其实在当今社会,网络上充斥着大量有用的数据,我们只需要耐心的观察,再加上一些技术手段,就可以获取到大量的有价值数据。这里的“技术手段”就是网络爬虫。今天就给大家分享一篇爬虫基础知识和入门教程:
爬虫就是自动获取网页内容的程序,例如搜索引擎,Google,Baidu 等,每天都运行着庞大的爬虫系统,从全世界的网站中爬虫数据,供用户检索时使用。
其实把网络爬虫抽象开来看,它无外乎包含如下几个步骤
那么我们该如何使用 Python 来编写自己的爬虫程序呢,在这里我要重点介绍一个 Python 库:Requests。
Requests 库是 Python 中发起 HTTP 请求的库,使用非常方便简单。
模拟发送 HTTP 请求
发送 GET 请求
当我们用浏览器打开豆瓣首页时,其实发送的最原始的请求就是 GET 请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
<Response [200]>
<class 'requests.models.Response'>可以看到,我们得到的是一个 Response 对象
如果我们要获取网站返回的数据,可以使用 text 或者 content 属性来获取
text:是以字符串的形式返回数据
content:是以二进制的方式返回数据
print(type(res.text))
print(res.text)
>>>
<class 'str'> <!DOCTYPE HTML>
<html lang="zh-cmn-Hans" class="">
<head>
<meta charset="UTF-8">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">
<meta name="keywords" content="豆瓣,广播,登陆豆瓣">.....发送 POST 请求
对于 POST 请求,一般就是提交一个表单
r = requests.post('http://www.xxxx.com', data={"key": "value"})
data 当中,就是需要传递的表单信息,是一个字典类型的数据。
header 增强
对于有些网站,会拒绝掉没有携带 header 的请求的,所以需要做一些 header 增强。比如:UA,Cookie,host 等等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}2020-10-25 14:56·数据分析不是个事儿
其实在当今社会,网络上充斥着大量有用的数据,我们只需要耐心的观察,再加上一些技术手段,就可以获取到大量的有价值数据。这里的“技术手段”就是网络爬虫。今天就给大家分享一篇爬虫基础知识和入门教程:
爬虫就是自动获取网页内容的程序,例如搜索引擎,Google,Baidu 等,每天都运行着庞大的爬虫系统,从全世界的网站中爬虫数据,供用户检索时使用。
其实把网络爬虫抽象开来看,它无外乎包含如下几个步骤
那么我们该如何使用 Python 来编写自己的爬虫程序呢,在这里我要重点介绍一个 Python 库:Requests。
Requests 库是 Python 中发起 HTTP 请求的库,使用非常方便简单。
模拟发送 HTTP 请求
发送 GET 请求
当我们用浏览器打开豆瓣首页时,其实发送的最原始的请求就是 GET 请求
import requests
res = requests.get('http://www.douban.com')
print(res)
print(type(res))
>>>
<Response [200]>
<class 'requests.models.Response'>
可以看到,我们得到的是一个 Response 对象
如果我们要获取网站返回的数据,可以使用 text 或者 content 属性来获取
text:是以字符串的形式返回数据
content:是以二进制的方式返回数据
print(type(res.text))
print(res.text)
>>>
<class 'str'> <!DOCTYPE HTML>
<html lang="zh-cmn-Hans" class="">
<head>
<meta charset="UTF-8">
<meta name="google-site-verification" content="ok0wCgT20tBBgo9_zat2iAcimtN4Ftf5ccsh092Xeyw" />
<meta name="description" content="提供图书、电影、音乐唱片的推荐、评论和价格比较,以及城市独特的文化生活。">
<meta name="keywords" content="豆瓣,广播,登陆豆瓣">.....
发送 POST 请求
对于 POST 请求,一般就是提交一个表单
r = requests.post('http://www.xxxx.com', data={"key": "value"})
data 当中,就是需要传递的表单信息,是一个字典类型的数据。
header 增强
对于有些网站,会拒绝掉没有携带 header 的请求的,所以需要做一些 header 增强。比如:UA,Cookie,host 等等信息。
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36",
"Cookie": "your cookie"}
res = requests.get('http://www.xxx.com', headers=header)
解析 HTML
现在我们已经获取到了网页返回的数据,即 HTML 代码,下面就需要解析 HTML,来提取其中有效的信息。
BeautifulSoup
BeautifulSoup 是 Python 的一个库,最主要的功能是从网页解析数据。
from bs4 import BeautifulSoup # 导入 BeautifulSoup 的方法
# 可以传入一段字符串,或者传入一个文件句柄。一般都会先用 requests 库获取网页内容,然后使用 soup 解析。
soup = BeautifulSoup(html_doc,'html.parser') # 这里一定要指定解析器,可以使用默认的 html,也可以使用 lxml。
print(soup.prettify()) # 按照标准的缩进格式输出获取的 soup 内容。BeautifulSoup 的一些简单用法
print(soup.title) # 获取文档的 title
print(soup.title.name) # 获取 title 的 name 属性
print(soup.title.string) # 获取 title 的内容
print(soup.p) # 获取文档中第一个 p 节点
print(soup.p['class']) # 获取第一个 p 节点的 class 内容
print(soup.find_all('a')) # 获取文档中所有的 a 节点,返回一个 list
print(soup.find_all('span', attrs={'style': "color:#ff0000"})) # 获取文档中所有的 span 且 style 符合规则的节点,返回一个 list具体的用法和效果,我会在后面的实战中详细说明。
XPath 定位
XPath 是 XML 的路径语言,是通过元素和属性进行导航定位的。几种常用的表达式
表达式含义node选择 node 节点的所有子节点/从根节点选取//选取所有当前节点.当前节点..父节点@属性选取text()当前路径下的文本内容
一些简单的例子
xpath('node') # 选取 node 节点的所有子节点
xpath('/div') # 从根节点上选取 div 元素
xpath('//div') # 选取所有 div 元素
xpath('./div') # 选取当前节点下的 div 元素
xpath('//@id') # 选取所有 id 属性的节点当然,XPath 非常强大,但是语法也相对复杂,不过我们可以通过 Chrome 的开发者工具来快速定位到元素的 xpath,如下图

得到的 xpath 为
//*[@id="anony-nav"]/div[1]/ul/li[1]/a
在实际的使用过程中,到底使用 BeautifulSoup 还是 XPath,完全取决于个人喜好,哪个用起来更加熟练方便,就使用哪个。
我们可以从豆瓣影人页,进入都影人对应的影人图片页面,比如以刘涛为例子,她的影人图片页面地址为
https://movie.douban.com/celebrity/1011562/photos/

下面我们就来分析下这个网页
注意:网络上的网站页面构成总是会变化的,所以这里你需要学会分析的方法,以此类推到其他网站。正所谓授人以鱼不如授人以渔,就是这个原因。
Chrome 开发者工具(按 F12 打开),是分析网页的绝佳利器,一定要好好使用。
我们在任意一张图片上右击鼠标,选择“检查”,可以看到同样打开了“开发者工具”,而且自动定位到了该图片所在的位置
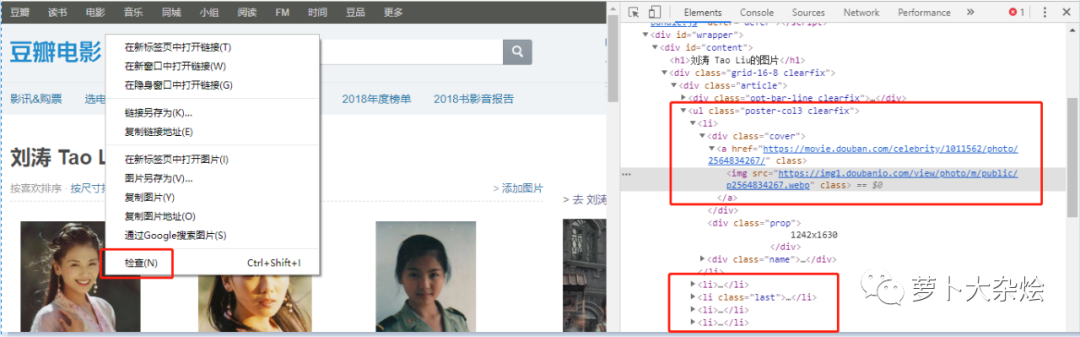
可以清晰的看到,每张图片都是保存在 li 标签中的,图片的地址保存在 li 标签中的 img 中。
知道了这些规律后,我们就可以通过 BeautifulSoup 或者 XPath 来解析 HTML 页面,从而获取其中的图片地址。
我们只需要短短的几行代码,就能完成图片 url 的提取
import requests
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/celebrity/1011562/photos/'
res = requests.get(url).text
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
print(picture_list)
>>>
['https://img1.doubanio.com/view/photo/m/public/p2564834267.jpg', 'https://img1.doubanio.com/view/photo/m/public/p860687617.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2174001857.jpg', 'https://img1.doubanio.com/view/photo/m/public/p1563789129.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2363429946.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2382591759.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2363269182.jpg', 'https://img1.doubanio.com/view/photo/m/public/p1959495269.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2356638830.jpg', 'https://img3.doubanio.com/view/photo/m/public/p1959495471.jpg', 'https://img3.doubanio.com/view/photo/m/public/p1834379290.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2325385303.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2361707270.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2325385321.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2196488184.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2186019528.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2363270277.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2325240501.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2258657168.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2319710627.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2319710591.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2311434791.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2363270708.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2258657185.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2166193915.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2363265595.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2312085755.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2311434790.jpg', 'https://img3.doubanio.com/view/photo/m/public/p2276569205.jpg', 'https://img1.doubanio.com/view/photo/m/public/p2165332728.jpg']可以看到,是非常干净的列表,里面存储了海报地址。
但是这里也只是一页海报的数据,我们观察页面发现它有好多分页,如何处理分页呢。
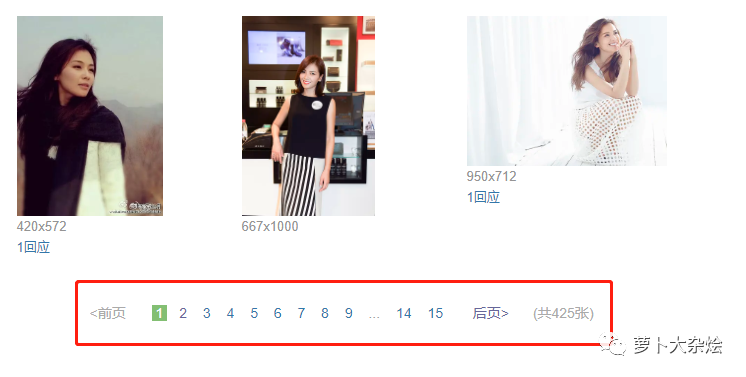
我们点击第二页,看看浏览器 url 的变化
https://movie.douban.com/celebrity/1011562/photos/?type=C&start=30&sortby=like&size=a&subtype=a
发现浏览器 url 增加了几个参数
再点击第三页,继续观察 url
https://movie.douban.com/celebrity/1011562/photos/?type=C&start=60&sortby=like&size=a&subtype=a
通过观察可知,这里的参数,只有 start 是变化的,即为变量,其余参数都可以按照常理来处理
同时还可以知道,这个 start 参数应该是起到了类似于 page 的作用,start = 30 是第二页,start = 60 是第三页,依次类推,最后一页是 start = 420。
于是我们处理分页的代码也呼之欲出了
首先将上面处理 HTML 页面的代码封装成函数
def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_list然后我们在另一个函数中处理分页和调用上面的函数
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
page += 1
此时,我们所有的海报数据都保存在了 data 变量中,现在就需要一个下载器来保存海报了
def download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)
再增加下载器到 fire 函数,此时为了不是请求过于频繁而影响豆瓣网的正常访问,设置 sleep time 为1秒
def fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)
下面就执行 fire 函数,等待程序运行完成后,当前目录下会生成一个 picture 的文件夹,里面保存了我们下载的所有海报

下面再来看下完整的代码
import requests
from bs4 import BeautifulSoup
import time
import osdef fire():
page = 0
for i in range(0, 450, 30):
print("开始爬取第 %s 页" % page)
url = 'https://movie.douban.com/celebrity/1011562/photos/?type=C&start={}&sortby=like&size=a&subtype=a'.format(i)
res = requests.get(url).text
data = get_poster_url(res)
download_picture(data)
page += 1
time.sleep(1)def get_poster_url(res):
content = BeautifulSoup(res, "html.parser")
data = content.find_all('div', attrs={'class': 'cover'})
picture_list = []
for d in data:
plist = d.find('img')['src']
picture_list.append(plist)
return picture_listdef download_picture(pic_l):
if not os.path.exists(r'picture'):
os.mkdir(r'picture')
for i in pic_l:
pic = requests.get(i)
p_name = i.split('/')[7]
with open('picture\\' + p_name, 'wb') as f:
f.write(pic.content)if __name__ == '__main__':
fire()
fire 函数
这是一个主执行函数,使用 range 函数来处理分页。
get_poster_url 函数
这个就是解析 HTML 的函数,使用的是 BeautifulSoup
download_picture 函数
简易图片下载器
本节讲解了爬虫的基本流程以及需要用到的 Python 库和方法,并通过一个实际的例子完成了从分析网页,到数据存储的全过程。其实爬虫,无外乎模拟请求,解析数据,保存数据。
当然有的时候,网站还会设置各种反爬机制,比如 cookie 校验,请求频度检查,非浏览器访问限制,JS 混淆等等,这个时候就需要用到反反爬技术了,比如抓取 cookie 放到 headers 中,使用代理 IP 访问,使用 Selenium 模拟浏览器等待方式。
由于本课程不是专门的爬虫课,这些技能就留待你自己去探索挖掘啦。

作为过来人,跟大家聊一聊我的自学心得,希望可以帮助大家少走弯路,少踩坑。
更多Python、爬虫、人工智能配套视频教程+书籍可以+v 免费领取。

对方向选择、学习规划、学习路线、职业发展方面有问题的可以加群:809160367


关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
Unity自动旋转动画1.开门需要门把手先动,门再动2.关门需要门先动,门把手再动3.中途播放过程中不可以再次进行操作觉得太复杂?查看我的文章开关门简易进阶版效果:如果这个门可以直接打开的话,就不需要放置"门把手"如果门把手还有钥匙需要旋转,那就可以把钥匙放在门把手的"门把手",理论上是可以无限套娃的可调整参数有:角度,反向,轴向,速度运行时点击Test进行测试自己写的代码比较垃圾,命名与结构比较拉,高手轻点喷,新手有类似的需求可以拿去做参考上代码usingSystem.Collections;usingSystem.Collections.Generic;usingUnityEngine;u
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主