f(x) f^(x)
import gzip
import matplotlib.pyplot as plt
import numpy
import random
import scipy
import tensorflow as tf
from collections import defaultdict
from fastFM import als
from scipy.spatial import distance
解析 Goodreads 漫画书数据(不包括评论)
def parseData(fname):
for l in gzip.open(fname):
d = eval(l)
del d['review_text'] #丢掉评论数据保存空间
d['year'] = int(d['date_added'][-4:]) # 只适用这一部分来展示
yield d
data = list(parseData("goodreads_reviews_comics_graphic.json.gz"))
random.shuffle(data)
data[0]
{'user_id': '81949d8bcf2b4a1fa26e6a9ac23cc9fd',
'book_id': '377254',
'review_id': '07ddcd474a9661cd6d88c760858e4f95',
'rating': 3,
'date_added': 'Thu Feb 14 09:30:44 -0800 2008',
'date_updated': 'Thu Feb 14 09:32:00 -0800 2008',
'read_at': 'Fri Feb 01 00:00:00 -0800 2008',
'started_at': '',
'n_votes': 0,
'n_comments': 0,
'year': 2008}
转换数据格式,最重要的是,每个用户和项目都被映射为一个从1到nUsers/nItems的ID
userIDs,itemIDs = {},{}
for d in data:
u,i = d['user_id'],d['book_id']
if not u in userIDs: userIDs[u] = len(userIDs)
if not i in itemIDs: itemIDs[i] = len(itemIDs)
nUsers,nItems = len(userIDs),len(itemIDs)
nUsers,nItems
(59347, 89311)
构建因式分解机输入矩阵。请注意,每个实例都是一行,列对用户和项目进行编码。可以直接添加其他功能。
这里我们使用scipy.sparse.lil_matrix生成需要的格式
X = scipy.sparse.lil_matrix((len(data), nUsers + nItems))
for i in range(len(data)):
user = userIDs[data[i]['user_id']]
item = itemIDs[data[i]['book_id']]
X[i,user] = 1 # One-hot encoding of user
X[i,nUsers + item] = 1 # One-hot encoding of item
生成每一行预测的目标(这里是评分)
y = numpy.array([d['rating'] for d in data])
fm = als.FMRegression(n_iter=1000, init_stdev=0.1, rank=5, l2_reg_w=0.1, l2_reg_V=0.5)
将数据拆分为训练和测试部分
X_train,y_train,data_train = X[:400000],y[:400000],data[:400000]
X_test,y_test,data_test = X[400000:],y[400000:],data[400000:]
fm.fit(X_train, y_train)
FMRegression(init_stdev=0.1, l2_reg=0, l2_reg_V=0.5, l2_reg_w=0.1, n_iter=1000,
random_state=123, rank=5)
y_pred = fm.predict(X_test)
y_pred[:10]
array([2.23866277, 4.37847526, 3.84866594, 5.03002627, 3.94993096,
4.36740166, 4.22497778, 4.30029268, 3.28282377, 4.05036905])
y_test[:10]
array([0, 3, 3, 4, 4, 2, 5, 4, 4, 5])
def MSE(predictions, labels):
differences = [(x-y)**2 for x,y in zip(predictions,labels)]
return sum(differences) / len(differences)
MSE(y_pred, y_test)
1.5940755947213534
这样我们就得到了因子分解机模型的结果
我们来看看因子分解机(FM)与矩阵分解(MF)的区别:
FM矩阵将User和Item都进行了one-hot编码作为特征,使得特征维度非常巨大且稀疏
矩阵分解MF是FM的特例,即特征只有User ID 和Item ID的FM模型
矩阵分解只能进行简单的用户和物品之间的特征计算,无法利用其他特征
FM引入了更多辅助信息(Side information)作为特征
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc